基于强化学习的多电平变换器中点电压平衡系统及方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及多电平变换器控制技术领域,尤其是涉及一种基于强化学习的多电平变换器中点电压平衡系统及方法。
背景技术
随着电力电子、微电子技术和现代控制理论的发展,多电平变换器成为解决中高压大功率电能变换的重要手段。多电平变换器输出的波形更接近正弦波,具有输出谐波含量低、单个开关器件承受电压应力小、dv/dt小、开关损耗小、EMI小等优点。中点钳位型变换器是广泛应用的多电平变换器拓扑结构类型,其特点是直流侧通过串联电容进行分压,变换器通过钳位两电容中点的电压产生多电平。两电容的中点即为中性点,因此,直流侧中性点的电压平衡控制是系统正确输出电平以及安全稳定运行的重要保障。抑制中点电压波动的方法较多,闭环控制方法是较为常见的方法之一。
现有的经典控制方法实现简单,效果稳定,但在自我学习、自适应和容错能力上明显不足,基于现代控制理论的控制方法对此进行了改进,对非线性系统具有良好的控制效果,但是仍然需要较多的先验知识,缺少自我寻优的能力。且目前中点钳位型多电平变换器存在的直流侧电容电压难以快速平衡、平衡算法实时性差、鲁棒性差、输出电流电压谐波大、受外部环境和负载变换影响较大、算法缺乏通用性等问题。
发明内容
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种调节响应速度快、抗扰动能力强、成本低的基于强化学习的多电平变换器中点电压平衡系统及方法。
本发明的目的可以通过以下技术方案来实现:
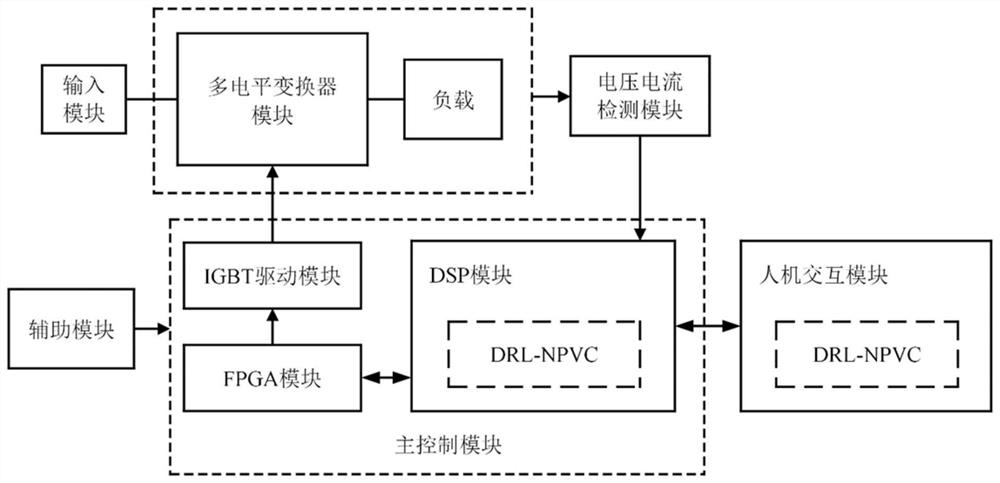
根据本发明的一个方面,提供了一种基于强化学习的多电平变换器中点电压平衡系统,包括输入模块、多电平变换器模块、电压电流检测模块、主控制模块、人机交互模块以及辅助模块,所述的辅助模块与主控制模块连接,所述的主控制模块包括FPGA模块以及分别与FPGA模块连接的IGBT驱动模块和DSP模块,所述的DSP模块分别与电压电流检测模块、人机交互模块连接,所述的多电平变换器模块分别与输入模块、IGBT驱动模块和电压电流检测模块连接;
所述的DSP模块或人机交互模块上部署有基于深度强化学习算法的中点电压控制器模块DRL-NPVC。
作为优选的技术方案,所述的输入模块包括交流输入端及不控整流器,所述交流输入端接交流电网,通过不控整流器,转化为独立直流电源与多电平变换器模块连接。
作为优选的技术方案,所述的多电平变换器模块包括各电平等级的中点钳位型多电平变换器,该多电平变换器直流侧采用两个电容器串联,通过钳位电容的中点电位产生多电平;每一相包含多个IGBT或反向Diode;所述多电平变换器的交流输出端通过滤波器与负载连接。
作为优选的技术方案,所述的电压电流检测模块通过与所述的DSP模块连接,用于获取实时电路信号,包括输出电流、输出电压以及直流侧电容电压;
所述的FPGA模块与IGBT驱动模块连接,用于发出PWM控制信号。
所述的IGBT驱动模块与多电平变换器模块连接,用于实现IGBT的开断控制。
作为优选的技术方案,所述的DSP模块用于部属多电平变换器空间矢量脉宽调制策略SVPWM。
作为优选的技术方案,所述的基于深度强化学习算法的中点电压控制器模块DRL-NPVC包括输入子模块、判断子模块和输出子模块;
所述的输入子模块通过电压电流检测模块获取直流侧电容电压、负载端电流电压及其他电路参数值;所述的判断子模块用于判断当前电压控制策略是否为最优策略,如果是,执行此策略并更新网络参数,如果不是,则继续执行迭代直到选出最优策略;所述的输出子模块用于输出当前选择的最优策略及参数,用于优化多电平变换器的SVPWM调制策略,实现中点电压的平衡控制。
作为优选的技术方案,如果所述的DRL-NPVC模块部署在人机交互模块中,还需要相应的通讯端口和DSP模块进行通信交互。
作为优选的技术方案,所述的人机交互模块包括上位机和显示屏,与DSP模块相连,用于实现人机交互。
