一种基于强化学习的自适应卫星姿轨控制方法
文献发布时间:2023-06-19 18:47:50
技术领域
本发明涉及卫星控制领域。具体讲,涉及一种基于强化学习的自适应卫星姿轨控制方法。
背景技术
卫星编队飞行在地球观测、天文观测和卫星与地球间的通信等领域引起了广泛的关注。与单个卫星相比,一组卫星是灵活且具有良好任务收益的,因为它们可以与不同的有效载荷进行协调,并依据特定的任务自由组合。卫星编队队形形成在各个领域具有巨大的潜力。由于卫星的姿态和相位置之间存在着复杂的耦合动力学,因此每个卫星的动力学模型都是高度非线性的,涉及到6个自由度之间的旋转-平移耦合。此外,很难获得精确的卫星动力学参数,这对确定多卫星系统的优化编队飞行的优化目标带来了挑战。
当前对卫星姿轨控制的方法主要有以下几种:
1. 将卫星六自由度动态模型简化为线性模型,结合传统最优控制方法,得到最优控制策略。
2. 针对非线性的卫星动力学模型,采用反馈线性化的方法将非线性部分抵消,基于一些优化方法(例如Riccati微分方法、
3. 对于卫星的位置控制,控制输入量在LVLH(当地垂直当地水平)坐标系中给出,不考虑姿态对于相对位置的耦合影响。
如CN105068546A公开了一种卫星编队相对轨道自适应神经网络构形包含控制方法,通过建立跟随星的相对轨道动力学方程;对每一个跟随星设计分布式速度观测器;随后跟随星的相对轨道动力学方程和分布式速度观测器进行神经网络逼近;根据神经网络逼近结果设计自适应神经网络构形包含控制算法。CN105138010A公开了一种编队卫星分布式有限时间跟踪控制方法,通过建立双星相对运动动力学模型;编队卫星相对参考点的相对运动动力学模型;设计分布式有限时间跟踪控制律,解决了卫星编队控制方法中编队卫星间通信受限的问题。
然而上述卫星姿轨控制方法都存在一定的问题,对于第一种,卫星在实际运行中的动态是强非线性的,因而该方式所得到的控制策略并不是最优的。对于第二种,应该注意到在反馈线性化过程与传统最优控制器设计过程中,都需要基于被控对象的模型信息。实际卫星的动态模型存在不确定性(如质量分布不确定性、转动惯量不确定性等)。故此类技术对于参数完全未知、被控对象模型信息未知的情况并不适用。对于第三种控制方法,实际卫星的位置控制器(如推力器)固定在卫星本体上,位置控制的输入矩阵取决于位置姿态,卫星姿态的变化对于推力器的推力分配影响明显。所以此类技术得到的最优控制输入是LVLH坐标系中的最优控制,而不是本体坐标系中每个推力器对应的最优控制。
发明内容
针对目前现有技术中存在的问题,本发明首先建立了卫星完整的六自由度非线性模型,相对第一类现有控制技术中将卫星动态简化为线性化模型的方式,本发明采用神经网络对直接对非线性模型的最优控制策略进行估计,以应对非线性影响。相比于第二类现有控制技术,本发明提出的算法由于采用强化学习算法基于可测得数据进行参数辨识,故而可以避免对卫星模型精确性的要求,学习得到最优控制律,同时对卫星部分参数未知情况下具有良好的自适应性,通过与环境进行交互即可辨识出参数并学习出真正的最优控制策略。相比于第三类现有控制技术,本发明将卫星相对参考点的位置动态投影至本体坐标系中,从本体坐标系中观察得到的相对位置动态包含了姿态对位置的耦合信息,在本体坐标系中对每个推力器设计出了最优控制。
本发明完整的技术方案包括:
一种基于强化学习的自适应卫星姿轨控制方法,包括如下步骤:
步骤1:针对一组由实际卫星组成的编队,采用虚拟领导卫星作为整个编队的基准;建立虚拟领导卫星的轨道动力学模型,并得到各实际卫星与虚拟领导卫星间的相对位置动态关系,结合各实际卫星的姿态运动方程,得到基于修正罗德里格斯参数描述的各实际卫星姿态动力学的拉格朗日表示;
步骤2:针对实际卫星编队,得到各实际卫星姿轨耦合的六自由度动态模型;
