一种基于高斯分布改进的文本对抗方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于文本对抗处理领域,具体涉及一种基于高斯分布改进的文本对抗方法。
背景技术
深度神经网络(Deep Neural Network,DNN)已经被广泛应用于多个领域(图像、自然语言、语音等),并由于其出色的表现,开始广泛地从学术论文走向现实生产,如物体识别、自动驾驶、语音识别、情感分析等。同时,人们也发现了其极易受到对抗性攻击的脆弱性质。如在图像领域中,只需人为向合法输入中添加少量像素进行干扰,就可使DNN做出错误的预测。因此为了迷惑DNN,人们通过向原始输入中添加不可察觉的恶意扰动,产生对抗样本,让网络做出错误判断,以求进一步提高网络的鲁棒性与可解释性。
图像处理领域的对抗攻击多种多样,这是因为很容易在添加攻击的同时保持图像原本表征效果,并顺利达到迷惑DNN的目的。在NLP中,有很多如机器翻译、垃圾邮件筛选等的安全性敏感任务,由于文本的离散性特点,和图像领域相比,它们更易受攻击影响。同时,在生成对抗样本时也存在很多困难,因为稍不严谨的对抗攻击,很容易产生一些奇怪的对抗样本。理想的攻击样本,应当是在很好地迷惑模型时,仍能保证语义相似性和句子正确性。
根据基本变化单位的不同,文本对抗方法可以分为字符级别、词级别和句子级别攻击。字符级别攻击通过对字符进行插入、交换、删除等操作来生成对抗样本,而这显然很容易产生错误词汇。句子级别攻击通过对句子进行释义来生成对抗样本,对句子进行大幅修改,这则容易产生语义歪曲的问题。与此相比,词级别攻击通过使用具有类似语义且词性合适的词或短语,替换原始输入句子中的几个词,以产生对抗样本,能更好地保持语义和句子正确性。因此,近期许多工作都转向了词级别的攻击。现有的词级别对抗方法已被证明是组合优化问题,可分为缩减搜索空间与搜索两个阶段。缩减搜索空间的常见方法是为原始样本每个单词准备候选词进行替换,使用这些候选词的组合作为递减的离散搜索空间;搜索则是指在这个递减的搜索空间中找到有效的对抗样本。Alzantot等人【Alzantot M,Sharma Y,Elgohary A,et al.Generating Natural Language Adversarial Examples[C]//Proceedings of the 2018Conference on Empirical Methods in NaturalLanguage Processing.2018:2890-2896.】使用词嵌入距离加语言模型获得候选词的搜索空间,并使用遗传算法对空间中样本进行搜索优化;Ren等人【Ren S,Deng Y,He K,etal.Generating natural language adversarial examples through probabilityweighted word saliency[C]//Proceedings of the 57th annual meeting of theassociation for computational linguistics.2019:1085-1097.】使用同义词获取候选词,并使用贪心算法进行搜索。
由于粒子群优化(PSO)算法已被证明能有效解决优化问题,故Zang等人【Zang Y,Qi F,Yang C,et al.Word-level Textual Adversarial Attacking as CombinatorialOptimization[C]//Proceedings of the 58th Annual Meeting of the Associationfor Computational Linguistics.2020:6066-6080.】使用与原始词拥有相同义原的替换词构建缩减搜索空间,并最先引入PSO算法搜索对抗样本;Xu【徐尹翔,陈祺东,孙俊.应用量子行为粒子群优化算法的文本对抗[J].计算机工程与应用,2022,58(9):175-180.】等人在此基础上进行改进,使用量子行为粒子群优化(QPSO)算法更有效地进行搜索。这些基于PSO的对抗方法均取得了不错的结果。
然而,在一些复杂的情况下,尤其是在求解句子中有很多单词的高维优化问题时,这些PSO算法经常出现全局搜索能力弱、过早收敛,最终陷入局部最优的情况。其中一个原因在于,这些方法在每次迭代进行搜索时,均只使用均匀分布,搜索范围受限。
