音频源分离和音频配音
文献发布时间:2023-06-19 18:25:54
技术领域
本公开通常涉及音频处理领域,并且具体地,涉及用于音频个性化的设备、方法和计算机程序。
背景技术
存在大量可用的音频内容,例如,以可从网络下载的光盘(CD)、磁带、音频数据文件的形式,但也以视频的声轨的形式,例如存储在数字视频盘或类似物上等。
通常地,例如对于单信道或立体声设置,在不保留来自已经用于音频内容的产生的原始音频源的原始音频源信号的情况下,音频内容已经与原始音频源信号混合。
然而,存在需要音频内容的再混合或上混合的情况或应用。例如,在音频内容将在具有比音频内容提供的更多可用音频信道的设备上播放的情况下,例如,将在立体声设备上播放的单信道音频内容、将在具有六个音频信道的环绕声设备上播放的立体人声频内容等。在其他情况下,应修正音频源的感知空间位置,或者应修正音频源的感知响度。
尽管通常存在用于重新混合音频内容的技术,但是通常期望改进用于音频个性化的方法和设备。
发明内容
根据第一方面,本公开提供了一种电子设备,该电子设备包括电路,该电路被配置为音频输入信号执行音频源分离,以获得经分离的源,并且基于替换条件对经分离的源执行音频配音,以获得个性化的经分离的源。
根据第二方面,本公开提供了一种方法,包括:对音频输入信号执行音频源分离,以获得经分离的源;并且根据替换条件对经分离的源执行配音,以获得个性化的经分离的源。
根据第三方面,本公开提供了一种包括指令的计算机程序,该指令在处理器上执行时使处理器对音频输入信号执行音频源分离,以获得经分离的源;并且根据替换条件对经分离的源执行配音,以获得个性化的经分离的源。
在从属权利要求、以下的描述和附图中阐述了进一步的方面。
附图说明
参照附图以示例的方式解释实施例,其中:
图1示意性地示出了借助于诸如音乐源分离(MSS)的盲源分离(BSS)混合/再混合音频的一般方法;
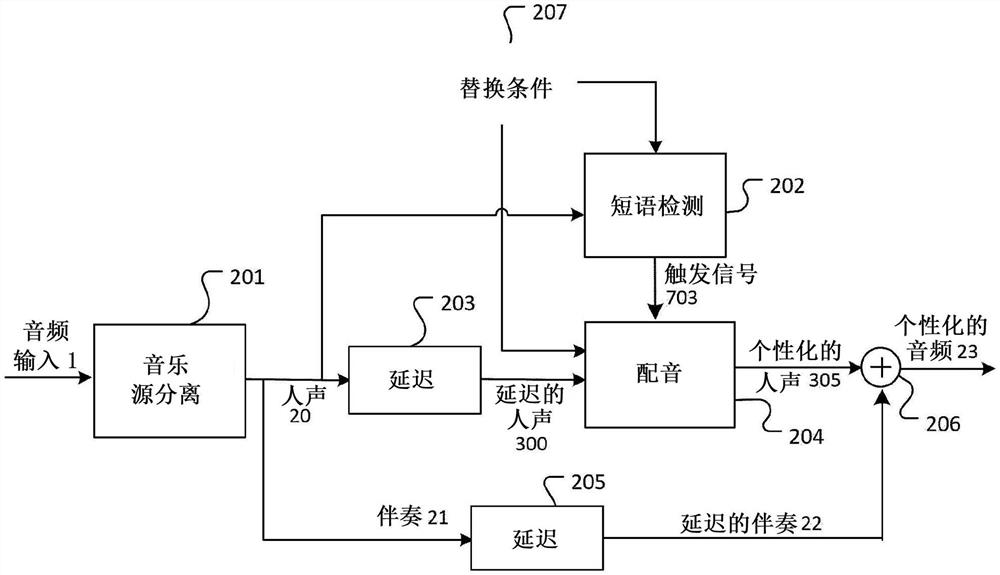
图2示意性地示出了基于音频源分离和配音的音频个性化处理;
图3a更详细地示意性地描述了在图2中描述的音频个性化处理中执行配音处理的实施例;
图3b示意性地示出了在图3a中执行的替换条件输入;
图3c示意性地示出了在图3a中描述的配音处理中执行的替换条件选择的处理;
图4更详细地示意性地描述了在图3a中描述的配音处理中执行的文本到人声处理的实施例;
图5更详细地示意性地描述了在图4中描述的文本到人声的处理中执行的Seq2Seq模型处理的实施例;
图6更详细地示意性地描述了在图4中描述的文本到人声的处理中执行的MelGAN生成器处理的实施例;
图7更详细地示意性地描述了在图2中描述的音频个性化处理中执行的短语检测处理的实施例;
图8示意性地示出了基于音乐源分离和配音的音频个性化处理的另一个实施例;
图9更详细地示意性地描述了在图8中描述的音频个性化处理中执行的内容修改器处理的实施例;
图10示意性地示出了在图9中描述的音频个性化处理中执行的内容修改器802中执行的条件过滤处理;
图11示意性地示出了基于音乐源分离和配音的转录个性化的处理;
图12示出了可视化用于与基于配音和音乐源分离的内容个性化相关的信号混合以获得个性化的内容信号的方法的流程图;以及
图13示意性地描述了可以实现基于配音和音乐源分离的内容个性化处理的电子设备的实施例。
具体实施方式
在详细描述参考图1至图13的实施例之前,进行一些总体说明。
在下文中,术语再混合、上混合和下混合可以指基于源自混合输入音频内容的分离的音频源信号生成输出音频内容的整个处理,而术语“混合”可以指分离的音频源信号的混合。因此,分离的音频源信号的“混合”可以导致输入音频内容的混合音频源的“再混合”、“上混合”或“下混合”。
实施例公开了一种电子设备,包括电路,该电路被配置为对音频输入信号执行音频源分离以获得经分离的源,并且基于替换条件对经分离的源执行音频配音以获得个性化的经分离的源。
电子设备可以例如是任何音乐或电影再现设备,例如智能手机、耳机、电视机、蓝光播放器等。
电子设备的电路可以包括处理器,例如可以是CPU、存储器(RAM、ROM等)、存储器和/或存储器、接口等。电路可以包括或与输入装置(鼠标、键盘、照相机等)、输出装置(显示器(例如液晶、(有机)发光二极管等))、扬声器等、(无线)接口等连接,因为接口通常用于电子设备(计算机、智能手机等)。此外,电路可以包括或与用于感测静止图像或视频图像数据,用于感测环境参数(例如,雷达、湿度、光、温度)等的传感器(图像传感器、照相机传感器、视频传感器等)连接。
在音频源分离中,包括多个源(例如乐器、语音(voice)等)的输入信号被分解成分离。音频源分离可以是无监督的(被称为“盲源分离”,BSS)或部分监督的。“盲”意味着盲源分离不一定具有关于原始源的信息。例如,它可能不一定知道原始信号包含多少个源,或者输入信号的哪个声信息属于哪个原始源。盲源分离的目的是在不知道分离的情况下,对原始信号分离进行分解。盲源分离单元可以使用本领域技术人员已知的任何盲源分离技术。在(盲)源分离中,可以搜索在概率或信息论意义上最小相关或最大独立的源信号,或者基于非负矩阵因式分解,可以找到对音频源信号的结构约束。用于执行(盲)源分离的方法是本领域技术人员已知的,并且基于例如主成分分析、奇异值分解、(不)相关成分分析、非负矩阵分解、人工神经网络等。
