一种MSM在多GPU下的优化方法及装置
文献发布时间:2023-06-19 19:28:50
技术领域
本申请涉及密码学技术领域,具体涉及一种MSM在多GPU下的优化方法及装置。
背景技术
零知识证明(Zero—Knowledge Proof),指的是证明者能够在不向验证者提供任何有用的信息的情况下,使验证者相信某个论断是正确的,它其实是一种密码协议。零知识证明实质上是一种涉及两方或更多方的协议,即两方或更多方完成一项任务所需采取的一系列步骤。证明者向验证者证明并使其相信自己知道或拥有某一消息,但证明过程不能向验证者泄漏任何关于被证明消息的信息。大量事实证明,零知识证明在密码学中非常有用。如果能够将零知识证明用于验证,将可以有效解决许多问题。
MSM(即,Multiple Scalar Multiplication)是目前流行的零知识证明系统中计算多项式承诺的方式,其计算公式为:
其中,P
MSM计算本质上是一系列椭圆曲线上的点的相加,其特点是:计算相对复杂,计算量大,所以成为提高零知识证明系统性能的主要焦点。
请参阅图1,目前MSM的通用算法是pippenger算法,pippenger算法的原理具体为:
步骤1:对每一个scalar进行窗口划分,即在scalar二进制表示下,每几位划分为一个窗口;假设scalar的位数是n位,每c位为一个窗口,则有k=n/c个窗口,每个窗口会对应一个大小为2
步骤2:丢桶;
步骤3:单桶累加;
步骤4:将每个桶的结果再进行运算得到最后结果。
为了更加清楚的说明pippenger算法的原理,下面以一个scalar和一个点P为例,演示上述过程:
假设scalar a=0x12cb=0001001011001011
步骤1:窗口划分,即scalar的位数n=16,令c=8,则k=16/8=2,即有两个窗口,记为:
window_0=0xcb=192
window_1=0x12=18;
为每个窗口准备桶数组,有两个窗口,所以有两个桶数组,每个数组有(2
步骤2:丢桶;即将窗口中的数值作为位置,将P加入到相应桶的对应位置上,记为:
window_0=192->bucket_0[192-1]+=P
window_1=16->bucket_1[18-1]+=P
步骤3:桶累加;即对bucket_0,bucket_1分别做遍历,进行如下累加:
fori=255to i=0:
res<-res+bucket_0[i]
sum<-sum+res
bucket_1也照此累加,记累加结果分别为sum_0,sum_1;
window_0->bucket_0->sum_0
window_1->bucket_1->sum_1
步骤4:通过double和add求取最后结果。
result=sum_1*2
在生成证明时,由于所有参与计算的点P
设每个窗口代表的数值(在桶中的位置)为s
i∈[0..k],s
由pippenger算法的原理可知,丢桶和桶累加的过程一起,本质上就是计算s
这样就可以将pippenger算法中丢桶和桶累加的算法合二为一,可以称为窗口累加。从计算量上来分析,就是减少了pippenger算法原理中桶累加部分的计算量,其余是一致的。
MSM在零知识证明的计算过程中至关重要,MSM计算的快慢关系着整个零知识证明协议是否能够使用,若MSM计算过慢会导致零知识证明协议无法使用,因此,如何提高MSM的计算效率成为了本领域人员亟待解决的问题。
发明内容
为此,本申请提供一种MSM在多GPU下的优化方法及装置,以解决现有技术存在的MSM的计算效率慢的问题。
为了实现上述目的,本申请提供如下技术方案:
第一方面,一种MSM在多GPU下的优化方法,包括:
获取MSM源数据;
将所述MSM源数据划分为若干组,采用查表法优化的pippenger算法,基于多GPU进行并行计算;
其中,对所有可能的S
根据得到的MSM计算结果,生成零知识证明,发送给对方终端。
作为优选,所述对所有可能的S
所述第一公式为:
其中,P
作为优选,所述基于多GPU进行并行计算时,MSM的计算公式为:
其中,a
作为优选,所述窗口c增大为:
其中,c
作为优选,所述MSM的计算效率提升为:
[n/c
第二方面,一种MSM在多GPU下的优化装置,包括:
MSM数据获取模块,用于获取MSM源数据;
