联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统及介质
文献发布时间:2023-06-19 18:27:32
技术领域
本发明涉及物流领域,具体是联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统及介质。
背景技术
物流供应链是国家和企业竞争的重要驱动力,对经济增长起着至关重要的作用。人工智能赋能下的智慧物流已经成为现代物流发展的必然趋势,因此便捷高效的物流系统受到了人们的广泛关注。
目前,随着现代先进的信息和通信技术(Information and CommunicationTechnology,ICT)的不断发展,工业互联网(Industry Internet of Things,IIoT)已经改变了物流系统的运行模式和体系结构,智慧物流已经成为现代物流发展的必然趋势。
IIoT通过对海量的物流数据和信息进行分析和处理,并结合云计算、大数据、人工智能等先进技术实现物流对象的智能控制。其中,人工智能(Artificial Intelligence,AI)作为一项重要的技术已经应用到智慧物流的多个领域,包括物流运输、仓储、装卸、配送加工、信息服务等,有助于节省时间和成本,极大的提高了物流的运输效率,促进了智慧物流的发展。
随着部署在智慧物流中的传感器节点不断增加,数据量也呈指数增长。然而由于物流车辆的计算和通信资源有限,很难满足智慧物流中计算密集型和时延敏感型的任务的服务质量需求(Quality of Service,QoS)需求。
因此,如何使用人工智能在资源受限的物流车辆上执行计算密集型应用仍面临巨大的挑战。
为了解决上述问题,物流车辆可以通过优化任务卸载,并从其他计算范式中获得协助来减轻传感器节点的负载,如移动边缘计算(Mobile Edge Computing,MEC)通过将边缘服务器放在离车辆更近的地方,将计算转移到靠近车辆的网络边缘,以提供比车辆高得多的计算能力,可以获得更低的通信时延。此外,多级协同任务卸载也常被考虑,多级协同任务卸载通常指不同的协作处理节点共同处理卸载任务,其中包括端-边、边-云和端-边-云协同等。基于应用程序的不同QoS需求,以及不同协作处理节点的应用场景,将时延敏感的计算密集型应用从物流车辆卸载到具有额外计算资源的协作处理节点,在很大程度上弥补了物流车辆计算能力不足的问题。
在以上分析的基础上,如何卸载任务,卸载哪些任务成为需要解决的关键问题之一。IIoT中物流系统的任务卸载问题通常不可避免地涉及到计算和传输资源的分配。因此,这个问题可以很容易地转化为一个有限资源分配问题。
其中,任务建模是探索这一最佳化问题的重要前提。但智慧物流将根据实际的技术和应用进行相应的改变,标识解析为任务提供了实时可追溯环境,多任务之间通常都具有依赖性。因此,上述方法容易造成资源浪费,不符合实际情况。考虑到当前IIoT中物流系统的动态性和异质性,大多数利用一次性优化的传统方法可能无法达到稳定的长期优化性能。
发明内容
本发明的目的是提供联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,包括若干物流车辆、若干助手仓库、若干助手车辆;
所述助手仓库搭载有仓库服务器;
所述物流车辆、助手车辆均搭载有车载服务器;
其中,第m个物流车辆的车载服务器产生任务序列
所述物流车辆的车载服务器存储有时延目标计算模型、能耗目标计算模型、任务卸载与资源分配优化模型、优化模型计算框架;
所述物流车辆的车载服务器分别利用时延目标计算模型、能耗目标计算模型计算任务序列
所述物流车辆的车载服务器将任务序列
所述物流车辆的车载服务器根据卸载策略,在本地执行任务或者将任务卸载到助手车辆或助手仓库的服务器中执行。
进一步,所述任务序列
进一步,所述时延目标T
式中,
进一步,所述仓库服务器利用时延计算模型计算得到的第u个子任务T
式中,α
其中,任务T
式中,
进一步,任务T
式中,车辆o表示执行第m个物流车辆第u-1个子任务的助手车辆;α
