在图片中提取用药记录方法及装置、存储介质、电子设备
文献发布时间:2023-06-19 19:27:02
技术领域
本申请涉及文字抽取技术领域,尤其是涉及到一种在图片中提取用药记录方法及装置、存储介质和电子设备。
背景技术
患者招募是给进入临床试验阶段的新研发的药物招募临床试验的患者,以测试药物的有效性。临床试验对患者有严格的要求,需要患者提供过往用药过程的材料才能够判断患者是否满足临床试验的条件。在现实的实践中,患者提供的往往是图片式的病历材料,如何从图片病历中抽取重要的患者用药史是迫切需要解决的问题。
然而,当前并没有专用于从图片病历中提取用药记录的技术。由于用药史存在日期可能连续出现、用药记录包含多种药物的组合等特殊性,普通的从电子病历等电子数据中提取信息的手段,并不完全适用于这种特殊的应用场景。
发明内容
有鉴于此,本申请提供了一种在图片中提取用药记录方法及装置、存储介质和电子设备,解决了现有的信息提取方法不适用于从图片中提取用药史的问题。
根据本申请的一个方面,提供了一种在图片中提取用药记录方法,包括:
在目标图片中提取目标文本段;
在所述目标文本段中搜索药物名称,并将搜索到的目标药物名称作为标的字符串;
确定所述标的字符串的第一个字符为所述第一标的位置,所述标的字符串之后的第一个字符为第二标的位置;
从所述第一标的位置开始,向前搜索用药日期文本,其中,所述用药日期文本包含一个或多个日期,每两个相邻所述日期之间的间隔字符数不大于预设间隔阈值;
从所述第二标的位置开始,向后搜索用药描述文本;
将所述用药日期文本、所述用药描述文本以及所述用药日期文本与所述用药描述文本之间的字符作为用药记录,添加至用药记录集合中;
在所述目标文本段中剔除所述用药记录,得到新的目标文本段,并返回至在所述目标文本段中搜索药物名称的步骤,直至在所述目标文本段中搜索不到所述药物名称。
可选地,所述从所述第一标的位置开始,向前搜索用药日期文本,包括:
从所述第一标的位置开始向前搜索,并将搜索到的第一个日期第一个字符作为第一起始搜索位置,所述第一个日期的最后一个字符作为结束位置;
提取所述第一起始搜索位置之前的第一预设数量个字符,组成第一待搜索字符串,并在所述第一待搜索字符串中搜索所述日期;
若搜索到所述日期,则将所述日期的第一个字符位置作为新的第一起始搜索位置,并返回至所述提取所述第一起始搜索位置之前的第一预设数量个字符的步骤;
若未搜索到所述日期或所述第一起始搜索位置之前的字符数量小于所述第一预设数量,则停止搜索;
将所述第一起始搜索位置与所述结束位置之间的字符作为用药日期文本添加至用药日期集合中。
可选地,所述从所述第二标的位置开始,向后搜索用药描述文本,包括:
将所述第二标的位置作为第二起始搜索位置,提取所述第二起始搜索位置之后的第二预设数量个字符,组成第二待搜索字符串,并在所述第二待搜索字符串中搜索用药描述,其中,所述用药描述包括药物名称以及用药剂量;
若搜索到所述用药描述,则确定所述用药描述的最后一个字符位置为新的第二起始搜索位置,并返回至所述提取所述第二起始搜索位置之后的第二预设数量个字符的步骤;
若未搜索到所述用药描述或搜索到日期,则停止搜索;
将所述第一标的位置与所述第二起始搜索位置之间的字符作为用药描述文本添加至用药描述集合中。
可选地,在所述若未搜索到所述用药描述或搜索到日期,则停止搜索之后,所述方法还包括:
若所述第二起始搜索位置与所述第二标的位置相同,则在所述第一标的位置后搜索截止符,并将所述第一标的位置与所述截止符之间的字符作为所述用药描述文本添加至用药描述集合中。
可选地,所述提取所述第二起始搜索位置之后的第二预设数量个字符,组成第二待搜索字符串,包括:
确定所述第二起始搜索位置与所述目标文本段的最后一个字符之间的长度;
若所述长度小于所述第二预设数量,则调整所述第二预设数量为所述长度。
可选地,所述在目标图片中提取目标文本段,包括:
将所述目标图片分割成多个子图片,其中,每个所述子图片内的文字与所述子图片的底边平行;
旋转所述目标图片,至所述目标图片的底边与所述子图片的底边平行,并分别确定每个所述子图片的中点的横坐标以及纵坐标;
根据所述横坐标以及纵坐标对所述子图片进行排序,得到子图片矩阵,其中,所述子图片矩阵中每一行子图片的中点的横坐标按照升序排序,每一列子图片的中点的纵坐标按照升序排序;
分别提取每个所述子图片中的子文本段,并按照每个所述子图片在所述子图片矩阵中的位置,拼接所述子文本段得到所述目标文本段。
可选地,所述将所述目标图片分割成多个子图片,包括:
根据所述图片中每行文字的高度以及宽度设置矩形检测框;
利用所述矩形检测框分割所述目标图标,以使每个所述子图片包含一行文字。
可选地,在所述直至在所述目标文本段中搜索不到所述药物名称之后,所述方法还包括:
在所述用药记录集合中提取数值记录以及文字记录;
确定所述数值记录与所述数值描述之间的第一匹配结果,以及所述文字记录与所述文字描述之间的第二匹配结果;
根据所述第一匹配结果以及第二匹配结果,确定所述目标图片对应的目标患者与所述目标药物试验之间的目标匹配结果。根据本申请的另一方面,提供了一种在图片中提取用药记录装置,所述装置包括:
文字识别模块,用于在目标图片中提取目标文本段;
位置标记模块,用于在所述目标文本段中搜索药物名称,并将搜索到的目标药物名称作为标的字符串;以及,确定所述标的字符串的第一个字符为所述第一标的位置,所述标的字符串之后的第一个字符为第二标的位置;
第一提取模块,用于从所述第一标的位置开始,向前搜索用药日期文本,其中,所述用药日期文本包含一个或多个日期,每两个相邻所述日期之间的间隔字符数不大于预设间隔阈值;
第二提取模块,用于从所述第二标的位置开始,向后搜索用药描述文本;
记录模块,用于将所述用药日期文本、所述用药描述文本以及所述用药日期文本与所述用药描述文本之间的字符作为用药记录,添加至用药记录集合中;
循环模块,用于在所述目标文本段中剔除所述用药记录,得到新的目标文本段,并返回至在所述目标文本段中搜索药物名称的步骤,直至在所述目标文本段中搜索不到所述药物名称。
可选地,所述第一提取模块,用于:
从所述第一标的位置开始向前搜索,并将搜索到的第一个日期第一个字符作为第一起始搜索位置,所述第一个日期的最后一个字符作为结束位置;
提取所述第一起始搜索位置之前的第一预设数量个字符,组成第一待搜索字符串,并在所述第一待搜索字符串中搜索所述日期;
若搜索到所述日期,则将所述日期的第一个字符位置作为新的第一起始搜索位置,并返回至所述提取所述第一起始搜索位置之前的第一预设数量个字符的步骤;
若未搜索到所述日期或所述第一起始搜索位置之前的字符数量小于所述第一预设数量,则停止搜索;
将所述第一起始搜索位置与所述结束位置之间的字符作为用药日期文本添加至用药日期集合中。
可选地,所述第二提取模块,用于:
将所述第二标的位置作为第二起始搜索位置,提取所述第二起始搜索位置之后的第二预设数量个字符,组成第二待搜索字符串,并在所述第二待搜索字符串中搜索用药描述,其中,所述用药描述包括药物名称以及用药剂量;
若搜索到所述用药描述,则确定所述用药描述的最后一个字符位置为新的第二起始搜索位置,并返回至所述提取所述第二起始搜索位置之后的第二预设数量个字符的步骤;
若未搜索到所述用药描述或搜索到日期,则停止搜索;
将所述第一标的位置与所述第二起始搜索位置之间的字符作为用药描述文本添加至用药描述集合中。
可选地,所述第二提取模块,还用于:
若所述第二起始搜索位置与所述第二标的位置相同,则在所述第一标的位置后搜索截止符,并将所述第一标的位置与所述截止符之间的字符作为所述用药描述文本添加至用药描述集合中。
可选地,所述第二提取模块,还用于:
确定所述第二起始搜索位置与所述目标文本段的最后一个字符之间的长度;
若所述长度小于所述第二预设数量,则调整所述第二预设数量为所述长度。
可选地,所述文字识别模块,用于:
将所述目标图片分割成多个子图片,其中,每个所述子图片内的文字与所述子图片的底边平行;
旋转所述目标图片,至所述目标图片的底边与所述子图片的底边平行,并分别确定每个所述子图片的中点的横坐标以及纵坐标;
根据所述横坐标以及纵坐标对所述子图片进行排序,得到子图片矩阵,其中,所述子图片矩阵中每一行子图片的中点的横坐标按照升序排序,每一列子图片的中点的纵坐标按照升序排序;
分别提取每个所述子图片中的子文本段,并按照每个所述子图片在所述子图片矩阵中的位置,拼接所述子文本段得到所述目标文本段。
可选地,所述文字识别模块,还用于:
根据所述图片中每行文字的高度以及宽度设置矩形检测框;
利用所述矩形检测框分割所述目标图标,以使每个所述子图片包含一行文字。
可选地,所述装置还包括匹配模块,用于:
在所述用药记录集合中提取数值记录以及文字记录;
获取目标药物试验对应的数值描述以及文字描述;
确定所述数值记录与所述数值描述之间的第一匹配结果,以及所述文字记录与所述文字描述之间的第二匹配结果;
根据所述第一匹配结果以及第二匹配结果,确定所述目标图片对应的目标患者与所述目标药物试验之间的目标匹配结果。
根据本申请又一个方面,提供了一种存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述在图片中提取用药记录方法。
根据本申请再一个方面,提供了一种电子设备,包括存储介质、处理器及存储在存储介质上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述在图片中提取用药记录方法。
