用为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶的糖基转移酶修饰糖蛋白的方法
文献发布时间:2023-06-19 19:28:50
本申请是2016年4月25日提交的申请号为201680036546.X、发明名称为“用为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶的糖基转移酶修饰糖蛋白的方法”的中国发明专利申请的分案申请。
技术领域
本发明涉及酶法修饰糖蛋白的方法。更具体地,本发明涉及使用为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶的糖基转移酶,用糖衍生物核苷酸修饰糖蛋白的方法。本发明还涉及通过所述方法可获得的糖蛋白,涉及可通过将糖蛋白与接头缀合物缀合而获得的生物缀合物,并且涉及可用于制备本发明的糖蛋白的β-(1,4)-N-乙酰半乳糖胺转移酶。
背景技术
糖基转移酶构成参与糖蛋白和糖脂上存在的复合碳水化合物的合成的酶的超家族。糖基转移酶的基本作用是将核苷酸衍生物的糖基部分转移至特定的糖受体。β-1,4-半乳糖基转移酶(β4Gal-T)(EC 2.4.1.38)组成糖基转移酶超家族的亚家族之一,所述亚家族至少包含Gal-T1至Gal-T7七个成员,其催化半乳糖(Gal)从UDP-Gal转移至不同的糖受体。半乳糖转移酶在末端GlcNAc残基上产生的共有基序是乳糖胺序列Galβ4GlcNAc-R(LacNAc或LN),其随后通过添加其他糖和硫酸根基团以多种方式修饰。膜糖缀合物的最常见和最重要的糖结构是聚-N-乙酰乳糖胺(聚-LN),其连接至蛋白(或脂质),在细胞通讯、黏附和信号传导中起重要作用,并且是免疫应答调节中的重要分子。
在脊椎动物和无脊椎动物糖缀合物中存在的另一个共有的末端基序是GalNAcβ4GlcNAc-R(LaCdiNAc或LDN)序列。LDN基序存在于哺乳动物垂体糖蛋白激素中,其中末端GalNAc残基是4-O-硫酸化的,并且作为内皮细胞Man/S4GGnM受体清除的识别标志物发挥作用。然而,非垂体哺乳动物糖蛋白还含有LDN决定簇。此外,LDN和LDN序列的修饰是许多寄生线虫和吸虫中的常见抗原决定簇。LDN的生物合成涉及将GalNAc转移至末端GlcNAc,这是由高度特异性GalNAc转移酶执行的过程。例如由Miller等人在J.Biol.Chem.2008,283,第1985页(通过引用的方式纳入本文)中报道,认为两个密切相关的β1,4-N-乙酰半乳糖胺转移酶——β4GalNAc-T3和β4GalNAc-T4——引起β1,4连接的GalNAc至许多糖蛋白(包括糖蛋白促黄体激素(LH)和碳酸酐酶-6(CA6))上的Asn-连接的寡糖的蛋白特异性的添加。
已经在一系列生物体中鉴定了β-(1,4)-乙酰半乳糖胺转移酶(β-(1,4)-GalNAcT),所述生物体包括人、秀丽隐杆线虫(Caenorhabditis elegans)(Kawar等人,J.Biol.Chem.2002,277,34924,通过引用纳入本文)、黑腹果蝇(Drosophilamelanogaster)(Hoskins等人,Science 2007,316,1625,通过引用的方式纳入本文)和粉纹夜蛾(Trichoplusia ni)(Vadaie等人,J.Biol.Chem.2004,279,33501,通过引用的方式纳入本文)。
最后,除了参与N-糖蛋白修饰的GalT和GalNAcT之外,称为UDP-N-乙酰半乳糖胺:多肽N-乙酰半乳糖胺转移酶(也称为ppGalNAcT)的非相关类别的酶负责粘蛋白型连接(GalNAc-α-1-O-Ser/Thr)的生物合成。这些酶将GalNAc从糖供体UDP-GalNAc转移至丝氨酸和苏氨酸残基,形成O-糖蛋白中典型的α端基异构键。尽管ppGalNAcT催化功能看似简单,但是基于计算机分析估计仅有24种独特的ppGalNAcT人类基因。因为O-连接的糖基化逐步进行,将GalNAc添加到至丝氨酸或苏氨酸中代表粘蛋白生物合成中的第一个关键步骤。尽管这看似简单,但多个ppGalNAcT家族成员对于其蛋白底物的完全糖基化似乎是必需的。
