基于文件扫描的文字识别方法、终端及存储装置
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及在文字扫描领域,尤其涉及一种基于文件扫描的文字识别方法、终端及存储装置。
背景技术
当前,计算机输入法主要有五笔输入法、拼音输入法、手写输入法等类型。当我们进行资料收集时,经常需要将大量纸质文档中的文字录入计算机中,如果通过上述几种输入法进行录入,费时又费力。目前,文件扫描是实现文字录入的有效工具。现有技术中,文件扫描通常借助光学字符识别(OCR,Optical Character Recognition)技术,将需要的文字拍摄为图像,然后对图像进行识别,即可实现快速录入。
但是,使用OCR功能进行文字识别后,在输出扫描的文件时存在以下两个缺陷:
1、输出TXT文件时,每次识别只能把单词合并成字符串段落,再把段落拼接上换行符,输出到TXT文件中。这种方法,只能获得文字内容,而丢失文字中字体大小、段落缩进、段落行高以及段落之间的间距,无法完整复原原有文档排版结构。
2.输出PDF文件时,每次识别只能把单词对应的区域内容填充为背景颜色,再把每个单词文本根据区域大小填充到区域内,最后输出到PDF文件。这种方法没有把文本合并为完整段落,实际是独立的文字行,不能执行段落复制。
为了使输出的文档贴近原文档,还需要根据被扫描的文档对输出的文件做进一步编辑,操作繁琐,耗时长,提高了扫描成本。
发明内容
为了克服现有技术的不足,本发明提出一种基于文件扫描的文字识别方法、智能终端以及存储装置,根据字符的位置获取位于同一行、同一段的字符以及行、段落的位置信息,并根据字符的字高获取字符渲染后的字宽,利用该字宽、行宽以及字高对字高进行修正,从而获取文件的排版和段落信息,能够对文稿上的文字位置进行正确识别,并正确还原出文稿的文本段落,还可以按每个段落的位置、行高、字体大小等信息进行排版,无需编辑即可实现对原文档排版结构的保留以及文本段落的获取,操作简单、耗时短,减少了工作量。
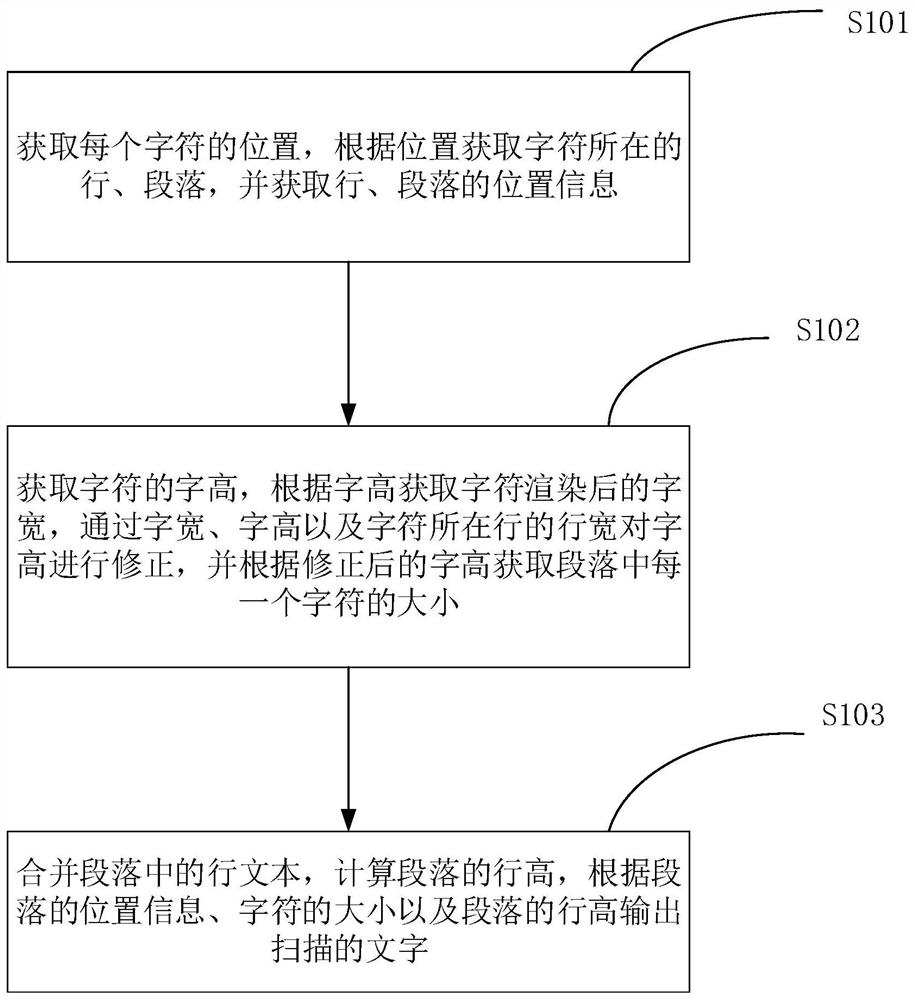
为解决上述问题,本发明采用的一个技术方案为:一种基于文件扫描的文字识别方法,所述基于文件扫描的文字识别方法包括:S101:获取每个字符的位置,根据所述位置获取所述字符所在的行、段落,并获取所述行、段落的位置信息;S102:获取字符的字高,根据所述字高获取所述字符渲染后的字宽,通过所述字宽、字符所在行的宽度以及字高对所述字高进行修正,并根据修正后的字高获取所述段落中每一个字符的大小;S103:合并段落中的行文本,计算所述段落的行高,根据所述段落的位置信息、字符的大小以及段落的行高输出扫描的文字。
进一步地,所述根据所述位置获取所述字符所在的行、段落的步骤具体包括:根据所述位置获取位于同一行/同一段落的字符,根据所述行获取位于同一段落的字符或根据所述段落获取位于同一行的字符。
进一步地,所述根据所述位置获取位于同一行的字符的步骤具体包括:根据所述位置获取所述字符在垂直于行方向上的排序,根据所述排序遍历所述字符,判断所述字符与上一个字符在垂直于行方向上的距离以及高度差是否均小于第一预设值;若是,则确定所述字符与上一个字符位于同一行;若否,则确定所述字符与上一个字符不位于同一行。
进一步地,所述根据所述行获取位于同一段落的字符的步骤具体包括:根据所述行在垂直于行方向上的排序遍历所述行,判断所述行与上一行的在垂直于行方向上的距离以及高度差均满足预设条件;若是,则确定所述行与上一行位于同一段落;若否,则确定所述行与上一行不位于同一段落。