发明内容
本发明旨在解决上述技术问题,提供一种基于高斯分布改进的文本对抗方法。本发明向原使用均匀分布的搜索算法中添加了新的高斯分布项,从而实现在搜索前期在局部进行广泛探索,在后期寻找到全局最优的对抗样本。
本发明的技术方案:
一种基于高斯分布改进的文本对抗方法,步骤如下:
1)对语料库进行词级别标记化(tokenize);
2)对各标记(token)进行词形还原(lemmatization),去除词缀,得到词原型;
3)使用知网(HowNet),获取各标记的词原型的所有概念(sense)的义原树,以及概念对应的词性标签;
4)对每一个标记的词原型,筛选其内容词词性作为有效词性,并按词性初始化候选词列表;
5)如标记的词原型的内容词词性中无有效词性,或知网查询结果为空,则直接返回初始化的空候选词列表;
6)遍历语料库中所有其他标记,寻找与当前标记的词原型的某一概念拥有相同词性和相同义原注释的其他标记的词原型。如找到,则为这个其他标记的词原型添加与当前标记相同的词缀,存入当前标记对应词性的候选词列表中;
7)对所有标记完成步骤6)后,得到完整的候选词列表;
8)对于一个有D个词的,能被受害模型正确预测的原始输入样本O,开始由它生成相应的一个对抗样本。首先根据原始样本O各个词的词性筛选出候选词列表,如整个样本O中所有词均无候选词,则攻击失败,算法结束;
9)对于原始样本O的第j个词X
10)每一个候选对抗样本,都对应解空间中的一个位置,在应用高斯分布的量子行为粒子群优化(Quantum behaved Particle Swarm Optimizationwith Gaussiandistribution,GQPSO)算法中被称为一个粒子。候选对抗样本被受害模型预测为目标错误标签的概率值,称为在该位置上粒子的优化分数。使用GQPSO在解空间中搜索对抗样本时,先初始化一个包含M个粒子的种群,每一个粒子由原始输入样本O中,根据各位置突变概率,随机选择一个原词X
11)在GQPSO算法的第t次迭代时,
其中
12)检查优化分数最高的粒子能否成功迷惑模型将其预测为目标错误标签,如是,则其对应的对抗样本即所要寻找的样本,攻击成功,算法结束;
13)在每次迭代中,粒子先进行位置更新,后重复步骤12);如未找到成功的对抗样本,则进行步骤10)中的粒子突变操作,再重复步骤12);如仍未找到,则更新个体与全局最优位置后,开始下次迭代至最大迭代次数T。其中位置更新的具体方法为:
首先使用式(4)计算粒子各维暂时位置,
由于
14)如达到最大迭代次数T,则攻击失败,算法结束。
本发明的有益效果:提出了一种新的词级别文本对抗方法Sememe-GQPSO,通过将高斯分布引入到量子行为粒子群优化算法中,有效提升了攻击方法对模型的攻击能力。对比实验证明,本方法在提高攻击成功率,降低修改率的同时,能够生成质量更高的对抗样本,攻击效率更好,将有利于进一步提高网络的鲁棒性与可解释性。
附图说明
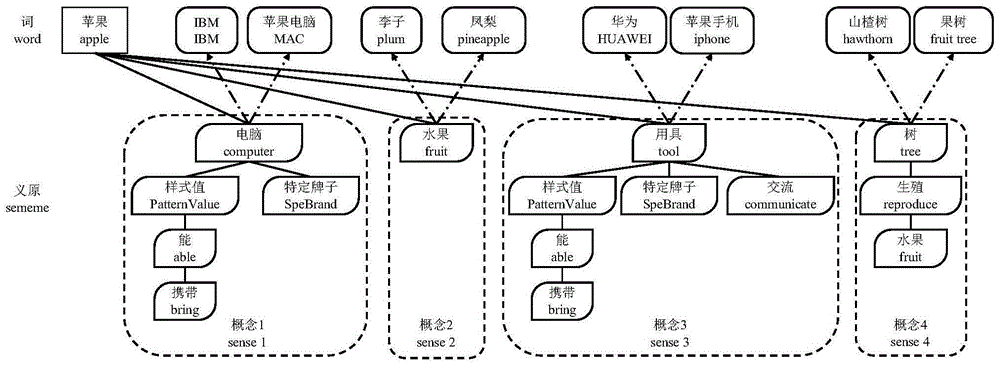
图1苹果(apple)各概念在知网中的义原树以及部分与苹果拥有相同义原标注的词。
具体实施方式
1 相关工作
1.1 义原与知网
义原(sememe)在语言学中被定义为人类语言最小语义单位,一个词的含义可以用这个词的义原组合来表示,具有相同义原注释的单词具有相同的含义,它们可以相互替代。Dong等人【DONG Z,DONG Q.Hownet and the computation of meaning[M].USA:WorldScientific Publishing Co Inc,2006.】使用预定义的2000多个义原,为20多万个由中英文词语所表示的概念(sense,即语义)进行了标注,形成了义原知识库,即知网(HowNet)。知网中的每个词都被表示为树形结构,由于一个词可能有多种概念,故每个概念都是一个义原树。如图1所示,“苹果(apple)”该词含有“苹果电脑”、“水果”、“苹果手机”、“苹果树”四种概念,这些在知网中使用预定义的义原分别进行标注,形成了树状结构。类似的知识库还有普林斯顿大学构建的基于单词的语义知识库WordNet。与WordNet相比,作为基于概念的知识库,知网可以找到更多语义相关的词。
