一种网页的核心内容的智能化抽取方法及系统
文献发布时间:2023-06-19 18:27:32
技术领域
本申请涉及计算机视觉领域,尤其涉及一种网页的核心内容的智能化抽取方法及系统。
背景技术
随着互联网的快速发展,无论是企业还是个人,对网页的数据进行监测的需求越来越明显,比如关心舆情的公司希望从各大媒体发布的文章中,抽出核心内容,来及时的监控特定舆情变化;比如关心医院招聘公告的企业,希望从各医院官网的公告中,抽出核心内容,来及时地监控特定的职位变化。
而这些核心内容信息的获取都建立在大规模的网页监测的基础上,由于不同的网页有不同的结构,使得网页有不同的数据抽取规则,因此在抽取数据前需要分别针对不同的网页结构对抽取的脚本进行相应的调整。
现有的技术更多的还是需要人为地去针对不同的网页分别进行相应的抽取配置,当网页数量很多时,会使得人的工作量过大以致于难以在短时间内完成配置,从而实现大规模数据的快速抽取和监控。
发明内容
本申请的目的是提供一种无人工参与的自动化智能抽取和监控服务,对网页的标题、发布时间和核心内容进行大规模快速抽取和监控。
第一方面,本申请提供一种网页的核心内容的智能化抽取方法及系统,采用如下的技术方案:
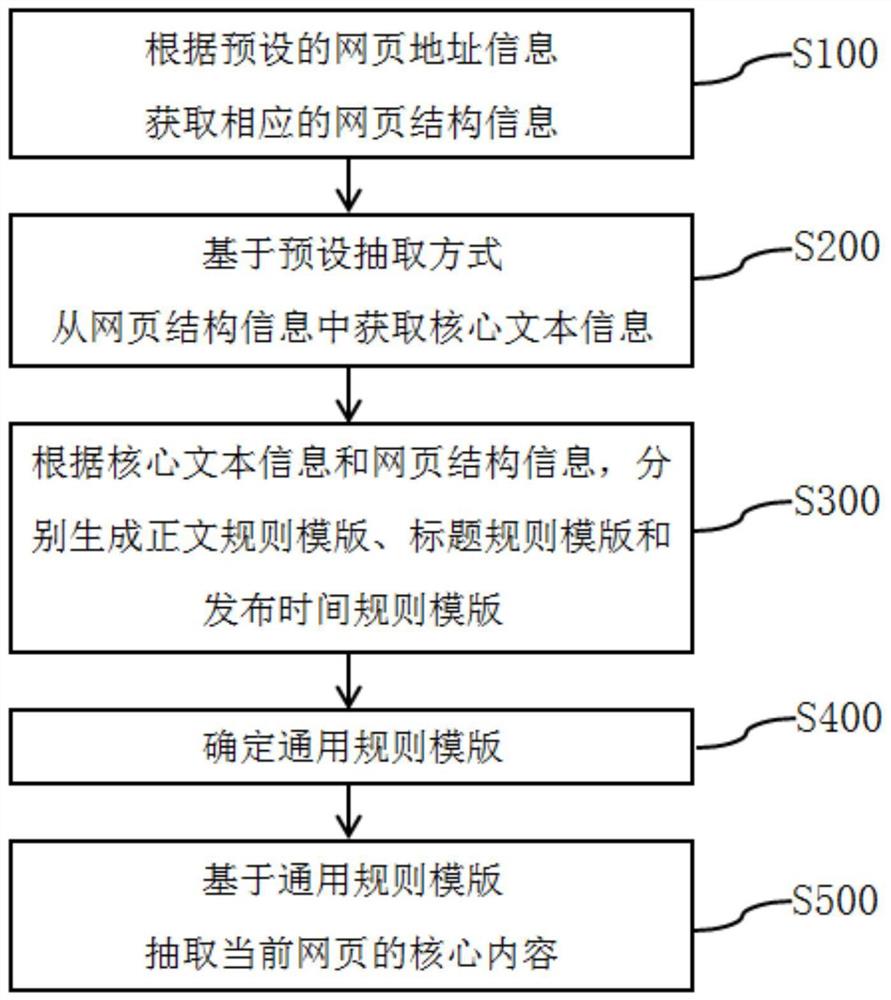
一种网页的核心内容的智能化抽取方法,包括以下步骤:
根据预设的网页地址信息获取相应的网页结构信息;
基于预设抽取方式,从网页结构信息中获取核心文本信息;
根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版;
根据正文规则模版、标题规则模版和发布时间规则模版,确定通用规则模版;
基于通用规则模版,抽取当前网页的核心内容。
通过上述技术方案,可以根据网页地址信息智能化抽取网页的正文、标题和发布时间,并会生成通用的规则模版,通过通用的规则模版可快速的获取同类型网页的核心内容,以实现大规模的网页数据的监控。
可选的,所述基于预设抽取方式,从网页结构信息中获取核心文本信息,包括:
根据网页结构信息,构建DOM树;
计算并获取DOM树中每个节点的文本密度和符号密度;
根据文本密度和符号密度,通过预设算法计算出DOM树所有节点的得分;
对所有节点按所对应的得分从高到低进行排序,将排名最前的节点所包含的内容作为核心文本信息。
可选的,所述根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版,包括:
根据网页结构信息,生成标签树,所述标签树中包括多个叶子节点,每个叶子节点对应有绝对路径和文本信息;
通过遍历标签树的叶子节点,获取对应的文本信息;
判断文本信息是否存在于核心文本信息;
若存在,则将当前节点的绝对路径记为有效路径;
对所有有效路径进行合并,以获取最长公共路径,即正文的规则模版。
可选的,所述对所有有效路径进行合并,以获取最长公共路径,包括:
对有效路径进行两两相似度计算,获取相应的相似度路径值,并形成相似度集合;
计算获取相似度集合中众数和平均数,获取有效路径的阈值点;
选取大于或等于有效路径的阈值点的相似度路径值对应的有效路径作为最相似的有效路径集合;
根据最相似的有效路径集合,获取同一位置节点的最大相同的路径和该位置的总路径的比值;
选取比值大于预设阈值的节点的最大相同的路径为有效公共路径;
从所有有效公共路径中获取最长公共路径,即正文的规则模版。
可选的,所述根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版,包括:
根据网页结构信息,获取title标签的文本内容,记为实验组,
获取h标签以及class包含title的div标签的文本内容,记为对照组;
对实验组和对照组计算最长公共子串,并对比包含最长公共子串的实验组和对照组的文本内容长度,选择文本内容更长的一组,作为标题以及标题的规则模版。