尽管一些实施例使用盲源分离来生成分离的音频源信号,但是本公开不限于其中没有进一步的信息用于分离的音频源信号的实施例,而是在一些实施例中,进一步的信息用于生成分离的音频源信号。这种进一步的信息可以是例如关于混合处理的信息、关于包括在输入音频内容中的音频源的类型的信息、关于包括在输入音频内容中的音频源的空间位置的信息等。
输入信号可以是任何类型的音频信号。它可以是模拟信号、数字信号的形式,它可以来源于光盘、数字视频盘等,它可以是数据文件,例如wave文件、mp3文件等,并且本公开不限于输入音频内容的特定格式。输入音频内容可以例如是具有第一信道输入音频信号和第二信道输入音频信号的立体人声频信号,本公开不限于具有两个音频信道的输入音频内容。在其他实施例中,输入音频内容可以包括任何数量的信道,例如5.1音频信号的再混合等。
输入信号可以包括一个或多个源信号。具体地,输入信号可以包括几个音频源。音频源可以是产生声波的任何实体,例如乐器、语音、人声、人工生成声,例如源自合成器等。
输入音频内容可以表示或包括混合音频源,这意味着声信息对于输入音频内容的所有音频源不是分离可用的,但是对于不同音频源的声信息,例如至少部分重叠或混合。
电路可以被配置为基于至少一个过滤的经分离的源和基于通过盲源分离获得的其他经分离的源来执行再混合或上混合,以获得再混合或上混合信号。再混合或上混合可以被配置为执行经分离的源的再混合或上混合,这里是“人声”和“伴奏”,以产生再混合或上混合信号,该信号可以被发送到扬声器系统。再混合或上混合还可以被配置为执行一个或多个经分离的源的歌词替换,以产生再混合或上混合信号,该信号可以被发送到扬声器系统的一个或多个输出信道。
电子设备的电路可以例如被配置为对经分离的源执行歌词识别以获得歌词,并且基于替换条件对歌词执行歌词替换以获得个性化的歌词。
电子设备的电路可以例如被配置为基于经分离的源对个性化的歌词执行文本到人声合成,以获得个性化的经分离的源。
电子设备的电路可以例如被配置为基于经分离的源对个性化的歌词应用序列到序列模型(Seq2Seq模型)以获得Mel频谱图,并且应用生成模型(例如,MelGAN)以获得个性化的经分离的源。
电子设备的电路可以例如被配置为对音频输入信号执行源分离以获得经分离的源和残留信号,并且执行混合个性化的经分离的源与残留信号以获得个性化的音频信号。
电子设备的电路可以例如被配置为执行延迟经分离的源以获得延迟的经分离的源,并且其中,该电路还被配置为执行延迟残留信号以获得延迟的经分离的源。
电子设备的电路可以例如被配置为基于触发信号对经分离的源执行音频配音以获得个性化的经分离的源。
电子设备的电路可以例如被配置为基于替换条件对经分离的源执行短语检测以获得触发信号。
电子设备的电路可以例如被配置为对经分离的源执行话语识别以获得转录/歌词。
电子设备的电路可以例如进一步配置为基于替换条件对转录/歌词执行目标短语检测以获得触发信号。
根据一个实施例,经分离的源包括人声并且残留信号包括伴奏。
根据另一个实施例,经分离的源包括话语并且残留信号包括背景噪声。
替换条件可能是年龄相关的替换条件。
本实施例还公开了一种方法,包括:对音频输入信号执行音频源分离以获得经分离的源;根据替换条件对经分离的源执行配音以获得个性化的经分离的源。
这些实施例还公开了一种包括指令的计算机程序,这些指令使得在处理器上执行指令时处理器执行这里公开的处理。
现在参照附图描述实施例。
通过音频源分离的音频再混合/上混合
图1示意性地示出了借助于诸如音乐源分离(MSS)的盲源分离(BSS)的音频上混合/再混合的一般方法。
首先,执行源分离(也称为“去混合”),其分解包括多个信道I的源音频信号1和从多个音频源(源1、源2、…源K(例如,乐器、语音等))分成“分离(seperation)”的音频,这里分成每个信道i的源估计2a至2d,其中K是整数,表示音频源的数量。在此处的实施例中,源音频信号1是具有两个信道i=1和i=2的立体声信号。由于音频源信号的分离可能是不完美的,例如,由于音频源的混合,除了分离的音频源信号2a至2d之外,还产生残留信号3(r(n))。残留信号可以例如表示输入音频内容与所有分离的音频源信号的总和之间的差异。由每个音频源发射的音频信号在输入音频内容1中由其各自记录的声波表示。对于具有多于一个音频信道的输入音频内容,例如立体声或环绕声输入音频内容,音频源的空间信息也通常由输入音频内容(例如以由包括在不同音频信道中的音频源信号的比例)包括或表示。将输入音频内容1分离成分离的音频源信号2a至2d和残留3是基于盲源分离或其它能够分离音频源的技术来执行的。
在第二步骤中,分离2a至2d和可能的残留3被重新混合并呈现为新的扬声器信号4,这里是包括五个信道4a至4e的信号,即5.0信道系统。基于分离的音频源信号和残留信号,考虑空间信息,通过混合分离的音频源信号和残留信号来产生输出音频内容。在图1中用参考标号4示例性地示出并表示输出音频内容。
在下文中,输入音频内容的音频信道数被称为M