并行计算模块,用于将所述MSM源数据划分为若干组,采用查表法优化的pippenger算法,基于多GPU进行并行计算;
其中,对所有可能的S
零知识证明生成模块,用于根据得到的MSM计算结果,生成零知识证明,发送给对方终端。
第三方面,一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现MSM在多GPU下的优化方法的步骤。
第四方面,一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现MSM在多GPU下的优化的步骤。
相比现有技术,本申请至少具有以下有益效果:
本申请公开了一种MSM在多GPU下的优化方法及装置,方法考虑到实际应用场景中,通常会有多张显卡并存的情况,针对在零知识证明中小电路规模可以使用查表法的情况下,通过利用多张显卡与单张显卡的不同进一步扩大算法中窗口大小c,进而提升MSM性能的方法,且通过公式[n/c
附图说明
为了更直观地说明现有技术以及本申请,下面给出几个示例性的附图。应当理解,附图中所示的具体形状、构造,通常不应视为实现本申请时的限定条件;例如,本领域技术人员基于本申请揭示的技术构思和示例性的附图,有能力对某些单元(部件)的增/减/归属划分、具体形状、位置关系、连接方式、尺寸比例关系等容易作出常规的调整或进一步的优化。
图1为现有技术中MSM的通用算法pippenger算法原理示意图;
图2为本申请提供的GPU pippenger算法原理示意图;
图3为本申请实施例一提供的一种MSM在多GPU下的优化方法流程图。
具体实施方式
以下结合附图,通过具体实施例对本申请作进一步详述。
在本申请的描述中:除非另有说明,“多个”的含义是两个或两个以上。本申请中的术语“第一”、“第二”、“第三”等旨在区别指代的对象,而不具有技术内涵方面的特别意义(例如,不应理解为对重要程度或次序等的强调)。“包括”、“包含”、“具有”等表述方式,同时还意味着“不限于”(某些单元、部件、材料、步骤等)。
本申请中所引用的如“上”、“下”、“左”、“右”、“中间”等的用语,通常是为了便于对照附图直观理解,而并非对实际产品中位置关系的绝对限定。在未脱离本申请揭示的技术构思的情况下,这些相对位置关系的改变,当亦视为本申请表述的范畴。
一、pippenger算法在GPU上的实现
请参阅图2,由于GPU拥有众多的计算单元,为了利用GPU的这个特点,于是将数据划分为若干组(group),便于并行计算。
由图2可知,将MSM的通用算法pippenger运用在GPU上(简称:GPU pippenger)与pippenger基本相同,其区别是:
(一)桶的个数增多;桶的个数由原来的每个窗口一个,增加为每个窗口,每个group一个;
(二)桶累加的个数变多;
(三)计算最后结果时,还要将各个group的结果加起来。
二、GPU pippenger算法的计算量分析(所谓计算量的分析,就是MSM所作点加的个数):
设MSM的规模为N,每个scalar的位数为n,窗口大小(每个窗口的位数)为c,窗口个数为k=n/c。
确定group的个数:设GPU的核心数是core_count,取一个常数记为batch_size,则:
group_num=batch_size*core_count/k
=batch_size*core_count*c/n
步骤1:丢桶;
每个窗口一个加法,所以对一个scalar有k次加法,总共N个scalar,所以总的加法个数为:k*N=n/c*N;
步骤2:桶累加;
每个桶一个循环,单次循环2个加法,一共2
(k*group_num)*2*(2
步骤3:求结果;
其计算量为:k*group_num个sum的double和add运算,其计算量是固定的。
三、查表法适用场景分析
由查表法对pippenger算法进行优化的原理可知,查表法是减少了桶累加部分的计算,所以考察如下比例:
由式(3)可知,当r越小,则说明查表法对性能提升就越小,反之则越大。同时可以得到,(batch_size*core_count/n)对于特定的显卡和scalar而言是常数,那么也就是说c越大,查表法的作用越大。但是由于显存的限制,表的大小实际是有上限的,也就是c是有上限的。
当问题规模N很大(比如N=2