其中,任务T
式中,w为物流车辆的带宽;
进一步,能耗目标E
其中,本地计算能量消耗
式中,k代表与车辆服务器的处理器芯片相关的计算能效系数。
进一步,任务卸载与资源分配优化模型min O如下所示:
式中,卸载指示变量α、β、γ为二进制变量;分配计算资源
进一步,建立优化模型计算框架的步骤包括:
1)本地训练Actor网络参数
1.1)将每个物流车辆建模为一个DDPG智能体,包括Actor网络Actor和Critic网络Critic;其中,Actor网络的输入是LV智能体观察物流系统的网络环境得到的本地状态,输出是任务卸载动作;Critic网络将本地状态和选定的动作作为输入,并输出当前状态的估计值;其中,第m个物流车辆的Actor网络参数、Critic网络参数分别表示为
1.2)每隔t周期,使用经验重放策略,通过最小化损失函数
损失函数
式中,
其中,Critic网络生成的目标值
式中,Q'
1.3)计算第m个物流车辆的Actor网络的预期奖励梯度更新量
式中,D
其中,Actor网络的参数
式中,δ为更新系数;
1.4)更新Actor网络参数
式中,τ为权重参数;
2)每个物流车辆智能体将本地训练得到Actor网络参数
其中,第j轮的全局优化模型计算框架权重更新为:
式中,θ
3)所述仓库服务器将聚合的全局模型分发给所有的物流车辆智能体,以更新本地优化模型计算框架。
进一步,所述优化模型计算框架包括状态空间、动作空间和奖励函数;
状态空间存储物流车辆智能体的本地状态S
S
式中,S
所述动作空间存储任务的卸载策略A
A
式中,K
奖励函数R
式中,O
进一步,所述物流车辆集合记为
一种计算机可读介质,所述计算机可读介质存储有上述联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统的计算机程序;
所述计算机程序用于生成联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配方案;
所述计算机程序被处理器执行时,实现以下步骤:
1)第m个物流车辆的车载服务器产生任务序列
2)所述物流车辆的车载服务器分别利用时延目标计算模型、能耗目标计算模型计算任务序列
3)所述物流车辆的车载服务器将任务序列
4)所述物流车辆的车载服务器根据卸载策略,在本地执行任务或者将任务卸载到助手车辆或助手仓库的服务器中执行。
本发明的技术效果是毋庸置疑的,本发明面向智慧物流中依赖型的应用程序,考虑任务间的依赖关系,研究端-边协同的动态任务卸载策略,以满足物流车辆对时延和能耗的服务质量需求(Quality of Service,QoS)。首先,对依赖型应用ARCore进行建模,转化为具有线性执行序列的模型。其次,使用ARCore模型,建立任务卸载和资源分配的联合优化问题,并提出了一种多智能体深度确定性策略梯度(Multi-Agent Deep DeterministicPolicy Gradient,MADDPG)的任务卸载策略,其目标是保证每辆携带任务的物流车辆在满足QoS的情况下最小化时延和能耗的系统总成本。最后,为了降低多智能体训练过程的计算复杂性和信令开销,设计了一个联邦学习辅助MADDPG学习架构,只需要每个智能体共享其模型参数,而不需要共享本地训练数据。数值结果表明,与基准策略相比,所提策略在系统总成本方面具有明显的优越性,其时延和能耗的系统平均成本至少降低了9.63%。
为了满足IIoT中依赖型应用在时延和能耗方面的差异化需求,任务卸载策略的设计应该将物流车辆的QoS需求、应用的内部依赖结构、各级计算范式的优劣势相结合,对任务卸载决策和各级计算资源进行联合管理和分配,进而将任务与协作处理节点相关联,本发明提出一种面向依赖型应用的智能协同卸载策略,该策略首先将具有依赖约束的计算密集型应用卸载到端-边协同的计算架构,并把该任务卸载问题表述为由时延和能耗组成的系统总成本最小化问题。然后利用多智能体DRL算法根据任务间的依赖关系和端-边各级的计算资源选择协作处理节点和分配计算资源。