步骤3:进行姿态控制器设计,包括针对实际卫星编队,根据实际卫星姿态动力学控制的模型,结合实际卫星参考信号的动态描述得到实际卫星的姿态子系统,并针对姿态子系统定义其价值函数,通过设计异策略强化学习最优姿态控制算法,得到最优姿态控制策略;
步骤4:进行相对位置控制器的设计,包括针对实际卫星编队,根据其与虚拟领导卫星间的相对位置动态,结合各实际卫星的相对位置参考动态,得到各实际卫星的相对位置子系统;并针对相对位置子系统定义其价值函数,通过设计异策略强化学习相对位置控制算法,得到最优相对位置控制策略。
所述步骤1具体为:
1.1 建立虚拟领导卫星的地心惯性坐标系和各实际卫星的本体坐标系;并在地心惯性坐标系中建立由位置矢量和引力加速度矢量组成的虚拟领导卫星轨道动力学模型;
1.2建立由位置矢量、引力加速矢量和位置控制力矢量组成的各实际卫星的轨道动力学模型;
1.3 根据各实际卫星的位置矢量和虚拟领导卫星的位置矢量,得到各实际卫星与虚拟领导卫星之间的相对位置以及相对位置动态;
1.4 将步骤1.3得到的相对位置动态投影至各实际卫星的本体坐标系;结合包含角速度、惯性积和控制力矩的实际卫星姿态运动方程,得到基于修正罗德里格斯参数描述的实际卫星姿态动力学的拉格朗日表示。
所述步骤2中,每颗实际卫星均包含六个推力器作为位置控制执行器,在本体坐标系中将各实际卫星与虚拟领导卫星之间的相对位置动态表示为各实际卫星姿轨耦合的六自由度动态模型。
所述步骤3中具体为:
3.1将各实际卫星的姿态状态表达为输出和控制力矩输入的函数;
3.2结合卫星参考信号的动态描述,得到各实际卫星的姿态子系统,
3.3针对卫星姿态子系统定义价值函数;
3.4结合各实际卫星的姿态子系统价值函数得到哈密顿函数,并通过异策略强化学习最优姿态控制算法得到最优姿态控制策略。
所述步骤4中具体为,
4.1针对各实际卫星,将其与虚拟领导卫星间的相对位置动态表达为相对位置状态量、输出量和控制加速度输入的函数,
4.2结合各实际卫星的相对位置参考动态,得到各实际卫星的相对位置子系统,
4.3针对相对位置子系统定义价值函数;
4.4结合各实际卫星的相对位置子系统价值函数得到贝尔曼方程,并通过异策略强化学习相对位置控制算法得到最优相对位置控制策略。
本发明相对于现有技术的优点在于:
1、建立卫星完整的非线性模型,采用神经网络对直接对非线性模型的最优控制策略进行估计,以应对非线性影响。
2、采用强化学习算法基于可测得数据进行参数辨识,故而可以避免对卫星模型精确性的要求,学习得到最优控制律,同时对卫星部分参数未知情况下具有良好的自适应性,通过与环境进行交互即可辨识出参数并学习出真正的最优控制策略。
3、本发明将卫星相对参考点的位置动态投影至本体坐标系中,从本体坐标系中观察得到的相对位置动态包含了姿态对位置的耦合信息,在本体坐标系中对每个推力器设计出了最优控制。
附图说明
图1为本发明公开方法的卫星编队坐标系示意图;
图2为卫星编队模型示意图;
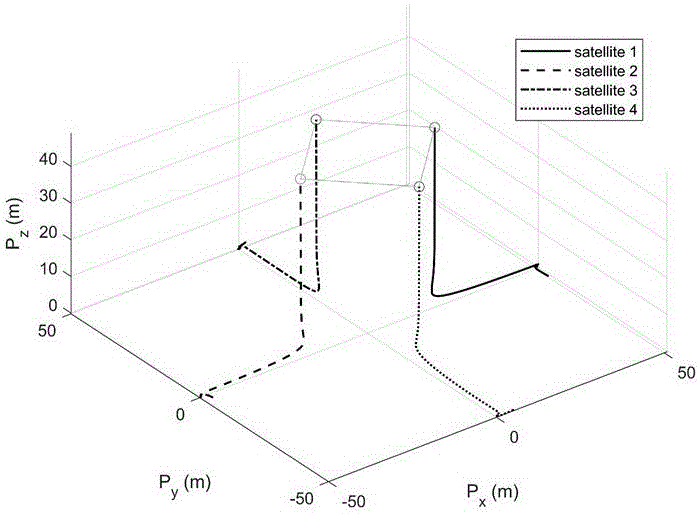
图3为本发明卫星仿真3D飞行效果图;
图4为本发明卫星仿真的姿态跟踪误差图;
图5为本发明卫星仿真的相对位置跟踪误差图。
具体实施方式
下面将结合本申请实施方式中的附图,对本申请的实施方式中的技术方案进行清楚、完整的描述,显然,所描述的实施方式仅仅是作为例示,并非用于限制本申请。
以下结合实施例和附图对本发明进行详细描述,但需要理解的是,所述实施例和附图仅用于对本发明进行示例性的描述,而并不能对本发明的保护范围构成任何限制。所有包含在本发明的发明宗旨范围内的合理的变换和组合均落入本发明的保护范围。
本发明采用的技术方案是,基于强化学习的自适应卫星姿轨控制方法,具体步骤如下:
对本实施方式所公开的技术方案进行进一步说明,需要指出的是,在本实施方式所用的参数符号中,如无特殊说明,
