一种基于糖尿病数据的无监督聚类方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明属于疾病聚类领域,具体涉及一种基于糖尿病数据的无监督聚类方法。
背景技术
糖尿病是一种以高血糖为特征的代谢性疾病。高血糖则是由于胰岛素分泌缺陷或其生物作用受损,或两者兼有引起。长期存在的高血糖,导致各种组织,特别是眼、肾、心脏、血管、神经的慢性损害、功能障碍。据IDF糖尿病地图最新数据显示:2021年,全球成年人糖耐量受损(IGT)患病率为9.1%,人数高达4.64亿,预计到2045年,这一比例将增加到10.0%,波及6.4亿成年人。因此所有人都应对糖尿病提高警惕,对糖尿病的研究也变得刻不容缓。
由于现实中糖尿病检测数据大多来自医院或者社区调查,它们几乎都是无标签的,因此利用无监督的聚类方法来分析糖尿病是至关重要的。本发明就是首先利用无监督的聚类将相似的数据聚类到同一个簇中,然后将错误聚类的样本视为异常值进行剔除,最后再利用有监督的分类检验聚类效果。但当前用于糖尿病数据的聚类方法基本都是简单的K-means,首先用K-means进行聚类,然后用AE进行降维,最后用KNN的变体对糖尿病数据进行分类。
然而,上述方法中的K-means存在着许多公认的问题,比如对k值和初始簇中心的敏感,受离群值的影响大等,而且大多糖尿病数据集两类之间都存在重叠的部分,Kmeans对这类数据不能很好的区分。
发明内容
针对现有技术中的上述不足,本发明提供的一种基于糖尿病数据的无监督聚类方法解决了现有的K-means聚类方法对k值和初始簇中心的敏感,受离群值的影响大的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种基于糖尿病数据的无监督聚类方法,包括以下步骤:
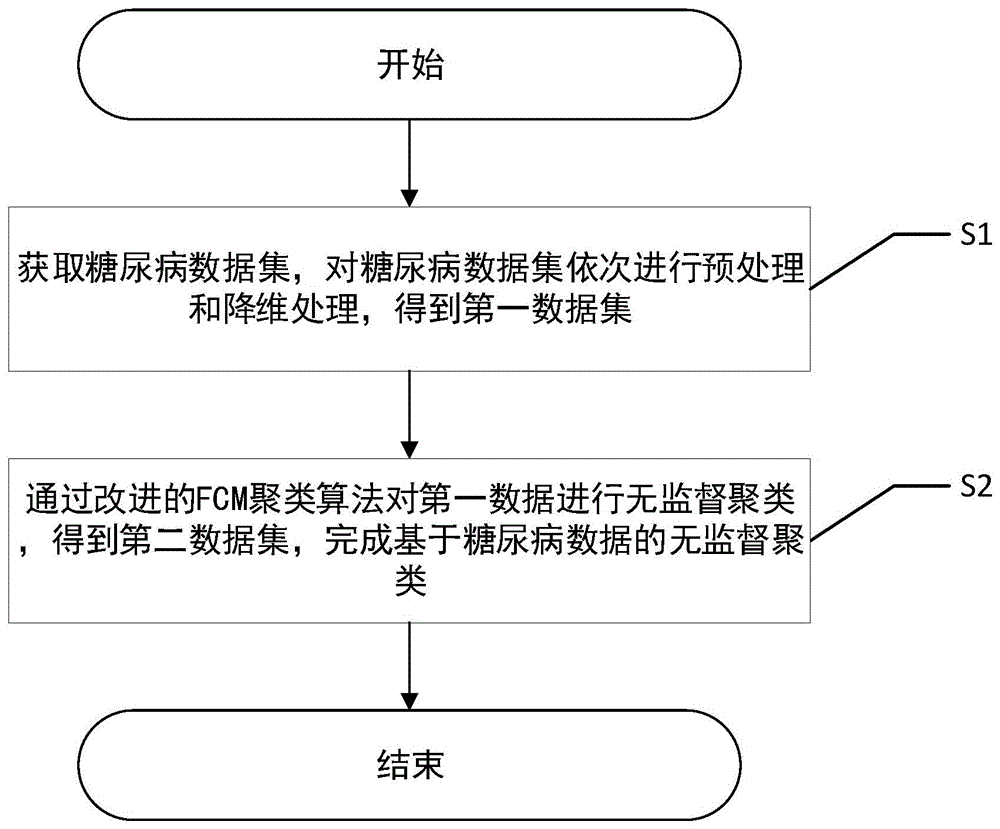
S1、获取糖尿病数据集,对糖尿病数据集依次进行预处理和降维处理,得到第一数据集;
S2、通过改进的FCM聚类算法对第一数据集进行无监督聚类,得到最优聚类数据集,完成基于糖尿病数据的无监督聚类。
进一步地:所述S1包括以下分步骤:
S11、获取糖尿病数据集,对糖尿病数据进行预处理,得到预处理后的糖尿病数据集;
S12、通过主成分分析PCA算法对预处理后的糖尿病数据集进行降维处理,得到第一数据集。
上述进一步方案的有益效果为:利用利用主成分分析PCA算法对数据进行降维处理,能够分析各特征对糖尿病标签的影响。
进一步地:所述S11具体为:
获取糖尿病数据集,将糖尿病数据集中的数据进行特殊字符替换、名义替换和缺失数据中位数填充处理,进而将处理后糖尿病数据集中的数据进行归一化,得到预处理后的糖尿病数据集;
其中,所述糖尿病数据集中的数据包括标签类和若干特征。
进一步地:所述S12具体为:
计算预处理后的糖尿病数据集中的数据协方差,得到协方差的特征值和特征向量,将特征值降序排列,选择前N个特征值作为行向量,并将选择的特征值对应的特征向量作为所述特征值的列向量,得到特征向量矩阵,将特征向量矩阵作为第一数据集。
上述进一步方案的有益效果为:本发明保留了两个最主要的特征值和特征向量以增强可视化,消除了不太重要的成分。
进一步地:所述S2包括以下分步骤:
S21、将当前的隶属度矩阵初始化,得到满足约束条件的隶属度矩阵;
S22、根据满足约束条件的隶属度矩阵计算当前的类中心矩阵;
S23、根据当前的类中心矩阵更新隶属度矩阵,得到更新后的隶属度矩阵;