已经表明,半乳糖基转移酶类除了转移天然底物UDP-Gal之外,还能够将一系列非天然半乳糖衍生物转移至受体GlcNAc底物。例如,Elling等人在ChemBioChem 2001,2,884(通过引用的方式纳入本文)中表明,通过在一系列半乳糖基转移酶的作用下从UDP-糖转移6-修饰的半乳糖,可以将含末端GlcNAc的蛋白质生物素化。类似地,Pannecoucke等人在Tetrahedron Lett.2008,49,2294(通过引用的方式纳入本文)中证实,在经受牛β1,4-半乳糖基转移酶之后,6-叠氮基-6-脱氧半乳糖可以(在一定程度上)从对应的UDP-糖转移至小分子GlcNAc底物上。在US2008/0108557(WO 2006/035057,Novo Nordisk A/S)中早先也报道了用于修饰的半乳糖衍生物的糖基转移酶的用途,其中要求在C-6处修饰的广泛范围的半乳糖衍生物(例如硫醇、叠氮化物、O-炔丙基、醛)可以在(牛或人)β1,4-半乳糖基转移酶的作用下,使用2-10当量的UDP-糖转移至GlcNAc底物上。然而,提供的用于支持这样的权利要求的数据仅涉及半乳糖的6-O-炔丙基和6-醛基变体。在C2处具有化学柄的许多GalNAc衍生物也被要求为糖基转移酶的底物,但没有提供实施例。
特别地,如由Ramakrishnan等人J.Biol.Chem.2002,23,20833(通过引用的方式纳入本文)所报道的,牛β4Gal-T1中Tyr-289残基至Leu-289的突变产生了酶的催化口袋,其可以有助于在C2处携带化学柄的UDP-Gal分子,例如2-酮基-Gal。通过包括首先转移非天然半乳糖部分,接着将肟连接到C-2柄上的两步过程,该突变型酶β4GalT(Y289L)已经用于体外检测蛋白上的O-GlcNAc残基或正常和恶性肿瘤组织的细胞表面聚糖上的末端GlcNAc部分的存在。
例如Khidekel等人,J.Am.Chem.Soc.2003,125,16162(通过引用的方式纳入本文)公开了非天然酮官能团到具有β4GalT(Y289L)的O-GlcNAc修饰的蛋白的化学选择性安装。酮部分充当独特标记物以使用肟连接用生物素来“标记”O-GlcNAc糖基化蛋白。一旦被生物素化,可以使用与辣根过氧化物酶(HRP)缀合的链霉亲和素通过化学发光来容易地检测糖缀合物。
例如WO 2007/095506、WO 2008/029281(均为Invitrogen Corporation的)、WO2014/065661(SynAffix B.V.)和Clark等人J.Am.Chem.Soc.2008,130,11576(均通过引用的方式纳入本文)报道了类似的方法,其使用β4GalT(Y289L)和半乳糖胺的叠氮乙酰基变体,取得了类似的成功。
例如US 8697061(Glykos)(通过引用的方式纳入本文)报道了一种类似的方法,其使用β4GalT(Y289L)和2-修饰的糖,获得类似的成功。
最近,突变体β4GalT(Y289L)也以制备方式应用于对抗体的重链聚糖进行位点选择性放射性标记,如Zeglis等人在Bioconj.Chem.2013,24,1057(通过引用的方式纳入本文)中所报道的。特别地,将叠氮化物修饰的N-乙酰半乳糖胺单糖(GalNAz)掺入至抗体的聚糖允许在合适的螯合剂的点击化学引入之后用
Ramakrishnan等人在Biochemistry 2004,43,12513(通过引用的方式纳入本文)中描述了双突变体β4GalT(Y289L、M344H)失去其Mn