可选的,所述根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版,包括:
根据网页结构信息,获取所有与日期、时间对应的字符串;
依次对获取的所有字符串进行时间标准化处理,分别获取对应的标准化时间;
通过预设的标准化时间模板,选取与其匹配度最高的标准化时间作为发布时间;
根据发布时间对应的文本信息利用标签树进行逆向推算发布时间的绝对路径,即发布时间规则模版。
可选的,根据正文规则模版、标题规则模版和发布时间规则模版,确定通用规则模版,包括:
根据正文规则模版、标题规则模版和发布时间规则模版生成与预设的网页地址信息对应的专用规则模版,将专用规则模版储存到预设的与网页类别对应的数据库中,统计数据库中的专用规则模版数量,判断专用规则模版数量是否达到预设值,
若不是,则使用当前的专用规则模版作为临时的通用规则模版;
若是,根据数据库中的专用规则模版筛选出通用规则模版。
可选的,从网页结构信息中获取核心文本信息之前,还包括:
判断是否存在与预设网页信息所对应的通用规则模版,
若是,则使用通用规则模版抽取网页核心内容;
若不是,则从网页结构信息中获取核心文本信息。
第二方面,本申请提供一种网页的核心内容的智能化抽取系统,包括:
网页数据获取模块,用于根据预设的网页地址信息获取相应的网页结构信息,基于预设抽取方式,从网页结构信息中获取核心文本信息;
规则模版生成模块,用于根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版,然后根据正文规则模版、标题规则模版和发布时间规则模版,确定通用规则模版;
核心内容抽取模块,用于基于通用规则模版,抽取当前网页的核心内容。
第三方面,本申请提供一种计算机可读存储介质,存储有能够被处理器加载并执行上述一种网页的核心内容的智能化抽取方法的计算机程序。
综上所述,本申请根据网页地址信息可通过设定的算法获取网页的核心内容,并生成对应的规则模版,通过规则模版可以针对网页所对应类别获取该类别网页通用的规则模版,有了通用的规则模版之后,对于同类型网页的核心内容,可直接使用通用的规则模版快速进行抽取,从而实现大规模的网页数据监控。
附图说明
图1是本申请实施例所提供的一种网页的核心内容的智能化抽取方法的流程图;
图2是本申请实施例所提供的从网页结构信息中获取核心文本信息的流程示意图;
图3是本申请实施例所提供的生成正文规则模版的流程示意图;
图4是本申请实施例所提供的生成发布时间规则模版的流程示意图;
图5是本申请实施例所提供的一种网页的核心内容的智能化抽取系统的示意图。
具体实施方式
以下结合附图1-附图5,对本申请作进一步详细说明。
本申请提供一种网页的核心内容的智能化抽取方法,参见图1,包括以下步骤:
S100、根据预设的网页地址信息获取相应的网页结构信息。
其中,预设的网页地址信息,包含有网页类型、网页的地址url,网页类别则细分为新闻类、科教类、娱乐类、军事类等,根据网页url可定位到想要抽取数据的网页;网页结构信息相当于网页源代码,由网页html、head、body等元素以及对应的文本、图片信息,样式css、脚步javescript等组成。
在本申请实施例中,通过网页地址信息采用scrapy-redis框架获取到网页结构信息,scrapy-redis作为分布式的爬虫框架,通常用来进行大规模的网站数据采集。
S200、基于预设抽取方式,从网页结构信息中获取核心文本信息。
在本申请实施例中,预设抽取方式是针对网页基于文本密度和符合密度进行建模来获取核心文本区域,核心文本区域所包含的内容即为核心文本信息。
核心文本信息的核心成分是正文文本信息,由于在网页中,正文所在的区域的文本密度以及符号密度是最大的,除此以外的其他区域,例如顶部导航栏,侧边广告栏,底部信息栏区域,文本是偏少的,且几乎没有文本符号。因此可以通过文本密度和符号密度作为判读依据来确定核心文本区域。
在本申请实施例中,基于预设抽取方式,从网页结构信息中获取核心文本信息,参见图2,具体包括如下步骤:
