一种应用虚拟人物漫游技术的智慧服务展示方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及智慧服务展示技术领域,尤其涉及一种应用虚拟人物漫游技术的智慧服务展示方法及系统。
背景技术
随着全球信息化的发展和进步,虚拟现实技术的应用日益普及,数字化、信息化逐渐渗透到各个领域,虚拟现实技术具有创设生动情境、营造沉浸式环境、将抽象画面可视化、创新服务展示方式和评价方法等优点,虚拟现实技术的三大特点为沉浸性、交互性、想象性,在虚拟现实环境中,创设虚拟情境,让用户有身临其境的感觉,可以提升用户在申请服务中的体验感,然而,现有的智慧服务展示虽然应用了虚拟现实技术,但是并没有人物漫游的体验,会大大降低用户的体验感。
发明内容
有鉴于此,本发明提出一种应用虚拟人物漫游技术的智慧服务展示方法及系统,可以解决现有技术所存在的没有人物漫游体验的缺陷。
本发明的技术方案是这样实现的:
一种应用虚拟人物漫游技术的智慧服务展示方法,具体包括:
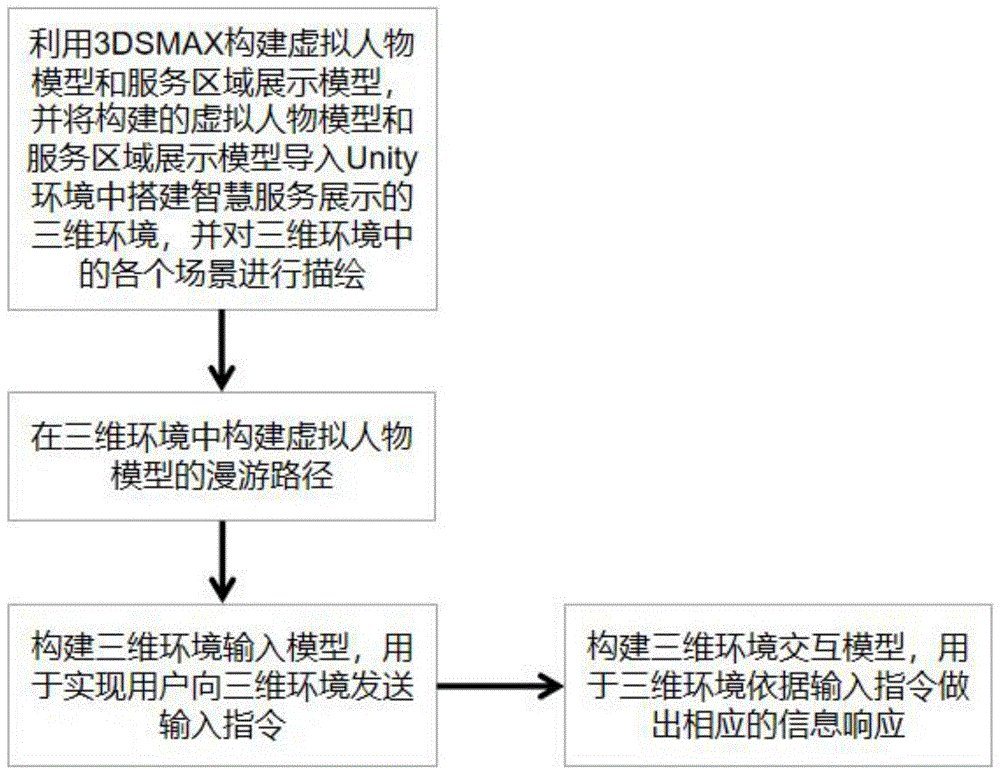
利用3DSMAX构建虚拟人物模型和服务区域展示模型,并将构建的虚拟人物模型和服务区域展示模型导入Unity环境中搭建智慧服务展示的三维环境,并对三维环境中的各个场景进行描绘;
在三维环境中构建虚拟人物模型的漫游路径;
构建三维环境输入模型,用于实现用户向三维环境发送输入指令;
构建三维环境交互模型,用于三维环境依据输入指令做出相应的信息响应。
作为所述应用虚拟人物漫游技术的智慧服务展示方法的进一步可选方案,所述交互模型包括文字交互模型和语音交互模型,所述文字交互模型用于三维环境做出文字信息响应,所述语音交互模型用于三维环境做出语音信息响应。
作为所述应用虚拟人物漫游技术的智慧服务展示方法的进一步可选方案,所述语音交互模型基于卷积神经网络进行构建,所述语音交互模型包括输入层,卷积层,池化层和分类层,输入层用于对输入多个词向量进行拼接,输出词拼接向量,卷积层用于利用滤波器对输入拼接词向量提取特征,并通过池化层对滤波器提取的特征进行聚合,输出词卷积特征向量,分类层包括全连接层和softmax函数,全连接层对输入词卷积特征向量进行融合,然后将融合后的特征向量输入softmax函数进行分类,基于分类结果得到语音回复信息。
作为所述应用虚拟人物漫游技术的智慧服务展示方法的进一步可选方案,所述文字交互模型基于人工智能进行构建,具体包括:
根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;
应用多个对话源的特征资源获取与所述解析结果对应的多个结果;
根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
作为所述应用虚拟人物漫游技术的智慧服务展示方法的进一步可选方案,所述在三维环境中构建虚拟人物模型的漫游路径,具体包括:
设定插值样条线性曲线的控制点;
依据控制点间的线段确定控制点间的多个插值点;
依据多个插值点,建立线条圆滑的虚拟人物模型的漫游路径。
一种应用虚拟人物漫游技术的智慧服务展示系统,包括:
第一构建模块,用于利用3DSMAX构建虚拟人物模型和服务区域展示模型,并将构建的虚拟人物模型和服务区域展示模型导入Unity环境中搭建智慧服务展示的三维环境,并对三维环境中的各个场景进行描绘;
第二构建模块,用于在三维环境中构建虚拟人物模型的漫游路径;
第三构建模块,用于构建三维环境输入模型,实现用户向三维环境发送输入指令;
第四构建模块,用于构建三维环境交互模型,三维环境依据输入指令做出相应的信息响应。