进一步地,所述根据所述字高获取所述字符渲染后的字宽的步骤具体包括:根据所述字高、所述字符对应的字体获取所述字符渲染后的字宽。
进一步地,所述通过所述字宽、字符所在行的行宽以及字高对所述字高进行修正的步骤具体包括:通过公式A=min(lineFontSize*width/contentWidth,lineFontSize)获取修正后的字高,其中,A为修正后的字高,lineFontSize为字高,width为字符所在行的行宽,contentWidth为字符渲染后的字宽。
进一步地,所述合并段落中的行文本的步骤具体包括:根据所述行在垂直于行方向上的排序拼接所述段落中的行文本,在行文本之间插入分隔符,并根据行与段落在行方向的距离差确定所述段落的缩进。
进一步地,所述根据所述段落的位置信息、字符的大小以及段落的行高输出扫描的文字的步骤具体包括:通过输出文件的尺寸获取缩放比例,根据所述段落在垂直于行方向的坐标大小按序合并所述段落形成文本,并基于所述位置信息、字符的大小以及段落的行高将所述文本以缩放比例绘制到输出文件上。
基于相同的发明构思,本发明还提出一种智能终端,智能终端包括:处理器、存储器,所述存储器存储有计算机程序,所述处理器通过所述计算机程序执行如上所述的基于文件扫描的文字识别方法。
基于相同的发明构思,本发明又提出一种存储装置,存储装置存储有程序数据,所述程序数据被用于执行如上所述的基于文件扫描的文字识别方法。
相比现有技术,本发明的有益效果在于:根据字符的位置获取位于同一行、同一段的字符以及行、段落的位置信息,并根据字符的字高获取字符渲染后的字宽,利用该字宽、行宽以及字高对字高进行修正,进而获取段落中字符的大小、行高,从而获取文件的排版和段落信息,能够对文稿上的文字位置进行正确识别,并正确还原出文稿的文本段落,还可以按每个段落的位置、行高、字体大小等信息进行排版,无需编辑即可实现对原文档排版结构的保留以及文本段落的获取,操作简单、耗时短,减少了工作量。
附图说明
图1为本发明基于文件扫描的文字识别方法一实施例的流程图;
图2为未使用本发明基于文件扫描的文字识别方法输出的文件一实施例的示意图;
图3为使用本发明基于文件扫描的文字识别方法输出的文件一实施例的示意图;
图4为本智能终端一实施例的结构图;
图5为本发明存储装置一实施例的结构图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
本文中术语“包括”,“包含”或其任何其他变体旨在覆盖非排他性包括,使得包括步骤列表的过程或方法不仅包括那些步骤,而且可以包括未明确列出或此类过程或方法固有的其他步骤。同样,在没有更多限制的情况下,以“包含...一个”开头的一个或多个设备或子系统,元素或结构或组件也不会没有更多限制,排除存在其他设备或其他子系统或其他元素或其他结构或其他组件或其他设备或其他子系统或其他元素或其他结构或其他组件。在整个说明书中,短语“在一个实施例中”,“在另一个实施例中”的出现和类似的语言可以但不一定都指相同的实施例。
除非另有定义,否则本文中使用的所有技术和科学术语具有与本发明所在领域的普通技术人员通常所理解的相同含义。