Mercer等人,Bioconjugate.Chem.2013,24,144(通过引用的方式纳入本文)描述了在Mg
使用野生型β-(1,4)-N-乙酰半乳糖胺转移酶(在本文也称为β-(1,4)-GalNAcT)来转移C-2修饰的GalNAc的尝试迄今已获得了小小的成功。
Bertozzi等人在ACS Chem.Biol.2009,4,1068(通过引用的方式纳入本文)中将生物正交化学报告技术应用于粘蛋白型O-聚糖在活的秀丽隐杆线虫中的分子成像。将蠕虫用N-乙酰半乳糖胺(GalNAz)的叠氮基-糖变体处理,使得能够体内掺入这种非天然糖。虽然观察到GalNAz代谢性掺入到糖蛋白中,但是对秀丽隐杆线虫溶解产物的软骨素酶ABC和肽N-糖苷酶F(PNGase F)消化,随后使用膦-Flag标签进行的施陶丁格连接(Staudingerligation)以及随后通过使用α-Flag抗体的Western印迹对糖蛋白的探测,表明糖蛋白上的大多数GalNAz残基位于除N-聚糖外的其他类型的聚糖中。此外,没有观察到叠氮化物标记的糖蛋白与N-聚糖特异性凝集素伴刀豆球蛋白A(ConA)的可检测的结合,这与绝大多数标记的聚糖是O-连接的而非N-连接的假说一致。基于这些观察结果,可以得出结论,GalNAz不会在该生物体中代谢性地掺入到N-GlcNAc化蛋白上。
最近,由Burnham-Marusich等人在Plos One 2012,7,e49020(通过引用的方式纳入本文)中得出了类似的结论,其中还观察到在PNGAse处理时缺乏信号减少——表明GalNAz在N-糖蛋白中没有明显掺入。Burnham-Marusich等人描述了使用末端炔烃探针与叠氮基标记的糖蛋白的Cu(I)-催化的叠氮化物-炔烃环化加成反应来检测代谢标记的糖蛋白的研究。结果表明大多数GalNAz标记掺入至对pNGase F不敏感、因此不是N-糖蛋白的聚糖类。
β-(1,4)-GalNAcT对UDP-GalNAc的高底物特异性从对UDP-GlcNAc、UDP-Glc和UDP-Gal的差的识别中变得显而易见,对UDP-GlcNAc、UDP-Glc和UDP-Gal分别仅有0.7%、0.2%和1%的转移酶活性残留,如Kawar等人,J.Biol.Chem.2002,277,34924(通过引用的方式纳入本文)中所报道的。
综上,没有通过非天然GalNAc衍生物(如2-酮基或2-叠氮乙酰基衍生物)的GalNAc转移酶的方式来修饰糖蛋白的体外方法的报道是不足为奇的。
同时,已由Qasba等人,J.Mol.Biol.2007,365,570(通过引用的方式纳入本文)报道,无脊椎动物GalNAcT中的Ile或Leu活性位点残基——对应于人β4Gal-T1同源酶(ortholog enzyme)中的Tyr-289残基——到Tyr残基的置换,通过将N-乙酰半乳糖胺基转移酶活性降低近1000倍,同时将其半乳糖基转移酶活性提高80倍,将酶转化为β(1,4)半乳糖基转移酶。
Taron等人,Carbohydr.Res.2012,362,62(通过引用的方式纳入本文)描述了GalNAz在GPI锚中的体内代谢掺入。
发明内容
本发明涉及一种修饰糖蛋白的方法,所述方法包括以下步骤:在糖基转移酶的存在下,使糖蛋白与糖衍生物核苷酸Su(A)-Nuc接触,所述糖蛋白包含含有末端GlcNAc部分的聚糖,其中:
(i)所述糖基转移酶为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶;
(ii)所述含有末端GlcNAc部分的聚糖如式(1)或(2)所示:
其中:
b为0或1;
d为0或1;
e为0或1;以及
G为单糖、或包含2至20个糖部分的直链或支链寡糖;以及
(iii)所述糖衍生物核苷酸Su(A)-Nuc如式(3)所示:
其中:
a为0或1;
f为0或1;