S210、根据网页结构信息,构建DOM树。
在本申请实施例中,由于在网页结构中,想要确认正文文本所在的区域,是通过网页标签以及其所在网页结构的位置来进行定位的,因此首先会根据网页结构,对网页结构进行解析,例如可以通过Jsoup提供的标准库中的Parse函数进行解析,以获取document对象,即DOM树,DOM树会将当前网页结构包含的元素或者标签如
、、
在构建DOM树之前,还会对网页结构信息进行预处理,主要是移除js脚步、css样式和Iframe等,因为构建DOM树不需要这些信息,同时还可能会带来一些干扰信息,此外,由于网页的内容主体通常是处于body标签中,因此会将body标签作为DOM树的根节点,以精简DOM树的组成,减少后续对文本密度和符号密度建模的计算量。
S220、计算并获取DOM树中每个节点的文本密度和符号密度。
在本申请实施例中,通过遍历DOM树中的每个节点,可计算出每个节点的文本密度和符号密度。
具体地,节点的文本密度T
其中,S为节点的纯文本数量,S
节点的符号密度C
其中,M为节点带有文本符号的文本数量,L-L
S230、根据文本密度和符号密度,通过预设算法计算出DOM树所有节点的得分。
在计算出DOM树中每个节点的文本密度和符号密度之后,由于有的节点文本密度较大,而有的节点符号密度较大,因此,如何去确定哪一个节点是所需要的核心文本信息所在的节点,还需要设定一个判断规则。
在一个实施例中,会采用文本密度*符号密度来作为对应节点的得分W,最后根据得分来确定最需的节点,W表现为:W=T
在另一个实施例中,由于考虑到某些情况下,比如网页的最后一个标签的文字数量很多,文本的密度可能是100/1,100是文字的数量,1是最后一个标签数量,会造成标签很少的情况下,密度反而很大的偏差,因此增加了该节点内所有标签的数量维度,最终的得分W表现为:W=L*T
在本申请实施例中,由于考虑到不同类型的网页会有不同的布局,并且通过分别采用文本密度和符号密度进行测试,会发现使用文本密度的准确率相对更高一些,但对于不同类型的网页内容,文本密度和符号密度的准确率也会有所差异,因此预设算法会赋予文本密度和符号密度不同的权重,并且根据不同类型的网页可相应的进行权重调整,即最后的节点得分W表现为:W=θ
其中,θ
S240、对所有节点按所对应的得分从高到低进行排序,将排名最前的节点所包含的内容作为核心文本信息。
在本申请实施例中,根据文本密度和符号密度计算出DOM树中所有节点的得分之后,会对得分进行排序,由于综合考量了文本密度和符号密度,当节点得分越大,表明该节点包含正文内容的可能性更大,因此会将排名最前的节点所包含的内容作为核心文本信息。
S300、根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版。
其中,正文规则模版、标题规则模版和发布时间模版都是指一种网页数据提取的xpath规则,例如正文一般会存在网页结构中的p标签中,标题会由h标签包含,也就是说数据的存在形式是具有一定的规则的,根据这种规则可以直接进行相应数据的提取。
在本申请实施例中,在获取到核心文本信息之后,会根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版,在得到这些模版之后,根据网页结构信息即可直接根据模版获取到网页正文、标题和发布时间。
在本申请实施例中,根据核心文本信息和网页结构信息,生成正文规则模版,参见图3,具体包括如下步骤:
S310、根据网页结构信息,生成标签树。
其中,标签树和上述的DOM树的结构上是相似的,只是节点中包含的数据和数据存储形式不一样,标签树的根节点以html标签开始,不断生成子节点形成枝路径,直到最终的叶子节点不再生成新的节点为终点。
其中所有叶子节点的内容均为三元组,分别是当前节点元素对象,绝对路径以及包含的文本信息,由于有的叶子节点只包含图片、a标签等,所以有文本信息的节点一定会是叶子节点,但叶子节点不一定都有文本信息。
