一种基于改进随机森林的核电站系统运行趋势预测方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及核电站系统在线运行趋势预测领域,具体为一种基于改进随机森林的核电站系统运行趋势预测方法。
背景技术
在工业领域,安全是重中之重,尤其对于事故多发,危害性较大的核电领域,其安全性尤为重要。运行趋势预测方法运用核电站运行的历史数据,预测核电未来运行趋势,在发生故障前采取相应的措施,可避免事故的进一步恶化。因此研究运行趋势预测方法对于提高核电站的安全性具有重要意义。
目前,核电站有多种方法应用于趋势预测。如:传统统计学时间序列方法(自回归预测法、滑动平均预测法、自回归滑动平均预测法)、灰色预测法、神经网络预测法(如:BP神经网络等)以及一些机器学习预测法(如:支持向量机、随机森林等)。其中灰色预测法与神经网络预测法时应用较为广泛的方法。灰色预测法适合于短期负荷预测,特别是在数据样本缺乏时。神经网络预测法中BP神经网络运用最多,但其对于初始参数依赖性较强容易陷入局部极小值,收敛速度慢,预测效果有待提高。尤其实时预测过程中,每一次预测都需要重新训练,为了避免陷入局部极小需要参数寻优算法进行优化,故需要占用大量资源。随机森林虽然也常用于运行趋势预测但其在多步预测过程中预测精度较差。
发明内容
本发明的目的是为了解决运行趋势预测方法多步预测误差较大的问题的一种基于改进随机森林的核电站系统运行趋势预测方法。
本发明的目的是这样实现的:
一种基于改进随机森林的核电站系统运行趋势预测方法,包括以下步骤:
步骤1:随机森林单步预测步骤;
步骤1.1:根据当前参数的历史数据构造出随机森林模型;
步骤1.2:将下一刻时间戳的数据带入到随机森林中。在决策树中时间戳会根据构建决策树时的规则,从根节点遍历整棵决策树直到叶子节点,并将该叶子节点的值当做该决策树的预测值;
步骤1.3:重复步骤1.2时间戳会遍历每一个决策树,每一棵决策树都会产生一个预测值,将所有预测值的加权平均值,就是最终预测值
步骤2:随机森林多步预测步骤;
时间序列多步预测是根据该参数当前时间以前的历史数据X以及每一步预测的预测值p
步骤2.1:根据步骤1中的随机森林单步预测,预测下一时刻的数据p
步骤2.2:将步骤1.1中预测的数据和历史数据作为新的训练数据[X,...p
步骤2.3:重复步骤1.2和步骤1.3,实现多步预测。
步骤3:多步预测修正;
对曲线斜率进行修正,通过当前时刻数据与下一刻曲线斜率预测下一刻数据:
设当前时间为t,当前时间n个历史数据为:
x={x
将上式中每m个历史数据做最小二乘法,一共可以得到n-m+1个斜率:
k={k
通过上式中斜率k可以计算斜率变化率:
可以通过上式中斜率变化率
设随机森林未来n步预测结果为:
X={x
斜率预测未来n步预测结果为:
Y={y
随机森林随着预测步数的增加其准确性越差,其结果对应的加权权值随之减小,经实验验证其权值范围为:[0.7,0.3],相应的斜率预测权值变化范围为:[0.3,0.7]。故对于n步预测随机森林每一步对应的权值按线性划分为:
w={0.7,...,n·(0.7-0.3)/15,...,0.3}
相应的斜率预测权值变化范围为1-w,最终预测结果为:
res={x
与现有技术相比,本发明的有益效果是:
本发明所用的随机森林方法在单步预测预测较为准确,但在多步预测效果较差,这是由于随机森林在预测时虽然能够预测曲线的变化趋势,但由于对于数据变化不敏感,当数据增加或减小变缓时其误差可能变大,而斜率预测考虑到短时间内斜率的变化,对数据短时间内的变化较为敏感,故可以通过随机森林预测与斜率预测加权平均的方式来进行预测,这种方法能够有效地提高多步预测的精确度,提高了随机森林多步预测的可用性。
附图说明