g为0或1;
Nuc为核苷酸;
U为[C(R
T为C
A选自:
(a)-N
(b)-C(O)R
其中R
(c)(杂)环炔基或-(CH
其中i为0-10且R
(d)-SH
(e)-SC(O)R
其中R
(f)-SC(V)OR
其中V为O或S,R
(g)-X
其中X选自F、Cl、Br和I;
(h)-OS(O)
其中R
(i)R
其中R
(j)R
其中R
(k)N(R
其中R
Z为CH
Y选自O、S、N(R
R
其中:
a、f、T、A和U如上所定义;
h为0或1;以及
W选自O、S、NR
本发明还涉及通过本发明的方法可获得的糖蛋白。
附图说明
在图1中示出了可通过本发明的方法修饰的糖蛋白的几个实例,所述糖蛋白包含含有末端GlcNAc部分的聚糖。
在图2中示出了修饰糖蛋白的方法的实施方案,其中所述糖蛋白是抗体。在该实施方案中,糖衍生物Su(A)-Nuc在糖基转移酶(其中糖基转移酶为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶)的作用下连接到抗体聚糖的末端GlcNAc部分,形成经修饰的抗体。
图3示出了抗体聚糖G0、G1、G2、G0F、G1F和G2F的不同糖型。
图4示出了一种通过用唾液酸酶和半乳糖苷酶处理糖型G0、G1、G2、G0F、G1F和G2F的混合物来提供包含式(10)的聚糖的糖蛋白的方法,以及通过用内切糖苷酶处理糖型G0、G1、G2、G0F、G1F和G2F的混合物来提供包含式(1)的聚糖的糖蛋白的方法。包含式(10)或(1)的聚糖的糖蛋白与叠氮基修饰的UDP-GalNAc衍生物(例如6-叠氮基GalNAc)的孵育分别得到叠氮基修饰的糖蛋白(33)或(32)。
图5示出了在本发明的经修饰的糖蛋白中的代表性的一组官能团(A),其经与反应性基团Q
图6示出了根据式(3)的糖衍生物核苷酸Su(A)-Nuc。
具体实施方式
定义
如本说明书和权利要求书中使用的动词“包含”及其变化形式以其非限制性意义使用,意指包括该词之后的项目,但不排除未具体提及的项目。
另外,通过不定冠词“一(a)”或“一个(an)”提及要素不排除存在多于一个要素的可能性,除非上下文清楚地要求存在一个且仅存在一个该要素。因此,不定冠词“一”或“一个”通常意指“至少一个”。
未取代的烷基具有通式C
芳基包含6至12个碳原子并且可以包括单环结构和双环结构。任选地,芳基可以被本文中进一步详细说明的一个或多个取代基取代。芳基的实例是苯基和萘基。
芳基烷基和烷基芳基包含至少七个碳原子,并且可以包括单环结构和双环结构。任选地,芳基烷基和烷基芳基可以被本文中进一步详细说明的一个或多个取代基取代。芳基烷基为例如苄基。烷基芳基为例如4-叔丁基苯基。
杂芳基包含至少两个碳原子(即至少C
杂芳基烷基和烷基杂芳基包含至少三个碳原子(即至少C
当芳基被表示为(杂)芳基时,该表示意指包括芳基和杂芳基。类似地,烷基(杂)芳基意指包括烷基芳基和烷基杂芳基,并且(杂)芳基烷基意指包括芳基烷基和杂芳基烷基。因此,C
除非另有说明,烷基、烯基、烯烃、炔烃、(杂)芳基、(杂)芳基烷基、烷基(杂)芳基、亚烷基、亚烯基、环亚烷基、(杂)亚芳基、烷基(杂)亚芳基、(杂)芳基亚烷基、烯基、炔基、环烷基、烷氧基、烯氧基、(杂)芳氧基、炔氧基和环烷氧基可以被一个或多个独立地选自以下的取代基取代:C
炔基包含碳-碳三键。包含一个三键的未取代的炔基具有通式C
环炔基是环状炔基。包含一个三键的未取代的环炔基具有通式C
杂环炔基是被选自氧、氮和硫的杂原子间隔的环炔基。任选地,杂环炔基被一个或多个本文中进一步详细说明的取代基取代。杂环炔基的实例是氮杂环辛炔基。
(杂)芳基包括芳基和杂芳基。烷基(杂)芳基包括烷基芳基和烷基杂芳基。(杂)芳基烷基包括芳基烷基和杂芳基烷基。(杂)炔基包括炔基和杂炔基。(杂)环炔基包括环炔基和杂环炔基。
本文中的(杂)环炔化合物定义为包含(杂)环炔基的化合物。