标签树还具有可正向/可逆向的特点,可正向表示只要有规则路径,就知道标签树的叶子节点包含的信息;可逆向表示只要知道文本信息,就能获取到该文本信息对应的标签树的路径。
在本申请实施例中,为了保障每一个绝对路径在当前网页结构中的唯一性,还会对绝对路径进行特殊处理:如果是平级标签,绝对路径会增加角标的形式,来保障规则的准确性。比如:
S311、通过遍历标签树的叶子节点,获取对应的文本信息。
在本申请实施例中,由于网页中正文中也会嵌入各种标签,所以并不是网页的正文部分就只存在于一个叶子节点中,而是被分散存于不同的叶子节点中,因此需要通过遍历标签树的所有叶子节点,获取到相应的文本信息,获取核心文本信息的目的在于获取正文,并找到能获取到完整正文信息的路径。
S312、判断文本信息是否存在于核心文本信息。
在本申请实施例中,核心文本信息是上述通过文本密度和符号密度建模获取到的,其内容主体就是正文。对于遍历标签树中所有叶子节点所获取的文本信息,可以以核心文本信息作为参考,因为若叶子节点中所包含的文本信息属于正文的话,则该文本信息一定也存在于核心文本信息中,因此通过判断叶子节点包含的文本信息是否存在于核心文本信息来确认该文本信息是否是正文的一部分。
在一个实施例中,会对核心文本信息进行分段和切割整句的方式将核心文本信息切分为多个文本信息。通过将叶子节点所包含的文本信息和核心文本信息中进行一对多的文本相似度计算,当有相似度达到预设的阈值时,则认为文本信息存在于核心文本信息中。
在另一个实施例中,会直接将叶子节点所包含的文本信息在核心文本信息中进行字符串匹配,根据匹配度来确认文本信息是否存在于核心文本信息中。
S313、若存在,则将当前节点的绝对路径记为有效路径。
在本身实施例中,若文本信息不存在于核文本信息中,则记该文本信息所对应结点的绝对路径为无效路径,反正,若文本信息存在于核文本信息中,则将该文本信息所对应结点的绝对路径记为有效路径。
S314、对所有有效路径进行合并,以获取最长公共路径,即正文的规则模版。
在本申请实施例中,由于有效路径表征的是正文文本部分信息的获取路径,即根据有效路径能获取到一部分正文内容信息,现在需要的是找到一条路径可以获取到所有的正文内容,因此会对所有有效路径进行合并,以获取最长公共路径,也就是能获取到所有正文内容的路径,即正文的规则模版。
在本申请实施例中,对所有有效路径进行合并,以获取最长公共路径,具体包括如下步骤:
S3141、对有效路径进行两两相似度计算,获取相应的相似度路径值,并形成相似度集合。
在本申请实施例中,由于需要根据所有有效路径确定一条最长的公共路径,所以首先需要找到公共的路径,而对于公共的路径会通过相似度计算来进行确定,通过对有效路径进行两两相似度计算,即每一个有效路径都需要同其他的有效路径进行相似度计算,计算获取到所有的相似度值之后,会形成一个相似度集合,集合中包含有效路径以及与之相关的相似度值。
S3142、计算获取相识度集合中众数和平均数,获取有效路径的阈值点。
S3143、选取大于或等于有效路径的阈值点的相似度路径值对应的有效路径作为最相似的有效路径集合。
在本申请实施例中,获取到相似度集合后,通过计算可获取到所有相似度值的众数和平均数,众数表示的是相似度集合中出现次数最多的相似度值,如果平均数小于众数,则取众数的相似度路径值为有效路径的阈值点,否则取平均数的相似度路径值为有效路径的阈值点,从而保留所有大于等于有效路径的阈值点的相似度路径值对应的有效路径作为最相似的有效路径集合。
S3144、根据最相似的有效路径集合,获取同一位置节点的最大相同的路径和该位置的总路径的比值。
S3145、选取比值大于预设阈值的节点的最大相同的路径为有效公共路径。
在本申请实施例中,由于最相似的有效路径计算的是整个路径的相似度,最终获取的公共路径还需要考虑到路径中节点的顺序,可能两个有效路径相似度很高,只有中间一个节点不同,但这种情况下,只有中间不同节点之前的路径才是有效的,因此在获取到最相似的有效路径集合后,还会对同一位置节点的最大相同的路径和该位置的总路径的比值进行计算。