请参阅图1-3,图1为本发明基于文件扫描的文字识别方法一实施例的流程图;图2为未使用本发明基于文件扫描的文字识别方法输出的文件一实施例的示意图;图3为使用本发明基于文件扫描的文字识别方法输出的文件一实施例的示意图。结合图1-3对本发明基于文件扫描的文字识别方法进行详细说明。
在本实施例中,基于文件扫描的文字识别方法包括:
S101:获取每个字符的位置,根据位置获取字符所在的行、段落,并获取所述行、段落的位置信息。
在本实施例中,执行该基于文件扫描的文字识别方法的设备可以为电脑、服务器、云平台、扫描仪、扫描笔以及其他能够获取文件的扫描图像,并根据该扫描图像进行文字排版的智能终端。
在本实施例中,智能终端获取文件的扫描图像,通过文字识别算法识别出文件中每个字符的位置,其中,该字符可以为汉字、英文、公式、字母以及其他在文件中能够形成行、段落的文字。
其中,字符所在的坐标系可以将坐标原点位置放置在扫描图像的四个角落中的任意一个,字符的横坐标、纵坐标为其相对于坐标原点的坐标。
在一个具体的实施例中,智能终端为手机,字符为单词,手机通过文字识别算法识别出每个单词的位置大小,记为(x,y,width,height),其中,x为单词的横坐标,y为单词的纵坐标,width为单词的宽度,height为单词的高。
在本实施例中,根据位置获取位于同一行的字符以及位于同一段落的字符的步骤具体包括:根据位置获取位于同一行/同一段落的字符,根据行获取位于同一段落的字符或根据段落获取位于同一行的字符。
根据位置获取位于同一行的字符的步骤具体包括:根据位置获取字符在垂直于行方向上的排序,根据排序遍历字符,判断字符与上一个字符在垂直于行方向上的距离以及高度差是否均小于第一预设值;若是,则确定字符与上一个字符位于同一行;若否,则确定字符与上一个字符不位于同一行。
在本实施例中,Y轴垂直于行方向,X轴平行于行方向,根据字符在X轴、Y轴上的坐标获取字符所在行以及所在段落。在其他实施例中,X轴也可以垂直于行方向,Y轴平行于行方向,还可以X轴、Y轴均不平行于行方向或垂直于行方向,只需能够获取字符或行在垂直行方向或行方向的位置即可。
在一个具体的实施例中,字符为单词,按单词在y轴上的坐标值y值从小到大的顺序依次遍历每个单词,设其y值与上一个单词的y值相差△y,高度值height值与上一个单词的height值相差△height,若△y和△height均小于height*k(系数k大于0,优选为0.5),则视为同一行。
在本实施例中,确定字符与上一个字符位于同一行的步骤之后还包括:根据字符在行方向上的排序遍历字符,判断字符与上一个字符之间的距离是否大于第二预设值;若是,则将字符与上一个字符划分至不同行;若否,则确定字符与上一个字符位于同一行。
其中,在获取同一行的字符后,还可以先获取每一行的位置信息,再筛选不位于同一行的字符,并根据筛选结果修正每一行的位置信息。
在一个具体的实施例中,智能终端更新行的位置信息,记位置信息为(x,y,width,height),x与y为行中所有单词分别在X轴、Y轴上的最小值,宽度值(即行宽)width为其所有单词的max(x+width)-min(x),高度值height为其所有单词的max(y+height)-min(y)。其中,max(x+width)为行中单词在X轴上最大坐标与该单词的宽度之和,min(x)为行中单词在X轴上最小坐标,max(y+height)为行中单词在Y轴上最大坐标与该单词的高度之和,min(y)为行中单词在Y轴上最小坐标。按行在Y轴上的y值从小到大的顺序依次遍历每一行;对每一行,按单词的x值大小的顺序依次遍历行内的每个单词,记当前单词i左侧为left(i)=x(i),x(i)为单词i在X轴上的坐标,上一个单词j右侧为right(j)=x(j)+width(j),x(j)为单词j在X轴上的坐标,width(j)为单词j的宽度,若left(i)>right(j)+g(系数g范围大于行高height,优选为height*3),则说明单词i与单词j相隔较大,应拆分至不同行。根据拆分后的行更新行的位置信息。