借由上述技术方案,本申请针对图片病例的特性,例如用药日期经常连续出现、常是组合用药、而且夹杂着ocr识别错误等情况,利用前向后向递归搜索,精确的向前搜索判断患者的用药时间,向后搜索得到用药描述的起止位置,保证了语义的完整性,得到完整且无冗余的病史信息。
上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1示出了本申请实施例提供的一种在图片中提取用药记录方法的流程示意图;
图2示出了本申请实施例提供的另一种在图片中提取用药记录方法的流程示意图;
图3示出了本申请实施例提供的另一种在图片中提取用药记录方法的矩形检测框示意图;
图4示出了本申请实施例提供的一种在图片中提取用药记录装置的结构框图。
具体实施方式
下文中将参考附图并结合实施例来详细说明本申请。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
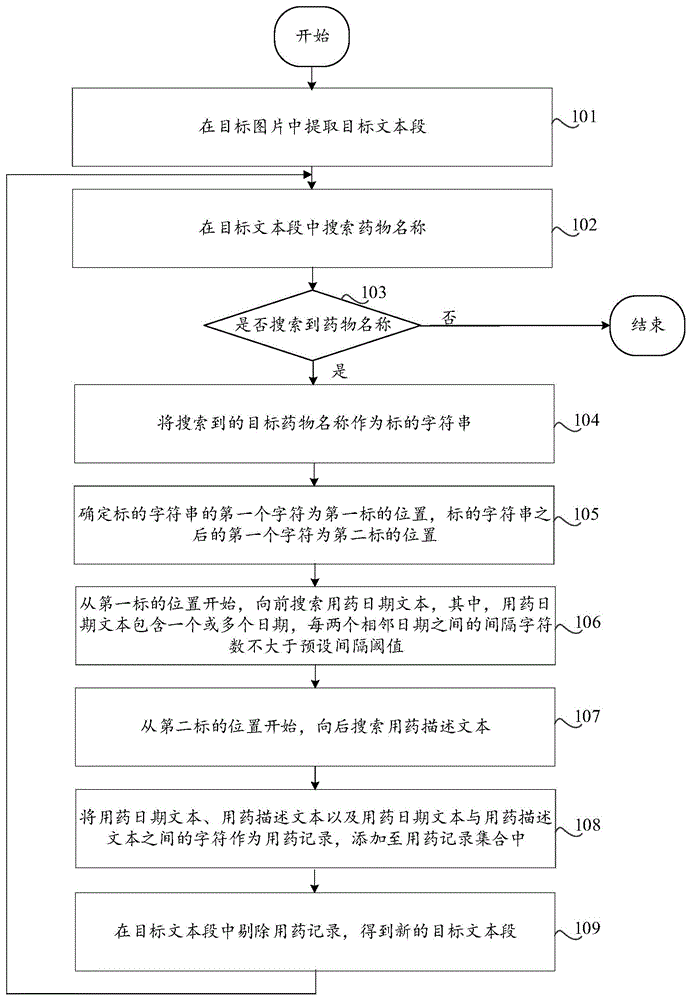
在本实施例中提供了一种在图片中提取用药记录方法,如图1所示,该方法包括:
步骤101,在目标图片中提取目标文本段;
本申请实施例提供的在图片中提取用药记录的方法,用于在患者提供的图片病历中提取用药史,其中,用药史包括用药时间以及药物名称等。
其中,可对目标图片进行OCR(光学字符识别)识别以实现文字提取,并将识别结果聚合成一个段落,以供下一步骤对用药记录进行搜索。
步骤102,在目标文本段中搜索药物名称;
步骤103,是否搜索到药物名称;若是,则跳转至步骤104;若否,则跳转至步骤109;
步骤104,将搜索到的目标药物名称作为标的字符串;
步骤105,确定标的字符串的第一个字符为第一标的位置,标的字符串之后的第一个字符为第二标的位置;
在步骤102-步骤105中,在目标文本段中确定标的位置,进而从标的位置开始执行前向以及后向搜索。具体地,首先定位搜索到的药物名称也即目标药物名称first_drug的位置,在其前后分别递归搜索日期和其它组合用药名称,获取pre_str和post_str,用药记录pre_str+first_drug+post_str就是原文中的一段话。基于以上这种连续查找用药名称,且后向递归药名搜索的方式,可以很大程度上对OCR的识别错误进行容错。
优选地,目标药物名称可以为目标文本段中的第一个药物名称。
步骤106,从第一标的位置开始,向前搜索用药日期文本,其中,用药日期文本包含一个或多个日期,每两个相邻日期之间的间隔字符数不大于预设间隔阈值;
步骤107,从第二标的位置开始,向后搜索用药描述文本;
在步骤106-步骤107中,图片病历中通常会包括用药的日期以及药品名称等信息,通常情况下,用药日期在药品名称之前,例如,2008年1月1日至2008年3月15日,药品A。基于此,从第一标的位置开始,向前进行搜索,得到用药日期文本。
此外,由于日期可能连续出现,而连续日期之间不应过多夹杂其它字符,因此用药日期可以为多个,且每两个相邻用药日期之间的间隔字符数小于预设值。例如,2022-06-14至2022-07-14,是由两个用药日期组成的连续日期,表明患者在连续日期内持续用药。
优选地,预设间隔阈值为2。
同理,在第二标的位置开始,向后进行搜索,得到用药描述文本,其中,用药描述文本可以包括药物名称以及用量等信息。
步骤108,将用药日期文本、用药描述文本以及用药日期文本与用药描述文本之间的字符作为用药记录,添加至用药记录集合中;
步骤109,在目标文本段中剔除用药记录,得到新的目标文本段,并返回至步骤102。
在步骤108-步骤109中,在针对目标药物名称对应的标的位置进行前向以及后向搜索后,将搜索到的用药日期文本、用药描述文本以及用药日期文本与用药描述文本之间的字符作为用药记录,添加至用药记录集合中。在目标文本段中剔除该用药记录,并在剩下的内容中再次搜索药物名称,进而对再次搜索到的目标药物名称进行前向以及后向搜索,并根据搜索结果得到新的用药记录,以此实现循环搜索,以达到在整个图片中提取用药信息的目的。
通过应用本实施例的技术方案,针对图片病例的特性,例如用药日期经常连续出现、常是组合用药、而且夹杂着ocr识别错误等情况,利用前向后向递归搜索,精确的向前搜索判断患者的用药时间,向后搜索得到用药描述的起止位置,保证了语义的完整性,得到完整且无冗余的病史信息。
进一步地,作为上述实施例具体实施方式的细化和扩展,为了完整说明本实施例的具体实施过程,提供了另一种在图片中提取用药记录方法,从第一标的位置开始,向前搜索用药日期文本,包括:
步骤201,从第一标的位置开始向前搜索,并将搜索到的第一个日期第一个字符作为第一起始搜索位置,第一个日期的最后一个字符作为结束位置;