当同一位置的节点的最大相同的路径和该位置的总路径的比值大于预设的阈值时,认为是有效的公共路径,一般阈值为设置为0.9。例如,最相似的有效路径集合为[‘/html/body/div/div’,’/html/body/div/a’,’/html/body/a/div’]。则1位置html的比值为1;2位置body的比值为1;3位置div的比值为2/3,,a的比值为1/3;4位置div的相似度为2/3,a的比值为1/3。那么选取比值大于0.9的位置对应的标签为有效公共路径,则最终的最长公共路径为/html/body。
S3146、从所有有效公共路径中获取最长公共路径,即正文的规则模版。
在本申请实施例中,获取到所有有效公共路径之后,若有效公共路径不止一个,例如,有效公共路径为/html/body和/html/body/p,则选取最长的公共路径为正文的规则模版,也就是/html/body/p。因为目的是只获取正文信息,而不需要其他的内容部分,因此最长公共路径才是需要的正文规则模版。
在本申请实施例中,根据核心文本信息和网页结构信息,生成标题规则模版,具体包括如下步骤:
S320、根据网页结构信息,获取title标签的文本内容,记为实验组,获取h标签以及class包含title的div标签的文本内容,记为对照组。
在本申请实施例中,由于通过对大量的网页进行分析,发现一般网页的标题会在title标签、h标签、div下class包含title的标签,而出现在title标签的比重最高。
因此,会根据网页结构信息,获取title标签的文本内容,记为实验组,然后获取h标签以及class包含title的div标签的文本内容,记为对照组。
S321、对实验组和对照组计算最长公共子串,并对比包含最长公共子串的实验组和对照组的文本内容长度,选择文本内容更长的一组,作为标题以及标题的规则模版。
在本申请实施例中,由于网页标题一般具有高概括性、精简性特点,会包含一些关键词,关键语句等信息,因此通过实验组和对照组所提取的文本内容进行字符串匹配,若获取到公共子串,则说明两组文本内容均包含有同样的信息,可理解为该公共的信息为关键信息。
通常情况下,网页中正文部分标题的文字长度对比其它的一些标题对应的文字长度要长,因此,通过对比包含公共关键信息的所有候选标题的文本长度,选择文本内容更长的一组,作为标题以及标题的规则模版。
在本申请实施例中,根据核心文本信息和网页结构信息,生成发布时间规则模版,参见图4,具体包括如下步骤:
S330、根据网页结构信息,获取所有与日期、时间对应的字符串。
通过对大量的同类型网页的分析,发现一般网页的发布时间在网页结构中也是存在一定的规则。例如,新闻类型的详情页的发布时间会在标题和正文之间,并且发布时间给出的形式基本上都是标准化的时间形式,例如,2022-08-23 09:21:00、2022-08-22 08:52等形式,而网页中包含的其他关于日期时间的内容,很少会以上述的标准化时间格式呈现。因此可以通过对网页中提取的时间进行标准化,与标准时间格式进行匹配,根据匹配程度来判断是否是发布时间。
在本申请实施例中,根据网页结构信息,获取所有与日期、时间对应的字符串,主要是获取meta中包含的发布时间、包含class中包含date的标签内容以及包含发布时间/日期的文本中的发布时间、以及正文中的发布时间。
S331、依次对获取的所有字符串进行时间标准化处理,分别获取对应的标准化时间。
其中,标准化时间格式为yyyy-MM-dd hh:mm:ss,可以直接采用js中的时间格式转化方法将获取的时间字符串转为标准化格式。
在本申请实施例中,由于网页中除了发布时间外,还包含有其它有关日期、时间的信息,因此将所有时间字符串都转为标准时间格式,以获取对应的标准化时间,再根据标准化时间与标准化时间格式的匹配度来确定发布时间。