在本实施例中,根据行获取位于同一段落的字符的步骤具体包括:根据行在垂直于行方向上的排序遍历行,判断行与上一行的在垂直于行方向上的距离以及高度差均满足预设条件;若是,则确定行与上一行位于同一段落;若否,则确定行与上一行不位于同一段落。
在一个具体的实施例中,按行在Y轴上的y值从小到大的顺序依次遍历每一行,记其高度值height与上一行的height值中的最小值为h,其y值与上一行的y值相差△y,高度值height值与上一行的height值相差△height,若△y小于h*g且△height小于h*f(系数g大于0,优选值0.7,系数f大于0小于1,优选值0.3),则视为两行位于同一个段落。更新段落的位置信息,记为(x
在上述实施例中,段落的位置信息计算方式与上文行的位置信息计算方式相同,且行及段落的位置识别顺序没有优先级别,即可以先识别行的位置,也可以先识别段落的位置。
S102:获取字符的字高,根据字高获取字符渲染后的字宽,通过字宽、字符所在行的行宽以及字高对字高进行修正,并根据修正后的字高获取段落中每一个字符的大小。
其中,根据每一行的行高计算行中字符的字高(字符的高度)。因系统选用的字体与打印字体不同,以及识别高度与打印内容高度均存在差异,需要在计算字高后对其进行修正。
在本实施例中,根据字高获取字符渲染后的字宽的步骤具体包括:根据字高、字符对应的字体获取字符渲染后的字宽(字符的宽度)。字符对应的字体为系统字体即将要渲染的字体,通过该字体的大小与字高的比例关系确定字符渲染后的字宽。
在本实施例中,通过字宽、字符所在行的行宽以及字高对字高进行修正的步骤具体包括:通过公式A=min(lineFontSize*width/contentWidth,lineFontSize)获取修正后的字高,其中,A为修正后的字高,lineFontSize为字高,width为字符所在行的行宽,contentWidth为字符渲染后的字宽。
在一个具体的实施例中,根据每一行的行高计算行字符大小为lineFontSize=height,height为行高,lineFontSize为字符高度;由于系统选用的字体与打印字体不同,以及识别高度与打印内容高度均存在差异,需矫正一次lineFontSize;矫正的做法是,通过系统字体的大小和lineFontSize的大小比例确定内容渲染后字符的宽度contentWidth,根据字符的宽度和行的宽度width等比例修正lineFontSize=min(lineFontSize*width/contentWidth,lineFontSize);计算段落内行中字符的大小lineFontSize的平均值,该平均值则为段落中字符的高度fontSize。
S103:合并段落中的行文本,计算段落的行高,根据段落的位置信息、字符的大小以及段落的行高输出扫描的文字。
其中,通过段落高度除以段落行数的方式获取段落的行高。