本发明主要面向依赖型的物流应用,该应用由几个固定的模块组成,不能进行任意分区。以ARCore应用模型为例,可以分解并建模为具有线性序列执行的任务模型,包含多个模块,当前子模块依赖于前一个子模块的输出。
本发明将智慧物流系统的联合任务卸载和资源分配问题建模为一个多智能体DRL问题,以最小化系统的时延和能耗。提出了一种多智能体深度确定性策略梯度(Multi-Agent Deep Deterministic Policy Gradient,MADDPG)的任务卸载策略,其中物流车辆智能体根据其本地观察独立采取行动,但通过协作探索环境来完善其策略,从而确定任务卸载路径和资源分配,提高系统整体性能。
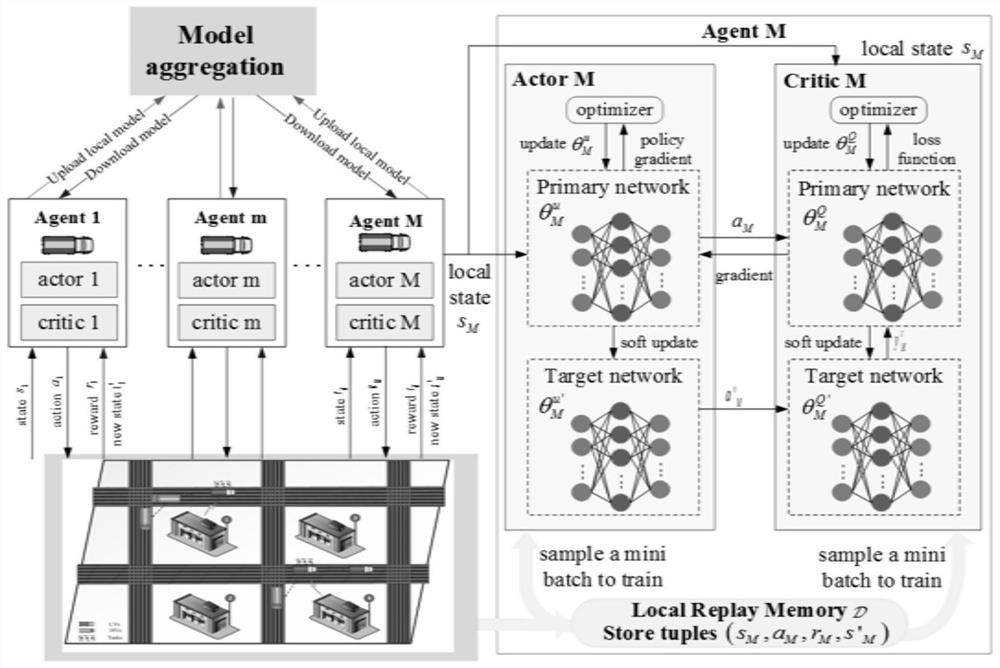
为了降低智能体间交换彼此的本地信息和动作值造成的信令开销,本发明设计了一个联邦学习辅助的多智能体DRL架构,只需要每个任务车辆智能体共享其模型参数到仓库,而不需要共享本地训练数据。
附图说明
图1为系统模型;
图2为任务模型;
图3为单物流车辆任务调度的示例;
图4为F-MADDPG学习框架。
图5为F-MADDPG模型收敛图;
图6为不同任务数据大小的平均成本;
图7为不同物流车辆计算能力下的平均成本;
图8为不同MEC服务器计算能力下的平均成本;
图9为不同物流车辆数量下的平均成本。
具体实施方式
下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。
实施例1:
参见图1至图9,联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,包括若干物流车辆、若干助手仓库、若干助手车辆;
所述助手仓库搭载有仓库服务器;
所述物流车辆、助手车辆均搭载有车载服务器;
其中,第m个物流车辆的车载服务器产生任务序列
所述物流车辆的车载服务器存储有时延目标计算模型、能耗目标计算模型、任务卸载与资源分配优化模型、优化模型计算框架;
所述物流车辆的车载服务器分别利用时延目标计算模型、能耗目标计算模型计算任务序列
所述物流车辆的车载服务器将任务序列
所述物流车辆的车载服务器根据卸载策略,在本地执行任务或者将任务卸载到助手车辆或助手仓库的服务器中执行。
所述任务序列
所述时延目标T
式中,
所述仓库服务器利用时延计算模型计算得到的第u个子任务T
式中,α
其中,任务T
式中,
任务T
式中,车辆o表示执行第m个物流车辆第u-1个子任务的助手车辆;α
其中,任务T
式中,w为物流车辆的带宽;
能耗目标E
其中,本地计算能量消耗
式中,k代表与车辆服务器的处理器芯片相关的计算能效系数。
任务卸载与资源分配优化模型min O如下所示:
式中,卸载指示变量α、β、γ为二进制变量;分配计算资源
建立优化模型计算框架的步骤包括:
1)本地训练Actor网络参数
1.1)将每个物流车辆建模为一个DDPG智能体,包括Actor网络Actor和Critic网络Critic;其中,Actor网络的输入是LV智能体观察物流系统的网络环境得到的本地状态,输出是任务卸载动作;Critic网络将本地状态和选定的动作作为输入,并输出当前状态的估计值;其中,第m个物流车辆的Actor网络参数、Critic网络参数分别表示为
1.2)每隔t周期,使用经验重放策略,通过最小化损失函数
损失函数
式中,
其中,Critic网络生成的目标值
式中,Q'
1.3)计算第m个物流车辆的Actor网络的预期奖励梯度更新量
式中,D
其中,Actor网络的参数
式中,δ为更新系数;
1.4)更新Actor网络参数
式中,τ为权重参数;
2)每个物流车辆智能体将本地训练得到Actor网络参数
其中,第j轮的全局优化模型计算框架权重更新为:
式中,θ
3)所述仓库服务器将聚合的全局模型分发给所有的物流车辆智能体,以更新本地优化模型计算框架。
所述优化模型计算框架包括状态空间、动作空间和奖励函数;
状态空间存储物流车辆智能体的本地状态S
S
式中,S
所述动作空间存储任务的卸载策略A
A
式中,K
奖励函数R
式中,O
