一种硝酸-硝酸铵溶液中硝酸铵浓度预测方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及一种硝酸-硝酸铵溶液中硝酸铵浓度预测方法,具体涉及一种由待测硝酸-硝酸铵溶液的近红外光谱数据与已知硝酸-硝酸铵溶液中硝酸铵浓度数据预测待测溶液中硝酸铵浓度的方法,属于炸药工艺和近红外光谱定量分析领域。
背景技术
奥克托今(HMX)是目前应用最广泛的炸药,目前世界各国普遍采用醋酐法进行生产。在HMX的生产过程中,原材料的质量对产品质量、生产成本和生产工艺有着重要的影响。硝酸-硝酸铵溶液是生产HMX过程中的重要原材料,对硝酸-硝酸铵溶液中硝酸铵浓度的检测可以增强投料的稳定性,进而影响产品得率和质量。
目前,在HMX生产制备过程中,铵硝溶液中硝酸铵浓度的分析检测主要采用化学分析方法,由于分析是间断或者离线操作,存在分析结果滞后的问题,当原材料品质或浓度出现异常时,难以及时调整,容易造成产品品质不稳定、得率不稳定以及由此引发的安全问题。因此,出于HMX生产工艺稳定性以及安全性考虑,需要创建一种快速且高精度的浓度在线分析方法。
近红外光谱技术具有快速、无损、环保、人力成本低等特点,广泛应用于过程分析、在线监测和传统的离线检测。目前,已广泛应用于炸药领域,如推进剂、发射药、混合炸药的快速检测。但是,至今国内还未见有关利用近红外光谱技术在线预测硝酸-硝酸铵溶液中硝酸铵浓度的相关报道。
发明内容
本发明的目的是提供一种硝酸-硝酸铵溶液中硝酸铵浓度预测方法,该方法利用硝酸-硝酸铵溶液中硝酸铵浓度与近红外光谱数据间的关系,通过光谱拟合预测待测硝酸-硝酸铵溶液中硝酸铵的浓度。
本发明提供的是一种硝酸-硝酸铵溶液中硝酸铵浓度预测方法,包括如下步骤:
步骤一、收集不同硝酸铵浓度的硝酸-硝酸铵溶液样本的近红外光谱,以及其对应的浓度数据,组成原始近红外光谱数据矩阵和原始浓度数据矩阵。
步骤二、对所述原始近红外光谱数据矩阵中的数据进行标准正态变量变换(SNV)预处理,得到预处理后的光谱矩阵。
步骤三、通过连续投影算法(successive projections algorithm,SPA)对所述预处理后的光谱矩阵进行降维处理,得到降维后的光谱矩阵。
步骤三所述SPA算法属于前向迭代搜索算法,其目的是选择光谱信息最少冗余的波长来解决共线性问题。预处理后的光谱矩阵为n行m列,其中n代表样本容量,m为全光谱波长数目,要选出H个最优波长,选择步骤为:
(1)初始迭代t=1时,任选所述预处理后的光谱矩阵第k列赋值给x
(2)将剩余列向量位置集合定义为s:
(3)分别计算剩余列向量x
式中
(4)提取最大投影值所对应波长序号k(t),计算式为:
(5)将最大投影值作为下次迭代的初始值,即
(6)令t=t+1,当t<H时,返回步骤(2)循环计算,当t=H时,停止循环,进行步骤(7);
(7)当循环终止时,得到最终筛选的波长变量组合{k(t),t=0,…,H-1}。
(8)由于迭代的第一个变量x
