一种基于多尺度深度卷积神经网络的全场位移在线识别方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及多尺度深度卷积神经网络技术领域,特别涉及一种基于多尺度深度卷积神经网络的全场位移在线识别方法。
背景技术
位移场是最直观反映物理实体的当前受载荷状态的物理量之一,可用于表征材料的刚度,评估结构关键部件的损伤状态等。现有的位移场测量方法主要是数字图像相关(DIC)方法,因其操作简单、环境要求低而被广泛应用于表面位移测量。该方法涉及跟踪(或匹配)两个图像之间的相同点,每次跟踪过程涉及优化计算,因而当识别出的斑点图像面积较大时,位移场的计算会非常耗时,导致DIC方法难以实现位移场的在线实时预测。近年来,以深度学习方法为代表的人工智能技术发展迅速,已被成功用于人脸识别、语义分割、自动驾驶等领域。为实现位移场的在线预测,少量研究工作基于深度学习构建了一个3D深度卷积神经网络(CNN)来预测斑点图像的位移,但由于只使用了单尺度子集图像的单尺度卷积神经网络进行模型训练,该方法的预测精度不足,仅适用于小变形。
发明内容
本发明为了解决该问题,本专利提出了一种基于通过融合多个单尺度上学习到的位移信息,实现位移场的准确预测的多尺度神经网络模型的全场位移在线识别方法。
提供一种基于多尺度深度卷积神经网络的全场位移在线识别方法,其特征在于,所述全场位移在线识别方法包括以下步骤:
步骤1,建立散斑图像-位移数据集,标识出散斑图像对应的位移;
步骤2,根据散斑图像的位移,将其分为不同尺度的数据集,并将散斑图裁剪到相应的尺寸;
步骤3,构建基于深度学习的多尺度卷积神经网络,自动判断输入的散斑图的尺度,并输出相应的位移;
所述多尺度卷积神经网络包括特征提取模块和多尺度决策融合模块;
所述特征提取模块包括小尺度CNN网络、中尺度CNN网络、大尺度CNN网络和全尺度CNN网络,分别输出小尺度特征向量、中尺度特征向量、大尺度特征向量和全尺度特征向量;
所述多尺度决策融合模块将四个不同尺度的特征向量生成系数矩阵,并通过系数矩阵与小尺度特征向量、中尺度特征向量和大尺度特征向量进行融合生成输出向量。
更近一步地,所述小尺度CNN网络包括依次连接的第一小尺度卷积模块、平均池化层、第二小尺度卷积模块、第三小尺度卷积模块、第四小尺度卷积模块、第五小尺度卷积模块和第六小尺度卷积模块;
所述中尺度CNN网络包括依次连接的第一中尺度卷积模块、平均池化层、第二中尺度卷积模块、第三中尺度卷积模块、第四中尺度卷积模块、第五中尺度卷积模块和第六中尺度卷积模块;
所述大尺度CNN网络包括依次连接的第一大尺度卷积模块、平均池化层、第二大尺度卷积模块、第三大尺度卷积模块、第四大尺度卷积模块、第五大尺度卷积模块、第六大尺度卷积模块和第七大尺度卷积模块;
所述全尺度CNN网络包括依次连接的第一全尺度卷积模块、平均池化层、第二全尺度卷积模块、第三全尺度卷积模块、第四全尺度卷积模块、第五全尺度卷积模块、第六全尺度卷积模块和第七全尺度卷积模块;
各卷积模块均包括依次连接的数量和尺寸不同的卷积核、归一化单元和Relu函数单元。
更近一步地,在步骤3中,多尺度融合模块中,四个不同尺度的输出数据叠加在一起,然后进入全连接层,生成一个6×1的向量。这个向量被改变形状,然后通过一个SoftMax层,生成一个3×2的系数矩阵
在该系数矩阵中,满足以下等式:
其中,c
其中,u
更近一步地,在步骤3中还包括位移场多尺度卷积神经网络分阶段训练方法:
对每个单尺度网络都是单独训练的,冻结训练和验证后的参数;然后训练多尺度融合模块,只更新多尺度融合模块的权重参数。
更近一步地,在步骤3中,使用模型的预测值与实际值之间的偏差量的均方误差(MSE)来定义:
其中,n是每个迭代步骤中使用的数据数量,
基于训练数据集,通过最小化损失值来学习包括权重W和b在内的模型参数的最佳值:
当得到权重W和偏置b时,融合系数c
本发明达到的有益效果是:
本专利提出了一种基于散斑图像和深度学习的全场位移自动识别方法及智能体,可实现位移场的在线识别。在所提出的新方法中,发展了一种适应于位移场的多尺度神经网络模型,通过融合多个单尺度上学习到的位移信息,实现位移场的准确预测。通过设计实验对所提方法的有效性进行验证,结果表明所提出的全场位移在线识别方法可提供准确的位移预测结果。另外,本专利通过集成该算法于移动装置中,开发了一种可通过图像自动识别位移场的智能体。
多尺度卷积神经网络可以自适应地针对不同尺度的变形进行特征提取,从而使得模型既能识别小变形的位移,也能识别大变形的位移。而且,对各个尺度的位移识别均达到了极高的精度,在测试集上的所有数据的相对误差都小于2%。
附图说明
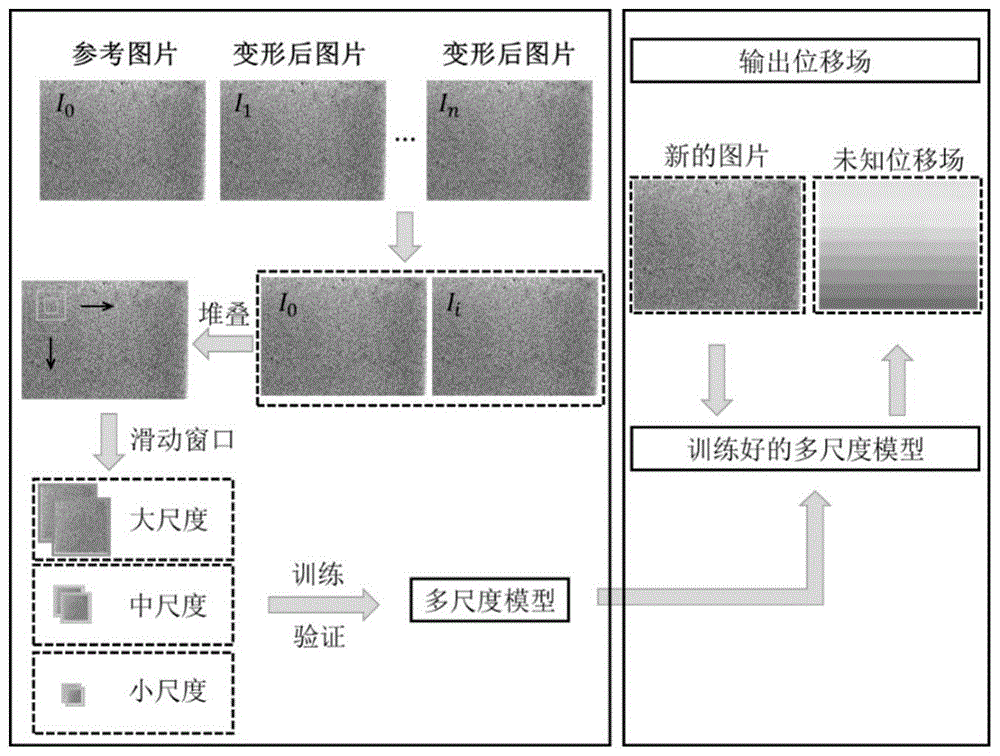
图1为一种基于多尺度深度卷积神经网络的全场位移在线识别方法的流程图;
图2为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中位移场识别多尺度卷积神经网络模型框架图;
图3为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中位移场散斑图像多尺度特征提取模块的示意图;
图4为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中中位移场信息多尺度决策级融合模块的示意图;
图5为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中位移场多尺度CNN训练实验方案示意图;
图6为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中基于单尺度CNN的位移场识别结果示意图;
图7为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中基于单尺度CNN和多尺度CNN的位移场识别精度对比示意图;
图8为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中基于多尺度CNN的位移场识别结果示意图;
图9为一种基于多尺度深度卷积神经网络的全场位移在线识别方法中位移场识别智能体装置装配示意图。
具体实施方式
下面结合附图对本发明的技术方案进行更详细的说明,本发明包括但不仅限于下述实施例。
如附图1所示,本发明提出了一种基于多尺度深度卷积神经网络的全场位移在线识别方法,该全场位移在线识别方法包括以下步骤:
步骤1建立散斑图像-位移数据集,标识出散斑图像对应的位移;
在步骤1中,通过相机采集多张在轴向/扭转试验系统上表面喷有散斑的试样图片,其中包括参考图像和变形图像,其中参考图像为试样在试验前的凸显,变形图像为试样进行试验中的图像。
从采集到的图像中,选取一个矩形区域作为分析区域,分别将每张变形图像与原始图像叠加形成带散斑的叠加图像,在这些图像用于训练和验证CNN模型,以及作为测试数据来验证CNN模型的有效性,其中训练、验证和测试数据比例为7:2:1。
步骤2根据散斑图像的位移,将其分为不同尺度的数据集,并将散斑图裁剪到相应的尺寸;
在步骤2中,基于叠加图像使用滑动采样策略从堆叠的散斑图像中选取关键点,滑动窗口的步长为5像素。然后,以关键点为中心,裁剪出不同大小的子集图像。根据子集图像大小,生成小尺度数据集、中尺度数据集和大尺度数据集。对于不同尺度子集图像,其中心点是一致的,因而这三个数据集的数据量相同,同时不同数据集对应的图像中心和位移标签相同。
步骤3构建基于深度学习的多尺度卷积神经网络,自动判断输入的散斑图的尺度,并输出相应的位移。