作为所述应用虚拟人物漫游技术的智慧服务展示系统的进一步可选方案,所述交互模型包括文字交互模型和语音交互模型,所述文字交互模型用于三维环境做出文字信息响应,所述语音交互模型用于三维环境做出语音信息响应。
作为所述应用虚拟人物漫游技术的智慧服务展示系统的进一步可选方案,所述语音交互模型基于卷积神经网络进行构建,所述语音交互模型包括输入层,卷积层,池化层和分类层,输入层用于对输入多个词向量进行拼接,输出词拼接向量,卷积层用于利用滤波器对输入拼接词向量提取特征,并通过池化层对滤波器提取的特征进行聚合,输出词卷积特征向量,分类层包括全连接层和softmax函数,全连接层对输入词卷积特征向量进行融合,然后将融合后的特征向量输入softmax函数进行分类,基于分类结果得到语音回复信息。
作为所述应用虚拟人物漫游技术的智慧服务展示系统的进一步可选方案,所述文字交互模型包括:
输入模块,用于根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;
获取模块,用于应用多个对话源的特征资源获取与所述解析结果对应的多个结果;
输出模块,用于根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
作为所述应用虚拟人物漫游技术的智慧服务展示系统的进一步可选方案,所述第二构建模块包括:
设定模块,用于设定插值样条线性曲线的控制点;
确定模块,用于依据控制点间的线段确定控制点间的多个插值点;
建立模块,用于依据多个插值点,建立线条圆滑的虚拟人物模型的漫游路径。
本发明的有益效果是:通过构建虚拟人物模型和服务区域展示模型,并依据虚拟人物模型和服务区域展示模型导入Unity环境中搭建智慧服务展示的三维环境,在三维环境中构建虚拟人物模型的漫游路径,能够有效在三维环境中加入虚拟人物模型,然后依据用户向三维环境发送的输入指令,做出相应的信息响应,从而增加用户在智慧服务展示中的体验感。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种应用虚拟人物漫游技术的智慧服务展示方法的流程示意图;
图2为本发明一种应用虚拟人物漫游技术的智慧服务展示系统的组成示意图。
具体实施方式
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
参考图1-2,一种应用虚拟人物漫游技术的智慧服务展示方法,具体包括:
利用3DSMAX构建虚拟人物模型和服务区域展示模型,并将构建的虚拟人物模型和服务区域展示模型导入Unity环境中搭建智慧服务展示的三维环境,并对三维环境中的各个场景进行描绘;
在三维环境中构建虚拟人物模型的漫游路径;
构建三维环境输入模型,用于实现用户向三维环境发送输入指令;
构建三维环境交互模型,用于三维环境依据输入指令做出相应的信息响应。
在本实施例中,通过构建虚拟人物模型和服务区域展示模型,并依据虚拟人物模型和服务区域展示模型导入Unity环境中搭建智慧服务展示的三维环境,在三维环境中构建虚拟人物模型的漫游路径,能够有效在三维环境中加入虚拟人物模型,然后依据用户向三维环境发送的输入指令,做出相应的信息响应,从而增加用户在智慧服务展示中的体验感。
优选的,所述交互模型包括文字交互模型和语音交互模型,所述文字交互模型用于三维环境做出文字信息响应,所述语音交互模型用于三维环境做出语音信息响应。
在本实施例中,通过设置文字交互模型和语音交互模型,能够实现文字交互和语音交互的功能,进一步提升用户的使用体验。
