一种基于卷积神经网络的音频处理方法、装置及相关设备
文献发布时间:2023-06-19 13:46:35
技术领域
本发明涉及视频初剪技术领域,尤其涉及一种基于卷积神经网络的音频处理方法、装置及相关设备。
背景技术
音视频时代的到来,使得越来越多的用户倾向于制作视频和剪辑视频。而如何从错综复杂的原视频中得到自己想要的内容,成为一件亟待解决的问题。
智能初剪作为一块新兴的领域,目前主流技术聚焦于对视频的信息量捕捉,主要是针对画面动作能量的叠加,找出能量变化较大的视频片段作为用户可能想初剪的结果,并且可以根据预设参数做一些视频片段时长和内容的调整。
目前的智能初剪技术,虽然可以帮助用户较大程度上减少剪辑时间,但仍存在几个缺点:
1.画面动作理解可能会忽略一些视频中的小细节变化,而这些变化可能在其他模态中是明显的,也就是说视频画面动作理解可能是内容的主要理解,但是仅仅依靠视频画面动作理解无法完全给予用户想要的视频片段;
2.对于一些只有音频需求,需要从音频中找到某些事件,此时无法借助于对视频画面动作的理解。
发明内容
本发明的目的是提供一种基于卷积神经网络的音频处理方法、装置及相关设备,旨在解决现有技术中,只根据视频信息进行初剪、仅仅依靠视频画面动作理解无法完全给予用户想要的视频片段的问题。
第一方面,本发明实施例提供了一种基于卷积神经网络的音频处理方法,包括:
提取视频数据中的音频信息;
对所述音频信息依次进行语音数据特征提取和降维运算得到降维特征数据;
将所述降维特征数据以预设时间长度分成若干份,并依次输入yamnet模型进行训练预测得到具有事件标签的语音音频数据和对应的语音事件时间戳;
根据所述语音事件时间戳,对每一所述语音音频数据进行切割处理,切割出每一所述语音音频数据的碎片数据,对每一所述语音音频数据进行语音端点检测得到话语级音频数据;
将所述话语级音频数据通过AlexNet网络进行语音情感检测得到预测的语音情感标签,记录所述语音情感标签和对应的时间段;
按时间先后顺序对所述语音音频数据和对应的语音事件时间戳、所述语音情感标签和对应的时间段进行整合,得到所述音频信息的所有所述事件标签、语音情感标签和对应的时间段。
第二方面,本发明实施例提供了一种基于卷积神经网络的音频处理装置,包括:
提取单元,用于提取视频数据中的音频信息;
特征提取降维单元,用于对所述音频信息依次进行语音数据特征提取和降维运算得到降维特征数据;
分类单元,用于将所述降维特征数据以预设时间长度分成若干份,并依次输入yamnet模型进行训练预测得到具有事件标签的语音音频数据和对应的语音事件时间戳;
语音端点检测单元,用于根据所述语音事件时间戳,对每一所述语音音频数据进行切割处理,切割出每一所述语音音频数据的碎片数据,对每一所述语音音频数据进行语音端点检测得到话语级音频数据;
语音情感检测单元,用于将所述话语级音频数据通过AlexNet网络进行语音情感检测得到预测的语音情感标签,记录所述语音情感标签和对应的时间段;
整合单元,用于按时间先后顺序对所述语音音频数据和对应的语音事件时间戳、所述语音情感标签和对应的时间段进行整合,得到所述音频信息的所有所述事件标签、语音情感标签和对应的时间段。
第三方面,本发明实施例又提供了一种计算机设备,其包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的基于卷积神经网络的音频处理方法。
第四方面,本发明实施例还提供了一种计算机可读存储介质,其中所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述第一方面所述的基于卷积神经网络的音频处理方法。
本发明通过对音频信息进行特征提取得到特征数据,并对特征数据进行降维,有利于后续处理中提高处理速度;将音频(降维特征数据)按预设时间长度进行事件切割,并对语音事件进行更精细化的切割,预测出语音情感标签,并对连续的情感标签对应的语音音频数据进行事件和时间点的逻辑合并。
本发明有效的简化了用户的操作步骤,将音频按预设时间长度切割,将音频碎片化,帮助用户进行音频的剪辑和音视频软件的智能碎片和事件剪辑模式。
附图说明
为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的基于卷积神经网络的音频处理方法的流程示意图;