所述物流车辆集合记为
一种计算机可读介质,所述计算机可读介质存储有上述联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统的计算机程序;
所述计算机程序用于生成联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配方案;
所述计算机程序被处理器执行时,实现以下步骤:
1)第m个物流车辆的车载服务器产生任务序列
2)所述物流车辆的车载服务器分别利用时延目标计算模型、能耗目标计算模型计算任务序列
3)所述物流车辆的车载服务器将任务序列
4)所述物流车辆的车载服务器根据卸载策略,在本地执行任务或者将任务卸载到助手车辆或助手仓库的服务器中执行。
实施例2:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,包括若干物流车辆、若干助手仓库、若干助手车辆;
所述助手仓库搭载有仓库服务器;
所述物流车辆、助手车辆均搭载有车载服务器;
其中,第m个物流车辆的车载服务器产生任务序列
所述物流车辆的车载服务器存储有时延目标计算模型、能耗目标计算模型、任务卸载与资源分配优化模型、优化模型计算框架;
所述物流车辆的车载服务器分别利用时延目标计算模型、能耗目标计算模型计算任务序列
所述物流车辆的车载服务器将任务序列
所述物流车辆的车载服务器根据卸载策略,在本地执行任务或者将任务卸载到助手车辆或助手仓库的服务器中执行。
实施例3:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,所述任务序列
实施例4:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,所述时延目标T
式中,
实施例5:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,所述仓库服务器利用时延计算模型计算得到的第u个子任务T
式中,α
其中,任务T
式中,
实施例6:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,任务T
式中,车辆o表示是执行第m个物流车辆第u-1个子任务的助手车辆;
其中,任务T
式中,w为物流车辆的带宽;
实施例7:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,能耗目标E
其中,本地计算能量消耗
式中,k代表与车辆服务器的处理器芯片相关的计算能效系数。
实施例8:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,任务卸载与资源分配优化模型如下所示:
式中,卸载指示变量α、β、γ为二进制变量;分配计算资源
实施例9:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,建立优化模型计算框架的步骤包括:
1)本地训练Actor网络参数
1.1)将每个物流车辆建模为一个DDPG智能体,包括Actor网络Actor和Critic网络Critic;其中,Actor网络的输入是LV智能体观察物流系统的网络环境得到的本地状态,输出是任务卸载动作;Critic网络将本地状态和选定的动作作为输入,并输出当前状态的估计值;其中,第m个物流车辆的Actor网络参数、Critic网络参数分别表示为
1.2)每隔t周期,使用经验重放策略,通过最小化损失函数
损失函数
式中,
其中,Critic网络生成的目标值
式中,Q
1.3)计算第m个物流车辆的Actor网络的预期奖励梯度更新量
其中,Actor网络的参数
1.4)更新Actor网络参数
2)每个物流车辆智能体将本地训练得到Actor网络参数
其中,第j轮的全局优化模型计算框架权重更新为:
式中,θ
3)所述仓库服务器将聚合的全局模型分发给所有的物流车辆智能体,以更新本地优化模型计算框架。