优选的,所述语音交互模型基于卷积神经网络进行构建,所述语音交互模型包括输入层,卷积层,池化层和分类层,输入层用于对输入多个词向量进行拼接,输出词拼接向量,卷积层用于利用滤波器对输入拼接词向量提取特征,并通过池化层对滤波器提取的特征进行聚合,输出词卷积特征向量,分类层包括全连接层和softmax函数,全连接层对输入词卷积特征向量进行融合,然后将融合后的特征向量输入softmax函数进行分类,基于分类结果得到语音回复信息。
优选的,所述文字交互模型基于人工智能进行构建,具体包括:
根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;
应用多个对话源的特征资源获取与所述解析结果对应的多个结果;
根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
优选的,所述在三维环境中构建虚拟人物模型的漫游路径,具体包括:
设定插值样条线性曲线的控制点;
依据控制点间的线段确定控制点间的多个插值点;
依据多个插值点,建立线条圆滑的虚拟人物模型的漫游路径。
一种应用虚拟人物漫游技术的智慧服务展示系统,包括:
第一构建模块,用于利用3DSMAX构建虚拟人物模型和服务区域展示模型,并将构建的虚拟人物模型和服务区域展示模型导入Unity环境中搭建智慧服务展示的三维环境,并对三维环境中的各个场景进行描绘;
第二构建模块,用于在三维环境中构建虚拟人物模型的漫游路径;
第三构建模块,用于构建三维环境输入模型,实现用户向三维环境发送输入指令;
第四构建模块,用于构建三维环境交互模型,三维环境依据输入指令做出相应的信息响应。
在本实施例中,通过构建虚拟人物模型和服务区域展示模型,并依据虚拟人物模型和服务区域展示模型导入Unity环境中搭建智慧服务展示的三维环境,在三维环境中构建虚拟人物模型的漫游路径,能够有效在三维环境中加入虚拟人物模型,然后依据用户向三维环境发送的输入指令,做出相应的信息响应,从而增加用户在智慧服务展示中的体验感。
优选的,所述交互模型包括文字交互模型和语音交互模型,所述文字交互模型用于三维环境做出文字信息响应,所述语音交互模型用于三维环境做出语音信息响应。
在本实施例中,通过设置文字交互模型和语音交互模型,能够实现文字交互和语音交互的功能,进一步提升用户的使用体验。
优选的,所述语音交互模型基于卷积神经网络进行构建,所述语音交互模型包括输入层,卷积层,池化层和分类层,输入层用于对输入多个词向量进行拼接,输出词拼接向量,卷积层用于利用滤波器对输入拼接词向量提取特征,并通过池化层对滤波器提取的特征进行聚合,输出词卷积特征向量,分类层包括全连接层和softmax函数,全连接层对输入词卷积特征向量进行融合,然后将融合后的特征向量输入softmax函数进行分类,基于分类结果得到语音回复信息。
优选的,所述文字交互模型包括:
输入模块,用于根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;
获取模块,用于应用多个对话源的特征资源获取与所述解析结果对应的多个结果;
输出模块,用于根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
优选的,所述第二构建模块包括:
设定模块,用于设定插值样条线性曲线的控制点;
确定模块,用于依据控制点间的线段确定控制点间的多个插值点;
建立模块,用于依据多个插值点,建立线条圆滑的虚拟人物模型的漫游路径。
以上所述仅为本发明的较佳实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。