图2为本发明实施例提供的步骤S102的子流程示意图;
图3为本发明实施例提供的步骤S103的子流程示意图;
图4为本发明实施例提供的步骤S304的子流程示意图;
图5为本发明实施例提供的步骤S105的子流程示意图;
图6为本发明实施例提供的步骤S601的子流程示意图;
图7为本发明实施例提供的基于卷积神经网络的音频处理装置的示意性框图;
图8为本发明实施例提供的步骤S501-S507的流程图;
图9为本发明实施例提供的步骤S601-S603的流程图;
图10为本发明实施例提供的DPTM的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
应当理解,当在本说明书和所附权利要求书中使用时,术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
还应当理解,在此本发明说明书中所使用的术语仅仅是出于描述特定实施例的目的而并不意在限制本发明。如在本发明说明书和所附权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。
还应当进一步理解,在本发明说明书和所附权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
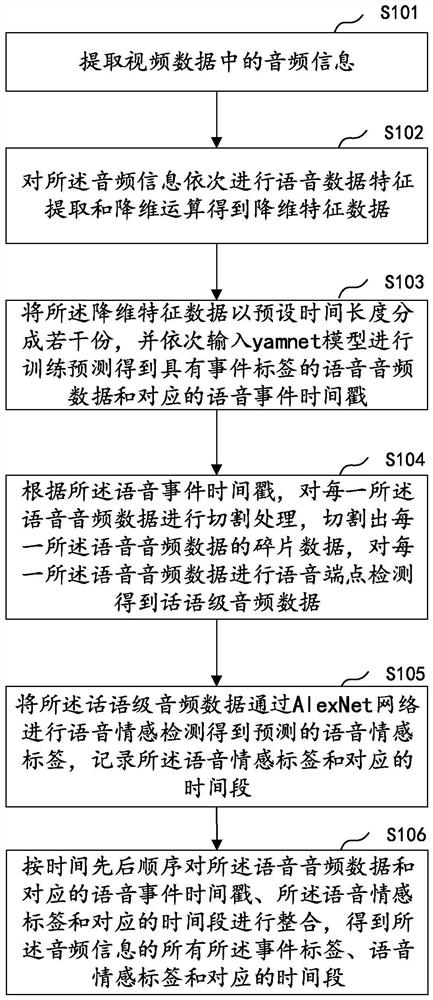
请参阅图1,一种基于卷积神经网络的音频处理方法,包括步骤S101-S106。
S101:提取视频数据中的音频信息;
S102:对所述音频信息依次进行语音数据特征提取和降维运算得到降维特征数据;
S103:将所述降维特征数据以预设时间长度分成若干份,并依次输入yamnet模型进行训练预测得到具有事件标签的语音音频数据和对应的语音事件时间戳;
S104:根据所述语音事件时间戳,对每一所述语音音频数据进行切割处理,切割出每一所述语音音频数据的碎片数据,对每一所述语音音频数据进行语音端点检测得到话语级音频数据;
S105:将所述话语级音频数据通过AlexNet网络进行语音情感检测得到预测的语音情感标签,记录所述语音情感标签和对应的时间段;
S106:按时间先后顺序对所述语音音频数据和对应的语音事件时间戳、所述语音情感标签和对应的时间段进行整合,得到所述音频信息的所有所述事件标签、语音情感标签和对应的时间段。
在本实施例中,通过对音频信息进行特征提取得到特征数据,并对特征数据进行降维,有利于后续处理中提高处理速度;将音频(降维特征数据)按预设时间长度进行事件切割,并对语音事件进行更精细化的切割,预测出语音情感标签,并对连续的情感标签对应的语音音频数据进行事件和时间点的逻辑合并。
本发明有效的简化了用户的操作步骤,将音频按预设时间长度切割,将音频碎片化,帮助用户进行音频的剪辑和音视频软件的智能碎片和事件剪辑模式。
请参阅图2,在一实施例中,步骤S102,包括:
S201:对所述音频信息进行语音数据特征提取,得到语音特征;
S202:对所述语音特征依次进行重采样、预加重、分帧、加窗、FFT、Mel滤波、对数运算和DCT操作,最终得到所述降维特征数据。
在本实施例中,对所述音频信息进行语音数据特征提取,其中特征提取技术可以运用现有技术中公开的音频特征提取技术。
以下以一实施例中的具体实施方式为例对步骤S202操作进行说明(其中的数据可以根据实际进行适应性的变动):
具体的,对语音特征进行重采样操作,将语音特征的时域信息重新采样到16KHz(采样成16Khz的原因是因为yamnet模型的训练集数据的采样率皆为16KHz,所以测试数据在16Khz的时候会得到最优的效果),接着对语音特征进行预加重操作(预加重一般是乘以一个比较小的系数,或者去除直流分量,保证音频数值范围的有效性),紧接着进行分帧操作,以400个数据点为窗口大小,以160个数据点为帧移长度(即前后帧之间的重叠点数为240个数据点),即25ms为音频的一帧,每一次音频点移动10ms的长度,对每一帧音频数据进行汉明窗加窗后,进行FFT(快速傅里叶变化),并使用64个滤波器大小的Mel窗口对每一帧语音特征进行滤波器操作,计算其功率谱(计算功率谱包含对数运算和平方运算),最后经过离散余弦变化(DCT),得到语音特征的MFCC的特征数据,即降维特征数据。