(9)从预处理后的光谱矩阵中提取步骤(8)中得到的最优波长对应的光谱数据,并组合成新的光谱矩阵,即降维后的光谱矩阵。
步骤四、将降维后的光谱矩阵与原始浓度数据矩阵按spxy(sample setpartitioning based on joint x-y distance)算法原理划分为训练集光谱矩阵、训练集浓度矩阵、测试集光谱矩阵和测试集浓度矩阵。
步骤四所述的spxy算法是在KS(Kennard-Stone)算法基础上发展而来的,在样本间距离计算时将降维后的光谱矩阵中的数据x和原始浓度数据矩阵中的数据y同时考虑在内。
式中p和q表示两个不同的样本,d代表样本间距离。
步骤五、将训练集光谱矩阵和训练集浓度矩阵输入到随机森林回归模型中进行训练,得到最优随机森林回归模型。用最优随机森林回归模型对验证集光谱矩阵对应的浓度值进行预测,将预测值和真实值进行对比,运用相关系数R
所述最优随机森林回归模型具体构建过程包括以下步骤:
1)将训练集光谱矩阵和训练集浓度矩阵组合成样本集,使用bootstrap方法随机有放回的对样本集进行采样,生成h个训练集,记为θ
2)假设训练集θ
子空间R分割规则为:
式中x为训练集θ
对于分割问题,存在一个最优解,使得最小值函数
式中y为训练集θ
按照上述方法,分别将R
式中I为逻辑值,表达形式为:
3)继续对训练集θ
4)将h棵回归决策树组成随机森林,并建立最优随机森林回归模型的函数
步骤六、将在线采集到的待测硝酸铵浓度的硝酸-硝酸铵溶液近红外光谱数据,通过步骤二中的SNV预处理、步骤三的SPA降维后,输入到步骤五得到的最优随机森林回归模型,即可直接获得待测溶液的浓度值。
有益效果
1、使用随机森林回归学习算法,构建了硝酸-硝酸铵溶液中硝酸铵浓度预测模型,可有效减少使用线性回归等模型出现的过拟合现象。
2、通过该方法,利用在线近红外光谱数据,通过建立的模型可快速预测硝酸-硝酸铵溶液中硝酸铵的浓度值,有利于观察HMX的生产稳定性,达到保证最终产品质量的目的。
附图说明
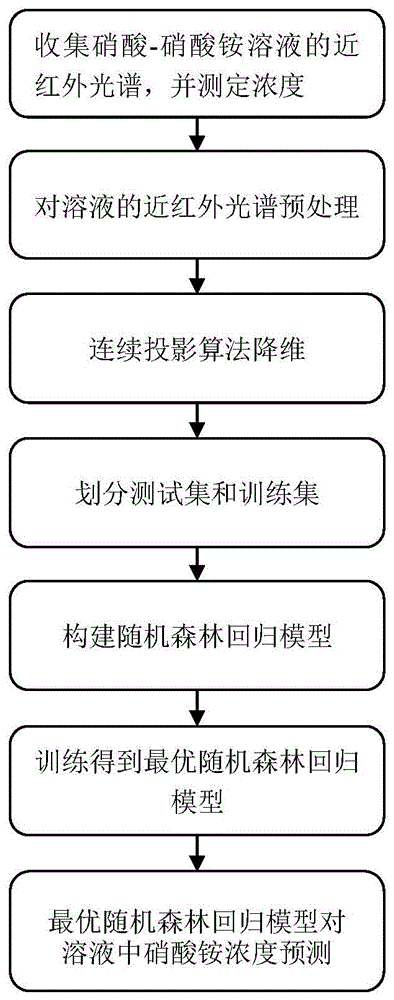
图1是本发明公开的一种硝酸-硝酸铵溶液中硝酸铵浓度预测方法的整体流程图;
图2是本发明的最优随机森林回归模型对测试集光谱矩阵的浓度预测值与实测值对比图。
具体实施方式
本发明的一种硝酸-硝酸铵溶液中硝酸铵浓度预测方法流程如图1所示。
下面结合附图对本发明做进一步的详细说明:
实施例1:
一、收集和处理硝酸-硝酸铵溶液样本
直接称取不同质量的硝酸铵和硝酸,配制成不同硝酸铵浓度的硝酸-硝酸铵溶液样本。测定各样本近红外光谱(扫描波长范围10000~4000cm
二、近红外光谱预处理
对原始光谱矩阵X
对原始光谱矩阵X
式中k=1,2,…,m,x代表每行中的光谱数据,x
三、连续投影算法降维
通过连续投影算法对所述预处理后的光谱矩阵X
所述连续投影算法降维处理包括以下步骤:
(1)初始迭代t=1时,任选光谱矩阵第k列赋值给x
(2)将剩余的列向量位置集合定义为s,
(3)分别计算剩余列向量x
式中
(4)提取最大投影值所对应波长序号k(t),计算式为:
(5)将最大投影值作为下次迭代的初始值,即
(6)令t=t+1,当t<H时,返回步骤(2)循环计算,当t=H时,停止循环,进行步骤(7);
(7)当循环终止时,得到最终筛选的波长变量组合{k(t),t=0,…,H-1}。
(8)由于迭代的第一个变量x
(9)从预处理后的光谱矩阵X
四、训练集和测试集划分
将降维后的光谱矩阵X
spxy算法划分训练集和测试集包括以下步骤:
1)从降维后的光谱矩阵X
式中d为两个样本间距离。
2)对降维后的光谱矩阵中的数据x和降维后的光谱矩阵中的数据y空间上的距离赋予同等的重要性,即进行归一化处理,归一化的距离d
3)选择时,首先将归一化后距离最大的样本对(p、q)选择进入训练集,在每次迭代中,选择相对已选择的任意样本归一化距离最大和最小的样本进行训练集,重复过程,直至达到满足训练集数量,其余部分进入测试集。
五、最优随机森林回归模型的构建
将训练集光谱矩阵和训练集浓度矩阵输入到随机森林回归模型中进行训练,得到最优随机森林回归模型。用最优随机森林回归模型对验证集光谱矩阵对应的浓度值进行预测,将预测值和真实值进行对比,运用相关系数R
所述最优随机森林回归模型具体构建过程包括以下步骤:
1)将训练集光谱矩阵和训练集浓度矩阵组合成样本集,使用bootstrap方法随机有放回的对样本集进行采样,生成h个训练集,记为θ
2)假设训练集θ
子空间R分割规则为:
式中x为训练集θ
对于分割问题,存在一个最优解,使得最小值函数
式中y为训练集θ
按照上述方法,分别将R
式中I为逻辑值,表达形式为:
3)继续对训练集θ
4)将h棵回归决策树组成随机森林,并建立最优随机森林回归模型的函数
对模型的预测能力评价采用相关系数R
①相关系数R
式中
②均方误差MSE:MSE值越小,说明模型的预测能力越强,计算式为:
结果表明,选择标准正态变量变换进行光谱预处理时,以连续投影算法降维,spxy算法划分训练集与测试集(85:15的比例),用最优随机森林回归模型预测时,得到的模型性能最佳。最佳建模的模型参数及性能见表1。
表1最终建模参数
表2所示的是用最优随机森林回归模型对测试集光谱矩阵X
表2最优随机森林回归模型对测试集的预测值与实际值对比情况
六、待测硝酸-硝酸铵溶液中硝酸铵浓度的预测
将在线采集到的待测硝酸铵浓度的硝酸-硝酸铵溶液近红外光谱数据,经过标准正态变量变换预处理、连续投影算法降维处理后,通过得到的最优随机森林回归模型,能够直接预测得到待测溶液的浓度值。运用本方法对另外收集的15个样本的测定结果如表3所示。由表3可知,预测值和实际值间的相对误差绝对值最大为0.73%,误差小,表明构建的方法可为硝酸-硝酸铵溶液的浓度测定研究提供可靠方法。
表3待测溶液中硝酸铵浓度的预测值与实际值对比情况
以上所述的具体描述,对发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 具有更新机制的硝酸-硝酸铵溶液中硝酸铵浓度预测方法
- 一种在线检测高浓度、高温硝酸铵溶液PH的方法及设备