在本实施例中,合并段落中的行文本的步骤具体包括:根据行在垂直于行方向上的排序拼接段落中的行文本,在行文本之间插入分隔符,并根据行与段落在行方向的距离差确定段落的缩进。
具体的,按行在Y轴上的y值从小到大的顺序依次拼接段落内所有的行文本,行文本之间插入”\n”分隔符;根据每一行在X轴上的x值与段落在X轴上的坐标值x值的差值在行文本之前插入对应数目的空格作为缩进。计算段落行高,lineHeight=段落高度值height/段落内行的数目,lineHeight为行高。
在本实施例中,根据段落的位置信息、字符的大小以及段落的行高输出扫描的文字的步骤具体包括:通过输出文件的尺寸获取缩放比例,根据段落在垂直于行方向的坐标大小按序合并段落形成文本,并基于位置信息、字符的大小以及段落的行高将文本以缩放比例绘制到输出文件上。
其中,输出文件的格式可以为PDF、DOC、DOCX以及其他能够用于存储文件的扫描信息的文档。
在一个具体的实施例中,智能终端将扫描的文字排版后以PDF格式输出。其中,将识别图片大小作为PDF文稿大小,按段落在Y轴上的坐标值y值从小到大的顺序依次将每个段落的段落合并文本,并按照其位置信息、字体和行高绘制到底稿对应区域内,最后保存为PDF文件。其中,若输出到指定尺寸,则设置缩放比例scale,段落的数值同比例缩放即可。
在另一个具体的实施例中,智能终端将扫描的文字排版后以DOCX格式输出。假定识别图片为A4纸张大小,图片宽度相对纸张宽度的比例记为scale,按段落在Y轴上的坐标值y值从小到大的顺序依次将每个段落的段落合并文本,并按其字体和行高乘以scale比例绘制到文稿上,最后保存为DOCX文件。
有益效果:本发明基于文件扫描的文字识别方法根据字符的位置获取位于同一行、同一段的字符以及行、段落的位置信息,并根据字符的字高获取字符渲染后的字宽,利用该字宽、行宽以及字高对字高进行修正,从而获取文件的排版和段落信息,能够对文稿上的文字位置进行正确识别,并正确还原出文稿的文本段落,还可以按每个段落的位置、行高、字体大小等信息进行排版,无需编辑即可实现对原文档排版结构的保留以及文本段落的获取,操作简单、耗时短,减少了工作量。
基于相同的发明构思,本发明还提出一种智能终端,请参阅图4,图4为本发明智能终端一实施例的结构图。结合图4对本发明的智能终端进行说明。
在本实施例中,智能终端包括:处理器、存储器,所述存储器存储有计算机程序,所述处理器通过所述计算机程序执行如上述实施例所述的基于文件扫描的文字识别方法。
基于相同的发明构思,本发明又提出一种存储装置,请参阅图5,图5为本发明存储装置一实施例的结构图。结合图5对本发明的存储装置进行说明。
在本实施例中,存储装置存储有程序数据,该程序数据被用于执行如上述实施例所述的基于文件扫描的文字识别方法。
在本发明所提供的实施例中,应该理解到,所揭露的智能终端/存储装置和方法,可以通过其他的方式实现。例如,以上所描述的实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个存储装置,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通讯连接可以是通过一些码,装置或单元的间接耦合或通讯连接,可以是电性,机械或其他的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 基于文件扫描的文字识别方法、终端及存储装置
- 一种文件分类协作机器人及基于其的图像文字识别方法