实施例10:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,所述优化模型计算框架包括状态空间、动作空间和奖励函数;
状态空间存储物流车辆智能体的本地状态S
S
式中,S
所述动作空间存储任务的卸载策略,即:
A
式中,K
奖励函数R
式中,O
实施例11:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,主要内容见实施例2,其中,所述物流车辆集合记为
实施例12:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统,内容包括:
1网络模型
本实施例考虑封闭式物流园区场景,如图1所示。由物流车辆(LogisticsVehicles,LVs)和物流协作助手组成。其中物流协作助手分为两类,即助手仓库(HelperWarehouses,HWs)和助手车辆(Helper Vehicles,HVs)。HWs和HVs都能同时进行通信和计算操作。一组HWs
2任务模型
与完全卸载应用模型相比,部分卸载应用模型提供了更大的灵活性,可以更好地匹配智慧物流应用场景。一般来说,云服务的应用程序可以分为以下几类:面向数据分区的应用程序、面向代码分区的应用程序、以及连续执行的应用程序。由于复杂的应用程序是由几个固定的组件组成,不能任意分区,因此我们关注面向代码分区的物流应用。近年来,IIoT技术已广泛应用于制造系统,如射频识别(RFID)、无线、移动和传感器设备。本实施例将复杂的应用模块依赖系统简化为线性序列执行模块,如图2所示。以新兴的ARCore应用模型为例,该应用程序可以表示为线性序列执行架构。该应用程序包含多个模块,当前子模块依赖于前一个子模块的输出。此外,本实施例不仅限于ARCore应用,当扩展到具有上述线性序列执行的其它应用时,所提出的模型仍然适用。
如上所述,本实施例将物流应用程序建模为一个由
3时延模型
在图3中,以LVm某一时隙的任务调度为示例,将ARCore应用的5个子任务调度到相应的计算节点进行计算。每个子任务在前一个子任务结束后执行。上一个子任务的执行结果需要传递给下一个子任务。因此任务T
(1)计算时延
假设LVm、HWb和HVn都配备了具有恒定计算能力的处理器,可分别表示为
当任务T
如果车辆m将任务T
因此,任务T
(2)传输时延
为了提高频谱利用率,我们假设物流车辆与助手车辆的链路复用物流车辆与助手仓库链路的频谱资源。本实施例对计算卸载链路进行建模,将路径损耗表示为X
其中,w为服务器分配给物流车辆的带宽,这里假设服务器均匀分配带宽给每辆车;
如果LV m相邻的两个子任务在同一计算节点进行计算,则不需要将前一个子任务的输出发送到另一个节点,此时的传输时延记为0。由于在HW处服务器上计算任务的输出数据大小要比输入数据大小得多,因此,回程连接的时延开销可以忽略。假设LV m的第u-1个子任务到第u个子任务的传输时延为
传输时延分为四种情况,箭头表示任务计算节点的转换,t
Case 1:模块u-1本地处理,模块u在HW b上执行,其传输时延可表示为:
Case 2:模块u-1本地处理,模块u在助手HV n上执行,其传输时延可表示为:
Case3:模块u-1在HV n上执行,模块u在LV m上执行,其传输时延可表示为:
Case4:模块u-1在HV n上执行,模块u在HW b上执行,其传输时延可表示为:
因此,公式(7)中LV m的第u-1个子任务到第u个子任务的传输时延
其中,车辆o表示是LV m的第u-1个子任务的HV。
4能耗模型:
在物流系统中,LV m能量的消耗包括两部分:一是LV m在本地执行任务T
1)本地计算的能耗
已知LV m服务器的计算能力
2)卸载任务的能耗
当LV m卸载到HW b或者HV n上的任务T
当LV m选择将任务T
5问题公式化
在物流系统下,需要同时对系统时延和能耗进行双目标优化。对于LV m的时延目标T
对于LV m的能耗目标E
本实施例旨在解决代码分区的物流应用执行的能量消耗和时延成本之间的权衡。为了构建本实施例的目标函数,引入一个加权因子ω
s.t.