S24、根据当前的类中心矩阵与更新后的隶属度矩阵计算当前的目标函数;
S25、判断当前的目标函数与设定的目标函数的改变量是否小于变量阈值;
若否,则将当前的目标函数作为设定的目标函数,并返回步骤S21;
若是,则根据当前的目标函数与约束条件对第一数据集进行聚类,得到第二数据集,进入S26;
S26、计算第二数据集中样本占第一数据集中样本的比例,判断第二数据集中样本占第一数据集中样本的比例是否大于设置的聚类效果比例阈值;
若是,则将第二数据集中样本占第一数据集中样本的比例作为聚类效果比例阈值,并将隶属度因子加1,进入S27;
若否,则将隶属度因子加1,进入S27;
S27、判断隶属度因子是否大于999;
若是,则将与聚类效果比例阈值相同的第二数据集中样本占第一数据集中样本的比例作为最优聚类比例,并将最优聚类比例对应的第二数据集作为最优聚类数据集,完成基于糖尿病数据的无监督聚类;
若否,则返回S21。
上述进一步方案的有益效果为:本发明改进的FCM聚类算法将m从2到1000依次赋值,用准确率评价聚类效果,能够将最佳的聚类结果保存下来,并将错误聚类的样本视为异常值进行剔除。
进一步地:所述S21中,满足约束条件的隶属度矩阵U
式中,i为聚类中心序数,c为聚类中心个数,j为第一数据集的样本序数,n为第一数据集的样本个数,u
进一步地:所述S22中,所述当前的类中心矩阵C=[c
式中,
进一步地:所述S23中,更新后的隶属度矩阵U
式中,c
进一步地:所述S24中,计算计算当前的目标函数J的表达式具体为:
式中,
本发明的有益效果为:发明采用改进的FCM模糊聚类算法,其不仅能克服初始簇中心和离群值的影响,而且其加入的隶属度这一概念能够更好的处理数据重叠部分,且本发明对隶属度因子m进行了改进,因此表现出更佳的聚类效果,这也能通过有监督的分类算法验证。
附图说明
图1为本发明的流程图。
图2为本发明实施例2展示的聚类效果图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
实施例1:
如图1所示,在本发明的一个实施例中,一种基于糖尿病数据的无监督聚类方法,包括以下步骤:
S1、获取糖尿病数据集,对糖尿病数据集依次进行预处理和降维处理,得到第一数据集;
S2、通过改进的FCM聚类算法对第一数据集进行无监督聚类,得到最优聚类数据集,完成基于糖尿病数据的无监督聚类。
所述S1包括以下分步骤:
S11、获取糖尿病数据集,对糖尿病数据进行预处理,得到预处理后的糖尿病数据集;
S12、通过主成分分析PCA算法对预处理后的糖尿病数据集进行降维处理,得到第一数据集。
所述S11具体为:
获取糖尿病数据集,将糖尿病数据集中的数据进行特殊字符替换、名义替换和缺失数据中位数填充处理,进而将处理后糖尿病数据集中的数据进行归一化,得到预处理后的糖尿病数据集;其中,所述糖尿病数据集中的数据包括标签类和若干特征。
在本实施例中,标签类包括糖尿病阳性和糖尿病阴性。
所述S12具体为:
计算预处理后的糖尿病数据集中的数据协方差,得到协方差的特征值和特征向量,将特征值降序排列,选择前N个特征值作为行向量,并将选择的特征值对应的特征向量作为所述特征值的列向量,得到特征向量矩阵,将特征向量矩阵作为第一数据集。
在本实施例中,利用利用主成分分析PCA算法对数据进行降维处理,能够分析各特征对糖尿病标签的影响,本发明保留了两个最主要的特征值和特征向量以增强可视化,消除了不太重要的成分,得到降维后的数据集,这将成为下一阶段聚类的输入。