关于上述图1中描述的源分离工艺的技术细节是本领域技术人员已知的。用于执行盲源分离的示例性技术例如在欧洲专利申请EP3201917中公开,或者由Uhlich、Stefan等公开。“Improving music source separation based on deep neural networks throughdata augmentation and network blending.”2017年IEEE声学、话语和信号处理国际会议(ICASSP).IEEE,2017。还存在用于执行盲源分离的编程工具包,诸如Open-Unmix、DEMUCS、Spleeter、Asteriod等,其允许技术人员执行如上面图1描述的源分离处理。
基于源分离和过配音的歌曲个性化
图2示意性地示出了基于音频源分离和配音的音频个性化处理。该处理允许通过组合(在线(online))音频源分离和音频配音来使用源分离和配音来执行音乐个性化。
包含多个源(参见图1中的1,2,…,K)的音频输入信号(参见图1中的1),例如具有多个信道(例如M
类似于延迟203,使用延迟205处理来延迟的伴奏21,以获得延迟的伴奏22。在延迟205处,由于短语检测202处理和由于配音204处理,伴奏21被延迟预期的组合等待时间以获得延迟的伴奏22。混合器206将由配音204获得的个性化的人声305与由延迟205获得的延迟的伴奏22混合以获得个性化的音频信号23。
要注意的是,所有上述处理,即音乐源分离201、短语检测202和配音204,都可以实时地执行,例如具有一些等待时间的“在线”。例如,它们可以直接在用户的智能手机上/耳机中运行。
配音204处理可以例如如在已由Kumar、Kundan等人发表的论文“Melgan:Generative adversarial networks for conditional waveform synthesis.”Advancesin Neural Information Processing Systems.2019中更详细描述的那样实现。下面参照图3a至图6更详细地描述配音204的该示例性处理,包括具有Seq2Seq模型401处理和MelGAN生成器402处理的文本到人声合成处理303处理。下面参照图3a更详细地描述配音204的示例性处理,包括文本到人声合成处理303。
使用图2的处理,可以例如改变歌曲中的歌词(如下面的图3a和图8中所描述的)或电影中的对话(如图11中所描述的),即,使它们个性化。
图3更详细地描述了在上面图2中描述的音频个性化处理中执行的配音处理的实施例,其中,为了获得个性化的人声,对延迟的人声执行配音。
在图3a的该实施例中,基于短语检测202获得的触发信号703,对延迟的人声(这里是人声300)执行配音204的处理以获得个性化的人声305。基于触发信号703对经分离的源20(这里是人声300)执行歌词识别301处理以获得人声300的歌词30。基于替换条件207对歌词30执行歌词替换302处理以获得个性化的歌词400。基于语音300对个性化的歌词400执行文本到人声合成303以获得个性化的人声305。个性化的人声305可以是人声的原始波形。下面参考图4更详细地描述文本到人声合成303的这个处理的实施例。
歌词识别301可以通过诸如自动语音识别(ASR)、计算机话语识别或话语到文本(STT)的任何技术来实现。例如,可以使用隐马尔可夫模型、基于动态时间扭曲(Dynamictime warping)(DTW)的话语识别、诸如深度前馈和递归神经网络的神经网络。
歌词替换302允许个性化的音乐(例如,替换歌词/对话中的名称)或用适合儿童的版本替换露骨的语言。以这种方式,可以修改音乐以使得歌词个性化。例如,这样的特征可以被用于创建个性化的爱情歌曲,其中所爱之人的名称被插入作为歌曲中的原始名称。例如,替换条件207可以指示歌词替换302将歌词30中的“安琪”替换为“塔拉”。此外,许多歌曲都有家长指导标签,因为它们包含露骨的语言。因此,这样的歌曲不能让孩子们听。使用图3a的处理,可以用适合儿童的版本替换露骨的语言。由歌词替换302输出的个性化的歌词400可以例如是字素(grapheme)或音素(phoneme)序列。
图3b示意性地示出了在图3a中执行的替换条件输入。歌词替换302(参见图3a)允许通过修改歌曲的歌词以使得音乐个性化(例如,替换歌词/对话中的名称),以便使得歌词个性化。
一个听歌曲的用户想要用他喜欢的名称(这里是名称“塔拉”)替换一个名称(这里是名称“安琪”,它包含在歌曲的歌词30中)。替换条件207是替换条件“由“塔拉”替换“安琪””,其指示歌词替换302将歌词30中的名称“安琪”替换为“塔拉”。这种特征可以例如用于创建个性化的爱情歌曲,其中被爱的人的名称被插入歌曲中的原始名称。
图3c示意性地示出了在图3a中描述的配音处理中执行的替换条件选择处理。许多歌曲具有父母指导标签,因为它们包含露骨的语言,因此这样的歌曲不能被儿童收听。在这种情况下,可以用适合儿童的版本替换露骨的语言。
如图3c的上部和下部之间的箭头所示的条件选择处理,基于用户收听的歌曲的歌词来选择存储在数据库中的替换条件,以获得期望的替换条件。图3c的上部示意性地示出了一个表格,在该表格中,例如在该实施例中的短语1,即“看透”,通过去除露骨的语言而被不同地表述。例如,短语1是一种包含露骨语言的表达,只能由成年人阅读/听到。如图3c所示,存在三种不同的表达方式,即“砍头”、“诅咒”、“杀死”,在这方面不限制于本公开。表达可以是任何想要的表达。基于歌词30中包含的表达以及替换条件,例如“用“短语2”替换“短语1””是适用的。在该实施例中,基于歌词30,短语1“砍头”可以由短语2“致命伤害”替换,短语1“诅咒”可以由短语2“战斗”替换,短语1“杀死”可以由短语2“受伤”替换。