其中,yamnet模型是一个经过预训练的深度网络,可基于AudioSet-YouTube语料库预测521种音频事件类别,并采用Mobilenet_v1深度可分离卷积架构。
请参阅图3,在一实施例中,步骤S103,包括:
S301:以预设时间长度将所述降维特征数据分割成若干份;
S302:将分割后的每一所述降维特征数据作为输入数据输入yamnet模型,得到对应的预测数据;
S303:对所述预测数据进行打分,根据打分结果从大到小进行排序,得到对应的当前时间长度内的声音事件概率,记录所述当前时间和对应的概率最大的若干个事件;
S304:对每一当前时间长度对应的降维特征数据和对应的概率最大的若干个事件进行整合得到语音音频数据和对应的语音事件时间戳。
在本实施例中,分割的长度可以自定义设置。
优选的,预设时间长度为1秒;记录所述当前时间和对应的概率最大的五个事件。
以下以一实施例中的具体实施方式为例对步骤S301-S304的操作进行说明(其中的数据可以根据实际进行适应性的变动):
具体的,以1秒的音频帧长度所组成的MFCC特征(即步骤S301实现分割后的单位降维特征数据)为输入数据依次输入yamnet模型进行预测,得到一个大小为[32,520]的预测数据(32代表yamnet模型对于这个时间长度最后得到的32个打分机制,520代表yamnet模型的标签一共有520个,[32,520]为yamnet训练模型的输出矩阵,是固定值),对32个打分取平均数后,进而对520个事件进行打分结果从大到小的排序,就可以得到当前时间段(由于是以1秒为切割长度,故每一单位降维特征数据都代表了一时间段,当前时间段也代表了当前降维特征数据)内的声音事件概率(声音事件指的是音频中出现的现实生活事件,比如说话,哭,笑,音乐等)。对其他每一个相当长度的降维特征数据都做上述操作(循环操作),记录每一次的时间和对应的前五个最可能的事件。当yamnet模型预测完成以后,对时间段(长度)所代表的降维特征数据和事件进行整合,即如果前后秒级的事件标签相同时,则把两个时间段(长度)对应的降维特征数据进行合并,以此类推,最后把事件标签为演讲(Speech)和交谈(Conversation)的降维特征数据部分加以提取,得到语音音频数据和对应的语音事件时间戳。
请参阅图4,在一实施例中,步骤S304,包括:
S401:当前后的两个事件的事件标签相同时,合并两个事件;
S402:提取出所述事件标签为演讲和交谈的对应的语音音频数据。
在本实施例中,具体操作已在上述对步骤S301-S304的操作说明中写明,可参考。
在一实施例中,步骤S104,包括:
S501:对每一所述语音音频数据中的每一帧进行短时傅里叶变化,以将所述语音音频数据从时域信息转换为频率信息;
S502:计算每一所述语音音频数据中的每一帧的短期能量和光谱差,得到每一所述语音音频数据对应的直方图的分布信息;
S503:采用以下公式计算直方图的阈值:
S504:将每一所述语音音频数据中的每一帧的所述短期能量和光谱差通过连续的五元素移动中位数过滤器进行平滑处理,以在一段时间内平滑;
S505:标记所述直方图中所述短期能量和光谱差中所有大于对应预设阈值的分布值所对应的数据坐标点,并记录所述数据坐标点;
S506:将数据坐标点按大小顺序进行整合,取两个相邻数据坐标点之间的数值长度作为语音段;
S507:当相邻两个语音段之间的时间距离小于预设的合并距离数值时,将两个所述语音段进行合并得到话语级音频数据;
其中,M
在本实施例中,将所述语音音频数据重采样到音频长度与音频信息的音频长度相同,根据所述语音事件时间戳,切割出每一个语音音频数据的碎片数据,紧接着对每一段语音音频数据使用语音端点检测进行话语级的切割(碎片化切割是因为并不是所有的声音事件检测的结果,举例如步骤一最后得到的结果为[[0,10],speech],[[10,12],cry],[[12,14],speech],那么语音的数据碎片其实只有0~10秒和12~14秒,而话语级切割的原因是因为在一段较长的说话内容中如0~10秒中,人的情感可能是有所变化的,但是因为情感变化的时间可能是短暂的,总体的情感是平稳的,但是局部可能会存在情感的较大变化,所以要进行话语级的切割)。