作为优选的技术方案,所述的辅助模块包括辅助电源及外围设备,所述的辅助电源为不间断电源,与FPGA模块、DSP模块及IGBT驱动模块分别连接,用于保障系统电压的稳定,满足供电需求。
根据本发明的另一个方面,提供了一种用于权利要求1所述的基于强化学习的多电平变换器中点电压平衡系统的方法,包括以下步骤:
S1:根据实际情况,初步确定基于强化学习的多电平变换器中点电压平衡需求;所述的多电平变换器采用SVPWM调制方式,其中直流侧中点电压的平衡控制基于深度强化学习控制器实时反馈的最优电压调节因子,通过改变开关序列占空比的方式调整流过中点的电荷,实现直流侧电容电压平衡;
S2:建立基于深度强化学习的多电平中点电压平衡控制器的马尔可夫决策过程(Markov Decision Process,MDP),将SVPWM调制过程中每个采样周期内电压调节因子的调节行为映射为基于动作价值迭代更新的强化学习过程,采用MDP和贝尔曼方程对中点电压平衡控制问题进行数学建模,确定算法控制目标、环境状态以及即时奖励,将问题抽象和化简,转化为求取最优价值函数和动作价值函数的问题:
v
q
其中,v
S3:建立Q网络模型,选取深度强化学习DDQN(Double Deep Q Network)算法求取网络参数;所述的DDQN算法为一种off-policy算法,将目标策略和行为策略相分离,避免对中点电压的过度调节;针对动作行为是离散变量的Q-learning方法,通过构建深度神经网络将目标Q值近似表达为Q*(s,a);网络输入为环境状态S
S4:对所建立的DDQN网络参数进行初始化,然后进行从1到T次的迭代寻优,求解出实现预期目标的最优网络参数,确定满足系统需求的最优电压调节因子;
S5:将所述的最优电压调节因子反馈给SVPWM调制策略,从而实现多电平变换器中点电压的有效平衡控制。
与现有技术相比,本发明具有以下优点:
1)本发明电压平衡效果好,调节响应速度快;
2)本发明根据电压的偏移方向、偏移程度和偏移时间,通过不断采用行动和获得反馈,能够学习并迭代寻优出最佳的电压调节行为;
3)本发明算法的鲁棒性好,能够根据环境的变化而做出实时的调整和反馈,能够有效应对如由于负载变化或电源扰动导致的中点电压不平衡;
4)本发明控制策略可以嵌入在DSP模块或上位机环境中,无需增加额外的硬件设备,有效节约成本;
5)本发明有效降低了输出电压和电流的谐波含量;
6)本发明避免过度调节,有效降低开关损耗;
7)本发明算法的通用性好,迁移性强,适用不同电平等级和拓扑结构的中点钳位型多电平变换器;
8)本发明中点电压平衡算法的复杂度不会随着调制策略的复杂度的增加而增加,因此适合解决电平等级较高、拓扑结构复杂的多电平变换器的中点电压平衡问题。
附图说明
图1为本发明中系统模块图;
图2为本发明中系统框架图;
图3(a)为单相三电平NPC变换器模块的示意图;
图3(b)为单相三电平T型变换器模块的示意图;
图4(a)为单相五电平NNPP变换器模块的示意图;
图4(b)为单相五电平ANPC变换器模块的示意图;
图5为深度强化学习控制器子模块图;
图6为本发明中基于深度强化学习的中点电压平衡控制流程图;
图7为深度强化学习控制器工作原理示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
深度学习(Deep Learning,DL)是机器学习领域一种基于对数据进行表征学习的方法,主要使用深度神经网络为工具,通过非线性变换对多层网络结构进行处理,将低层特征进行组合并形成易于区分的高层特征表示,从而用简单模型完成复杂的学习任务。强化学习(Reinforcement Learning,RL)是机器学习领域的方法论之一,其基本思想是代理(Agent)在与环境(Environment)的交互过程中,通过采取行动(Action)不断改变状态(State),并获得环境给予的反馈,即奖励(Reward)或惩罚,从而逐步形成获取最大化预期利益的习惯性行为。将DL的感知能力与RL的决策能力进行了创造性结合,形成了深度强化学习DRL,从原始输入到输出,DRL实现了代理端对端(end-to-end)的直接控制,是具有很强通用性的感知控制系统,能够解决具有高维度原始数据的复杂决策控制任务。