基于以上三点分析可得,在小规模电路,运用查表法的情况下的计算量为n/c*N。从中可以看到,c愈大,则计算量愈小,所以,在实践中,总是尽可能提高窗口大小c,以达到减少计算量的目的。但是,由查表法对pippenger算法进行优化的原理中所展示的表可知,c每增加一位(即一个bit),表的规模就扩大一倍,占用显存空间就会扩大一倍,因此,对于单张显卡来说,c是有上限的。同时,考虑到实际应用场景中,通常会有多张显卡并存的情况,所以,本申请提出了在零知识证明中小电路规模的情况下,针对多张显卡进一步扩大c,进而提升MSM性能的方法。
实施例一
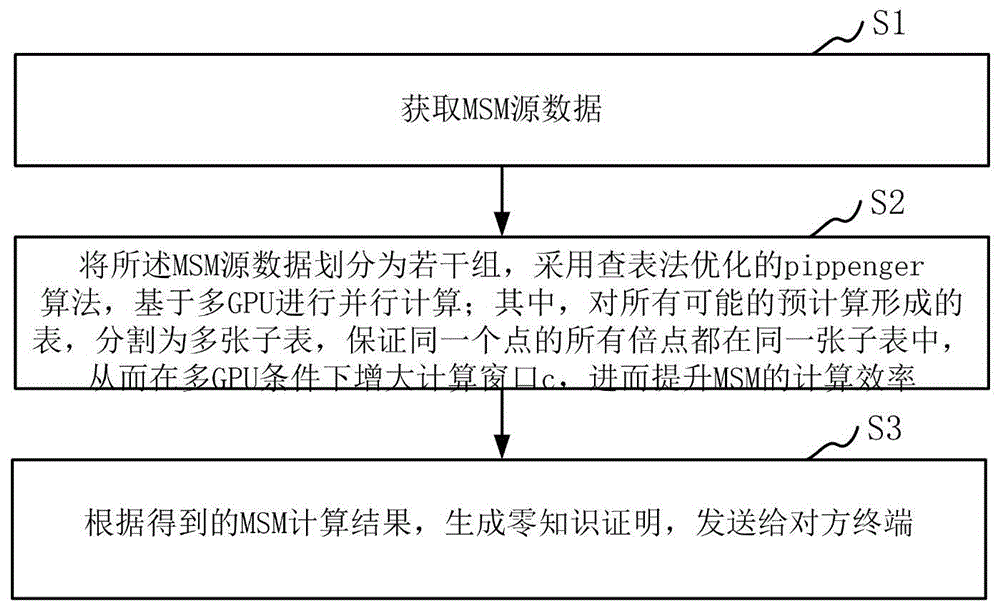
请参阅图3,本实施例提供一种MSM在多GPU下的优化方法,包括:
S1:获取MSM源数据;
S2:将MSM源数据划分为若干组,采用查表法优化的pippenger算法,基于多GPU进行并行计算;
其中,对所有可能的S
S3:根据得到的MSM计算结果,生成零知识证明,发送给对方终端。
具体的,在对所有可能的S
分割后的表用表(4)来表示。
其中,P
具体的,基于多GPU进行并行计算时,MSM的计算公式为:
式(5)是将背景技术中的式(1)进行分割后得到的,其中,a
从表(4)和式(5)中可以看出,每张显卡只存储原表的1/m大小。此时,虽然MSM的计算量几乎没有发生变化(只多了m次加法),但是每张显卡显存确只有原来的1/m,因此为扩大窗口c开辟了空间。
因为表缩小为了原来的1/m,所以窗口c增大为:
其中,c
需要说明的是,当显卡一共有m张时,同时假设在该型号单张显卡上窗口大小c已达到上限,即c
注意式(6)中最后的“约等于”在实践中是可以接受的。这是因为,当c
(2
且由此可知,窗口大小扩展一位,则表的大小就会扩大一倍。所以式(7)相比于在单卡直接扩展一位,占用内存的大小的差为:
这说明,在实际中,式(6)中的“约等于”的是可以取得的。
综上可知,性能提升的衡量标准是对加法个数的减少,所以,MSM的计算效率提升为:
[n/c
综上,本实施例实现了在零知识证明中,小规模电路情况下,多张显卡对MSM性能的提升,并给出了该方法性能提升的具体数值。
本申请通过提供MSM在多GPU下的优化方法,使得基于查表法的MSM计算性能可以随显卡数目线性增长,进一步提高了MSM的计算效率,进而为零知识证明协议在现实场景中的应用和推广打开了广阔空间。
实施例二
本实施例提供了一种MSM在多GPU下的优化装置,包括:
MSM数据获取模块,用于获取MSM源数据;
并行计算模块,用于将所述MSM源数据划分为若干组,采用查表法优化的pippenger算法,基于多GPU进行并行计算;
其中,对所有可能的S
零知识证明生成模块,用于根据得到的MSM计算结果,生成零知识证明,发送给对方终端。
关于一种MSM在多GPU下的优化装置的具体限定可以参见上文中对于一种MSM在多GPU下的优化方法的限定,在此不再赘述。
实施例三
本实施例提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现MSM在多GPU下的优化方法的步骤。
实施例四
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现MSM在多GPU下的优化的步骤。
以上实施例的各技术特征可以进行任意的组合(只要这些技术特征的组合不存在矛盾),为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述;这些未明确写出的实施例,也都应当认为是本说明书记载的范围。
上文中通过一般性说明及具体实施例对本申请作了较为具体和详细的描述。应当理解,基于本申请的技术构思,还可以对这些具体实施例作出若干常规的调整或进一步的创新;但只要未脱离本申请的技术构思,这些常规的调整或进一步的创新得到的技术方案也同样落入本申请的权利要求保护范围。
- 一种CPU与GPU协同执行算法优化的方法和相关装置
- 一种基于AI云的GPU资源调度方法和装置
- 一种GPU虚拟化画面显示的方法及装置
- 一种基于GPU的遥感影像DSM快速提取方法及装置
- 一种基于单GPU卡的图像并发处理方法、装置及系统
- 一种多GPU环境下的数据通信性能优化方法
- 一种多GPU环境下的数据通信性能优化方法