所述S2包括以下分步骤:
S21、将当前的隶属度矩阵初始化,得到满足约束条件的隶属度矩阵;
S22、根据满足约束条件的隶属度矩阵计算当前的类中心矩阵;
S23、根据当前的类中心矩阵更新隶属度矩阵,得到更新后的隶属度矩阵;
S24、根据当前的类中心矩阵与更新后的隶属度矩阵计算当前的目标函数;
S25、判断当前的目标函数与设定的目标函数的改变量是否小于变量阈值;
若否,则将当前的目标函数作为设定的目标函数,并返回步骤S21;
若是,则根据当前的目标函数与约束条件对第一数据集进行聚类,得到第二数据集,进入S26;
S26、计算第二数据集中样本占第一数据集中样本的比例,判断第二数据集中样本占第一数据集中样本的比例是否大于设置的聚类效果比例阈值;
若是,则将第二数据集中样本占第一数据集中样本的比例作为聚类效果比例阈值,并将隶属度因子加1,进入S27;
若否,则将隶属度因子加1,进入S27;
S27、判断隶属度因子是否大于999;
若是,则将与聚类效果比例阈值相同的第二数据集中样本占第一数据集中样本的比例作为最优聚类比例,并将最优聚类比例对应的第二数据集作为最优聚类数据集,完成基于糖尿病数据的无监督聚类;
若否,则返回S21。
所述S21中,满足约束条件的隶属度矩阵U
式中,i为聚类中心序数,c为聚类中心个数,j为第一数据集的样本序数,n为第一数据集的样本个数,u
所述S22中,所述当前的类中心矩阵C=[c
式中,
所述S23中,更新后的隶属度矩阵U
式中,c
所述S24中,计算计算当前的目标函数J的表达式具体为:
式中,
在本实施例中,改进的FCM聚类算法通过最小化目标函数与其约束条件来实现聚类,目标函数为每个样本的隶属度与该样本到各个类中心的欧式距离的乘积之和,本发明改进的FCM聚类算法将m从2到1000(达到最佳聚类效果时的m值都不超过1000)依次赋值,用准确率评价聚类效果,将最佳的聚类结果保存下来,将错误聚类的样本视为异常值进行剔除。在对聚类结果进行清洗后,保留了平均582个样本,作为有监督的KNN分类算法的输入。
本发明通过有监督的KNN分类算法结合十折交叉验证糖尿病数据集的聚类效果,其具体包括以下步骤:
S31、将第一数据集划分为训练集与测试集,得到10组训练集与测试集;
S32、通过改进的KNN分类算法将计算每组训练集与测试集的分类准确率;
S33、将每组训练集与测试集的分类准确率分和最优聚类比例进行比较,完成聚类效果评价。
S32、通过十折交叉验证最优聚类数据集对第一数据集的聚类性能评价;
S33、基于第一数据集的预测分类和最优聚类数据集对第一数据集的聚类性能评价,完成基于糖尿病数据的无监督聚类评价。
S31具体为:按照糖尿病数据集的标签比例划分第一数据集,得到10个子集,并将其中任一个子集作为训练集,其余的子集作为测试集,得到10组训练集与测试集。
在本实施例中根据不同的训练集和测试集设置方式,一共可设置10组训练集与测试集。
S32中,计算每组训练集与测试集的分类准确率的方法具体为:
计算测试集中每个待测样本与训练集中所有样本之间的欧氏距离,选取与待测样本距离最小的k个邻近样本,确认此k个样本中各个标签的占比,将占比最高的标签即作为该待测样本的预测标签,将预测标签与最优聚类数据集标签进行对比,将预测标签的样本数占测试集所有样本的比例作为分类准确率。
在本实施例中,k值选择不同于传统的人为设定,而是对k从1到100进行轮流验证,将分类准确率达到最高时的k挑选出来作为最终的k,进而提升KNN分类器的性能。