深度强化学习方法能够在无模型、无前期知识积累的情况下,在与环境的交互过程中获得反馈实现自我迭代、自我更新,进而实现控制性能的不断提升,是拥有良好应用前景的真正的智能控制方法。将DRL应用于基于强化学习的多电平变换器中点电压平衡,是DRL在工程领域的一项创新型应用。DRL的应用能够有效适应不同环境及变化,根据环境反馈不断更新最优控制策略参数,有助于实现快速、自适应、强鲁棒性的中点电压控制策略。
在本实施例中,如图1所示,本发明提供的一种基于深度强化学习的多电平变换器中点电压平衡系统,包括输入模块、多电平变换器模块、电压电流检测模块、DRL-NPVC模块、主控制模块、人机交互模块以及辅助模块。
所述的输入模块为相对独立的供电网络,如图2所示,交流电网通过整流和滤波后转化为直流电,与多电平变换器模块相连接,作为电源给所述的多电平变换器模块供电。
所述的多电平变换器模块,为各种电平等级和各类拓扑结构的中点钳位型多电平变换器,由输入模块供电,其交流输出端通过滤波器与负载相连。所述的多电平变换器包括但不限于如图3(a)、图3(b)、图4(a)、图4(b)所示的三电平NPC变换器、三电平T型变换器、五电平ANPC变换器及五电平NNPP变换器。如图2所示,中点钳位型多电平变换器的直流侧将两电容器串联,并通过钳位两电容中点电位的方式产生多电平。以图4中所示的五电平NNPP变换器为例,ABC三相每一相由12个IGBT/反向二极管以及2个悬浮电容构成,通过钳位中点电压和悬浮电容电压产生五电平,对该变换器的调制不仅需要考虑直流侧电容电压的平衡,同时要考虑悬浮电容电压的平衡,以及电容电压的纹波抑制、可接受的最大总谐波失真等。因此,随着变换器电平等级的提升和拓扑结构复杂度的提升,中点电压平衡控制的难度也随之加大,需要综合考虑以上因素,并实时适应工况和负载的变化。
所述的电压电流检测模块主要由电压及电流传感器构成,与所述的主控制模块中的DSP模块相连,用于实时监测并采样电路信号,获取系统运行状态,电路信号包括但不限于变换器的输出电压及电流、直流侧电容电压及电流、悬浮电容电压及电流等;电路信号经过A/D转换,反馈给部署于DSP模块的多电平变换器调制策略,作为控制信号对多电平变换器的运行状态进行调节。
所述的DRL-NPVC模块,为基于深度强化学习的变换器中点电压平衡控制器,该模块的主要功能基于软件实现,可根据需求,部署在DSP模块或与DSP相连接的上位机中。如图5所示,所述的DRL-NPVC模块包括输入子模块、判断子模块和输出子模块三个部分。以部署在DSP模块中为例,DRL-NPVC将在DSP模块内完成控制策略的迭代寻优,其输入为从A/D采样模块实时获取数字化的电路信号,其判断子模块以多电平变换器为环境,采用行动并获得电路运行状况给予的反馈,不断迭代学习,并判断当前电压平衡控制参数是否为最优参数,若否,则继续进行学习迭代;若是,则将该参数输出,其输出子模块与DSP模块内部属的SVPWM策略相连,将获得的最优电压平衡控制参数反馈给调制策略,实现对多电平的电压控制。
所述的主控制模块基于DSP模块、FPGA模块和功率开关器件驱动模块,用以实现一种多电平PWM调制。多电平变换器控制系统具有驱动数量多的特点,单独的DSP模块难以独立完成调制,加入FPGA到控制系统中对DSP调制进行扩展,共同完成对多电平变换器的驱动调制。
所述的DSP模块负责产生三相多路PWM调制信号并传送至所述的FPGA模块,其运行控制分为三个状态:待机状态、运行状态和故障状态。DSP程序初始化后进入待机状态,等待进行采样、串口通信工作。在采样满足要求并接收到串口通讯传输的指令后,进入正常运行状态,将采样数据进行电参数的转化并后进行软件保护判断。如果出现保护信号,则DSP进入故障状态,发送运行关闭指令给FPGA,将子模块复位。通过串口通信将故障信号发送至上位机并保持故障状态。如果没有保护信号,则DSP继续运行SVPWM调制策略核心算法,并将开关状态控制信号发送给FPGA模块。完成后可通过串口通信控制需要保存和查看的信息。核心程序运行完成后判断是否有关机信号,如果没有则重复上述动作,如果接到关机指令,则关机并进行子模块复位。