请参阅图8,具体步骤如下:
a)设定好音频audioIn的窗口长度window和帧间的重复长度OverlapLength,将音频从时域信息转换为频率信息,即进行短时傅里叶变化(STFT)(请参阅图8中1代表的步骤),短时傅里叶变化是傅里叶变化的一种变形,可以有效解决傅里叶变化过程中时间信息丢失的问题,达到时域信息和频域信息在时间线上的对应;
b)计算每一所述语音音频数据中的每一帧的短期能量Energy和光谱差Spread;其中光谱差是根据光谱分布计算的;短期能量Energy是可以区分浊音段和情感段,浊音段的短时数值远大于清音段,光谱差可以很好的体现声音的短时变化情况,光谱差越小,说明声音处于一段稳定的清音或者浊音(请参阅图8中2代表的步骤);
c)直方图(Histogram)分布信息由短期能量和光谱分布的数据共同决定(请参阅图8中3代表的步骤);
d)对于每一个直方图,阈值(DetermineThreshold)根据
e)将光谱差和短期能量都通过连续的五元素移动中位数过滤器进行平滑处理(平滑Smooth)(五元素移动中位数过滤器movmedian为matlab中的一个函数)(请参阅图8中5代表的步骤),五元素移动中位数过滤器相当于跟传统的中位数相比,有效的利用了每一个点的位置信息,传统的中位数如果5个数取中位值,则5个数都会被覆盖为一个数,而移动中位数则会在每一次的移动中增加点的信息使用率,使数据结果更加平滑,比如1、2、3、4、5传统中位数为3、3、3、3、3而1、2、3、4、5、6、7、8移动中位数为2、2.5、3、4、5、6;
f)设置短期能量和光谱分布各自的阈值Create Mask(预设阈值),寻找到相应阈值符合条件的直方图中分布值所对应的短期能量Energy或者是光谱差Spread的对应数值坐标点,标记所述直方图中所述短期能量和光谱差中所有大于对应预设阈值的分布值所对应的数据坐标点,记为标记Mask。即短期能量和光谱差都必须高于各自的阈值,保证包含的时间段必定是语音(请参阅图8中6和7代表的步骤);
g)将上面得到的短期能量Energy和光谱差Spread的数值坐标点按大小顺序进行整合,称为合并Merge,每两个数值坐标点之间的数值长度称为一段语音段,如果Merge中的两个语音段时间的距离差距小于设置的合并距离MergeDistance,当前的两个相邻的语音段将被合并,最终输出结果speechindices(结果的数值为语音段的起始点和终止点,且speechindices数量一定是偶数)(请参阅图8中8代表的步骤)。
请参阅图5,在一实施例中,步骤S105,包括:
S601:对所述AlexNet网络进行模型训练;
S602:将所述AlexNet网络中的全连接层的上一层的输出作为DTPM的输入,所述DTPM的输出作为所述全连接层的输入;
S603:将所述话语级音频数据进行特征提取并通过所述AlexNet网络进行预测,得到语音情感标签和对应的时间段。
在本实施例中,使用柏林情感数据集(EMO-DB),The RyersonAudio-VisualDatabase of Emotional Speech and Song(RAVDESS),MELD:Multimodal EmotionLinesDataset作为本次AlexNet网络所使用的数据集,三个数据集都是一段音频对应一个情感标签,共有情感标签有anger,disgust,neutral,happy,sadness,fear,因此可以使用交叉熵作为损失函数,对AlexNet网络进行学习。三个数据集进行混合后,以数据集总量的70%的数据量为训练集、10%的验证集、20%的为测试集,在AlexNet网络中进行训练模型训练。
其中,AlexNet网络是2012年ImageNet竞赛冠军获得者Hinton和他的学生AlexKrizhevsky设计的。
请参阅图9,具体步骤如下:
因为三个数据集每一个音频的长度不同,数据预处理阶段,把所有的音频数据切割成相同的长度,并计算切割后的每一个音频数据中的每一帧的MFCC、MFCC的一阶差分和MFCC的二阶差分,计算完成后特征的大小为(64,64,3),第一个64为64个Mel滤波器,其中中间的数值64为频率的64个帧,由输入的音频长度决定,3表示MECC、MFCC的一阶差分和MFCC的二阶差分为一组完整的特征数据(Log Mel-spectgram);