如附图2所示,在步骤3中,模型由三部分组成:特征提取模块、单尺度输出模块和多尺度融合输出模块,同时包括以下步骤:
步骤31,位移场多尺度卷积神经网络特征提取:
区别于传统基于单尺度神经网络的位移场识别方法,本专利将散斑图形分割成具有不同像素的大尺度、中尺度和小尺度子集图像,每个尺度均通过深度卷积层进行特征提取。
在多尺度神经网络训练时,目标值在[0,8]像素内的2×48×48像素子集图像作为小尺度CNN的输入数据,目标值在[4,22]内的2×68×68像素子集图像作为中尺度CNN的输入数据,目标值在[20,54]像素内的2×132×132像素子集图像作为大尺度CNN的输入数据,各个尺度的训练子集存在目标值交叉区域,以提高模型在目标值处于跨尺度边界附近的预测精度。目标值在[0,54]像素范围内的132×132像素子集图像作为全尺度CNN的输入数据。
如附图3所示,特征提取模块的网络结构包括小尺度CNN网络、中尺度CNN网络、大尺度CNN网络和全尺度CNN网络。其中,小尺度CNN网络包括依次连接的第一小尺度卷积模块、平均池化层、第二小尺度卷积模块、第三小尺度卷积模块、第四小尺度卷积模块、第五小尺度卷积模块和第六小尺度卷积模块;中尺度CNN网络包括依次连接的第一中尺度卷积模块、平均池化层、第二中尺度卷积模块、第三中尺度卷积模块、第四中尺度卷积模块、第五中尺度卷积模块和第六中尺度卷积模块;大尺度CNN网络包括依次连接的第一大尺度卷积模块、平均池化层、第二大尺度卷积模块、第三大尺度卷积模块、第四大尺度卷积模块、第五大尺度卷积模块、第六大尺度卷积模块和第七大尺度卷积模块;全尺度CNN网络包括依次连接的第一全尺度卷积模块、平均池化层、第二全尺度卷积模块、第三全尺度卷积模块、第四全尺度卷积模块、第五全尺度卷积模块、第六全尺度卷积模块和第七全尺度卷积模块;各卷积模块均包括依次连接的数量和尺寸不同的卷积核、归一化单元和Relu函数单元。
小尺度CNN网络输出小尺度特征向量,中尺度CNN网络输出中尺度特征向量,大尺度CNN网络输出大尺度特征向量,全尺度CNN网络输出全尺度特征向量。
步骤32,位移场多尺度卷积神经网络决策级融合:
该决策融合模块通过设计神经网络,将不同单尺度的位移信息结果进行自动融合,相比传统的经验性融合,其融合方式通过神经网络进行学习,更加准确和智能。在特征提取模块之后,提取的特征进一步通过全连接层,并在每个单独的CNN尺度上生成位移结果。然后,提出了一个多尺度决策融合模块来融合这些在不同尺度上学习到的位移。
如图4所示,在多尺度融合模块中,四个不同尺度的输出数据叠加在一起,然后进入全连接层,生成一个6×1的向量。这个向量被改变形状,然后通过一个SoftMax层,生成一个3×2的系数矩阵
在该系数矩阵中,满足以下等式:
其中,c
其中,u
本发明使用了四种不同尺度的CNN,分别是小尺度CNN、中尺度CNN、大尺度CNN和全尺度CNN。小尺度网络、中尺度网络、大尺度网络的输出在各自的范围内都是准确的,而全尺度网络在所有范围内的输出精度都没有那么高,但是足以判断结果隶属的尺度。因此,通过融合这四个网络的结果,可以计算出合适的系数矩阵来确定正确的结果。所以,全尺度网络的结果虽然不参与融合,但起着重要的决策作用。
步骤33:位移场多尺度卷积神经网络分阶段训练方法:为了训练提出的多尺度卷积神经网络模型,本专利提出了分步训练方式。首先训练图2中的特征提取模块和单尺度输出模块,在这个过程中,每个单尺度网络都是单独训练的,训练和验证后的参数被冻结。然后训练多尺度融合模块,其中只更新多尺度融合模块的权重参数。为了训练模型,需要构建一个损失函数来量化模型的性能。在本专利中,使用模型的预测值与实际值之间的偏差量的均方误差(MSE)来定义:
其中,n是每个迭代步骤中使用的数据数量,
当得到权重W和偏置b时,融合系数c