图3c的下部示意性地示出了从上述条件选择处理获得的替换条件。在图3c的实施例中,基于歌词30,所获得的替换条件是将“砍头”替换为“致命伤”。
歌词替换302可以例如实现为正则表达式(regexp)处理器,并且替换条件207可以例如实现为正则表达式(regexp)模式。Aregexp处理器将正则表达式转换成内部表示形式,可以执行该表示形式并与表示被搜索文本的字符串进行匹配。正则表达式是定义搜索模式的字符序列,它在形式语言理论中描述正则语言。字符串搜索算法可以使用Aregexpattern对字符串进行“查找”或“查找并替换”操作,或者进行输入验证,并且匹配目标字符串。例如,匹配任何字符的通配符可用于构造替换条件。例如,正则表达式/([a-z*])\scut\s([a-z]*)’s\shead/加上替换/$1致命伤$2/将翻译文本字符串“柯南进入了房间。他找到了浩克。柯南砍下了浩克的头。”变为“柯南走进房间。他找到了浩克。柯南致命地伤害了浩克。”.
图4更详细地示意性地描述了在上面图3a中描述的配音处理中执行的文本到人声合成处理的实施例,其中基于个性化的歌词(参见图3a)对延迟的人声执行文本到人声合成,以便获得个性化的人声。基于个性化的歌词400,Seq2Seq模型401处理应用于延迟的人声(这里是人声300),以获得人声的Mel频谱图506。下面参考图5更详细地描述Seq2Seq模型401的该处理的实施例。随后,对人声300的Mel频谱图506执行MelGAN生成器402处理以获得个性化的人声305。个性化的人声305可以是人声的原始波形。下面参考图6更详细地描述MelGAN生成器402的该处理的实施例。
在上面图4中描述的实施例中,文本到人声合成303基于个性化的歌词400和经分离的源20(这里是人声300)创建Mel频谱图506,然后,通过将个性化的人声305与延迟的伴奏22混合,将Mel频谱图506转换成个性化的人声305,其可以被插入回音乐(参见图2)。
图5更详细地示意性地描述了在上面图4中描述的文本到人声合成303的处理中执行的这些Seq2seq模型处理401的实施例,其中Seq2Seq模型基于个性化的歌词(参见图4中的400)应用于延迟的人声,以便获得Mel声谱。该Seq2Seq模型401可以例如被实现为将字符嵌入映射到Mel声谱的递归序列到序列特征预测网络。输入到Seq2Seq模型处理401的个性化的歌词400可以例如是输入到合成器500的字素或音素序列,并且人声300在文本到人声合成303处理中被用作说话者的参考波形。
说话者编码器501处理人声300以获得说话者嵌入50,说话者嵌入50是从语音信号(例如这里的人声300)计算的固定维向量。说话者编码器501可以例如由神经网络实现,该神经网络被训练成从人声300生成个性化的人声(参见图3a和图4中的305,如发表的论文Shen,Jonathan等人所述)。“Natural TTS synthesis by conditioning WaveNeton Mel-Spectrogram predictions.”2018年IEEE声学、话语和信号处理国际会议(ICASSP).IEEE,2018,或者Prenger,Ryan,Rafael Valle,和Bryan Catanzaro的“WaveGlow:A flow-basedgenerative network for speech synthesis.”ICASSP 2019-2019IEEE声学、话语和信号处理国际会议(ICASSP).IEEE,2019。人声300充当说话者的参考波形,该参考波形是目标TTS说话者的音频数据,其由说话者编码器502映射到描述说话者特征(例如男性、女性等)的固定长度向量,例如说话者嵌入向量。
基于由说话者编码器501获得的个性化的歌词400和说话者嵌入50,执行诸如合成器500的序列到序列合成器的处理,以获得个性化的歌词400的Mel频谱图506。具体地,个性化的歌词400被输入到合成器500的编码器502。个性化的歌词400由编码器502编码以获得个性化的歌词嵌入向量。编码的个性化的歌词嵌入向量在每个时间步长与由说话者编码器501获得的峰值嵌入向量合并(concat)。合并的个性化的歌词被传递到合成器500的注意(Attention)504层,其基于具有注意的编码器-解码器架构来实现,例如合成器500的编码器502、解码器505和注意504。注意图5的合成器500的编码器-解码器体系结构可以例如如上面引用的参考文献Shen,Jonathan等人所描述的那样实现。例如,编码器可以将字符序列转换成隐藏的特征再现,解码器使用该特征再现来预测频谱图。例如,输入字符可以使用学习的512维字符嵌入来表示,该字符嵌入通过三个卷积层的堆栈来生成编码特征。编码器输出由注意网络消耗,该注意网络将完整的编码序列总结为每个解码器输出步骤的固定长度上下文向量。解码器是一个自回归递归神经网络,它一次一帧地从编码的输入序列预测Mel频谱图。以这种方式,由具有注意504编码器502-解码器505架构产生Mel频谱图506。该Mel频谱图506根据表征人声300的说话者嵌入矢量50进行调节。也就是说,说话者编码器502用于根据所需目标说话者的参考话语信号(这里是人声300)来调节合成器500。