步骤202,提取第一起始搜索位置之前的第一预设数量个字符,组成第一待搜索字符串,并在第一待搜索字符串中搜索日期;
步骤203,若搜索到日期,则将日期的第一个字符位置作为新的第一起始搜索位置,并返回至提取第一起始搜索位置之前的第一预设数量个字符的步骤;
步骤204,若未搜索到日期或第一起始搜索位置之前的字符数量小于第一预设数量,则停止搜索;
步骤205,将第一起始搜索位置与结束位置之间的字符作为用药日期文本添加至用药日期集合中。
在该实施例中,在搜索到的第一个药名的位置前面搜寻以日期开始的子字符串,由于日期可能连续出现,因此采用递归搜索的方式。具体地,在第一标的位置之前,向前搜索用药日期,直至搜索到第一个日期。然后从搜索到的日期所在的位置前面开始继续搜索下一个用药日期。
其中,一般来说类似2022-06-14的日期占10个字符,连续日期之间不应过多夹杂其它字符,因此,在继续向前搜索的过程中,每次搜索的字符数量也即第一预设数量可设定为12。
若搜索到用药日期,则继续递归搜索,直至搜索不到日期或第一起始搜索位置之前的字符数量小于第一预设数量。最后将第一起始位置与结束位置之间的字符作为用药日期文本。
此外,在搜索到用药日期后,在继续递归搜索的过程中,若搜索到用药名称,则认为搜索到了目标药物名称的搜索边界,因此停止搜索,同样将第一起始位置与结束位置之间的字符作为用药日期文本。
具体地,前向日期递归搜索算法如下:
输入:目标图片OCR之后排序聚合的结果page_ocr_str,搜索开始位置start_pos
If start_pos<12:
returnstart_pos;
End
在搜索开始位置前的12字符内搜索日期
lf日期不存在:
returnstart_pos
else:
以搜到的日期第一个字符位置作为新的搜索开始位置new_start_pos
递归调用本算法(page_ocr_str,new_start_pos)
End
输出:搜索到的最后一个日期的起始位置。
例如,针对目标文本段“免疫组化:MLH1(+),MSH2(+),MSH6(+),PMS2(+),EGFR(+),HER-2(0),PD-L1(-),Ki-67阳性指数约60%。术后好转出院,2021-02-16至2021-05-30在我科行FP方案化疗5周期,具体为:氟尿嘧啶0.75gd1-5+顺铂20mg d1-5……”,可以确定第一个药名为“氟尿嘧啶”,在“氟尿嘧啶”之前,向前搜索用药日期,得到第一个用药日期“2021-05-30”。将该用药日期的第一个字符也即2作为第一起始位置,第一个用药日期的最后一个字符也即0作为结束位置。从第一起始搜索位置开始向前提取12个字符,得到第一待搜索字符串“,2021-02-16至”,在该第一待搜索字符串中搜索到日期“2021-02-16”,将该日期的第一个字符2作为新的第一起始位置,继续向前搜索,直至搜索不到新的日期,停止搜索。此时将新的第一起始位置与结束位置之间的字符提取出来,得到“2021-02-16至2021-05-30”,也即用药日期文本为“2021-02-16至2021-05-30”。
该实施例利用递归调用的方式,可以实现连续日期的搜索,适用于提取用药记录这一特殊的应用场景。
进一步地,在另一种在图片中提取用药记录方法中,从第二标的位置开始,向后搜索用药描述文本,包括:
步骤301,将第二标的位置作为第二起始搜索位置,提取第二起始搜索位置之后的第二预设数量个字符,组成第二待搜索字符串,并在第二待搜索字符串中搜索用药描述,其中,用药描述包括药物名称以及用药剂量;
步骤302,若搜索到用药描述,则确定用药描述的最后一个字符位置为新的第二起始搜索位置,并返回至提取第二起始搜索位置之后的第二预设数量个字符的步骤;
步骤303,若未搜索到用药描述或搜索到日期,则停止搜索;
步骤304,将第一标的位置与第二起始搜索位置之间的字符作为用药描述文本添加至用药描述集合中。
在该实施例中,在搜索到的第一个药名的位置后面搜寻用药描述,其中,用药描述包括药物名称以及用药剂量。由于患者一般是多种药物联合使用,为了提供连续、易读的用药信息,采用后向递归搜索的方法。具体地,在第二标的位置开始,向后搜索用药描述,直至搜索到第一个用药描述。然后从搜索到的用药描述所在的位置向后开始继续搜索下一个用药描述。
其中,由于用药描述通常较长,因此,在向后搜索的过程中,每次搜索的字符数量也即第二预设数量可设定为一个较大的数值。
若搜索到用药描述,则继续递归搜索,直至搜索不到新的用药描述或搜索到日期位置。最后将第一标的位置与第二起始位置之间的字符作为用药日期文本。
具体地,后向用药递归搜索算法如下:
输入:图片OCR之后排序聚合的结果page_ocr_str,搜索开始位置start_pos
搜索结束位置end_pos=startpos+10
If end_pos>len(page_ocr_str):
end_pos=len(page_ocr_str)
End
在(start_posend_pos)范围内搜索药名
lf药名不存在:
return start pos
else:
以搜到药名最后一个字符的位置作为新的搜索开始位置new_start_pos
递归调用本算法(page_ocr_str,new_start_pos)
End
输出:搜索到的最后一个药名的结束位置。
例如,例如,针对目标文本段“2021-02-16至2021-05-30在我科行FP方案化疗5周期,具体为:氟尿嘧啶0.75gd1-5+顺铂20mg d1-5,+亚叶酸钙200mg d1-5,同时予以护胃、止呕等对症处理,后好转出院。现患者为求下一步诊疗,就诊于我科,门诊以“食管癌”收入我科,患者自手术以来,神志清,精神可,饮食睡眠可,大小便正常。”,可以确定第一个药名为“氟尿嘧啶”,第一标的位置为“氟”,第二标的位置为“0”。在“氟尿嘧啶”之后,从第二标的位置也即第二起始搜索位置开始,向后搜索用药描述,得到第一个药物描述“0.75gd1-5”。将该用药描述的最后一个字符也即5作为第二起始位置,从第二起始搜索位置开始向后递归搜索,依次搜索到“顺铂”、“20mg d1-5”、“亚叶酸钙”以及“200mg d1-5”,直至搜索不到新的用药描述,停止搜索。此时将第一标的位置与新的第二起始位置之间的字符提取出来,得到“氟尿嘧啶0.75gd1-5+顺铂20mg d1-5,+亚叶酸钙200mg d1-5”,也即用药描述文本为“氟尿嘧啶0.75gd1-5+顺铂20mg d1-5,+亚叶酸钙200mg d1-5”。
该实施例通过这种递归搜索的方式,假若中间一两个药名因OCR识别错误无法找到,下一次递归可跳过识别错误的药名,在形成的一整句话中,避免因OCR错误导致用药信息提取遗漏,实现了OCR识别的容错。
进一步地,在另一种在图片中提取用药记录方法中,在若未搜索到用药描述或搜索到日期,则停止搜索之后,方法还包括:
步骤401,若第二起始搜索位置与第二标的位置相同,则在第一标的位置后搜索截止符,并将第一标的位置与截止符之间的字符作为用药描述文本添加至用药描述集合中。
在该实施例中,若第二起始搜索位置与第二标的位置相同,也即在向后搜索的过程中,未搜索到任何一个用药描述,此时,为避免遗漏用药信息,在第一标的位置开始向后搜索截止符,在将第一标的位置与截止符之间的字符均提取出来作为用药描述文本。
优选地,截止符可以为句号“。”。
例如,针对目标文本段“2021-02-16至2021-05-30在我科行FP方案化疗5周期,具体为:氟尿嘧啶,好转出院。现患者为求下一步诊疗,就诊于我科,门诊以“食管癌”收入我科。”,可以确定第一个药名为“氟尿嘧啶”,第一标的位置为“氟”,第二标的位置为“,”。将第二标的位置作为第二起始搜索位置,在“氟尿嘧啶”之后,从第二起始位置开始,向后搜索用药描述,由于未搜索到任何用药描述,因此第二起始搜索位置未进行递归迭代,始终与第二标的位置相同。此时从第一标的位置“氟”开始向后搜索截止符“。”,并提取第一标的位置与截止符之间的所有字符“氟尿嘧啶,好转出院。”,也即用药描述文本为“氟尿嘧啶,好转出院。”。
该实施例通过这样的搜索方式,使得搜索得到的用药描述文本为一段具有实际意义的文字,语义完整连续,避免出现遗漏信息的情况。
进一步地,在另一种在图片中提取用药记录方法中,提取第二起始搜索位置之后的第二预设数量个字符,组成第二待搜索字符串,包括:
步骤501,确定第二起始搜索位置与目标文本段的最后一个字符之间的长度;
步骤502,若长度小于第二预设数量,则调整第二预设数量为长度。
在该实施例中,由于用药描述的文字一般较多,因此第二预设数量可以设置为一个较大的数字。并且在向后递归搜索的过程中,第二起始搜索位置逐渐向后移动,第二起始搜索位置与目标文本段最后一个字符之间的长度也随之减小。在该长度小于第二预设数量时,可以理解的是,此时无法从第二起始搜索位置之后提取出第二预设数量个字符作为第二待搜索字符串,基于此,调整第二预设数量的大小,将第二预设数量设置为与该长度相同,也即将第二起始搜索位置至目标文本段末尾的所有字符提取出来作为第二待搜索字符串。
该实施例通过调整第二预设数量的大小,解决了第二起始搜索位置与目标文本段末尾之间的字符数量不足的问题。