S332、通过预设的标准化时间模板,选取与其匹配度最高的标准化时间作为发布时间。
其中,预设标准化时间模板是根据标准时间格式设定的优先级序列,按年月日时分秒、年月日时分、年月日时、月日时分、年月日、年月、月日来设定优先级。例如yyyy-MM-ddhh:mm:ss这种优先最高,其次yyyy-MM-dd hh:mm,以此类推,最后MM-dd优先级最低。
在本申请实施例中,通过将所有时间字符串都转为标准时间格式,以获取对应的标准化时间后,可以根据标准化时间与优先级序列进行匹配,每一个标准化时间都能匹配到与之对应的优先级,最后将匹配优先级最高的标准化时间作为发布时间。
S333、根据发布时间对应的文本信息利用标签树进行逆向推算发布时间的绝对路径,即发布时间规则模版。
在本申请实施例中,根据上述方法获取到发布时间之后,还需要将这种方法转为制定的规则模版,以便于根据制定的规则模版即可直接获取到发布时间。根据发布时间对应的文本信息可以通过上述提到的标签树来获取相应的绝对路径,而这个路径即为发布时间模版。
在本申请实施例中,还考虑到网页中可能有出现一些对于时间比较精细化的情景,例如,火箭发射、监控场景下的帧识别等也可能会涉及到具体的分秒,还有网页中可能还会出现修改的时间,也会同发布时间一样有着相同的时间格式。
因此为了进一步提升对于发布时间获取的准确度,对于具有同样高优先级的候选发布时间,还会根据候选发布时间对应的文本信息所在节点位置进行进一步筛选,对于节点位置在标题和正文之间的候选发布时间赋予更高的优先级。
S400、根据正文规则模版、标题规则模版和发布时间规则模版,确定通用规则模版。
在本申请实施例中,获取的正文规则模版、标题规则模版和发布时间规则模版都是根据当前的网页所得到的,还需要根据当前的模版确定通用规则模版,以便于对于同类型的网页数据都能根据通用规则模版进行数据抽取。
在本申请实施例中,根据正文规则模版、标题规则模版和发布时间规则模版,确定通用规则模版,具体包括如下步骤:
S410、根据正文规则模版、标题规则模版和发布时间规则模版生成与预设的网页地址信息对应的专用规则模版,将专用规则模版储存到预设的与网页类别对应的数据库中,统计数据库中的专用规则模版数量,判断专用规则模版数量是否达到预设值。
S420、若不是,则使用当前的专用规则模版作为临时的通用规则模版;
S430、若是,根据数据库中的专用规则模版筛选出通用规则模版。
在本申请实施例中,将正文规则模版、标题规则模版和发布时间规则模版进行组合即为当前网页的专用规则模版,根据预设的网页地址信息可以获取到当前网页的所属类别,将专业规则模版存储到与所属类别对应的数据库中,当一个类型的网页专用规则模版达到一定数量,则可从中去筛选出通用规则模版。
通过统计数据库中的当前网页对应类别的专用规则模版数量,判断是否达到预设值,若没有达到预设值,则将当前网页对应的专用规则模版作为临时的通用规则模版。
若当前网页对应类别的专用规则模版数量达到预设值,则计算出当前网页对应类别的专用规则模版中的众数,也就是当前网页对应类别中,有多个专用规则模版是相同的,则将该相同的模版作为通用规则模版,只有当众数达到一定值,我们才会认为众数所对应的专用规则模版是具有较高的通用性,因此会设定一个众数阈值,若当前网页对应类别的专用模版中的众数达到预设众数阈值,则将众数对应的专用规则模版作为通用规则模版。
S500、基于通用规则模版,抽取当前网页的核心内容。
在本申请实施例中,在生成当前网页的专用规则模版后,可直接根据专用规则模版抽取当前网页的核心内容,当由于生成当前网页的专用模版之后,恰好可生成对应的通用规则模版,也就是在生成当前网页的专用规则模版之前,是没有与之对应的通用规则模版的,因此为了对获取到的通用规则模版进行测试,还会使用通用规则模版进行核心内容的提取,目的在于若通用规则模版不同于当前网页的专用规则模版时,可根据两者的核心内容抽取结果对新获取的通用规则模版进行评估。