采用以下公式计算差分:
其中,N为特征长度,c
对所述特征数据进行整理,特征整理的流程为:假设MFCC和MFCC的一阶差分和MFCC的二阶差分的大小都是(64,64,1),其中第一个64为64个Mel滤波器,第二个64是64个帧,第三个为有1个大小为64*64的特征,把得到的三个特征按照第三维度,即具体特征类别维度进行整理,得到的大小为(64,64,3),这是一个音频数据碎片可能的大小,假设如果音频数据的集合有10000个,则总的特征应该表示为四维,即(10000,64,64,3),此为总体数据集,取70%作为训练集(并保证标签和特征对应),即把(7000,64,64,3)的特征按着一定的batch大小依次输入AlexNet网络训练(DCNN),当训练集准确率达到90%时,模型训练就可以结束(batch为每一次模型训练的训练集数量,一般为2的n次方,常取16,32,64)。
将话语级音频数据经过特征提取,将所述AlexNet网络中的全连接层的上一层的输出作为DTPM的输入,所述DTPM的输出作为所述全连接层的输入,将所述话语级音频数据进行特征提取并通过所述AlexNet网络进行预测,得到语音情感标签和对应的时间段(DTPM是一个时间尺度的层,经过DTPM,可以把原本切割成碎片化的特征整合为每一个音频的话语级特征,保证话语级可以通过对时间尺度的学习,得到最优的特征结果,并保证最后的每一个音频的特征长度保持相同)。
其中,MFCC表示经过梅尔倒谱系数提取流程提取后的数据,梅尔倒谱系数提取流程可参考步骤S202。
请参阅图10,其中,DPTM算法全称时域金字塔,目的是将同一个音频相同碎片大小的特征进行话语级的学习,分别把音频在1阶,2阶和4阶2上进行时间尺度的扩大,然后再1阶上取得一个特征向量,2阶上取得一个2阶特征向量,4阶上取得一个4阶特征向量,并加以分别1,0.5,0.25的权重,将一个7阶的碎片化的特征向量用平均池化的方式得到话语级的音频特征(Utterance-based Features)。即不同长度的音频,最终都可以得到一个相同特征长度的话语级特征。
请参阅图6,在一实施例中,步骤S601,包括:
S701:将所述数据集切割成长度相同的音频数据,并分别计算每一所述音频数据中每一帧的MFCC、MFCC的一阶差分和MFCC的二阶差分,得到完整的特征数据;
S702:对所述特征数据进行整理,输入AlexNet网络进行模型训练。
在本实施例中,可参考上述步骤S601-S603的具体步骤说明。
请参阅图7,一种基于卷积神经网络的音频处理装置10,包括:
提取单元11,用于提取视频数据中的音频信息;
特征提取降维单元12,用于对所述音频信息依次进行语音数据特征提取和降维运算得到降维特征数据;
分类单元13,用于将所述降维特征数据以预设时间长度分成若干份,并依次输入yamnet模型进行训练预测得到具有事件标签的语音音频数据和对应的语音事件时间戳;
语音端点检测单元14,用于根据所述语音事件时间戳,对每一所述语音音频数据进行切割处理,切割出每一所述语音音频数据的碎片数据,对每一所述语音音频数据进行语音端点检测得到话语级音频数据;
语音情感检测单元15,用于将所述话语级音频数据通过AlexNet网络进行语音情感检测得到预测的语音情感标签,记录所述语音情感标签和对应的时间段;
整合单元16,用于按时间先后顺序对所述语音音频数据和对应的语音事件时间戳、所述语音情感标签和对应的时间段进行整合,得到所述音频信息的所有所述事件标签、语音情感标签和对应的时间段。
一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至7中任一项所述的基于卷积神经网络的音频处理方法。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行如权利要求1至7任一项所述的基于卷积神经网络的音频处理方法。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 一种基于卷积神经网络的音频处理方法、装置及相关设备
- 基于卷积神经网络的MRI图像处理方法、装置及相关设备