一种网约车需求模式识别与短时需求预测方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及交通需求预测技术领域,尤其是涉及一种网约车需求模式识别与短时需求预测方法。
背景技术
城市客运枢纽是旅客集散的中心,在客运交通运输过程中发挥着组织、协调、服务的重要作用。城市客运枢纽旅客的激增和滞留,不仅给人民群众的出行带来不便,同时存在重大安全隐患。随着互联网技术的提升,基于共享出行理念的网约车服务迅猛发展,成为保障旅客便捷出行的重要手段。
目前,对于城市客运枢纽网约车需求规律和需求预测的相关研究较少,行业主管部门及网约车平台主要凭借经验部署城市客运枢纽的运力调度工作,存在保障不精准、调运不及时等问题。为了有效治理城市客运枢纽客流激增现象,提高网约车调度效率,迫切需要对网约车需求进行精准预测。本发明综合利用多源数据,提出了数据特征驱动的网约车需求模式分析和短时需求预测方法,能够为城市客运枢纽的客流管理提供决策依据。
发明内容
本发明的目的是提供一种网约车需求模式识别与短时需求预测方法,针对机场、火车站等城市交通枢纽,识别出多种网约车需求模式,在不增加运营成本的前提下,利用多源异构的城市级数据资源,对网约车需求模式进行分析,并预测未来一段时间的网约车需求量。
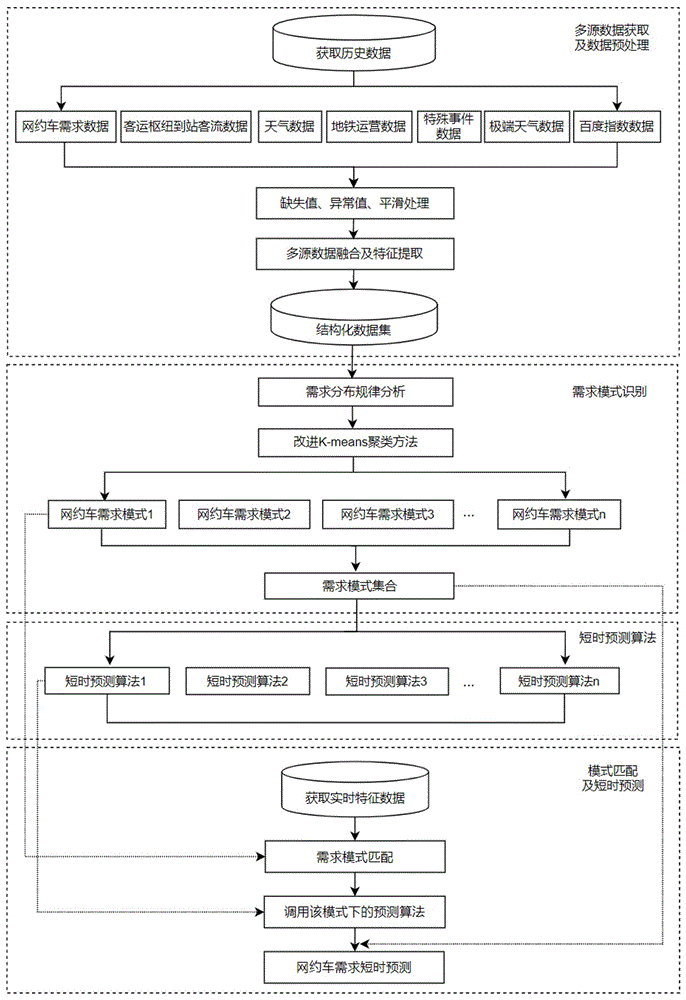
为实现上述目的,本发明提供了一种网约车需求模式识别与短时需求预测方法,包括以下步骤:步骤S1:多源数据预处理及特征提取,筛选出城市客运枢纽的网约车需求模式识别与短时预测场景适用的多源数据,将多源数据作为初始数据,以一天作为一个样本周期,对所述初始数据进行预处理,预处理包括填补缺失值,数据平滑,筛选并修正异常值等操作;将初始数据以特定的时间粒度汇聚,并对相关时间、天气、特殊事件等特征进行全面提取,得到基础数据集;
步骤S2:网约车需求模式识别,基于改进的时间序列K-means聚类算法,以一天作为一个样本周期,对步骤S1中基础数据集进行聚类分析,得到多维特征指标下的典型网约车需求模式集合;
步骤S3:网约车需求短时预测算法,针对步骤S2获得的每种典型网约车需求模式,基于该类别的所有数据样本,分别验证短时需求预测模型的有效性,并从中选择最适合的短时需求预测算法。
步骤S4:需求模式匹配与短时需求预测,基于实时获取的特征数据,匹配步骤S2中得到的网约车需求模式,根据适配的网约车需求模式,调用对应的短时预测算法,预测网约车的短时需求量。
步骤S1中所述多源数据包括:网约车需求数据、城市客运枢纽到站客流数据、温度数据、降水数据、地铁运营状态数据、特殊事件数据、极端天气数据、百度指数数据。
优选的,步骤S1的预处理具体为:
预处理中缺失值处理的实现为,以一天作为一个样本周期,针对连续缺失数据为至多两个的缺失数据,取值为和前一个最近的值;针对连续缺失数据为至少两个的缺失数据,采用线性插值方法对数据缺失值进行填补,假设在连续时间段内检测到缺失值,线性插值方法填补缺失值的公式如下:
优选的,步骤S1对相关特征进行全面提取操作具体如下:
多源数据融合:统一将多源数据以特定的时间粒度汇聚,并将多源数据整合为结构化数据集;
特征提取:分别提取融合后数据集的日期特征、天气特征、城市客运枢纽到站客流特征、地铁运营特征、特殊事件特征、极端天气特征和百度指数特征;