C2:α
其中,约束C1和C2确保一个子任务只能在一个计算节点上进行处理,即本地,或者卸载到一个HW或一辆附近的HV上;C3保证HW的服务器中分配的总计算资源不超过其计算能力;C4保证HV中分配的计算资源必须小于其计算能力;C5确保一个子任务必须在其容忍时延内完成;C6确保表示LV的总能耗不应超过其自身总能量。公式(18)中的优化问题为混合整数非线性规划问题(Mixed Integer Nonlinear Programming,MINLP),其中卸载指示变量α、β、γ为二进制变量,而分配的计算资源
6F-MADDPG任务卸载和资源分配策略
在这一部分,首先对多智能体的环境进行描述,主要定义多智能体的状态空间、动作空间和奖励函数。然后,给出一个F-MADDPG任务卸载和资源分配策略的学习框架,这是实现多智能体模型训练的核心。最后,基于该框架,详细描述了本实施例提出算法的实现步骤。
6.1多智能体环境描述
在本小节中,我们将优化问题(18)使用马尔可夫决策过程(Markov DecisionProcess,MDP)进行描述。然后,根据多用户的MDP公式,采用多智能体强化学习方法来解决MDP问题。在图1所示的智慧物流场景中,每辆LV根据其本地环境和每个时隙的总资源情况来决定其自身的计算卸载和资源分配方案。不同LV的决策是相互影响的,导致不同LV区域性能的紧耦合。因此,可以被建模为一个多智能体强化学习问题,其中每辆LV作为一个智能体并与环境交互以获得经验,以改进其计算卸载和资源分配的策略。考虑引入策略的方法,即深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG),使用双神经网络分别估计动作和Q值。在该场景中,使用MADDPG算法来解决优化问题,该算法是对DDPG算法的改进,以适应多智能体环境。在本实施例描述的系统中,状态空间、动作空间和奖励函数定义如下。
1)状态空间:
状态是智能体观察自身具体和直接的情况。其设置应充分反映物流系统的网络环境,包括物流车辆的任务、计算能力、通信资源和实时位置状态,以及HW的计算能力和实时位置。定义智能体m的本地状态为一个变量集,可表示为:
S
其中S
2)动作空间:
动作是智能体可以做出的所有可能动作的集合。在物流系统中,LVm智能体必须决定任务是在本地执行,还是将任务卸载到哪辆HV或哪个HWS上,并为计算任务分配多少计算资源。复合动作A
A
其中K
3)奖励和惩罚:
奖励是衡量智能体在给定状态下的行为成功或失败的反馈。奖励设置在训练神经网络中起着关键作用。公式(18)的主要目标是最小化系统任务执行时延和能耗的加权和,而奖励函数旨在最大化获得的奖励。因此,奖励应该与目标函数成反比。故本实施例考虑以下为奖励函数:
6.2联邦学习辅助的多智能体学习架构
每个LV智能体根据其本地状态和用户需求独立采取行动,并通过环境的协作探索,细化其任务卸载和资源分配策略,从而提高系统整体的时延和能耗性能。在多智能体环境中,需要关于所有LV智能体的状态和动作的全局信息来训练每个智能体。然而,LV智能体需要交换彼此的本地信息和动作值,这可能会导致大量的信令开销。缺乏训练数据也可能会对每个智能体的精确DRL模型的训练构成重大挑战。为了在低开销的情况下解决这个问题,可以利用分布式联邦学习来提高单个本地DRL模型的训练性能,而不需要集中训练数据。针对上述问题,本实施例提出了一个联邦学习辅助的多智能体深度确定性策略梯度(Federated Multi-Agent Deep Deterministic Policy Gradient,F-MADDPG)框架。如图4所示,F-MADDPG框架主要包括三部分:本地训练、模型聚合和模型下发。本地训练的目的是利用MADDPG的DRL算法推导适合每个智能体自身的本地模型参数。然后,每个智能体将训练好的模型参数上传到服务器,进行模型聚合,生成适合数据训练的全局模型。最后,服务器将聚合好的全局模型下发至每个智能体。
1)本地训练