所述的FPGA模块与DSP模块和IGBT驱动模块相连,其主要功能是根据DSP产生的各路信号的电平状态,输出多路功率器件的PWM驱动信号,对多电平变换器的高频开关进行控制。FPGA根据窄脉冲进行滤波,避免功率器件频繁开断,并根据功率器件调制信号的上升沿下降沿计算叠加时长进行死区控制。
所述的IGBT驱动模块接收FPGA模块发出的控制指令,与多电平变换器模块相连,用于控制电路中的高频开关器件。
所述的人机交互模块与DSP模块相连,包括上位机、显示屏幕以及串口通信设备等,用于实现人机交互。所述的DRL-NPVC为软件模块,可部署在上位机系统中,并在上位机系统中实现算法的迭代寻优过程,并将获得的最佳电压调节参数,返还给DSP模块中的SVPWM算法,优化多电平变换器的调制策略。
本发明提供的所述的基于深度强化学习的多电平中点电压平衡方法,如图6、图7所示,包括如下步骤:
步骤1:确定系统调制需求,即控制目标。利用电压调节因子的数值变换来抑制变换器中点电压波动并提高系统稳定性,其控制目标为:
Minimize|ΔVdc/Vdc|
S.t.Thd<δ
其中,SLR为开关损耗率Switching Loss Rate,其中δ和
步骤2:采用基于g/h坐标系的七段式空间矢量脉宽调制策略对多电平变换器进行调制。在g/h坐标系下,对于任意给定的参考电压矢量U
步骤3:对于任意的空间参考电压矢量U
步骤4:根据中性点电压的平衡情况,引入电压调节因子λ,通过重新分配作用时间T
步骤5:多电平变换器的中点电压平衡问题满足离散事件动态系统状态的描述,且电压状态在未来的演变不以过去的演变和状态表达为必要条件,因此该问题满足马尔可夫过程,我们采用马尔可夫模型对该问题进行数学描述。
步骤6:确定强化学习的基本要素,包括t时刻环境的状态S
步骤7:将调制过程中电压调节因子的调节行为映射为基于价值函数或动作价值函数迭代更新的强化学习过程,采用马尔可夫决策过程和贝尔曼方程描述价值函数和动作价值函数:
v
q
步骤8:建立Q网络模型。采用DDQN算法搭建电压平衡问题的模型网络并求解网络参数。其中,算法的输入包括:迭代次数T、采取的动作集合A、步长α,奖励衰减因子γ,探索概率ε,当前网络Q,目标网络Q',梯度下降样本数m;算法的输出为Q网络参数。
步骤9:随机初始化所有的状态和动作对应的价值v
步骤10:开始进行从1到T的迭代。
步骤10.1:用ε-greedy法选出当前网络Q中最大Q值对应的动作a
步骤10.2:在状态S执行当前电压平衡控制动作,得到新状态S′对应的特征向量φ(S')、奖励R′,是否终止状态END;将{A,R,φ(S),φ(S'),END}五个元素存入经验回放集合ER。
步骤10.3:更新当前环境状态S=S'。
步骤10.4:从经验回放集合ER中采样m个样本{φ(S
步骤10.5:更新当前Q网络的所有参数ω;经过一定的时间间隔,更新目标网络Q'的网络参数ω'=ω。
步骤10.6:如果S'是终止状态,当前轮迭代完毕,否则回到步骤11继续执行。
步骤11:将获取的最优Q网络参数反馈给SVPWM调制策略进行电压调节,从而实现多电平变换器中点电压的有效平衡控制。
本发明的有益效果为:
电压调节速度快、平衡效果好;实时性好,控制算法不停地和环境进行交互、迭代循环,直到获得最佳的电压调节行为;鲁棒性好,在任何时刻,对于强化学习算法输入新的训练样本,都可以实时更新网络参数并完善状态,能够根据环境的变化做出实时的调整和反馈,有效应对如由于负载变化或电源扰动导致的中点电压不平衡;基于软件控制,实现灵活,成本低,算法可在DSP模块或人机交互模块中实现,无需增加额外的硬件设备;将当前状态和目标状态网络解耦控制,避免了过度调节带来的电压波动;有效降低了输出电压和电流的谐波含量及开关损耗;算法的通用性好,迁移性强,适用不同电平等级和拓扑结构的多电平变换器;在面对高电平等级、复杂拓扑结构的变换器中点电压控制问题时,算法优越性体现的更加明显。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 基于强化学习的多电平变换器中点电压平衡系统及方法
- 基于混合调制的多电平逆变器中点电压平衡控制方法