由于义原这种贴近语言本质的特点,其已被广泛应用于NLP的多项任务中,如文本匹配、语义合理性评估、词汇融合等。
1.2量子行为粒子群优化算法
量子行为粒子群优化(QPSO)算法是对粒子群优化算法进行改进的一种算法,由Sun等人【Sun J,Xu W,Feng B.Aglobal search strategy of quantum-behaved particleswarm optimization[C]//IEEE Conference on Cybernetics and IntelligentSystems,2004.IEEE,2004,1:111-116.】于2004年提出。QPSO算法通过模拟量子系统中叠加态的强不确定性,能够在迭代寻优过程中覆盖整个搜索空间,而不是像其它一些PSO算法在搜索过程的末尾失去全局搜索能力,陷入局部最优。其更新方法与经典PSO有很大不同,粒子仅更新位置,没有速度的概念。假设一个包含M个粒子的群体在D维搜索空间中进行搜索,在第t次迭代时,
其中
2Sememe-GQPSO
本发明提出了一种基于义原和使用高斯分布改进的QPSO算法的文本对抗攻击方法,称为Sememe-GQPSO。即在缩减搜索空间阶段,先使用基于义原的方法为每个单词准备候选词,随后在搜索阶段,使用经过高斯分布改进的QPSO算法对候选对抗样本进行搜索,最终得到生成的对抗样本。
2.1基于义原的候选词提取方法
基于义原的候选词选取方法由Zang等人【Zang Y,Qi F,Yang C,et al.Word-level Textual Adversarial Attacking as Combinatorial Optimization[C]//Proceedings of the 58th Annual Meeting of the Association for ComputationalLinguistics.2020:6066-6080.】最先提出。该方法将与原始输入词拥有相同义原的词作为候选词。相较于如语言模型预测分数、基于词向量距离、基于同义词等方法,基于义原的方法能够找到更多高质量的候选词,因而本发明也采用该方法选取候选词。
仍以“苹果(apple)”为例,该词四种概念的义原树根结点分别为“电脑(computer)”、“水果(fruit)”、“用具(tool)”和“树(tree)”,对应拥有相同义原标注的词分别有“苹果电脑(MAC)”、“凤梨(pineapple)”、“华为(HUAWEI)”、“果树(fruittree)”等等。通过这种方法,即找到了“苹果”的替换词。而如果对于一个词,没有其他的词和它拥有完全相同的义原,那么其就没有替换词。
为减少引入语法错误,我们仅选取内容词进行替换,并要求候选词需与原词具有相同的词性标签。对于如“苹果”这种一词多义的情况,仅当原词的一个概念与候选词的一个概念拥有相同的义原注释时,原词才可以被该候选词替换。此外,还使用词性还原在避免引入语法错误的同时,检索到更多候选词。
通过上述方法,为句子中的每个词生成候选词列表。为了提高攻击效率,仅保留每个词的候选词列表中,对受害模型伤害最大者(即在仅将原句中一个词替换为其某个候选词的情况下,让模型预测为目标错误标签的概率最大的那个候选词),作为该原词的候选词,过滤掉其余伤害力弱的候选词,进一步对搜索空间进行缩减,提高攻击效率。
2.2应用高斯分布的QPSO搜索方法
对于文本对抗问题,其解空间由句子各位置候选词所有的替换组合形成。故在通过义原方法得到句中各位置的候选词后,使用应用高斯分布的QPSO(GQPSO)算法在该离散的解空间中搜索对抗样本。每一个候选对抗样本,都对应解空间中的一个位置;候选对抗样本被模型预测为目标错误标签的概率值,对应在该位置上粒子的优化分数。
具体的,给定一个长度为D的原始输入O,其对抗样本的解空间维度也为D。GQPSO算法在解空间中搜索时,将先初始化一个包含M个粒子的种群,每一个粒子由原始输入O中随机一个原词突变为其候选词而来。候选词对模型伤害越大,突变概率越高。生成种群后,计算各粒子优化分数,为
为了找到一个能以更小的修改率,成功攻击受害模型的对抗样本,算法需要提升在迭代前期的局部搜索能力,并在后期快速达到全局最优位置。故在原QPSO已使用均匀分布的基础上,新引入高斯分布项,得到GQPSO粒子位置更新公式:
其中
由于
在(10)中,由于α