实施例2:
本实施例针对一种基于糖尿病数据的无监督聚类方法的仿真实验。
为了验证基于糖尿病数据的无监督聚类方法的有效性,在真实数据集上进行了对比实验,采用Pytorch的数据挖掘工具来构建机器学习模型。实验采用的数据集有两个:一个是从UCI机器学习库获得的Pima Indian Diabetes数据集,包含768名女性糖尿病患者样本(268名测试阳性病例和500名测试阴性病例)和8个特征(Pregnancies,Glucose,BloodPressure,SkinThickness,Insulin,BMI,DiabetesPedigreeFunction和Age)以及1个标签类(Outcome),全是数值型数据;另一个是由华西医院提供的数据,经过处理后保留了762名糖尿病患者样本(390名测试阳性病例和372名测试阴性病例)和8个特征(餐后2h血糖(mmol/L),空腹血糖(mmol/L),糖化血红蛋白(HbA1C),收缩压(mmHg),葡萄糖(mmol/L),舒张压(mmHg),年龄和BMI(公式:体重/身高/身高))以及1个标签类(标签)。在分别对两个数据集进行了数据预处理后,利用PCA对数据进行降维:PIDD数据集的两个主成分为Glucose和BMI,而医院数据集的两个主成分为餐后2h血糖(mmol/L)和空腹血糖(mmol/L),将降维后的数据作为无监督聚类的输入进行实验。
为了验证本发明的有效性,与传统的K-means聚类算法和原始的FCM聚类算法进行了对比,并通过改进的KNN分类算法验证了聚类效果。
实验结果评估:
表1和表2分别是对两个数据集进行聚类对比的实验结果。从对比的实验可以看到,本方法的聚类效果明显优于传统的K-means聚类算法和原始的FCM聚类算法。表3是通过KNN算法结合十折交叉验证对聚类效果进行的评估,可以看出聚类后的数据分类效果很好。
表1:在PIDD数据集上进行聚类算法的比较
表2:在医院数据集上进行聚类算法的比较
表3:通过KNN分类算法进行聚类评价
结合图2和表2可知,传统的K-means算法对于糖尿病数据集中重叠的部分聚类效果不佳,因此两类中间部分被清除的样本数就多;原始的FCM聚类算法略好于K-means,但由于隶属度因子m的影响,对于隶属度矩阵U和类中心C的迭代不能达到最佳的效果。相对于上述两种算法,本发明的改进FCM聚类算法达到最佳的聚类效果。
本发明的有益效果为:本发明采用改进的FCM模糊聚类算法,其不仅能克服初始簇中心和离群值的影响,而且其加入的隶属度这一概念能够更好的处理数据重叠部分,且本发明对隶属度因子m进行了改进,因此表现出更佳的聚类效果,这也能通过有监督的分类算法验证。
在本发明的描述中,需要理解的是,术语“中心”、“厚度”、“上”、“下”、“水平”、“顶”、“底”、“内”、“外”、“径向”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的设备或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性或隐含指明的技术特征的数量。因此,限定由“第一”、“第二”、“第三”的特征可以明示或隐含地包括一个或者更多个该特征。
- 一种基于卷积神经网络的文本数据无监督聚类方法
- 一种基于模糊深度聚类的无监督行人再识别方法
- 一种基于双端神经网络的无监督数据聚类方法
- 一种基于卷积神经网络的文本数据无监督聚类方法