如图5的实施例所述,实现合成器500中的注意机制(参见图5中的502、504、505)。解码器505决定要注意的源内容的部分,这里是个性化的歌词400。通过让解码器505具有注意504机制,编码器502从必须将源句子中的所有信息编码成固定长度向量的负担中解脱出来。因此,可以在注释序列中散布信息,因此可以由解码器505选择性地检索该注释序列。
在图5的实施例中,为了创建特定人的语音,例如特定歌手的人声,可以替代地执行创建Mel频谱图506的Seq2Seq模型401的调节,如由Jia,Ye等在发表的论文“Transferlearning from speaker verification to multispeaker text-to-speech synthesis.”神经信息处理系统进展,2018中所描述的。
还应该注意,说话者编码器502和合成器500可以是两个独立训练的神经网络。然而,本发明不限于该示例。说话者编码器502和合成器500也可以是一个经过训练的神经网络。
图6更详细地示意性地描述了上述图4中描述的文本到人声合成303的处理中的MelGAN生成器处理402的实施例。MelGAN生成器403应用于由Seq2Seq模型401获得的Mel频谱图506以获得个性化的人声。
Mel频谱图506由卷积层601过滤以获得激活序列,例如特征图。转置卷积层的堆栈(参见图6中的602和603)对激活的输入序列进行上采样。具体地,每个转置卷积层(参见图6中的602和603)包括上采样层,该上采样层之后是具有扩张卷积的残留块的堆栈。转置卷积层603输出激活的输出序列,其由卷积层604过滤以获得个性化的人声305。
例如,可以基于由Kumar,Kundan等人发表的论文“MelGAN:Generativeadversarial networks for conditional waveform synthesis.”神经信息处理系统的进展.2019中描述的MelGAN生成器处理来实现上述MelGAN生成器处理。在该示例中,MelGAN生成器被实现为以Mel频谱图作为输入和原始波形作为输出的全卷积前馈网络。由于Mel频谱图的时间分辨率较低256倍,因此使用转置卷积层堆栈对输入序列进行上采样。每个转置的卷积层之后是一堆具有扩张卷积的残留块。在每个上采样层之后添加具有扩张的残留块,使得每个后续层的时间上远的输出激活具有显著的重叠的输入。一叠扩张卷积层的接受系数随层数呈指数增长。然而,在音频生成实例的情况下,归一化可能会洗掉重要的音高信息,使音频听起来像金属(metallic)。因此,在生成器的所有层中使用权重归一化。
图7更详细地示意性地描述了在上面图2中描述的音频个性化处理中执行的短语检测处理202的实施例。具体地,在人声300上执行话语识别701的处理,以便将人声300转换成文本,从而获得转录/歌词70,例如单词序列。基于替换条件207,对转录/歌词70执行目标短语检测702的处理以获得触发信号703。换句话说,基于替换条件207对转录/歌词70检测目标单词/短语。随后,触发信号703触发配音204(参见图3a),以使用歌手的音频特性,在人声300中将目标单词(例如“名称A”)替换为另一预定词(例如“名称B”)。
目标短语检测702可执行正则表达式匹配,并且在正则表达式模式匹配的情况下,创建触发信号703。即,目标短语检测702可以例如实现为正则表达式处理器,如关于图3c所描述的,并且替换条件207可以例如实现为正则表达式模式。
还应当注意,在替换条件207被实现为正则表达式的情况下,不必在目标短语检测702和歌词替换302中同时发生正则表达式匹配。根据替代实施例,可以仅在目标短语检测702中执行正则表达式匹配,并且歌词替换302实现替换部分。在其他实施例中,歌词替换302和目标短语检测702的功能可以在单个功能单元中执行。在这种情况下,例如,成功的正则表达式匹配(regexp-matching)可以触发相应的替换。
在图7的实施例中,执行短语检测202处理以检测转录/歌词70上的目标单词或目标短语,在这方面不限制本实施例。可以执行短语检测202处理以检测目标内容,目标内容可以是任何种类的文本内容,诸如单词、单词序列(例如短语)等。
使音乐个性化以删除露骨的内容
图8示意性地示出了基于音乐源分离和配音的音频个性化处理的另一个实施例。包含多个源(参见图1中的经分离的源2和残留信号3)的音频输入信号,如上面关于图1所描述的,这里分为经分离的源2,即“人声”20,和残留信号3,即“伴奏”21。人声20,可以是人声音频波形,由内容修改器802处理以获得触发信号703和与听众年龄相关的替换条件。下面参照图9更详细地描述内容修改器802的该处理的实施例。基于替换条件,触发信号703触发要执行的配音处理204,例如使用歌手的音频特征将人声音频波形中的“短语A”替换为“短语B”。与内容修改器802同时,使用延迟203处理来延迟人声20,以获得延迟的人声300。基于触发信号703和由内容修改器802获得的替换条件,对延迟的人声300执行配音204处理,以获得个性化的人声305。参照以上图3a至图6更详细地描述了配音204的处理的实施例。由于内容修改器802的处理需要一些时间,配音204将比实际情况更晚地检测人声20。即,存在人声20的预期的等待时间,例如时间延迟Δt。预期的时间延迟是已知的预定义参数,其可以在延迟203中被设置为预定义参数。