图2示出了本申请实施例的另一种在图片中提取用药记录方法的流程图,如图所示,对图片病例进行ORC识别得到如下的目标文本段“rdo00ty75次,病情一直平稳,患者曾多次来院复查均未发现明品复发与转移。于2020年6月14日遭医嘱来院复查开治疗,胸部CT;L双肺多发结节灶(左肿下叶背段结节为大),右帅门种大洋巴结,性质待定:转移其他持排,建议PET-CT或左肺下叶背段结节活检,于6月20日行皮肺穿刺话检病理示:(左下肺肿块)中分化腺癌,结合免疫组果:CDX-2(4).Ki67(+).TTF-1(-).Nap*inA(-),CK-7,c20(+)考虑肠腺癌转移。于2020年6月29日入省肿瘤医院入组临床实验,因基因检测不符合入组条件,于2020年7月11日,8月8日,8月30日再求治于我科,予贝伐单珠机370ng+雷替由嘉4.4ng治疗3周期,2020年9月25日于我科行伊立替康120m治疗一周期,专者手足麻木,乏力,翻身困难于2020年10月2日在我院神经内科治疗好转后出院。患者感反复全身乏力件头颈部疼痛。于11月2日、12月24日在我院康复科予以话血化瘀,营养支持治疗,患者在家自行口服味唑替尼,多次因手足麻木来我院予以营养种经,中药抗肿瘤等治疗,2021年3月21人因腹再来院治疗,予以营养神经、护胃、中药调理等对症治疗后出院。后多次米我院复查,病情稳定,今日患者来我院复查,门诊以"直肠癌"收住我科,患者入院时于足麻木,乏力。自起病来,精神尚可、睡眠可,食纳尚可,小便正常。”。
具体搜索过程如下:在目标文本段中搜索到第一个药物名称“贝伐单珠机”,并从“贝伐单珠机”所在的位置开始分别向前搜索日期、向后搜索药物描述。在向前搜索的过程中,依次得到“2020年7月11日”,“8月8日”,“8月30日”三个用药日期,而“2020年6月29日”由于距离“2020年7月11日”较远未搜索到,此时,第一起始搜索位置为“2020年7月11日”的第一个字符,结束位置为“8月30日”的最后一个字符。因此,提取到用药日期文本“2020年7月11日,8月8日,8月30日”。同理,在向后搜索的过程中,搜索得到“370ng+雷替由嘉4.4ng治疗3周期”,并在搜索到日期时停止搜索,此时,提取用药日期文本、用药描述文本以及用药日期文本与用药描述文本之间的字符,得到“2020年7月11日、8月8日、8月30日再求治于我科,予贝伐单珠抗370mg+雷替曲塞4.4mg治疗3周期”。
同理,在剔除掉提取的字符后,在新的目标文本段中搜索到第一个药物名称“伊立替康”,并再次分别向前搜索日期、向后搜索药物描述,其搜索过程不再赘述。
进一步地,在另一种在图片中提取用药记录方法中,在目标图片中提取目标文本段,包括:
步骤601,将目标图片分割成多个子图片,其中,每个子图片内的文字与子图片的底边平行;
步骤602,旋转目标图片,至目标图片的底边与子图片的底边平行,并分别确定每个子图片的中点的横坐标以及纵坐标;
步骤603,根据横坐标以及纵坐标对子图片进行排序,得到子图片矩阵,其中,子图片矩阵中每一行子图片的中点的横坐标按照升序排序,每一列子图片的中点的纵坐标按照升序排序;
步骤604,分别提取每个子图片中的子文本段,并按照每个子图片在子图片矩阵中的位置,拼接子文本段得到目标文本段。
在该实施例中,在对图片进行文字识别的过程中,将图片分割成多个子图片,并分别对子图片进行文字识别,然后再将子图片组合起来,也即识别到的多个子文本段组合起来,得到最终的目标文本段。
由于用户拍摄图片病例时,可能出现图片偏斜等情况,此时直接对识别结果进行从上到下,从左到右进行排序合并会影响识别准确度。因此,可对图片进行角度矫正,以消除图片偏斜带来的影响。
具体地,由于图片偏斜,目标图片与文字并不平行,而分割得到的子图片与图片中的文字平行,因此,可转动目标图片,同时保持子图片不动,直至目标图片与子图片平行,此时目标图片就与图片中的文字平行,可顺利进行文字识别与整合。
其中,在整合的过程中,根据旋转后的目标图片的底边以及侧边建立坐标系,将子图片的中点坐标进行行、列二阶升序排序,得到子图片矩阵,进而根据每个子图片在子图片矩阵中的位置进行组合。其中,根据中点坐标行、列二阶升序排序后,子图片矩阵中每一行子图片的中点的横坐标按照升序排序,每一列子图片的中点的纵坐标按照升序排序
进一步地,在另一种在图片中提取用药记录方法中,将目标图片分割成多个子图片,包括:
步骤701,根据图片中每行文字的高度以及宽度设置矩形检测框;
步骤702,利用矩形检测框分割目标图标,以使每个子图片包含一行文字。
在该实施例中,利用矩形检测框将目标图片分割成多个子图片,子图片的大小以及形状与矩形检测框相同。
具体地,可根据图片中每行文字的高度以及宽度设置矩形检测框,避免出现某一行文字被分割到两个子图片中的情况。
优选地,矩形检测框的高度以及宽度分别与一行文字的高度以及宽度相同,此时,矩形检测框每次分割得到的子图片中恰好包括一行文字。