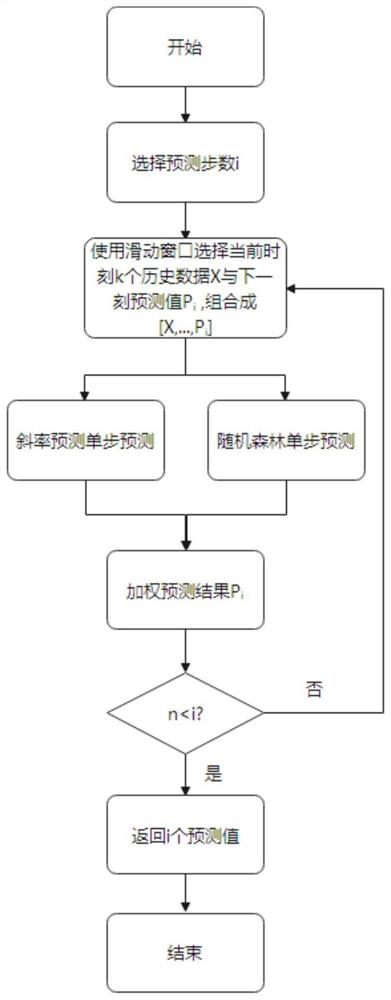
图1为本发明改进随机森林预测流程图;
图2为本发明的改进随机森林单步运行趋势预测图;
图3为本发明改进随机森林多步运行趋势预测图;
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述。
本发明实现包括以下步骤:
步骤1:随机森林单步预测步骤
时间序列单步预测是根据该参数当前时间以前的历史数据预测该参数下一时刻的数据,步骤如下:
1)根据当前参数的历史数据构造出随机森林模型。
2)将下一刻时间戳的数据带入到随机森林中。在决策树中时间戳会根据构建决策树时的规则,从根节点遍历整棵决策树直到叶子节点,并将该叶子节点的值当做该决策树的预测值。
3)重复步骤2)时间戳会遍历每一个决策树,每一棵决策树都会产生一个预测值,将所有预测值的加权平均值,就是最终预测值。
步骤2:随机森林多步预测步骤
时间序列多步预测是根据该参数当前时间以前的历史数据X以及每一步预测的预测值p
1)根据上文步骤1中的随机森林单步预测,预测下一时刻的数据p
2)将1)中预测的数据和历史数据作为新的训练数据[X,...p
3)重复步骤1),2),实现多步预测。
步骤3:多步预测修正
由于随机森林多步预测数据与实际数据偏差较大,本文采用曲线斜率进行修正。曲线斜率的变化在一定程度上能够反映曲线的变化趋势,如果知道曲线下一刻斜率的变化,通过当前时刻数据与下一刻曲线斜率就可以预测下一刻数据。
设当前时间为t,当前时间n个历史数据为:
x={x
将(3)中每m个历史数据做最小二乘法,一共可以得到n-m+1个斜率:
k={k
通过(4)中斜率k可以计算斜率变化率:
可以通过(5)中斜率变化率
由于随机森林在预测时虽然能够预测曲线的变化趋势,但由于对于数据变化不敏感,当数据增加或减小变缓时其误差可能变大,而斜率预测考虑到短时间内斜率的变化,对数据短时间内的变化较为敏感,故可以通过随机森林预测与斜率预测加权平均的方式来进行预测。
设随机森林未来n步预测结果为:
X={x
斜率预测未来n步预测结果为:
Y={y
随机森林随着预测步数的增加其准确性越差,其结果对应的加权权值随之减小,经实验验证其权值范围为:[0.7,0.3],相应的斜率预测权值变化范围为:[0.3,0.7]。故对于n步预测随机森林每一步对应的权值按线性划分为:
w={0.7,...,n·(0.7-0.3)/15,...,0.3} (7)
相应的斜率预测权值变化范围为1-w,最终预测结果为:
res={x
本发明的程序是以PyCharm为开发平台,采用Python3.6语言编写而成,其主要功能为:
当连接好系统后,输入核电站实时运行数据,使用滑动窗口截取一定长度的历史数据作为训练数据,使用训练数据训练改进随机森林预测模型,然后使用训练好的模型对核电站系统进行运行趋势预测。预测结果与实际运行结果一并显示在图中。
本发明的技术方案如下:
1.使用PCTran仿真软件获取压水堆核电站运行数据,本发明使用蒸汽发生器传热管破裂事故的仿真数据作为验证数据。
2.按照图1所示的流程图构建改进随机森林预测模型,其流程如下:
a.选择需要预测的步数i;
b.使用滑动窗口选择当前k个历史数据X={x
据{x
c.使用b中的训练数据对随机森林与斜率预测进行训练,并输出下一刻预测结果;
d.将c中的随机森林与斜率预测的预测结果加权输出最终预测结果p
f.判断当前预测步数n是否小于i,如果是则返回i个预测值,否则跳转第b步继续预测。
(3)针对(2)的预测流程,如果预测步数i=1为单步预测,其对于蒸汽发生器蒸汽产量预测结果如图2所示。如果i>1为多步预测,以i=15为例其对于蒸汽发生器蒸汽产量结果如图3所示。
- 一种基于改进随机森林的核电站系统运行趋势预测方法
- 基于改进深度随机森林算法的变桨系统故障预测方法