在延迟203处,由于内容修改器802处理,人声被延迟预期的等待时间,以获得延迟的人声300。这具有由内容修改器802处理引起的等待时间由人声20的相应延迟来补偿的效果。与延迟203同时,使用延迟205处理延迟的伴奏21,以获得延迟的伴奏22。在延迟205处,由于内容修改器802处理和配音204处理,伴奏21被延迟预期的延迟,以获得延迟的伴奏22。这具有通过伴奏21的相应延迟来补偿延迟的效果。混合器206将经分离的源20(这里是由配音204获得的个性化的人声300)与由延迟205获得的延迟的伴奏22混合,以获得个性化的音频信号23。
配音204处理可以例如如在已由Kumar、Kundan等人发表的论文“MelGAN:Generative adversarial networks for conditional waveform synthesis.”神经信息处理系统进展.2019中更详细描述的那样实现。要注意的是,所有上述处理,即音乐源分离201、内容修改器802和配音204,都可以实时地执行,例如“在线”。
图9更详细地示意性地描述了在上面图8中描述的音频个性化处理中执行的内容修改器处理的实施例,其中内容修改器基于听众年龄对人声执行,以便获得个性化替换条件和触发信号。基于听众年龄803和基于存储在数据库中的年龄相关替换条件900来执行条件过滤901处理,以获得个性化替换条件902。基于个性化替换条件902,对由音乐源分离201(参见图8)获得的人声300执行短语检测202处理,以获得触发信号703。以上参照图7更详细地描述短语检测202处理的实施例。随后,基于触发信号703和个性化替换条件902执行配音204处理。以上参照图3a至图6更详细地描述配音204处理的实施例。
个性化替换条件902是与替换人声300中的露骨的语言有关的条件,使用预定的语言,例如适合儿童的版本的人声等。另外,个性化替换条件902是与音频的听众的年龄相关的条件,例如需要用另一预定短语替换短语的条件,这是一个适合儿童的短语,如果听众年龄低于某一年龄,例如“柯南砍下了对手的头”改为“柯南伤害了敌人”,因此,触发信号703触发配音204基于个性化替换条件903,例如用“短语2”替换“短语1”,用另一预定内容替换目标内容,例如短语1“柯南砍下了他的对手的头”,例如短语2“柯南致命地伤害了他的对手”。目标内容,这里是短语1,可以是任何种类的文本内容,例如单词、单词序列(例如短语)等。
图10示意性地示出了在上面图9中描述的音频个性化处理中执行的内容修改器802中执行的条件过滤处理,其中基于听众的年龄和替换条件对歌词执行条件过滤以获得个性化替换条件。条件过滤(参见图9中的901)处理,如图10的上部和下部之间的箭头所示,基于听众的年龄(见图9中的803),过滤存储在数据库中的年龄相关的替换条件(见图9中的900),以获得个性化的替换条件(见图9中的902)。图10的上部示意性地示出了一个表格,其中基于听众的年龄组,通过去除露骨的语言,以不同的方式表述短语,例如在该实施例中的短语1,即“柯南砍下了他的对手的头”。例如,短语1是包含露骨的语言的短语,并且应该只在成人之外阅读/听到。如图10所示,存在三个不同的年龄组,即18岁以上和15岁以上的年龄组、15岁和9岁之间的年龄组、以及9岁以下的年龄组,在这方面不限制本公开。年龄组可以是任何期望的年龄组。基于听众的年龄组,替换条件,例如用“短语2”替换“短语1”,是适用的,替换条件在年龄组之间是不同的。在该实施例中,基于18岁至15岁之间的年龄组,短语1“柯南砍下了对手的头”可以替换为短语2“柯南致命地伤害了对手”,基于15岁至9岁之间的年龄组,短语1“柯南砍下了对手的头”可以替换为短语2“柯南与对手战斗”,并且基于9岁以下的年龄组,短语1“柯南砍下了对手的头”可以替换为短语2“柯南伤害了他的敌人”。
图10的下部示意性地示出了从上述条件过滤(参见图9中的901)处理获得的个性化替换条件(参见图9中的902)。在图10的实施例中,所获得的个性化替换条件是基于听众的年龄组,这里的年龄组在15岁和9岁之间“用“柯南与他的对手战斗”来替换“柯南砍下他的对手的头””。
在图10的实施例中,上面描述了基于15岁和9岁之间的年龄组获得的个性化替换条件,而在这方面不限制本公开。可以基于任何合适的年龄和/或年龄组来获得个性化替换条件。此外,关于图10描述的年龄组在这方面不限制本公开,年龄组可以是任何期望的年龄组。
使得电影个性化以删除露骨内容