在图4中,每个LV被建模为一个DDPG智能体,由演员家(Actor)网络和批评家(Critic)网络两部分组成。其中,Actor网络的输入是LV智能体观察物流系统的网络环境得到的本地状态,输出是其选择的动作。而Critic网络将本地状态和选定的动作作为输入,并输出当前状态的估计值。对于LV智能体m,其Actor和Critic网络参数分别表示为
其中,
动作价值函数Q
另一方面,LV智能体m的Actor网络的预期奖励梯度更新由下式给出:
相应地,Actor网络的参数
另一方面,目标网络的参数在每个时间周期由主网络缓慢更新。LV智能体m的Actor目标和Critic目标网络的参数
2)模型聚合
在多智能体的学习场景中,需要交互信息来共享不同智能体的策略。然而,观察空间数据的传输和处理会消耗过多的通信和计算资源。因此,为了克服这些困难,受联邦学习概念的启发,所有的LV智能体共享它们的网络参数并执行联合更新。每个LV智能体通过专用回程控制链路,将其本地模型的参数上传到服务器,以执行模型聚合。具体地说,采用小批量随机梯度下降法进行联合平均,其中第j轮的全局模型权重更新为:
其中θ
6.3 F-MADDPG在线学习算法
根据提出的F-MADDPG学习框架,算法1给出了F-MADDPG的学习算法,包括四个过程:(1)第
1行到第4行是初始化过程;第6行到第11行是探索行为过程,其中智能体选择是随机行为还是遵循动作家网络策略;(2)第12行到第17行是网络的重放训练过程;(3)第18行到第20行周期性的目标网络更新过程;(4)第21行到第23行是联合更新过程。具体见算法1。
实施例13:
联邦多智能体Actor-Critic学习智慧物流任务卸载和资源分配系统的验证实验,内容包括:
该实验的仿真环境基于Python 3.7搭建。智慧物流系统中物流车辆的分布符合泊松分布。各个参数的具体设置如表1所示。为了分析上文所提出的F-MADDPG的任务卸载策略的性能,将该策略与其他任务卸载策略进行了对比,描述如下:
(1)联合计算卸载和任务迁移算法(Joint Computation Offloading and TaskMigrationOptimization,JCOTM):提出多智能体深度Q网络的JCOTM算法,来解决最小化系统时延和能耗的联合优化问题。
(2)多智能体自主学习算法(Multi-agent Separate Learning,MASL):车辆用户智能体是不需要任何协作的独立学习者,其中每个智能体根据自己的观察和与环境的交互学习策略,智能体之间不存在模型共享和信息交换。
(3)全部本地计算策略(All Local Computing Strategy,ALCS):在该策略下,所有用户的计算任务都在其本地车辆上进行计算,即不进行任何计算卸载。用户的任务卸载成本由本地执行任务的计算时延和CPU执行任务所产生设备能耗两部分组成。
(4)随机卸载计算策略(Random Offloading Computing Strategy,ROCS):在该策略中,任务随机在MEC层或本地计算层执行。
(5)完全MEC计算策略(All MEC Computing Strategy,AMCS):在该策略中,车辆用户将所有的任务都卸载到MEC服务器上执行。
表1仿真参数
图5评估了本实施例所提F-MADDPG算法在模型训练过程中的收敛性。仿真设置模型训练过程有1000轮,每轮100个时间步。在图5中,x轴表示训练的轮数,y轴表示智能体训练过程中的累计奖励,即每辆LV关于时延和能耗的总成本。可以看到,经过150轮次迭代后,累计奖励开始平稳并逐渐接近零损耗。因此,F-MADDPG算法模型的训练逐渐收敛,该模型被认为训练完成。