右上角标T代表矩阵转置,如
步骤1:卫星动力学模型:分别建立地心惯性坐标系和每颗卫星的本体坐标系;考虑一组刚体卫星围绕地球运行,每颗卫星包含六个推力器作为它的位置控制执行器,如图1所示,姿态控制力矩在本体坐标系中给出。为了便于编队表示,引入虚拟领导作为整个编队的基准,每颗卫星需要与虚拟领导保持所需要的相对位置,即可构建整个卫星编队,如图2所示。在地心惯性坐标系下建立虚拟领导卫星的轨道动力学模型,并给出每颗卫星的轨道动力学模型,并根据其分别求出每颗卫星与虚拟领导卫星的相对位置动态,并将每颗卫星与虚拟领导卫星的相对位置动态投影至各卫星的本体坐标系后,结合卫星的姿态运动方程,从而给出基于MRPs描述的卫星姿态动力学的拉格朗日表示;具体包括如下步骤:
1.1 给出由虚拟领导卫星的位置矢量及其欧几里得常数、引力加速度矢量、地球引力常数定义的虚拟领导卫星轨道动力学模型;
式中,
1.2建立第i颗实际卫星的轨道动力学模型如下:
式中,
1.3得到第i颗卫星与虚拟领导卫星的相对位置
1.4 得到第
1.5由于控制相对位置的执行器(推力器)固定在卫星本体上,为了控制器设计,将第
式中,
由于上述相对位置动态模型中包含角速度和角加速度,因此存在卫星姿态对相对位置动态的耦合影响。
1.6对卫星姿态动力学进行如下描述:
式中,
为了避免姿态描述的奇异问题,本发明采用修正罗德里格斯参数(MRPs)描述第i颗卫星的姿态
其中
姿态运动学可以写为:
式中,
可以得到基于MRPs描述的卫星姿态动力学的拉格朗日表示:
式中:
M为
步骤2:对编队问题进行描述,得到卫星姿轨耦合的六自由度动态模型如下:
其中:
且
得到包含强非线性和高耦合的卫星六自由度动态模型,可以看到姿态动态对相对位置动态的耦合作用。本实施方式的目的即是设计自适应控制器,控制包含非线性与姿轨耦合的卫星形成所需要的卫星编队。
步骤3:姿态控制器的设计,给出卫星参考信号的动态描述,并定义卫星子系统的价值函数,进一步得到哈密顿函数,通过设计异策略强化学习最优姿态控制算法,得到最优控制策略:
(1)对于编队中的第i颗卫星,式(9)中的姿态动力学可以整理为:
其中:
其中
(2)另卫星的姿态的参考信号动态描述如下:
其中,
(3)从式(11)与式(12)可得到第
其中:
且
(4)采用强化学习方法,针对姿态子系统定义价值函数,结合第i颗卫星的增强动态得到哈密顿函数,根据稳定性条件得到最优姿态控制策略,再将其带入哈密顿函数,设计异策略强化学习最优姿态控制算法,得到贝尔曼方程。
对于一个给定的控制策略
步骤 1:为第i颗卫星设置一个可令系统稳定的初始控制策略与探索噪声,并收集需要的卫星姿态属于与控制输入数据。
步骤 2:使用给定的迭代控制初值和步骤1中收集到的数据,求解贝尔曼方程。
步骤 3:根据求解结果更新控制策略并返回步骤一,直到满足终止条件。
步骤 4:结束。
在本步骤中,由于价值函数和控制策略都是非线性函数,所以贝尔曼方程很难求解。所以引入两个神经网络去估计价值函数和控制策略。
(4)采用强化学习方法,针对相对位置子系统定义价值函数,得到贝尔曼方程,贝尔曼方程解得的最有价值函数,得到最优相对位置控制策略,并将其带入贝尔曼方程,利用如下异策略强化学习相对位置控制算法求解,
和姿态控制器设计类似,可以用两个神经网络(NNs)去估计价值函数和控制策略,且在探索噪声构成的持续激励的条件下,使用最小二乘法(LS)更新神经网络,得到最优的位置控制策略。
在仿真测试中,执行了四颗卫星编队飞行的任务,每颗卫星的参数为:重力加速度g=9.8m/s
每颗卫星的期望姿态为[0 0 0]
以上申请的仅为本申请的一些实施方式。对于本领域的普通技术人员来说,在不脱离本申请创造构思的前提下,还可以做出若干变型和改进,这些都属于本申请的保护范围。