图11示意性地示出了基于话语增强和配音的转录个性化的处理。包含多个源(参见图1中的1,2,…,K)的电影音频输入信号,例如一段音乐,被输入到话语增强111并被分解成分离(参见图1中的经分离的源2和残留信号3),如上面关于图1所描述的,这里被分解成经分离的源2,即“语音”11,和残留信号3,即“背景噪声”14。话语11由内容修改器802处理以获得触发信号703和与用户年龄相关的替换条件。基于替换条件,触发信号703触发要执行的配音处理204,例如使用说话者的语音特征将“短语A”替换为“短语B”。与内容修改器802同时,使用延迟203处理延迟话语11,以获得延迟话语12。基于触发信号703和由内容修改器802获得的替换条件,对延迟的话语12执行配音204的处理,以获得个性化话语13。参照以上图3a至图6更详细地描述了配音204的该处理的实施例。由于内容修改器802的处理需要一些时间,配音204将比实际情况更晚地检测话语11。即,存在话语11的预期的等待时间,例如时间延迟Δt。预期的时间延迟是已知的预定义参数,其可以在延迟203中设置为预定义参数。
在延迟203,由于内容修改器802处理,话语11被延迟预期的等待时间,以获得延迟的话语12。这具有由于内容修改器802处理引起的等待时间由话语11的相应延迟来补偿的效果。与延迟203同时,使用延迟205处理延迟背景噪声14,以获得延迟的背景噪声15。在延迟205处,由于内容修改器802处理和配音204处理,背景噪声14被延迟预期的等待时间,以获得延迟的背景噪声15。这具有通过背景噪声14的相应延迟来补偿的效果。混合器206将由配音204获得的个性化话语13与由延迟205获得的延迟背景噪声15混合,以获得个性化电影音频16。
在图11的实施例中,对电影音频输入信号执行话语增强111,以获得话语11和背景噪声14。图11的话语增强111处理具有与图1中执行的音乐源分离201处理相同的网络架构,然而,它们的网络是在不同的数据集上训练的。例如,图11中的话语增强111处理的训练材料包含话语和噪声样本。
配音204处理可以例如如在已由Kumar、Kundan等人发表的论文发表的论文“MelGAN:Generative adversarial networks for conditional waveform synthesis.”神经信息处理系统进展.2019中更详细描述的那样实现。要注意的是,所有上述处理,即音乐源分离201、内容修改器802和配音204,都可以实时地执行,例如“在线”。
方法和实现
图12示出了可视化用于与基于配音和音乐源分离的内容个性化相关的信号混合以获得个性化的内容信号的方法的流程图。在1100,音乐源分离(参见201,图2、图8和图10)接收音频输入信号(参见图1中的立体声文件1)。在1101,基于接收的音频输入信号执行音乐源分离(参见201,图2、图8和图11)以获得人声和伴奏(参见图2、图8和图10)。在1102,对人声和伴奏执行延迟以获得延迟的人声和延迟的伴奏(参见203、205,图2、图8和图11)。在1103,由短语检测(参见202,图2、图7、图8和图11)和配音(参见204,图2、图8、图9和图11)接收替换条件。在1104,基于接收的替换条件(见图2和图7中的207)对人声(见图3a和图7中的300)执行短语检测(见图2和图7中的202),以获得触发信号(见图3a和图7中的703)。在1105,基于接收的触发信号(见图3a和图7中的703)和接收的替换条件(见图3a和图7中的207),对延迟的人声(见图3a、图4、图5和图7中的300)进行配音(见图2、图3a、图8和图11中的204),以获得个性化的人声(见图3a、图4和图6中的305)。在1106,执行个性化的人声(见图2、图3a、图4、图6、图8和图11)和延迟的伴奏(见图2、图8和图11)的混合,以获得个性化音频(见图2、图8和图11)。
在图12的实施例中,描述了可视化用于使用短语检测的信号混合的方法的流程图,然而,本公开不限于上述方法步骤。例如,可以对人声执行话语识别处理(参见图8和图11)和内容修改处理(参见图8、图9和图11),而不是短语检测处理等。
图13示意性地描述了可以实现如上所述的基于配音和音乐源分离的内容个性化处理的电子设备的实施例。电子设备1200包括作为处理器的CPU 1201。电子设备1200还包括连接到处理器1201的麦克风阵列1210、扬声器阵列1211和卷积神经网络单元1220。处理器1201可以例如实现短语检测202、配音204、话语识别701、内容修改器802和/或延迟203和205,其实现关于图2、图3a、图7、图8、图9和图10更详细描述的处理。CNN 1220可以例如是硬件中的人工神经网络,例如GPU上的神经网络或专门用于实现人工神经网络的任何其他硬件。CNN 1220可以例如实现源分离201和/或Seq2Seq模型401,Seq2Seq模型401包括编码器502至解码器505和注意504架构,编码器502至解码器505更详细地实现关于图2、图4和图5描述的处理。扬声器阵列1211由分布在预定义空间上的一个或多个扬声器组成,并且被配置为呈现任何种类的音频,例如3D音频。电子设备1200还包括连接到处理器1201的用户界面1212。该用户接口1212充当人机接口,并且使得管理员和电子系统之间能够对话。例如,管理员可以使用该用户界面1212对系统进行配置。电子设备1200还包括以太网接口1221、蓝牙接口1204和WLAN接口1205。这些单元1204、1205充当用于与外部设备进行数据通信的I/O接口。例如,具有以太网、WLAN或蓝牙连接的附加扬声器、麦克风和摄像机可以经由这些接口1221、1204和1205耦合到处理器1201。电子设备1200还包括数据存储器1202和数据存储器1203(这里是RAM)。数据存储器1203被布置成临时存储或高速缓存用于由处理器1201处理的数据或计算机指令。数据存储器1202被布置为长期存储器,例如用于记录从麦克风阵列1210获得并提供给CNN 1220或从CNN 1220检索的传感器数据。