在整个算法流程,每次计算粒子优化分数,都将检查分数最高的粒子能否成功迷惑模型将其预测为目标的错误标签,如是,则其对应的对抗样本,攻击成功;否则在达到最大迭代次数T后,攻击失败。
3实验
3.1数据集、受害模型与攻击方法
数据集方面,选用了三种经典的NLP分类数据集,分别是情感分类任务的IMDB【
Maas A,Daly R E,Pham P T,et al.Learning word vectors for sentimentanalysis[C]//Proceedings of the 49th annual meeting of the association forcomputational linguistics:Human language technologies.2011:142-150.】、SST-2【Socher R,Perelygin A,Wu J,et al.Recursive deep models for semanticcompositionality over a sentiment treebank[C]//Proceedings of the2013conference on empirical methods in natural language processing.2013:1631-1642.】,和自然语言推理分类任务的SNLI【Bowman S,Angeli G,Potts C,et al.Alargeannotated corpus for learning natural language inference[C]//Proceedings ofthe 2015Conference on Empirical Methods in Natural Language Processing.2015:632-642.】。IMDB和SST-2都来自电影评论领域,都是输入为一个句子的二分类任务数据集,区别在于IMDB输入句子普遍更长,SST-2更短。SNLI由斯坦福大学发表,是输入为前提-假设句子对的三分类任务数据集,三种类别分别是包含、矛盾、中立。数据集的更多相关信息详见表1。
表1:三种基准数据集的信息汇总。‘Train’,‘Dev’,‘Test’分别表示训练集、验证集、测试集数量,‘AvgWord’表示平均句长。
在受害模型上,选择Bi-LSTM模型和BERT模型。Bi-LSTM是NLP领域的经典模型;BERT模型是Devlin等人【Devlin J,Chang M W,Lee K,et al.BERT:Pre-training of DeepBidirectional Transformers for Language Understanding[C]//Proceedings of the2019Conference of the North American Chapter of the Association forComputational Linguistics:Human Language Technologies,Volume 1(Long and ShortPapers).2019:4171-4186.】于2019年提出的基于双向Transformer的预训练语言模型,提出时在多项NLP任务上取得了最好效果。本发明的Bi-LSTM使用由Conneau等人【Conneau A,Kiela D,Schwenk H,et al.Supervised Learning of Universal SentenceRepresentations from Natural Language Inference Data[C]//Proceedings ofthe2017Conference on Empirical Methods in Natural Language Processing.2017:670-680.】于2017年提出的后接最大池化层模型,使用300维的GloVe【Pennington J,Socher R,Manning C D.Glove:Global vectors for word representation[C]//Proceedings of the 2014conference on empirical methods in natural languageprocessing(EMNLP).2014:1532-1543.】预训练词向量,隐含层维数设置为128维;BERT模型使用base版。