本说明书和权利要求书中公开的几种化合物可以描述为稠合(杂)环炔化合物,即其中第二个环结构是与(杂)环炔基稠合(即成环)的(杂)环炔化合物。例如在稠合(杂)环辛炔化合物中,环烷基(例如环丙基)或芳烃(例如苯)可以与(杂)环辛炔基成环。稠合(杂)环辛炔化合物中的(杂)环辛炔基的三键可以位于三个可能位置的任一个上,即在环辛炔部分的2、3或4位上(根据“IUPAC Nomenclature of Organic Chemistry”,Rule A31.2编号)。本说明书和权利要求书中对任何稠合(杂)环辛炔化合物的描述意指包括环辛炔部分的所有三种单独的区域异构体。
本文中的一般性术语“糖”用于表示单糖,例如葡萄糖(Glc)、半乳糖(Gal)、甘露糖(Man)和岩藻糖(Fuc)。本文中的术语“糖衍生物”用于表示单糖的衍生物,即包含取代基和/或官能团的单糖。糖衍生物的实例包括氨基糖和糖酸,例如葡糖胺(GlcNH
本文中的术语“核苷酸”以其通常的科学含义使用。术语“核苷酸”是指由核碱基、五碳糖(核糖或2-脱氧核糖)和一个、两个或三个磷酸基团组成的分子。没有磷酸基团,核碱基和糖组成核苷。因此,核苷酸也可以称为一磷酸核苷、二磷酸核苷或三磷酸核苷。核碱基可以是腺嘌呤、鸟嘌呤、胞嘧啶、尿嘧啶或胸腺嘧啶。核苷酸的实例包括尿苷二磷酸(UDP)、鸟苷二磷酸(GDP)、胸苷二磷酸(TDP)、胞苷二磷酸(CDP)和胞苷一磷酸(CMP)。
本文中的术语“蛋白”以其通常的科学含义使用。在本文中,包含约10个或更多个氨基酸的多肽被认为是蛋白。蛋白可以包含天然的氨基酸,但也包括非天然的氨基酸。
本文中的术语“糖蛋白”以其通常的科学含义使用,并且是指包含与蛋白共价键合的一个或多个单糖链或寡糖链(“聚糖”)的蛋白。聚糖可以连接到蛋白的羟基上(O-连接的聚糖),例如,连接到丝氨酸、苏氨酸、酪氨酸、羟赖氨酸或羟脯氨酸的羟基上;或连接到蛋白的氮官能团上(N-糖蛋白),例如天冬酰胺或精氨酸;或连接到蛋白的碳上(C-糖蛋白),例如色氨酸。糖蛋白可以包含一个以上的聚糖,可以包含一个或多个单糖和一个或多个寡糖聚糖的组合,并且可以包含N-连接的、O-连接的和C-连接的聚糖的组合。据估计,超过50%的所有蛋白具有某种形式的糖基化,因此被认为是糖蛋白。糖蛋白的实例包括PSMA(前列腺特异性膜抗原)、CAL(南极假丝酵母脂肪酶)、gp41、gp120、EPO(促红细胞生成素)、抗冻蛋白和抗体。
本文中的术语“聚糖”以其通常的科学含义使用,并且是指与蛋白连接的单糖链或寡糖链。因此,术语聚糖是指糖蛋白的碳水化合物部分。聚糖经由一个糖的C-1碳连接至蛋白,所述糖可以不经进一步取代(单糖)或可以在其一个或多个羟基上被进一步取代(寡糖)。天然存在的聚糖通常包含1至约10个糖类部分。然而,当更长的糖链与蛋白连接时,所述糖链在本文中也被认为是聚糖。
糖蛋白的聚糖可以是单糖。通常,糖蛋白的单糖聚糖由与蛋白共价连接的单一的N-乙酰葡糖胺(GlcNAc)、葡萄糖(Glc)、甘露糖(Man)或岩藻糖(Fuc)组成。
聚糖也可以是寡糖。糖蛋白的寡糖链可以是直链或支链的。在寡糖中,直接连接至蛋白的糖称为核心糖。在寡糖中,不直接连接至蛋白并连接至至少两种其他糖的糖称为内部糖。在寡糖中,不直接连接至蛋白而是连接至单个其他糖的糖,即在其一个或多个其他羟基处不具有其他糖取代基的糖,称为末端糖。为了避免疑义,在糖蛋白的寡糖中可以存在多个末端糖,但是仅存在一个核心糖。
聚糖可以是O-连接的聚糖、N-连接的聚糖或C-连接的聚糖。在O-连接的聚糖中,单糖或寡糖聚糖通常经由丝氨酸(Ser)或苏氨酸(Thr)的羟基与蛋白的氨基酸中的O原子键合。在N-连接的聚糖中,单糖或寡糖聚糖经由蛋白的氨基酸中的N-原子,通常经由天冬酰胺(Asn)或精氨酸(Arg)侧链中的酰胺氮与蛋白键合。在C-连接的聚糖中,单糖或寡糖聚糖与蛋白的氨基酸中的C-原子键合,通常与色氨酸(Trp)的C-原子键合。