以专用规则模版的抽取结果作为参考标准,通过计算核心内容的文本相似度来判断通用规则模版抽取的准确度,若准确度达到预设的标准,则认为当前通用规则模版是有效的,若准确度没有达到预设的标准,则认为当前通用规则模版未达到标准,还需要继续收集专用规则模版,以重新生成对应的通用规则模版。
所以基于通用规则模版,抽取当前网页的核心内容实际上是:若通用规则模版是临时的通用规则模版,则根据临时的通用规则模版,也就是当前网页的专用规则模版抽取核心内容,若通用规则模版不是临时的,则分别使用当前网页的专用规则模版和获取的通用规则模版进行核心内容的抽取。
在本申请实施例中,从网页结构信息中获取核心文本信息之前,还包括如下步骤:
S610、判断是否存在与预设网页信息所对应的通用规则模版。
S620、若是,则使用通用规则模版抽取网页核心内容;
S630、若不是,则从网页结构信息中获取核心文本信息。
在本申请实施例中,由于对网页根据设定的算法获取正文、标题和发布时间之后,会生成相应的规则模版,并将这些模版存储到对应网页类别的数据库中,当某一类别收集到规则模版达到预设值之后,会选出通用的规则模版,当再次抽取该类别网页的核心内容时,会直接使用通用规则模版进行抽取。
因此,根据网页地址信息获取到网页结构信息之后,从网页结构信息中获取核心文本信息之前,会根据网页地址信息所包含的类别来确定对应数据库中是否已有通用规则模版,若是,则使用通用规则模版抽取网页核心内容,若不是,则从网页结构信息中获取核心文本信息,并进行后续的步骤,即S300-S500。
本申请实施例还提供一种网页的核心内容的智能化抽取系统,参见图5,包括:网页数据获取模块101、规则模版生成模块102、核心内容抽取模块103。
其中,获取网页数据模块101用于根据预设的网页地址信息获取相应的网页结构信息,基于预设抽取方式,从网页结构信息中获取核心文本信息。
生成规则模版模块102用于根据核心文本信息和网页结构信息,分别生成正文规则模版、标题规则模版和发布时间规则模版,然后根据正文规则模版、标题规则模版和发布时间规则模版,确定通用规则模版。
核心内容抽取模块103用于基于通用规则模版,抽取当前网页的核心内容。
在本申请实施例中,网页数据获取模块具体用于根据待抽取网页的地址信息获取网页结构数据,并根据网页结构数据通过预设的抽取方式获取核心文本信息。
规则模版生成模块具体用于通过设定的算法根据网页结合数据和核心文本信息获取网页正文、标题和发布时间,并分别生成对应规则模版,然后将规则模版存储于与当前网页对应类别的数据库中,最后根据数据库的规则模版选出通用规则模版。
核心内容抽取模块具体用于根据获取的通用规则模版抽取当前网页的核心内容。
本申请实施例还提供一种计算机可读存储介质,存储有能够被处理器加载并执行上述一种网页的核心内容的智能化抽取方法的计算机程序。
本具体实施方式的实施例均为本申请的较佳实施例,并非依此限制本申请的保护范围,故:凡依本申请的原理所做的等效变化,均应涵盖于本申请的保护范围之内。
- 一种智能化网页内容自动模糊抽取系统
- 一种智能化网页内容自动模糊抽取系统
- 农业;林业;畜牧业;狩猎;诱捕;捕鱼
- 焙烤;制作或处理面团的设备;焙烤用面团
- 屠宰;肉品处理;家禽或鱼的加工
- 其他类不包含的食品或食料;及其处理
- 烟草、雪茄烟、纸烟、吸烟者用品
- 服装
- 帽类制品
- 鞋类
- 服饰缝纫用品、珠宝
- 手携物品或旅行品
- 刷类制品
- 家具、家庭用的物品或设备、咖啡磨、香料磨、一般吸尘器
- 医学或兽医学、卫生学
- 救生、消防
- 运动、游戏、娱乐活动
- 本部其他类目中不包括的技术主题
- 一般的物理或化学的方法或装置
- 破碎、磨粉或粉碎、谷物碾磨的预处理
- 用液体或用风力摇床或风力跳汰机分离固体物料、从固体物料或流体中分离固体物料的磁或静电分离、高压电场分离
- 用于实现物理或化学工艺过程的离心装置或离心机
- 一般喷射或雾化、对表面涂覆液体或其他流体的一般方法
- 一般机械振动的发生或传递
- 将固体从固体中分离、分选
- 清洁