图3示出了本申请实施例的另一种在图片中提取用药记录方法的矩形检测框示意图,如图所示,图中倾斜矩形为一个子图片,子图片的中点坐标为(x,y),子图片与目标图片之间的偏斜角为θ,目标图片的宽为w,高为h。
可以理解的是,假设任意一点坐标为(x,y),圆心坐标为(Cx,Cy),旋转角度为θ,则点(x,y)绕圆心坐标旋转,得到新坐标(x1,y1)的公式如下:
x1=(x-Cx)cosθ-(y-Cy)sinθ+Cx
y1=(y-Cx)cosθ+(x-Cx)sinθ+Cy
因此,子图片中心(x,y)绕目标图片中点
此外,在实际旋转时,图片绕任意一点进行旋转矫正,均可得到正确的结果,因此可简化上式为:
x′=xcosθ-ysinθ
y′=xsinθ+ycosθ
由于图片的转动是相对的,因此,可利用简化后的式子计算目标图片旋转后,子图片的中心的新坐标(x′,y′)。
进一步地,在另一种在图片中提取用药记录方法中,在直至在目标文本段中搜索不到药物名称之后,方法还包括:
步骤801,在用药记录集合中提取数值记录以及文字记录;
步骤802,获取目标药物试验对应的数值描述以及文字描述;
步骤803,确定数值记录与数值描述之间的第一匹配结果,以及文字记录与文字描述之间的第二匹配结果;
步骤804,根据第一匹配结果以及第二匹配结果,确定目标图片对应的目标患者与目标药物试验之间的目标匹配结果。
在该实施例中,在目标文本段中搜索不到药物名称之后,也即根据目标图片得到了最终的用药记录集合,根据用药记录集合中的信息以及目标药物试验的信息,计算目标患者与目标药物试验的匹配程度,得到目标匹配结果。若目标患者与目标药物试验匹配,则该目标患者可参与该目标药物试验,测试药物的有效性;若目标患者与目标药物试验不匹配,则该目标患者不可参与该目标药物试验。
具体地,使用端到端的学习框架学习一个嵌入表征空间,在对齐的嵌入表征空间对目标患者和目标药物试验进行匹配。在匹配过程中,将数值与文字分别进行匹配程度计算。分别获取用药记录集合中的数值记录以及目标药物试验的数值描述,对其进行匹配计算,得到第一匹配结果;利用同样的方法,获取用药记录集合中的文字记录以及目标药物试验的文字描述,得到文字记录与文字描述之间的第二匹配结果,综合分析第一匹配结果与第二匹配结果,即可知晓目标患者于目标药物试验之间是否匹配。
进一步地,作为上述在图片中提取用药记录方法的具体实现,本申请实施例提供了一种在图片中提取用药记录的装置,如图4所示,该装置包括:文字识别模块、位置标记模块、第一提取模块、第二提取模块、记录模块以及循环模块。
文字识别模块,用于在目标图片中提取目标文本段;
位置标记模块,用于在目标文本段中搜索药物名称,并将搜索到的目标药物名称作为标的字符串;以及,确定标的字符串的第一个字符为第一标的位置,标的字符串之后的第一个字符为第二标的位置;
第一提取模块,用于从第一标的位置开始,向前搜索用药日期文本,其中,用药日期文本包含一个或多个日期,每两个相邻日期之间的间隔字符数不大于预设间隔阈值;
第二提取模块,用于从第二标的位置开始,向后搜索用药描述文本;
记录模块,用于将用药日期文本、用药描述文本以及用药日期文本与用药描述文本之间的字符作为用药记录,添加至用药记录集合中;
循环模块,用于在目标文本段中剔除用药记录,得到新的目标文本段,并返回至在目标文本段中搜索药物名称的步骤,直至在目标文本段中搜索不到药物名称。
在具体的应用场景中,可选地,第一提取模块,用于:
从第一标的位置开始向前搜索,并将搜索到的第一个日期第一个字符作为第一起始搜索位置,第一个日期的最后一个字符作为结束位置;
提取第一起始搜索位置之前的第一预设数量个字符,组成第一待搜索字符串,并在第一待搜索字符串中搜索日期;
若搜索到日期,则将日期的第一个字符位置作为新的第一起始搜索位置,并返回至提取第一起始搜索位置之前的第一预设数量个字符的步骤;
若未搜索到日期或第一起始搜索位置之前的字符数量小于第一预设数量,则停止搜索;
将第一起始搜索位置与结束位置之间的字符作为用药日期文本添加至用药日期集合中。
在具体的应用场景中,可选地,第二提取模块,用于:
将第二标的位置作为第二起始搜索位置,提取第二起始搜索位置之后的第二预设数量个字符,组成第二待搜索字符串,并在第二待搜索字符串中搜索用药描述,其中,用药描述包括药物名称以及用药剂量;
若搜索到用药描述,则确定用药描述的最后一个字符位置为新的第二起始搜索位置,并返回至提取第二起始搜索位置之后的第二预设数量个字符的步骤;
若未搜索到用药描述或搜索到日期,则停止搜索;
将第一标的位置与第二起始搜索位置之间的字符作为用药描述文本添加至用药描述集合中。
在具体的应用场景中,可选地,第二提取模块,还用于:
若第二起始搜索位置与第二标的位置相同,则在第一标的位置后搜索截止符,并将第一标的位置与截止符之间的字符作为用药描述文本添加至用药描述集合中。
在具体的应用场景中,可选地,第二提取模块,还用于:
确定第二起始搜索位置与目标文本段的最后一个字符之间的长度;
若长度小于第二预设数量,则调整第二预设数量为长度。
在具体的应用场景中,可选地,文字识别模块,用于:
将目标图片分割成多个子图片,其中,每个子图片内的文字与子图片的底边平行;
旋转目标图片,至目标图片的底边与子图片的底边平行,并分别确定每个子图片的中点的横坐标以及纵坐标;
根据横坐标以及纵坐标对子图片进行排序,得到子图片矩阵,其中,子图片矩阵中每一行子图片的中点的横坐标按照升序排序,每一列子图片的中点的纵坐标按照升序排序;
分别提取每个子图片中的子文本段,并按照每个子图片在子图片矩阵中的位置,拼接子文本段得到目标文本段。
在具体的应用场景中,可选地,文字识别模块,还用于:
根据图片中每行文字的高度以及宽度设置矩形检测框;
利用矩形检测框分割目标图标,以使每个子图片包含一行文字。
在具体的应用场景中,可选地,装置还包括匹配模块,用于:
在用药记录集合中提取数值记录以及文字记录;
获取目标药物试验对应的数值描述以及文字描述;
确定数值记录与数值描述之间的第一匹配结果,以及文字记录与文字描述之间的第二匹配结果;
根据第一匹配结果以及第二匹配结果,确定目标图片对应的目标患者与目标药物试验之间的目标匹配结果。
需要说明的是,本申请实施例提供的一种在图片中提取用药记录装置所涉及各功能模块的其他相应描述,可以参考图1至图3中的对应描述,在此不再赘述。
基于上述如图1至图3所示方法,相应的,本申请实施例还提供了一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述如图1至图3所示的在图片中提取用药记录方法。
基于这样的理解,本申请的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台电子设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施场景所述的方法。
基于上述如图1至图3所示的方法,以及图4所示的虚拟装置实施例,为了实现上述目的,本申请实施例还提供了一种电子设备,具体可以为个人计算机、服务器、网络设备等,该电子设备包括存储介质和处理器;存储介质,用于存储计算机程序;处理器,用于执行计算机程序以实现上述如图1至图3所示的在图片中提取用药记录方法。
可选地,该电子设备还可以包括用户接口、网络接口、摄像头、射频(RadioFrequency,RF)电路,传感器、音频电路、WI-FI模块等等。用户接口可以包括显示屏(Display)、输入单元比如键盘(Keyboard)等,可选用户接口还可以包括USB接口、读卡器接口等。网络接口可选的可以包括标准的有线接口、无线接口(如蓝牙接口、WI-FI接口)等。
本领域技术人员可以理解,本实施例提供的一种电子设备结构并不构成对该电子设备的限定,可以包括更多或更少的部件,或者组合某些部件,或者不同的部件布置。
存储介质中还可以包括操作系统、网络通信模块。操作系统是管理和保存电子设备硬件和软件资源的程序,支持信息处理程序以及其它软件和/或程序的运行。网络通信模块用于实现存储介质内部各控件之间的通信,以及与该实体设备中其它硬件和软件之间通信。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本申请可以借助软件加必要的通用硬件平台的方式来实现,也可以通过硬件实现。
本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的单元或流程并不一定是实施本申请所必须的。本领域技术人员可以理解实施场景中的装置中的单元可以按照实施场景描述进行分布于实施场景的装置中,也可以进行相应变化位于不同于本实施场景的一个或多个装置中。上述实施场景的单元可以合并为一个单元,也可以进一步拆分成多个子单元。
上述本申请序号仅仅为了描述,不代表实施场景的优劣。以上公开的仅为本申请的几个具体实施场景,但是,本申请并非局限于此,任何本领域的技术人员能思之的变化都应落入本申请的保护范围。
- 通过图片检索视频的方法、装置、电子设备及存储介质
- 图片真实性的确定方法、装置、电子设备及可读存储介质
- 图片处理方法、装置、电子设备及存储介质
- 木材测量信息自动记录方法、装置、电子设备及存储介质
- 电子设备的显示控制方法、装置、电子设备和存储介质
- 一种3D图片到2D图片的转化方法、装置、电子设备及存储介质
- 图片显示方法、图片显示装置、电子设备及存储介质