一种基于改进的余弦相似性算法的事件相似性比对方法
文献发布时间:2023-06-19 13:46:35
技术领域
本发明涉及关键词的提取及事件相似性比对,尤其涉及基于改进的余弦相似性算法的关键词提取及相似性比对。
背景技术
社会治理数字化改革是提升国家治理效能中的重要一环。社会治理需要整合信访、公安、司法、市民热线等所有能整合的数据,借助信息化数据处理技术,在各类数据中提取出风险较大的事件作为社会主要的矛盾和风险进行及时的告警,把社会风险化解在萌芽状态,最终达到降低社会风险、建设更高水平的平安中国的伟大目标。
由于社会治理涉及的数据面非常广泛,包括信访、公安、司法、市民热线等各类数据,其中存在着地名、村名、小区名、企业和个体工商户名、学校、娱乐场所等各式各样的名称,通常描述中这些名称都不是政府官方登记的名称,而是具有地方特色的口语化简称,同类事件的描述差异较大。现有的jieba分词、Ansj_seg分词等组件在通用场景中具有很好的分词能力,但对于本发明所处的特定场景(口语化简称识别、地方特色词语识别),现有的分词组件存在分词不准确,从而导致关键词提取不够精准的技术问题。另外,jieba分词、Ansj_seg分词等组件还存在分词过度,导致相似性比对时复杂度过高的问题。
对于分完词的事件描述相似性判断,目前比较常用的方法是通过计算事件词向量间的余弦相似性的大小来判断事件的相似程度。其中余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度,计算公式如下:
其中,
现有的余弦相似性算法在计算相似性时没有考虑到某些特殊情况,比如当一个词向量中的词包含在另一个词向量内时,会造成计算的结果为1,导致本来不相似的两事件判断为相似的,举例:
发明内容
为了解决jieba分词和Ansj_seg分词对于地名、企业和个体工商户名等名称的口语化简称进行分词时,分词不精准并降低因过度分词导致的文本相似性对比复杂度高以及文本相似性比对技术不准确的问题,本发明提供一种基于改进的余弦相似性计算方法的关键词提取和事件相似性比对方法,以便可以更准确地判断事件的相似性。
本发明提供一种基于改进的余弦相似性算法的事件相似性比对方法,方法包括以下步骤:
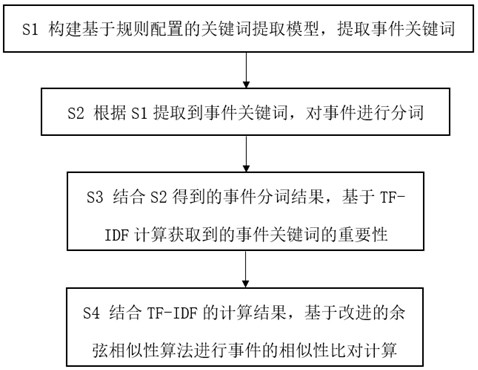
S1 构建基于规则配置的关键词提取模型,提取事件关键词;
S2 根据S1提取到事件关键词,对事件进行分词;
S3 结合S2得到的事件分词结果,基于TF-IDF计算获取到的事件关键词的重要性;
S4 结合TF-IDF的计算结果,基于改进的余弦相似性算法进行事件的相似性比对计算;
其中,基于规则配置的关键词提取模型专门用于处理专用实体名称,所述基于规则配置的关键词提取模型包括规则配置模块,规则配置模块由多张具有不同预设规则的配置表组成;
所述改进的余弦相似性算法为计算向量夹角余弦值与基于示性函数的词向量长度的最大比率。
作为一个实施例,所述改进的余弦相似性算法包括由拆分错误的词的数量构建的分段式矫正函数。
作为一个实施例,基于规则配置的关键词提取模型还包括基础词料库、关键词生成模块、关键词提取模块。
作为一个实施例,S1 构建基于规则配置的关键词提取模型,提取事件关键词具体包括:
S1.1 构建基础词料库;
S1.2 根据预设规则,构建规则配置模块的多个配置表;
S1.3 基于关键词生成模块生成事件关键词;
S1.4 基于关键词提取模块提取事件关键词。
作为一个实施例,S1.2 根据预设规则,构建规则配置模块的配置表包括:
配置表至少包括停用词表、替换词表、自定义添加词表中的一种或多种的组合,各配置表具有相应的预设规则。
作为一个实施例,S1.3 基于关键词生成模块生成事件关键词包括:
关键词生成模块读取规则配置模块中的配置表数据,基于Spark分布式计算框架按照特定规则处理基础词料库中的词,形成最终的关键词输出到关键词库中。
作为一个实施例,S1.4 基于关键词提取模块提取事件关键词具体包括:
S1.4.1 在任务开始时,设置任务的必要参数,必要参数至少包括分区数、执行器个数、每个执行器的CPU核数;