在一种实施方式中,步骤1,全场位移在线识别多尺度卷积神经网络数据集获取。数据集来自如图5所示的实验。该实验是MTS809轴向/扭转试验系统上进行,拉伸速率为1mm/min。试样材料为316L钢。试样表面喷上散斑,用相机(acA2440-75μm,Basler)进行记录,帧频为5Hz,分辨率为4032×3024像素。
最终共采集到351张斑点图像,包括1张参考图像和350张变形图像,标本应变范围为0%~13%。从采集到的原始图像中,选取一个916×496像素的矩形区域作为分析区域,将变形图像与参考图像叠加形成350张带散斑的叠加图像。在这些数据中,315幅图像用于训练和验证CNN模型,并选择35幅图像作为测试数据来验证CNN模型的有效性。
在步骤2中,基于收集的图像,单尺度CNN的数据集形成如下:使用滑动采样策略从堆叠的散斑图像中裁剪子集图像。根据滑动窗口的大小,生成小尺度数据集、中尺度数据集和大尺度数据集,它们的大小分别为2×48×48、2×68×68和2×132×132。需要注意的是,这三个数据集的数据量完全相同,不同数据集对应的数据中心值和目标值相同。通过滑动采用策略,从每个堆叠的图像中,形成了703个子图像。因此,这三个数据集中的每一个都包含315×703=221445组输入子集图像和目标值,目标值在[0,54]像素范围内。这些数据集以7:2的比例分为训练集和验证集。
在步骤3中,平均池化层均为2*2平均池化;第一小尺度卷积模块为15个步长为1的7*7卷积核;第二小尺度卷积模块为15个步长为1的3*3卷积核;第三小尺度卷积模块为20个步长为2的3*3卷积核;第四小尺度卷积模块为60个步长为1的3*3卷积核;第五小尺度卷积模块为60个步长为1的3*3卷积核;第六小尺度卷积模块为120个步长为2的3*3卷积核;第一中尺度卷积模块为15个步长为1的7*7卷积核;第二中尺度卷积模块为30个步长为2的3*3卷积核;第三中尺度卷积模块为30个步长为1的3*3卷积核;第四中尺度卷积模块为60个步长为2的3*3卷积核;第五中尺度卷积模块为120个步长为2的3*3卷积核;第六中尺度卷积模块为120个步长为1的3*3卷积核;第一大尺度卷积模块为15个步长为1的7*7卷积核;第二大尺度卷积模块为15个步长为1的3*3卷积核;第三大尺度卷积模块为30个步长为2的3*3卷积核;第四大尺度卷积模块为30个步长为1的3*3卷积核;第五大尺度卷积模块为60个步长为2的3*3卷积核;第六大尺度卷积模块为120个步长为2的3*3卷积核;第七大尺度卷积模块为240个步长为2的3*3卷积核;第一全尺度卷积模块为15个步长为1的7*7卷积核;第二全尺度卷积模块为15个步长为1的3*3卷积核;第三全尺度卷积模块为30个步长为2的3*3卷积核;第四全尺度卷积模块为30个步长为1的3*3卷积核;第五全尺度卷积模块为60个步长为2的3*3卷积核;第六全尺度卷积模块为120个步长为2的3*3卷积核;第七全尺度卷积模块为240个步长为2的3*3卷积核。
在训练多尺度CNN模型时,首先单独训练每个单尺度CNN,然后训练多尺度融合模块。为了提高预测精度,在多尺度模型中训练每个单尺度CNN时,只使用了上面提到的单尺度数据集的部分数据。在多尺度模型中,小尺度子数据集由单个小尺度数据集中目标值在[0,8]范围内的图像组成;中尺度子数据集由单个中尺度数据集中目标值在[4,22]范围内的图像组成。大尺度子数据集由单个大尺度数据集中目标值在[20,54]范围内的图像组成。结果,总共使用了50039幅小尺度图像、146236幅中尺度图像和174189幅大尺度图像分别训练多尺度模型中的小尺度、中尺度和大尺度CNN。此外,全尺度CNN在上述单尺度大尺度数据集上进行了训练。