相关性分析:计算各特征之间的相关性系数,根据皮尔森相关系数
步骤S22:确定聚类指标,根据需求分布规律,选取相应的聚类指标;在进行聚类分析的过程中,为防止数量级别大的指标对结果产生干扰,需要对数据进行归一化处理;
步骤S23:确定权重系数,使用加权变异系数K-means聚类方法,该方法在所有聚类指标之间分配不同的权重;
步骤S24:改进K-means聚类算法识别网约车需求模式:确定最佳聚类数目后,对所述聚类指标使用改进K-means聚类算法识别网约车需求模式。优选的,步骤S2中所述多维特征指标是指根据时间、特殊事件等特征确定的聚类指标,所述网约车需求模式集合包括不同模式下网约车需求的时间序列数据集合。优选的,所述步骤S3中短时需求预测模型包括ARIMA、XGBoost、RF、BiLSTM、CNN等。选择短时需求预测算法,具体如下:分别计算ARIMA、XGBoost、RF、BiLSTM、CNN等不同短时预测模型的RMSE、MAE、MAPE、R
数据中具有较高离散程度的聚类指标被赋予更大的权重,以加强其在聚类过程中的作用,相反,数据中离散程度较低的聚类指标则分配较小的权重,以削弱其影响,某个指标对应的变异系数计算如下:
步骤S241:随机选取K个点,作为聚类中心;步骤S242:计算每个点分别到K个聚类中心的距离,将该点分到最近的聚类中心,形成K个类;
步骤S243:重新计算每个类的聚类中心;
步骤S244:重复以上步骤S242至步骤S243,直到每个类的聚类中心的位置不再发生变化或达到设定的迭代次数。因此,本发明采用上述的一种网约车需求模式识别与短时需求预测方法,具有以下有益效果:
本发明融合并提取多源数据特征,得到多种典型的网约车需求模式;针对不同需求模式,训练短时需求预测算法;基于实时特征数据匹配需求模式,调用预测算法来预测未来一段时间的网约车需求量。本发明的方法将历史数据与实时数据相结合,既能从城市客运枢纽的网约车需求规律的角度出发,通过对历史数据的分析识别出网约车需求模式,又能根据网约车需求模式高效预测网约车需求,更加充分地挖掘数据中的潜在信息和价值,从而有效应对城市客运枢纽激增客流问题。下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明提供的一种网约车需求模式识别与短时需求预测方法的流程图;
图2为本发明提供的各种特征之间的相关性排序示意图;
图3为本发明提供的各种特征之间的相关性热力图示意图;
图4为本发明提供的节假日与非节假日需求分布示意图;
图5为本发明提供的有特殊事件与无特殊事件需求分布示意图;
图6为本发明提供的节假日下有特殊事件与无特殊事件需求分布示意图;图7为本发明提供的非节假日下有特殊事件与无特殊事件需求分布示意图;
图8为本发明提供的有特殊事件下节假日与非节假日需求分布示意图;
图9为本发明提供的轮廓系数示意图;
图10为本发明提供的网约车需求模式示意图;
图11为本发明提供的不同网约车需求模式匹配示意图;
图12为本发明提供的网约车需求量短时预测示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
