一种基于YOLO的2D姿态检测方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及计算机视觉检测技术领域,尤其是一种基于YOLO的2D姿态检测方法。
背景技术
姿态估计是计算机视觉领域中的一个重要研究方向,目前被广泛应用于人体活动分析、人机交互以及视频监视等方面。姿态估计大多数是人体姿态估计,还有一些有手部姿态估计;人体姿态估计是指通过计算机算法在图像或视频中定位人体关键点(如肩、肘、腕、髋膝、膝、踝等);手部姿态估计分为有标记和无标记的姿态估计,用于理解手部行为的意思。
姿态估计的方法可分为基于传统的姿态估计和基于深度学习的姿态估计。
传统的姿态估计主要是基于图结构模型方法。基于图结构模型方法包含三部分:图模型、优化算法和组件外观模型,它提供了经典的对象统计模型,使用图形结构模型识别图像中的对象,缺点在于属于启发式的局部搜索,没办法找到全局最优解。
深度学习是自我解释型的学习方式,简单方便,功能强大,很多领域都在使用,而基于深度学习的姿态估计是利用深度卷积神经网络来增强人体估计系统的性能。与传统方法相比,深度学习能够得到更深层图像特征,对数据的表达更准确,因此已成为研究的主流方向。在深度学习方法中,根据检测人数分为单人姿态估计与多人姿态估计两类,对单人姿态估计分为基于坐标回归与基于热图检测的方法;对多人姿态估计可分为自上而下(Top-Down)和自下而上(Bottom-Up)的方法。
自上而下是指先检测目标,然后对提取出来的目标区域使用单目标关键点检测方法来构造姿态,这种方法优势是不用考虑多个目标的多个同类别关键点间的匹配组合问题,缺点是非常依赖目标检测效果,当目标检出不完整时就无法检出目标的所有关键点,同时随着目标数量的增加,计算量也会增加。自下而上的方法是目前的主流方法,这种方法先计算所有目标的所有关键点,再将关键点组合到对应的目标上,关键点匹配组合到目标的过程会增加算法的复杂度。
对于关键点检测目前常用的方法主要有基于heatmap的方法和YoloPose这样的用目标模型直接回归关键点坐标的方法。早期的回归坐标的方法是用于单目标的关键点检测,对单目标图片提取特征后直接用全连接层输出所有关键点坐标。Heatmap的方法将关键点坐标用图片的形式输出出来,生成与关键点类别数相等的热力图的数量,这种方法的缺点是计算量大,显存占用量高;通常heatmap的尺寸为输入图片的四分之一,这就导致至少会存在3个像素左右的误差。使用heatmap的方法随着关键点数量的增加会大幅度增加特征图尺寸,同时还需要考虑不同目标的同类别关键点的区分与匹配问题,如在人体姿态估计中一张图片存在两个人,每个人都有左肩、左肘、左手这三个关键点,即一张图片中的6个点应该怎样连接才能分别正确地构成这两个人的左手臂,在OpenPose算法中使用的是生成关键点亲和场的方法,这会进一步增加特征图尺寸,同时带来计算量与显存的增加;虽然heatmap方法也有通过生成关键点embedding的方法进行匹配,但无法解决生成heatmap特征图带来的计算量增加的问题。
而YoloPose使用的是在预测目标对象的目标框同时,计算每个目标的每个关键点,即在得到关键点坐标的同时就已经与目标对象进行关联,通过目标对象的全局特征姿态来生成关键点,所以不用考虑找到关键点后与目标的关联匹配问题,因此可以使算法的检测速度达到与Yolo系列目标检测模型几乎相同的速度。但YoloPose存在的问题是对于大尺寸的目标,Yolo是通过低分辨率特征图进行回归的,所以对于大尺寸目标检测关键点这样的精细操作会带来较大的精度丢失。
发明内容
本发明要解决的技术问题是:提供一种基于YOLO的2D姿态估计方法,解决目前已有的基于YOLO架构在对超大目标的关键点定位时,由于都是基于目标所在anchor回归关键点的偏移量,导致anchor尺度过大、目标末端关键点距离anchor距离较远而产生了较大的误差的问题。
本发明解决其技术问题所采用的技术方案是:一种基于YOLO的2D姿态检测方法,包括以下步骤,
1)训练集标注;标注出训练集图片中检测对象的Bbox,即Bounding box、检测对象所有关键点坐标及关键点类别、各个关键点连接顺序;
2)训练检测模型并进行检测;
3)检测时的输入包含待检测图片与关键点连接顺序两部分组成;先经过检测模型检测出检测对象的Bbox、Bbox的embedding值,关键点的坐标、关键点的embedding值;然后关键点匹配组合部分根据embedding值将同个检测对象的关键点组合到一起,再依据关键点连接顺序确定检测对象位置及姿态。