S1.4.2 通过Spark分布式计算框架读取关键词库,基于关键词库的数据构造分布式词典,将词典分发到每个执行器中;
S1.4.3 通过Spark分布式计算框架将分区中的数据提交给执行器,执行器基于事件的描述文本,遍历词典库中的每一个关键词进行文本匹配,并对事件的描述文本中能匹配上的所有关键词按照字典序进行排序;
S1.4.4 通过S1.4.3获得每个事件的描述文本对应的关键词,将关键词记录到事件表中。
作为一个实施例,S2 根据S1提取到事件关键词,对事件进行分词包括通过jieba库进行分词。
作为一个实施例,S3 结合S2得到的事件分词结果,基于TF-IDF计算获取到的事件关键词的重要性具体包括:
S3.1计算词频(term frequency, TF),计算公式为
S3.2计算逆向文件频率 (inverse document frequency, IDF),具体公式为:
S3.3计算最终的TF-IDF,具体公式如下:
作为一个实施例,S4 结合TF-IDF的计算结果,基于改进的余弦相似性算法进行事件的相似性比对计算具体包括,改进的余弦相似性算法的计算公式如下:
其中,
本发明还提供一种存储介质,其存储有计算机程序;当所述计算机程序被计算机设备中的处理器执行时,计算机设备执行上述任一项的方法。
本发明提供的提供基于改进的余弦相似性计算方法的关键词提取和事件相似性比对方法,首先利用TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)计算出分词后词向量中每个词的重要性,再根据改进的余弦相似性进行事件的相似性度量。本发明对传统的余弦相似性进行了一定补充,弥补了当一个词向量中的词包含在另一个词向量内时,传统的余弦相似性会造成计算的结果为偏高,导致本来不相似的两事件判断为相似的的缺陷。经实际的事件相似性判断运行结果表明,相比于传统的余弦相似性算法,本发明改进的余弦相似性算法在进行事件相似性判断时,判断结果更为准确。同时,本发明通过设置基于规则配置的关键词提取模型,有效解决了现有技术在特定场景下分词不准确造成的关键词提取不精准、以及过度分词和文本相似性计算错误的问题。
附图说明
为了更清楚地说明发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的方法流程图
图2是基于本发明改进的余弦相似性算法和传统的余弦相似性算法计算事件1和事件2的相似性的示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
实施例一
本发明提供一种基于改进的余弦相似性算法的关键词提取和事件相似性比对方法,其流程图如图1所示,包括以下步骤:
S1 构建基于规则配置的关键词提取模型,提取事件关键词;
其中,基于规则配置的关键词提取模型专门用于处理专用实体名称,所述基于规则配置的关键词提取模型包括规则配置模块,所述规则配置模块由多张具有不同预设规则的配置表组成。
众所周知,社会治理所涉及的信访、公安、司法、市民热线等各类数据中,存在着地名、村名、小区名、企业和个体工商户名、学校、娱乐场所等各式各样的名称,通常描述中这些名称都不是政府官方登记的名称,而是具有地方特色的口语化简称。现有的jieba分词、Ansj_seg分词等组件在通用场景中具有很好的分词能力,但对于上述特定场景(口语化简称识别、地方特色词语识别)中,现有的分词组件存在分词不准确,关键词提取不够精准的问题。本发明通过设置专门用于处理实体名称的基于规则配置的关键词提取模型,可以有效提高特定场景下的分词准确性。
基于规则配置的关键词提取模型还包括基础词料库、关键词生成模块、关键词提取模块。
其中,S1 构建基于规则配置的关键词提取模型具体包括以下步骤:
S1.1 构建基础词料库;
S1.2 根据预设规则,构建规则配置模块的配置表;
具体的,规则配置模块由多张配置表组成,不同的配置表对应不同的处理规则。配置表包括停用词表、替换词表、自定义添加词表等,各表具有相应的预设规则。