第一步,多源数据预处理及特征提取:面向多源异构的城市级数据资源,筛选出城市客运枢纽的网约车需求模式识别与短时预测场景适用的多源数据,将多源数据作为初始数据,初始数据包括城市客运枢纽的网约车需求数据、城市客运枢纽的到站客流数据、节假日数据、周边天气数据、地铁运营状态数据、特殊事件数据、极端天气数据、百度指数等;以一天作为一个样本周期,对初始数据进行预处理,预处理包括填补缺失值,数据平滑,筛选并修正异常值等操作;统一将初始数据以特定的时间粒度汇聚,并对相关时间、天气、特殊事件等特征进行全面提取,得到基础数据集;
第二步,网约车需求模式识别:基于改进的时间序列K-means聚类算法,以一天作为一个样本周期,对第一步中基础数据集进行聚类分析,得到多维特征指标下的典型网约车需求模式集合。多维特征指标是指根据时间、特殊事件等特征确定的聚类指标,网约车需求模式集合包括不同模式下网约车需求的时间序列数据集合;
第三步,网约车需求短时预测算法:针对第二步获得的每种典型网约车需求模式,基于该类别的所有数据样本,分别验证ARIMA、XGBoost、RF、BiLSTM、CNN等短时需求预测模型的有效性,并从中选择最适合的短时需求预测算法;
第四步,需求模式匹配与短时需求预测:基于实时获取的特征数据,匹配第二步中得到的网约车需求模式,根据适配的网约车需求模式,调用对应的短时预测算法,预测网约车的短时需求量。
预处理中的缺失值处理的实现为,针对连续缺失数据为两个及以下的缺失数据,取值为前一个最近的值;针对连续缺失数据为两个以上的缺失数据,采用线性插值方法对数据缺失值进行填补,假设在连续时间段内检测到缺失值,
预处理中的数据平滑处理的实现为,基于移动平均的网约车需求数据平滑。移动平均法是一种数据平滑技术,基本思想是根据时间序列逐项推移,依次计算包含一定项数的时序平均值,以反映长期趋势的方法,其本质是一种低通滤波,目的是过滤掉时间序列中的高频扰动,保留有用的低频趋势,消除周期变动和不规则变动的影响,显示出长期趋势。设有一个时间序列,基于滑动窗口的思想,按数据点顺序逐点推移求出
多源数据融合:统一将多源数据以特定的时间粒度汇聚,并将多源数据整合为结构化数据集;
特征提取:分别提取融合后数据集的日期特征、天气特征、城市客运枢纽到站客流特征、地铁运营特征、特殊事件特征、极端天气特征和百度指数特征;
相关性分析:计算各特征之间的相关性系数。皮尔森相关系数是常用的一种线性相关系数,记为
(1)对数据进行描述性统计分析,得到网约车下单需求分布规律;
(2)确定聚类指标:根据需求分布规律,选取相应的聚类指标;在进行聚类分析的过程中,为防止数量级别大的指标对结果产生干扰,需要对数据进行归一化处理;
(3)确定权重系数:使用加权变异系数K-means聚类方法,该方法在所有聚类指标之间分配不同的权重。具体而言,数据中具有较高离散程度的聚类指标被赋予更大的权重,以加强其在聚类过程中的作用。相反,数据中离散程度较低的聚类指标则分配较小的权重,以削弱其影响。某个指标对应的变异系数计算如下:
其中,
为了确定最佳聚类数,即K的值,我们采用轮廓系数来评估与每个K值相关的聚类表现,并选择聚类效果最好的作为最终的K值。首先,对于每个样本,其轮廓系数定义为:
(4)改进K-means聚类算法识别网约车需求模式:确定最佳聚类数目后,对聚类指标使用改进K-means聚类算法识别网约车需求模式,改进K-means聚类算法的具体操作步骤如下:
1)随机选取K个点,作为聚类中心;
2)计算每个点分别到K个聚类中心的距离,将该点分到最近的聚类中心,这样可形成K个类;
3)重新计算每个类的聚类中心,即均值;
4)重复以上2)-3)步,直到每个类的聚类中心的位置不再发生变化或达到设定的迭代次数。
其中,第(2)、(3)步为改进K-means聚类算法的体现,确定聚类指标和确定指标权重系数能体现不同指标对于聚类的影响能力不同,优化聚类的效果。
第三步中,基于每种典型网约车需求模式样本数据选择最适合的短时需求预测算法,具体如下:分别计算ARIMA、XGBoost、RF、BiLSTM、CNN等不同短时预测模型的RMSE、MAE、MAPE、R
实施例
具体以北京西站客运枢纽为例,现收集获取到106天时间跨度从2021年1月1日至2022年5月4日包含全部节假日和部分工作日的多源数据,以一天作为一个样本周期,具体包含网约车需求数据、天气数据(包含温度、降水数据)、北京西站地铁首末班车数据、北京西站到站客流数据。另外,通过网络爬虫技术爬取了数据集对应的特殊事件数据、极端天气数据和百度指数数据(包含搜索指数、PC端搜索趋势、移动端搜索趋势)。
针对此数据集,本发明对其网约车需求进行模式识别和短时需求预测。具体步骤如下:
(1)多源数据预处理及特征提取:将2021年1月1日至2022年5月4日包含全部节假日和部分工作日的多源数据作为初始数据,对初始数据进行预处理,预处理操作包括对数据填补缺失值,对网约车需求数据平滑处理,
筛选并修正数据异常值。以2021年1月1日0:00-23:00时段的网约车需求数据为例,预处理后网约车需求数据如表1所示。
表1 网约车需求数据
预处理中的缺失值处理的实现为,针对连续缺失数据为两个及以下的缺失数据,取值为前一个最近的值;针对连续缺失数据为两个以上的缺失数据,采用线性插值方法对数据缺失值进行填补。
异常值处理的实现为,采用三倍标准差分解法,首先筛选与样本均值之差大于三倍标准差的异常样本数据,并将其值调整为样本均值与三倍标准差之和;然后筛选与样本均值之差小于负三倍标准差的异常值,调整为样本均值与三倍标准差之差。
数据平滑处理的实现为,基于移动平均的网约车需求数据平滑。滑动窗口设置为3,基于滑动窗口的思想,按数据点顺序逐点推移求出平均值,即可得到一次移动平均数。多源数据融合及特征提取的实现为,将预处理后的多源数据进行融合,统一将全部数据以1小时汇聚,1天可划分为24个相等时段,并分别提取融合后数据集的日期特征、天气特征、到站客流特征、地铁运营特征、特殊事件特征、极端天气特征和百度指数特征。具体如下:
1、多源数据融合:统一将多源数据以1小时间隔汇聚,将文本数据转为数值型数据,并将多源数据整合为结构化数据集,见表2。
表2 结构化数据集
2、特征提取:分别提取结构化数据集的日期特征、天气特征、到站客流特征、地铁运营特征、特殊事件特征、极端天气特征和百度指数特征,见表3。其中日期特征包括:年份、月份、日期、小时、星期几、是否工作日、是否周末、是否节假日和1-5个步长的滞后周期;天气特征包括:温度、降水;到站客流特征包括:到站客流人数;地铁运营特征包括:地铁是否运营;特殊事件特征包括:当日受特殊事件影响人数,前一日受特殊事件影响人数;百度指数特征包括:搜索指数、PC端搜索趋势、移动端搜索趋势;极端天气特征包括:前一天是否存在极端天气或大量旅客滞留信息。