与蛋白直接连接的寡糖的末端称为聚糖的还原末端。寡糖的另一端称为聚糖的非还原端。
对于O-连接的聚糖,存在多种多样的链。天然存在的O-连接的聚糖的特征通常在于丝氨酸或苏氨酸连接的α-O-GalNAc部分,其进一步用另一个GalNAc、半乳糖、GlcNAc、唾液酸和/或岩藻糖取代。具有聚糖取代的羟基化氨基酸可以是蛋白中任何氨基酸序列的一部分。
对于N-连接的聚糖,存在多种多样的链。天然存在的N-连接的聚糖的特征通常在于天冬酰胺连接的β-N-GlcNAc部分,进而在其4-OH处用β-GlcNAc进一步取代,进而在其4-OH处用β-Man进一步取代,进而在其3-OH和6-OH处用α-Man进一步取代,得到聚糖戊多糖Man
本文中的术语“抗体”以其通常的科学含义使用。抗体是由免疫系统产生的能够识别和结合至特定抗原的蛋白。抗体是糖蛋白的一个实例。本文中的术语抗体以其最广泛的含义使用,并具体包括单克隆抗体、多克隆抗体、二聚体、多聚体、多特异性抗体(例如双特异性抗体)、抗体片段以及双链抗体和单链抗体。本文中的术语“抗体”还意指包括人抗体、人源化抗体、嵌合抗体和特异性结合癌抗原的抗体。术语“抗体”意指包括全抗体,但也包括抗体的片段,例如抗体Fab片段、F(ab’)
同一性/相似性
在本发明的上下文中,蛋白或蛋白片段由氨基酸序列表示。
应理解,如本文中通过给定的序列身份号(SEQ ID NO)所确定的每个蛋白或蛋白片段或肽或衍生肽或多肽不限于所公开的这种特定序列。本文中的“序列同一性”定义为通过比较序列确定的两个或更多个氨基酸(多肽或蛋白)序列之间的关系。在本领域中,“同一性”还意指根据情况可通过这种序列的字符串之间的匹配确定的氨基酸序列之间的序列相似性程度。除非本文另有说明,与给定SEQ ID NO的同一性或相似性意指基于所述序列的全长(即在其整个长度上或作为整体)的同一性或相似性。
本发明包含的与由其SEQ ID NO所定义的具体指定序列具有小于100%序列同一性的任何酶优选具有为与由SEQ ID NO所定义的所述序列具有100%同一性的酶的酶活性的至少10%、20%、30%、40%、50%、60%、70%或优选至少80%或90%或至少100%的酶活性。
两个氨基酸序列之间的“相似性”通过将一个多肽的氨基酸序列和其保守氨基酸取代物与第二多肽的序列进行比较来确定。“同一性”和“相似性”可以通过已知方法容易地计算,包括但不限于在以下中描述的那些:Computational Molecular Biology,Lesk,A.M.编辑,牛津大学出版社,纽约,1988;Biocomputing:Informatics and Genome Projects,Smith,D.W.编辑,Academic Press,纽约,1993;Computer Analysis of Sequence Data,Part I,Griffin,A.M.,和Griffin,H.G.编辑,胡玛纳出版社,新泽西州,1994;SequenceAnalysis in Molecular Biology,von Heine,G.,Academic Press,1987;以及SequenceAnalysis Primer,Gribskov,M.和Devereux,J.,eds.,M Stockton Press,纽约,1991以及Carillo,H.,和Lipman,D.,SIAM J.Applied Math.,48:1073(1988)。