其中,停用词表中预设有原始词料中经常出现的词,如有限公司、分公司、公司、xx省、xx市、商行、服务部等以及“【”、“】”、“(”、“)”、“,”等标点符号。这类词通常会大量出现在原始词料中,当这些词被分词出来后,对于相似性的比对意义不大并且会影响相似性的准确性。因此,本发明设置先经过停用词处理后再输出关键词。
替换词表用于当部分原始词料难以用规则正确处理时,根据预设规则,使用原始词料所对应的正确关键词替换原始词料,配置在替换词报中。替换词表是对停用词的一种补充和修正,原始词料会先经过替换词表的查找,如已在替换词表中,就输出表中提供的关键词,之后这个原始词料不再做停用词处理。如在替换词表中查找不到,则做停用词处理后输出关键词。例如,经过人工核验,当一个原始词料是由多个停用词构成的,通过停用词规则处理后输出的关键词,可能不再具有原始词料的含义,如“xx市运输有限公司”,经过停用词处理后,输出关键词:“运输”,与“xx市运输有限公司”含义差别较大,造成分词不准确。这类专用实体名称就需要人工标注出与名称含义相近的关键词如“xx市运输公司”,将原始词料与对应的关键词加入到替换词表中作为预设规则。
自定义添加词表中通常预设一些通用的关键词,并可对后续新产生的关键词做添加。如中国移动、中国联通、中国电信、移动公司、联通公司、电信公司、火车站等作为预设关键词。如台风、积水、内涝等关键词会由于台风下暴雨而作为关键词被添加到自定义添加词表中。
S1.3 基于关键词生成模块生成事件关键词;
具体的,关键词生成模块读取规则配置模块中的配置表数据,基于Spark分布式计算框架按照特定规则处理基础词料库中的词,最终输出到关键词库中,具体包括以下步骤:
S1.3.1 利用Spark分布式计算框架,分别将停用词表、替换词表、自定义添加词表中的数据读取到内存中。
S1.3.2 利用Spark分布式计算框架,将原始词料读取到内存中。
S1.3.3 遍历每一个原始词料,在替换词表中查找是否有配置对应的关键词,找到则将原始词料与关键词存于内存中等待最终输出;没找到就对原始词料做停用词处理,将原始词料中的停用词去除,将剩余部分作为关键词存于内存中等待最终输出。
S1.3.4 利用Spark分布式计算框架,将内存中的关键词与自定义添加词表中的数据合并起来后去重,形成最终的关键词输出到关键词库中。
S1.4 基于关键词提取模块提取事件关键词;
具体的,关键词提取模块基于Spark分布式计算框架将关键词库构造成分布式词典,遍历词典库,对事件的描述文本进行匹配,抽取出事件的关键词,具体包括以下步骤:
S1.4.1 在任务开始时,设置任务的必要参数,例如设置分区数为20,执行器的个数为5,每个执行器的CPU核数为2。Spark分布式计算框架将所有事件数据按照事件id的hashcode将数据分散到20个分区中。
S1.4.2 通过Spark分布式计算框架读取关键词库,基于关键词库的数据构造分布式词典,将词典分发到每个执行器中。
S1.4.3 Spark分布式计算框架将20个分区中的数据提交给执行器,执行器基于事件的描述文本,遍历词典库中的每一个关键词做文本匹配,事件描述中包含该关键词的,则存于内存中,不包含的就对下一个关键词做文本匹配,直到一个事件的事件描述匹配完词库中的所有关键词。对该事件描述能匹配上的所有关键词按照字典序进行排序。
S1.4.4 通过S1.4.3获得每个事件的事件描述对应的关键词,将关键词记录到事件表中。
S2 根据S1提取到事件关键词,对事件进行分词;
本发明采用jieba库进行分词,在分词前,先导入S1提取到的事件关键词,然后基于jieba库对关键词进行语义分割。
S3 结合S2得到的事件分词结果,基于TF-IDF计算获取到的事件关键词的重要性。
具体的,首先利用TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)技术,将文本转化为数值,并计算出分词后词向量中每个词的重要性。
具体的,TF-IDF的计算过程如下:
S3.1计算词频 (term frequency, TF),即计算某一个给定的词语在该文件中出现的次数,计算公式为
S3.2计算逆向文件频率 (inverse document frequency, IDF),具体由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到,具体公式为:
S3.3计算最终的TF-IDF,公式如下:
本实施例根据最终的TF-IDF公式可以计算出每个词的TF-IDF值,通过它我们可以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度,借此可以过滤掉常见的词语,保留重要的词语。
S4 结合TF-IDF的计算结果,基于改进的余弦相似性算法进行事件的相似性计算。
其中,改进余弦相似性算法的公式如下:
(2)
其中:
相对于传统的余弦相似性算法,本实施例通过增加两个向量长度的最大比率,可以有效的消除词向量长度差异带来的影响。本实施例的最大比率的计算方式基于示性函数获得,在保持一定有效率的情况下,极大的降低了计算量,提高了整体的计算速度。
在另一优选实施例中,基于改进余弦相似性算法采用jieba分词的准确率进行矫正:
其中,
a、b、p基于历史数据训练获得最优解,其训练的方法为常规训练方法,在数据量一定的情况下,训练方法本身不影响本实施例的技术效果的实现。
现有技术中,通常情况下在计算预先相似性时,未考虑在先阶段的处理带来的误差,如分词等。本实施例综合考虑在先多个阶段的误差,有针对性的选择不同的最优处理方式。在先阶段包括分词阶段、文本转化数值等。分词阶段,基于矫正函数消除分词误差的影响;文本转化数值阶段,基于最大比例消除向量长度的影响。本实施例通过对上述多个阶段的误差消除不可拆离式的有机融合,准确且高效地对事件的相似度进行最优化处理,避免了现有技术中由于分词不当、长度差异带来的不相似的两事件判断为相似的的缺陷。
作为一个应用实施例,如图2所示,分别通过本发明改进的余弦相似性算法和传统的余弦相似性算法计算事件1和事件2的相似性。事件1为“佛堂镇骆村**(谐音)户,修筑围墙,严重影响到其他住户。诉求:希望拆除围墙,请处理”。事件2为“佛堂镇骆村**(谐音)户,修筑围墙,严重影响到其他住户。12月30日又工作人员回电告知元旦回来推土的,但是来了之后是骗骗的,又围回去了”。根据图2显示的计算结果可知,改进的余弦相似性算法结果准确性高的多。
本实施例对传统的余弦相似性进行了一定补充,弥补了当一个词向量中的词包含在另一个词向量内时,传统的余弦相似性会造成计算的结果为偏高,导致本来不相似的两事件判断为相似的的缺陷。经实际的事件相似性判断运行结果表明,相比于传统的余弦相似性算法,本实施例改进的余弦相似性算法在进行事件相似性判断时,判断结果更为准确。同时,本发明通过设置基于规则配置的关键词提取模型,有效解决了现有技术在特定场景下分词不准确造成的关键词提取不精准、以及过度分词和文本相似性计算错误的问题。本实施例综合考虑在先多个阶段的误差,有针对性的选择不同的最优处理方式。在先阶段包括分词阶段、文本转化数值等。分词阶段,基于矫正函数消除分词误差的影响;文本转化数值阶段,基于最大比例消除向量长度的影响。本实施例通过对上述多个阶段的误差消除不可拆离式的有机融合,进一步提高了相似性事件判断的准确性。
为了说明的目的,前述描述使用具体命名以提供对所述实施方案的透彻理解。然而,对于本领域的技术人员而言将显而易见的是,不需要具体细节即可实践所述实施方案。因此,出于例示和描述的目的,呈现了对本文所述的具体实施方案的前述描述。这些描述并非旨在是穷举性的或将实施方案限制到所公开的精确形式。对于本领域的普通技术人员而言将显而易见的是,鉴于上面的教导内容,许多修改和变型是可行的。另外,当在本文中用于指部件的位置时,上文和下文的术语或它们的同义词不一定指相对于外部参照的绝对位置,而是指部件的参考附图的相对位置。
此外,前述附图和描述包括许多概念和特征,其可以多种方式组合以实现多种有益效果和优点。因此,可组合来自各种不同附图的特征,部件,元件和/或概念,以产生未必在本说明书中示出或描述的实施方案或实施方式。此外,在任何特定实施方案和/或实施方式中,不一定需要具体附图或说明中所示的所有特征,部件,元件和/或概念。应当理解,此类实施方案和/或实施方式落入本说明书的范围。
- 一种基于改进的余弦相似性算法的事件相似性比对方法
- 一种基于复杂网络结点相似性的计算事件相似性的方法和系统