进一步的说,本发明所述的步骤1)中,同一个检测对象的关键点数量、关键点类别完全相同且各个关键点的连接方式唯一,关键点的连接顺序标注时只创建一次。
再进一步的说,本发明所述的步骤3)中,关键点检测部分采用YoloX的backbone;输出的是点类型的目标,采用高分辨率的特征图提高定位精度,backbone中去掉了一个CSP1和CBA的结构,使原始backbone输出的特征图尺寸由(W/8,H/8)、(W/16,H/16)、(W/32,H/32)变为(W/4,H/4)、(W/8,H/8)、(W/16,H/16),其中W、H为输入图片的宽与高。
再进一步的说,本发明所述的步骤3)中,embedding head的loss计算方法如下:
其中,P={(p
更进一步的说,本发明所述的步骤3)中,在对关键点匹配时,使用MeanShift算法对关键点的embedding进行聚类,包括以下步骤:
1、在未被标记的数据点中随机n个点作为n个聚类的起始中心点center;
2、找出以center为中心,半径为radius的区域中出现的所有数据点,认为这些点同属于一个聚类C;同时将在该聚类中数据点的访问频率加1;
3、以center为中心点,计算center点到集合M中每个数据点的向量之和,得到向量shift,对于给定的d维空间中的n个样本点xi,i=1,...,n,对于点x,MeanShift向量的基本形式为:
4、center点沿着向量shift的方向移动,移动距离是||shift||;
5、迭代:重复步骤2、3、4,直到||shift||很小,即迭代到收敛,记住此时的center;这个迭代过程中遇到的点都应该归类到簇C;
6、如果收敛时当前簇C的center与其它已经存在的簇C2中心的距离小于阈值,那么把C2和C合并,数据点出现次数也对应合并;否则,把C作为新的聚类;
7、重复1、2、3、4、5、6直到所有的点都被标记为已访问;
8、根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
本发明的有益效果是,解决了背景技术中存在的缺陷,将关键点作为单独的目标进行检测,关键点组合到同个目标采用匹配embedding的方法,同时预测每个关键点的embedding;训练时,对于同个目标让模型向各关键点embedding距离最短收敛,对于不同目标以增加embedding距离的方向收敛;保留了相较heatmap方法的基于YOLO的姿态估计方法推理速度快显存占用小的特点,同时提高了关键点的预测精度并且几乎不增加额外的算法运行时间。
附图说明
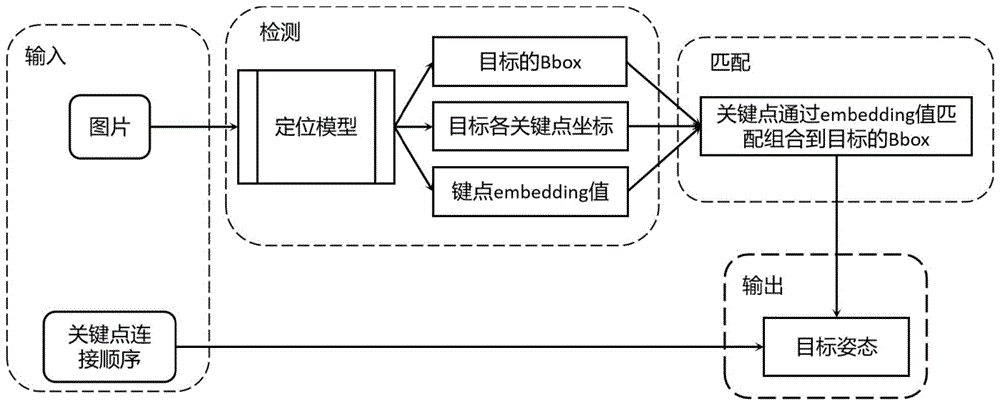
图1是本发明基本架构示意图;
图2是模型结构示意图。
具体实施方式
现在结合附图和优选实施例对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
如图1-图2所示的一种基于YOLO的2D姿态检测方法,分为关键点检测与关键点匹配组合两个部分,基本架构如图1所示,包括以下流程:
1)训练集标注。标注出训练集图片中检测对象的Bbox(Bounding box)、检测对象所有关键点坐标及关键点类别、各个关键点连接顺序(注:embedding不用标注;由于同一个检测对象的关键点数量、关键点类别完全相同且各个关键点的连接方式唯一,所以关键点的连接顺序标注时只需创建一次)。
2)模型训练。
3)检测过程。如图1所示,本检测方案的输入包含待检测图片与关键点连接顺序两部分组成。先经过检测模型检测出检测对象的Bbox、Bbox的embedding值,关键点的坐标、关键点的embedding值。关键点匹配组合部分会根据embedding值将同个检测对象的关键点组合到一起(注:一张图片可能存在多个检测对象),再依据关键点连接顺序确定检测对象位置及姿态。
其中关键点检测部分采用YoloX的backbone。由于输出的是点类型的目标,需要用高分辨率的特征图提高定位精度,backbone中去掉了一个CSP1和CBA的结构,使原始backbone输出的特征图尺寸由(W/8,H/8)、(W/16,H/16)、(W/32,H/32)变为(W/4,H/4)、(W/8,H/8)、(W/16,H/16),其中W、H为输入图片的宽与高。相较于官方版本的YoloX,在回归检测头分支中增加了对关键点embadding的输出,如图2所示。