表3 数据集特征
3、相关性分析:计算皮尔森相关系数计算各种特征之间的相关性,相关性排序及热力图见图2、图3,选择相关性系数较大的:1-5个步长的滞后期、小时、地铁是否运营、移动端搜索趋势、极端天气、气温、是否节假日、到站客流人数、降水、前一日受特殊事件影响人数作为后续预测的特征变量(2)网约车需求模式识别:基于改进的时间序列K-means聚类算法,以一天作为一个样本周期,对(1)中基础数据集进行聚类分析,得到多维特征指标下的典型网约车需求模式集合。其中多维特征指标是指根据时间、特殊事件等特征确定的聚类指标,网约车需求模式集合包括不同模式下网约车需求的时间序列数据集合。具体如下:1、对数据进行描述性统计分析,得到网约车下单需求分布规律。将数据集根据是否节假日、是否有特殊事件进行划分,对1小时粒度网约车需求量均值进行可视化展示,可以得到对应需求的分布情况,分别如图4-8所示。2、聚类指标的确定:根据网约车需求数据的分布特征,选取全天均值、偏度;20:00-22:00均值;22:00、23:00需求量;20:00-24:00峰值;0:00、1:00需求量、2:00-5:00均值、0:00-5:00峰值、当日特殊事件受影响人数、前一日特殊事件受影响人数、是否极端天气作为共13个指标作为聚类指标;在进行聚类分析的过程中,为防止数量级别大的指标对结果产生干扰,需要对数据进行归一化处理。3、权重的选取:使用每个时间节点的变异系数作为权重赋值给每个时间点下的需求值数据。4、确定最佳聚类数目的:使用轮廓系数来确定最佳聚类数目。从图9中可以看出,当聚类数目为3时,轮廓系数最大,即最佳聚类数目为3类。5、改进K-means聚类识别网约车需求模式:确定最佳聚类数目后,对聚类指标使用改进K-means聚类算法实现网约车需求模式识别,网约车需求模式如图10所示,北京西站网约车需求模式可分为三类:模式1为无特殊事件+非节假日后半段模式(此类模式所包含的日期大多数为特殊事件受影响人数较少的工作日、周末、短节假日及长节假日前半段);模式2为无特殊事件+节假日后半段模式(此类模式所包含的日期大多数为特殊事件受影响人数较少的长节假日的后半段及极端天气或突发事件影响下的特殊日期);模式3为特殊事件严重模式(此类模式所包含的日期为受特殊事件影响较严重的日期)。(3)网约车需求短时预测算法:获得的每种典型网约车需求模式,基于该类别的所有数据样本,分别验证ARIMA、XGBoost、RF、BiLSTM、CNN等短时需求预测模型的有效性,并从中选择适合的短时需求预测算法。具体如下:获得的每种典型网约车需求模式,基于该类别的所有数据样本,按照9:1分为训练集和测试集,将训练集加入到集成了ARIMA、XGBoost、RF、GBDT、BiLSTM、CNN、GRU等多种预测方法预测系统中进行训练并在测试集上测试,分别计算不同预测方法下的RMSE、MAE、MAPE、R
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神。
- 一种考虑时空非平稳性的网约车出行需求预测方法
- 一种基于时空多图神经网络的网约车需求预测方法