- 固体废物的处理、被污染土壤的再生
- 基本上无切削的金属机械加工、金属冲压
- 铸造、粉末冶金
- 机床、其他类目中不包括的金属加工
- 磨削、抛光
- 手动工具、轻便机动工具、手动器械的手柄、车间设备、机械手
- 手动切割工具、切割、切断
- 木材或类似材料的加工或保存、一般钉钉机或钉U形钉机
- 加工水泥、黏土或石料
- 塑料的加工、一般处于塑性状态物质的加工
- 压力机
- 纸品或纸板或类似纸的方式加工的材料制品制作、纸或纸板或类似纸的方式加工的材料的加工
- 层状产品
- 附加制造技术
- 印刷、排版机、打字机、模印机
- 装订、图册、文件夹、特种印刷品
- 书写或绘图器具、办公用品
- 装饰艺术
- 一般车辆
- 铁路
- 无轨陆用车辆
- 船舶或其他水上船只、与船有关的设备
- 飞行器、航空、宇宙航行
- 输送、包装、贮存、搬运薄的或细丝状材料
- 卷扬、提升、牵引
- 开启或封闭瓶子、罐或类似的容器、液体的贮运
- 鞍具、家具罩面
- 微观结构技术
- 纳米技术
- 无机化学
- 水、废水、污水或污泥的处理
- 玻璃、矿棉或渣棉
- 水泥、混凝土、人造石、陶瓷、耐火材料
- 肥料、肥料制造
- 炸药、火柴
- 有机化学
- 有机高分子化合物、其制备或化学加工、以其为基料的组合物
- 染料、涂料、抛光剂、天然树脂、黏合剂、其他类目不包含的组合物、其他类目不包含的材料的应用
- 石油、煤气及炼焦工业、含一氧化碳的工业气体、燃料、润滑剂、泥煤
- 动物或植物油、脂、脂肪物质或蜡、由此制取的脂肪酸、洗涤剂、蜡烛
- 生物化学、啤酒、烈性酒、果汁酒、醋、微生物学、酶学、突变或遗传工程
- 糖工业
- 使用化学药剂、酶类或微生物处理小原皮、大原皮或皮革的工艺,如鞣制、浸渍或整饰、其所用的设备、鞣制组合物(皮革或毛皮的漂白入D06L、皮革或毛皮的染色入D06P)
- 铁的冶金
- 冶金、黑色或有色金属合金、合金或有色金属的处理
- 对金属材料的镀覆、用金属材料对材料的镀覆、表面化学处理、金属材料的扩散处理、真空蒸发法、溅射法、离子注入法或化学气相沉积法的一般镀覆、金属材料腐蚀或积垢的一般抑制
- 电解或电泳工艺、其所用设备
- 晶体生长
- 组合技术
- 天然或化学的线或纤维、纺纱或纺丝
- 纱线、纱线或绳索的机械整理、整经或络经
- 织造
- 编织、花边制作、针织、饰带、非织造布
- 缝纫、绣花、簇绒
- 织物等的处理、洗涤、其他类不包括的柔性材料
- 绳、除电缆以外的缆索
- 造纸、纤维素的生产
- 道路、铁路或桥梁的建筑
- 水利工程、基础、疏浚
- 给水、排水
- 建筑物
- 锁、钥匙、门窗零件、保险箱
- 一般门、窗、百叶窗或卷辊遮帘、梯子
- 土层或岩石的钻进、采矿
- 一般机器或发动机、一般的发动机装置、蒸汽机
- 燃烧发动机、热气或燃烧生成物的发动机装置
- 液力机械或液力发动机、风力、弹力或重力发动机、其他类目中不包括的产生机械动力或反推力的发动机
- 液体变容式机械、液体泵或弹性流体泵
- 流体压力执行机构、一般液压技术和气动技术
- 工程元件或部件、为产生和保持机器或设备的有效运行的一般措施、一般绝热
- 气体或液体的贮存或分配
- 照明
- 蒸汽的发生
- 燃烧设备、燃烧方法
- 供热、炉灶、通风
- 制冷或冷却、加热和制冷的联合系统、热泵系统、冰的制造或储存、气体的液化或固化
- 干燥
- 炉、窑、烘烤炉、蒸馏炉
- 一般热交换
- 武器
- 弹药、爆破
- 测量、测试
- 光学
- 摄影术、电影术、利用了光波以外其他波的类似技术、电记录术、全息摄影术〔4〕
- 测时学
- 控制、调节
- 计算、推算、计数
- 核算装置
- 信号装置
- 教育、密码术、显示、广告、印鉴
- 乐器、声学
- 信息存储
- 仪器的零部件
- 特别适用于特定应用领域的信息通信技术
- 核物理、核工程
- 基本电气元件
- 发电、变电或配电
- 基本电子电路
- 电通信技术
- 其他类目不包含的电技术
- 其他专利