本发明共选取了四种攻击方法作为实验对比。第一个对比方法是Alzantot等人提出的E/L-Genetic方法,该方法在词向量中寻找替换词,通过限制词向量空间的距离来控制替换词的数量,然后使用遗传算法搜索对抗样本。第二个对比方法是Ren等人提出的Synonym-Greedy方法,使用同义词作为替换词,计算其语言模型分数,然后使用贪心算法对抗样本进行搜索。后两种分别是由Zang等人提出的Sememe-PSO和Xu等人提出的Sememe-QPSO方法,均使用基于义原的方法寻找替换词,区别在于Zang等人使用PSO算法来搜索对抗样本,Xu等人则使用QPSO算法进行搜索。
3.2评价指标
实验使用攻击成功率、对抗样本平均修改率、可转移性和不可察觉度进行评价,其中攻击成功率和对抗样本平均修改率计算方法分别如下:
式中,|sent
对抗样本的可转移性,表示攻击方法在不对模型进行事先访问的情况下,攻击DNN的能力,反映其对不同受害模型攻击能力的普适性,也是衡量攻击方法效果的重要指标。模型对转移来的样本分类准确率越低,表明样本迷惑模型越成功,可转移性越高,对抗方法性能越好。
不可察觉度是衡量对抗样本质量的重要要求,除对抗样本平均修改率外,还包括语义、语法、流畅度等人类语言要求。本发明使用专业人员打分的方式进行评价。
为提高评价效率,限制原始输入长度为10-100,并限制有效样本修改率在25%以下,即如果修改率超过该值,则认为攻击失败。使用数据集测试集中随机的1000个的正确分类样本作为原始输入集合。另外,在SNLI中,只对假设句进行修改。
3.3参数设置
在GQPSO算法中,设置最大迭代次数T为20,种群中粒子数量M为60,α
3.4实验结果
五种攻击方法在三个数据集上,对两种模型进行攻击的成功率如表2。可见本发明所提出的添加高斯分布改进的新方法取得了最高的攻击成功率。其中对于IMDB和SST-2两个同为二分类的电影评论数据集,由于两者平均长度相差较大,故在生成SST-2的对抗样本时,修改率很容易超过设定限制,导致攻击失败。使得对SST-2上模型攻击的成功率较IMDB上的略低。对于SNLI数据集来说,由于其是输入为句子对的三分类自然语言推理数据集,且句长更低,攻击难度大,故攻击成功率相比更低。
表2:五种攻击方法的攻击成功率
攻击成功的对抗样本的平均修改率如表3。可见本发明所提出方法在达到更高攻击成功率的同时,仍拥有优秀的修改率。
表3五种攻击方法的对抗样本平均修改率
3.5可转移性
本发明使用BERT模型,对为攻击Bi-LSTM模型生成的对抗样本进行分类,来评估样本的可转移性,反之亦然。两种模型对转移来的对抗样本分类准确率如表4,可见我们提出的方法有更好的可转移性,对抗样本普适性更好。尤其与原Xu等人的Sememe-QPSO方法相比,我们使用高斯分布改进的方法有明显优化。
表4两种模型对转移来的对抗样本分类准确率
3.6人工评测与实例分析
我们沿用Zang等人的评价方法,在SST-2数据集上,选取500对原始输入样本和针对Bi-LSTM模型生成的对抗样本,由三位专业人员对它们进行打分,围绕符合人类语言要求程度,判断样本属于“机器生成”、“不确定”和“人类书写”中哪一类,分别打1、2、3分。评分结果如表5,可见,与基于词向量、基于同义词的方法相比,三种基于义原获取候选词的方法能够更好地保证扰动的不可察觉性。同时与Zang等人和Xu等人的方法相比,所提出的GQPSO对抗样本搜索方法,能够搜索到质量更高的对抗样本。
表5扰动不可察觉度人工评分
在SST-2数据集上,针对Bi-LSTM模型生成对抗样本的实例对比如表6。可见在均使用义原获取候选词的情况下,与Zang等人和Xu等人的方法相比,本发明方法能以更低的修改率成功迷惑模型,且生成的对抗样本与人类语言更相似,样本质量更高,再次证明了使用高斯分布改进的方法的明显优化效果。
表6对抗样本实例对比
本发明提出了一种新的词级别文本对抗方法,通过将高斯分布引入到量子行为粒子群优化算法中,提升了攻击方法对模型的攻击能力。对比实验证明,Sememe-GQPSO方法在提高攻击成功率,降低修改率的同时,能够生成质量更高的对抗样本,攻击效率更好。
- 一种基于文本-图像对抗网络模型的分解卷积方法
- 基于改进的量子行为粒子群优化算法的文本对抗攻击方法
- 基于改进GA的深度神经网络对抗性文本生成方法及系统