由于检出目标都为点类型,模型会主要由(W/4,H/4)分辨率的检测头分支进行输出,为了进一步降低计算量,裁减掉backbone中的PAN结构,去掉(W/8,H/8)和(W/16,H/16)分别率的检测头分支。
对于class head、region head和object head分支的损失函数不做修改,embedding head的loss计算方法如下:
其中P={(p
这个损失函数的作用是使模型训练时尽可能减少同个目标的每个关键点embedding的距离,尽可能增大不同目标间的参考embedding距离,实现同个目标关键点间的匹配,不同目标的同类型关键点能够区分。
在对关键点匹配时,使用MeanShift算法对关键点的embedding进行聚类。
其中MeanShift的基本步骤如下:
1、在未被标记的数据点中随机n个点作为n个聚类的起始中心点center。
2、找出以center为中心,半径为radius的区域中出现的所有数据点,认为这些点同属于一个聚类C。同时将在该聚类中数据点的访问频率加1。
3、以center为中心点,计算center点到集合M中每个数据点的向量之和,得到向量shift,对于给定的d维空间中的n个样本点xi,i=1,...,n,对于点x,MeanShift向量的基本形式为:
4、center点沿着向量shift的方向移动,移动距离是||shift||。
5、迭代:重复步骤2、3、4,直到||shift||很小(就是迭代到收敛),记住此时的center。这个迭代过程中遇到的点都应该归类到簇C。
6、如果收敛时当前簇C的center与其它已经存在的簇C2中心的距离小于阈值,那么把C2和C合并,数据点出现次数也对应合并。否则,把C作为新的聚类。
7、重复1、2、3、4、5、6直到所有的点都被标记为已访问。
8、根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
本发明采用类似heatmap方法中先检测所有关键点再用关键点embedding匹配的方法,而不同的是将每个关键点用目标模型当成一个目标进行检出,这样可以避免生成heatmap特征图需要大量计算资源的问题;同时由于是对关键点的检测,特征图分辨率越高越有利于回归出精确坐标,又因为Yolo算法对小目标检测结果的输出主要来源高分别率特征图,因此对网络结构进行简化,去掉了PAN结构,仅保留FPN部分,裁减掉另外两个低分辨率的检测头。
针对关键点检测所用的Heatmap方法计算量大、不适合部署在边缘设备上的问题,本方法目标检测的方法,将关键点当成目标进行检测。目标模型的整体架构基于YOLOX,YOLO系列的模型在业内是公认的兼具精度与速度的模型,YOLOX在历代YOLO模型的基础上首次使用了分类检测头、回归检测头分离的解耦头,增加了模型的收敛速度,同时提高了模型的可拓展性;使用simOTA标签分配策略使模型在使用anchor free机制的情况下也能有非常好的检测效果,简化了历代YOLO模型使用anchor base机制下模型output decode的复杂度。通过对模型结构简化、部署时使用int8量化,使模型能够做到在边缘设备上实时检测的需求。
针对关键点匹配组合算法复杂度高的问题,本发明采用了关键点embedding的方法,每个关键点都会通过模型回归出一个embedding值,在训练过程中让同个检测对象的每个关键点embedding值向相等的方向收敛;不同检测对象的关键点embedding值向距离增大的方向收敛。最终在模型推理时,可直接通过聚类的方式将embedding值近似的关键点归类于同一个检测对象,简化了关键点匹配组合流程。
同时由于是对关键点的检测,特征图分辨率越高越有利于回归出精确坐标,又因为Yolo算法对小目标检测结果的输出主要来源高分别率特征图,因此对网络结构进行简化,去掉了PAN结构,仅保留FPN部分,裁减掉另外两个低分辨率的检测头。
以上说明书中描述的只是本发明的具体实施方式,各种举例说明不对本发明的实质内容构成限制,所属技术领域的普通技术人员在阅读了说明书后可以对以前所述的具体实施方式做修改或变形,而不背离发明的实质和范围。
- 基于2D工业相机的工件目标检测及三维姿态判定方法
- 基于2D检测的物体6D姿态估计方法、装置及计算机设备