全场位移在线识别多尺度卷积神经网络训练。对于单尺度CNN,模型训练过程共使用了172235张图像,每次训练迭代使用8个mini-batch大小。在训练过程中,三个单尺度CNN的训练损失在30个epoch后收敛到一个很小的值。验证数据集(49210张图像)用于验证训练网络。验证数据集的最终训练损失与30个epoch的训练结果损失非常相似。因此,具有30个epoch的训练网络被认为是预测测试图像中位移的基准。
对于本专利提出的多尺度CNN,首先使用来自子数据集的图像在多尺度模型中训练特征提取模块。随后,三个单尺度图像集训练多尺度融合模块的参数。最后,多尺度网络的训练损失在30个epoch后也收敛到一个较小的值。因此,在后续测试中,以30个epoch为基准来预测测试集中的位移。
通过验证数据集对位移场识别多尺度卷积神经网络模型验证。采用测试数据集验证上述训练的CNN的有效性。在单尺度CNN中,为了评估模型的性能,小、中、大单尺度CNN模型分别预测了1%、8%和13%应变的散斑图像。在预测过程中,首先通过滑动采样策略将图像裁剪成小、中、大尺度的图像子集。然后,将子集图像分别输入到单尺度CNN中,通过该CNN可以预测子集图像中心的位移。最后,通过整合所有中心的位移,可以得到使用三种不同尺度的CNN预测的位移场结果。图6显示了三个单尺度CNN预测的结果。可以发现,单尺度CNN均无法有效预测试样在整个应变范围内的位移场。
使用上述三个单尺度CNN预测了15个应变范围为1-13%的散斑图像。将预测精度定义为预测值落在真实值2%以内的比例。图7显示了三个单尺度CNN模型在不同应变下的精度。可发现,小尺度的CNN在应变较小时表现最好,中尺度的CNN在应变处于中间值时表现最好,而大尺度的CNN在应变较大时表现最好。因此,融合多尺度信息是必要的。
为了评估所提出的多尺度CNN模型的性能,使用多尺度CNN模型预测散斑图像在1%、8%和13%应变下的位移场。图8显示了所提出的多尺度CNN模型的可视化结果。在多尺度CNN的预测过程中,首先将输入图像裁剪成2×48×48、2×68×68和2×132×132三种不同尺寸的子集图像。对于图像中的任意点,包括小尺度、中尺度和大尺度子集图像三个子集图像。这些子集图像被一起输入到多尺度CNN模型中,以预测每个点的位移。通过滑动采样技术,可以获得整个位移场。
如图8所示,可以看出,所提出的多尺度CNN模型预测的位移场的值和分布与实际结果完全相同,无论是小应变情况还是大应变情况。在1%、8%和13%应变下,y方向的平均绝对误差分别等于0.039、0.121和0.209像素,x方向的平均绝对误差分别等于0.013、0.031,和0.02像素,误差值都非常小。多尺度CNN模型在不同应变下的预测精度如图7所示。结果表明,在所有应变范围内,预测值全部落在真实值的2%以内。与单尺度模型相比,多尺度模型在预测精度和范围上都具有显著优势。
将训练的模型嵌入到如图9所示的多尺度卷积神经网络位移场在线识别智能体,该装置由树莓派4B开发板、搭载35mm长焦镜头的HQ Camera摄像头、7寸电容屏、装置整体外壳、树莓派电源线、Type-C线和螺丝螺母组成。开发板放置在外壳的内部,外壳前部安装了HQ Camera摄像头,摄像头上辅助安装了长焦镜头方便调节装置放在试件不同距离位置时进行调焦拍摄,外壳后部安装了7寸的触摸电容屏,方便进行触摸操作和查看裂纹测试结果,树莓派电源线接口和Type-C线接口分别在外壳的左右两侧,连接上电源后装置即可启动,可设置装置连接有线或无线网,连接云端服务器进行计算,提升计算速度。
发明不仅局限于上述具体实施方式,本领域一般技术人员根据实施例和附图公开内容,可以采用其它多种具体实施方式实施本发明,因此,凡是采用本发明的设计结构和思路,做一些简单的变换或更改的设计,都落入本发明保护的范围。
- 一种基于多尺度卷积神经网络的静态手势识别方法
- 一种基于深度卷积神经网络的模式识别方法
- 基于深度残差多尺度一维卷积神经网络的雷达目标识别方法
- 基于深度卷积神经网络的多尺度巡检图像识别方法及装置