应该注意的是,上面的描述只是一个示例配置。替代配置可以用附加的或其他的传感器、存储设备、接口等来实现。
***
应当认识到,实施例描述了具有方法步骤的示例性排序的方法。然而,方法步骤的具体顺序仅用于说明目的,不应被解释为具有约束力。
还应当注意,将图13的电子设备划分为单元仅是为了说明的目的,并且本公开不限于在特定单元中的任何特定功能划分。例如,至少部分电路可以由分别编程的处理器、现场可编程门阵列(FPGA)、专用电路等。
如果没有另外说明,本说明书中描述的和在所附权利要求中要求保护的所有单元和实体可以被实现为集成电路逻辑,例如在芯片上,并且如果没有另外说明,由这些单元和实体提供的功能可以由软件实现。
就使用软件控制的数据处理设备至少部分地实现上述公开的实施例而言,将理解,提供这种软件控制的计算机程序和提供这种计算机程序的传输、存储或其他介质被设想为本公开的方面。
注意,本技术也可以如下所述进行配置。
(1)一种电子设备,包括电路,该电路被配置为对音频输入信号(1)执行音频源分离(201)以获得经分离的源(4;20;11)并基于替换条件(207;902)对经分离的源(4;20;11)执行音频配音(204)以获得个性化的经分离的源(305;13)。
(2)根据(1)的电子设备,其中,电路进一步被配置为对经分离的源(4;20;11)执行歌词识别(301)以获得歌词(30)并且基于替换条件(207;902)对歌词(30)执行歌词替换(302)以获得个性化的歌词(400)。
(3)根据(1)或(2)的电子设备,其中,电路进一步被配置为基于经分离的源(4;20;11)对个性化的歌词(400)执行文本到人声合成(303)以获得个性化的经分离的源(305;13)。
(4)根据(2)或(3)的电子设备,其中,电路进一步被配置为基于经分离的源(4;20;11)将Seq2Seq模型(401)应用于个性化的歌词(400)以获得Mel-频谱图(506),并且对Mel-频谱图(506)应用MelGAN生成器(402)以获得个性化的经分离的源(305)。
(5)根据(1)至(4)中任一项的电子设备,其中,电路进一步被配置为对音频输入信号(1)执行源分离(201)以获得经分离的源(4;20;11)和残留信号(4;21;14),并且执行混合(206)个性化的经分离的源(305;13)与残留信号(4;21;14),以获得个性化的音频信号(23;16)。
(6)根据(1)至(5)中任一项的电子设备,其中,电路进一步被配置为执行延迟(203)经分离的源(4;20;11)以获得延迟的经分离的源(300;12),并且其中,电路进一步被配置为执行延迟(205)残留信号(21;14)以获得延迟的经分离的源(22;15)。
(7)根据(1)至(6)中任一项的电子设备,其中电路进一步被配置为基于触发信号(703)对经分离的源(4;20;11)执行音频配音(204)以获得个性化的经分离的源(305;13)。
(8)根据(7)的电子设备,其中,电路进一步被配置为基于替换条件(207;902)对经分离的源(4;20;11)执行短语检测(202)以获得触发信号(703)。
(9)根据(8)的电子设备,其中,电路进一步被配置为对经分离的源(4;20;11)执行话语识别(701)以获得转录/歌词(70)。
(10)根据(9)的电子设备,其中,电路进一步被配置为基于替换条件(207;902)对转录/歌词(70)执行目标短语检测(702)以获得触发信号(703)。
(11)根据(1)至(10)中任一项的电子设备,其中,经分离的源(4;20;11)包括人声(20),并且残留信号(4;21;14)包括伴奏(22)。
(12)根据(1)至(11)中任一项的电子设备,其中,经分离的源(4;20;11)包括话语(20),并且残留信号(4;21;14)包括背景噪声(22)。
(13)根据(1)或(2)的电子设备,其中,替换条件(207;902)是年龄相关的替换条件(900)。
(14)根据(1)至(13)中任一项的电子设备,其中,经由用户界面(UI)获得替换条件(207;902)。
(15)根据(1)至(13)中任一项的电子设备,其中,替换条件(207;902)是存储在数据库中的查询表。
(16)根据(5)的电子设备,其中,音频输入信号(1)由麦克风获取。
(17)根据(16)的电子设备,其中,麦克风是诸如智能电话、耳机、电视机、蓝光播放器的设备的麦克风。
(18)根据(5)的电子设备,其中,个性化的音频信号(23;16)被输出至扬声器系统。
(19)一种方法,包括:
对音频输入信号(1)执行音频源分离(201)以获得经分离的源(4;20;11);以及
基于替换条件(207;902)对经分离的源(4;20;11)执行配音(204)以获得个性化的经分离的源(305;13)。
(20)一种包括指令的计算机程序,指令使得当在处理器上执行指令时处理器执行(19)的方法。
- 具有基于迭代加权的源方向确定的音频源分离
- 一种低时延音频信号超定盲源分离方法及分离装置