图6比较了物流车辆任务的不同数据量大小对应的成本的变化。如图6所示,随着任务输入数据量的增加,每种卸载策略的总成本都会增加。这是由于任务的数据量越大,计算时延、传输时延以及能量消耗就越大。从图中的比较来看,所提出的F-MADDPG的任务卸载策略所对应的总成本要低于其他策略,这是因为F-MADDPG优化了任务卸载策略,且优化性能要比JCOTM和MASL好。当任务的数据量较小时,物流车辆在本地就可以执行任务,且比将任务都卸载到边缘服务器的成本要低;当任务的数据量越大时,大部分任务会被卸载到边缘服务器上执行,因为边缘服务器丰富的计算资源足以执行这些数据量大的任务。当任务的数据大小从150Kbit增加到200Kbit时,所提F-MADDPG策略的总成本增加了27.74%,而ALCS、AMCS、ROCS、MASL和JCOTM策略的总成本分别至少增加了36.63%、29.65%、26.32%、24.59%和26.31%。这意味着卸载策略的总成本随着网络负载的增加而增加,且F-MADDPG的总成本始终维持在较低水平。
能力提高的变化趋势:可以看出,随着物流车辆的计算能力的增加,完全MEC执行策略的这条曲线对应的总成本保持不变。这是由于物流车辆的计算能力的变化完全不影响完全MEC执行卸载任务的过程。F-MADDPG、JCOTM、MASL、ROCS和AMCS卸载策略的总成本都随着物流车辆计算能力的增大而下降。例如,当物流车辆的计算能力为1.4GHz时,图7中总成本按照由低到高排序分别为612、647、675、802、1176和1242;且当物流车辆的计算能力为1.6GHz时,F-MADDPG、AMCS和ALCS卸载策略完成任务的总成本分别为576、1242、1080。这是因为物流车辆计算能力的增大使得LV有更多的计算资源,从而减少了物流车辆从MEC服务器获得计算资源,并且在物流车辆上执行任务的时延也减小了。较于计算时延来说,物流车辆计算能力的增大对计算能耗的影响相对较小。因此,所提任务卸载策略的总成本呈现下降的趋势。
图8显示了MEC服务器计算能力的大小对物流系统总成本的影响情况。在图8中,本实施例所提出多智能体DDPG的任务卸载策略的总成本比其他卸载策略都低且呈现下降趋势。可以看出,所提策略的总成本随着MEC服务器计算能力的增大而减小。这是因为MEC服务器计算能力的大小可以节省相应卸载任务的执行时延。当MEC服务器的计算能力增加时,MEC服务器可以利用更多的计算资源来执行来自物流车辆卸载的任务,从而使执行卸载任务的速度更快。当MEC服务器的计算能力为20GHz时,所提F-MADDPG策略完成任务的总成本为777,ALCS、AMCS、ROCS、MASL和JCOTM卸载策略的总成本分别为1432、1222、973、847、807,相对应地比较,总成本分别降低了45.74%、36.42%、20.14%、8.26%和3.72%。此外,ALCS策略的曲线不会随着MEC服务器计算能力的增大而改变,这是因为该策略没有使用到边缘服务器的计算能力。在图9中,我们比较了6种卸载策略在不同车辆数量下的平均系统卸载成本。可以看出,各卸载策略的系统成本随着物流车辆数量的增加而逐渐上升。显然,更多的物流车辆意味着处理更多的任务,从而增加时间和能耗成本。从图9可以看出,与其他卸载策略相比,所提F-MADDPG的卸载成本最低,JCOTM的卸载性能次之。另外,MASL的性能优于ROCS,而ROCS的性能优于AMCS和ALCS。此外,当物流车辆数逐渐增加时,全部在本地计算的卸载成本始终大于边缘计算策略,但AMCS的增长速度比ALCS更快,两者的系统平均成本的差距在逐渐减小。原因是当大量的任务被卸载到同一个MEC服务器上时,每个物流车辆可以分配的计算资源会减少,从而导致计算成本的增加。
本实施例研究了智慧物流系统中任务卸载和资源分配的联合优化问题,其中携带时延敏感的依赖型任务的物流车辆是能量受限的。针对这一问题,本专利在保证QoS需求的同时最小化时延和能耗的系统总成本。此外,设计了联邦学习辅助的DRL框架,以减少由于训练过程而引起的计算复杂度和信令开销通过大量的仿真实验,验证了该策略在不同的任务输入数据大小、边缘服务器计算能力和物流车辆数量下的有效性。由于实际生活中的道路场景和交通情况会更加的复杂和多变。
- 一种端边协同环境下联邦学习任务可信卸载系统及方法
- 5G网络中面向多任务联邦学习的资源分配方法及系统