设计确定同一性的优选方法以在测试的两个或更多个序列之间给出最大匹配。确定同一性和相似性的方法编码在可公开获得的计算机程序中。确定两个序列之间的同一性和相似性的优选计算机程序方法包括例如GCG程序包(Devereux,J.等人,Nucleic AcidsResearch 12(1):387(1984))、BestFit、BLASTP、BLASTN和FASTA(Altschul,S.F.等人,J.Mol.Biol.215:403-410(1990))。BLAST X程序可公开获自NCBI和其他来源(BLASTManual,Altschul,S.,等人,NCBI NLM NIH Bethesda,MD20894;Altschul,S.等人,J.Mol.Biol.215:403-410(1990))。众所周知的Smith Waterman算法也可用于确定同一性。
用于多肽序列比较的优选参数包括如下内容:算法:Needleman和Wunsch,J.Mol.Biol.48:443-453(1970);比较矩阵:来自Hentikoff和Hentikoff的BLOSSUM62,Proc.Natl.Acad.Sci.USA.89:10915-10919(1992);缺口罚分:12;以及缺口长度罚分:4。具有这些参数的有用的程序作为“Ogap”程序公开获自位于Madison,WI的Genetics ComputerGroup。上述参数是用于氨基酸比较的默认参数(以及对于末端缺口没有罚分)。
任选地,在确定氨基酸相似性程度时,技术人员还可以考虑所谓的“保守”氨基酸置换,这对技术人员将是清楚的。保守氨基酸置换是指具有相似侧链的残基的可互换性。例如,具有脂肪族侧链的氨基酸组是甘氨酸、丙氨酸、缬氨酸、亮氨酸和异亮氨酸;具有脂肪族-羟基侧链的氨基酸组是丝氨酸和苏氨酸;具有含酰胺侧链的氨基酸组是天冬酰胺和谷氨酰胺;具有芳族侧链的氨基酸组是苯丙氨酸、酪氨酸和色氨酸;具有碱性侧链的氨基酸组是赖氨酸、精氨酸和组氨酸;具有含硫侧链的氨基酸组是半胱氨酸和甲硫氨酸。优选的保守氨基酸置换基是:缬氨酸-亮氨酸-异亮氨酸、苯丙氨酸-酪氨酸、赖氨酸-精氨酸、丙氨酸-缬氨酸和天冬酰胺-谷氨酰胺。本文公开的氨基酸序列的置换变体是其中已经除去所公开序列中的至少一个残基并且在其位置插入不同残基的那些。优选地,氨基酸改变是保守的。每个天然存在的氨基酸的优选保守置换如下:Ala至Ser;Arg至Lys;Asn至Gln或His;Asp至Glu;Cys至Ser或Ala;Gln至Asn;Glu至Asp;Gly至Pro;His至Asn或Gln;Ile至Leu或Val;Leu至Ile或Val;Lys至Arg;Gln或Glu;Met至Leu或Ile;Phe至Met、Leu或Tyr;Ser至Thr;Thr至Ser;Trp至Tyr或His;Tyr至Trp或Phe;以及Val至Ile或Leu。
用于修饰糖蛋白的方法
本发明涉及用于在糖基转移酶的作用下修饰糖蛋白以获得经修饰的糖蛋白的方法,其中所述糖基转移酶为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶。优选地,所述方法是体外方法。
具体地,本发明涉及用于修饰糖蛋白的方法,所述方法包括以下步骤:在糖基转移酶的存在下,将糖蛋白与糖衍生物核苷酸Su(A)-Nuc接触,所述糖蛋白包含含有末端GlcNAc部分的聚糖,其中:
(i)所述糖基转移酶为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶;
(ii)所述含有末端GlcNAc部分的聚糖如式(1)或(2)所示:
其中:
b为0或1;
d为0或1;
e为0或1;以及
G为单糖,或包含2至20个糖部分的直链或支链寡糖;以及
(iii)所述糖衍生物核苷酸Su(A)-Nuc如式(3)所示:
其中:
a为0或1;
f为0或1;g为0或1;
Nuc为核苷酸;
U为[C(R
T为C
A选自:
(a)-N
(b)-C(O)R
其中R
(c)(杂)环炔基或-(CH
其中i为0-10且R
(d)-SH
(e)-SC(O)R
其中R
(f)-SC(V)OR
其中V为O或S,R
(g)-X
其中X选自F、Cl、Br和I;
(h)-OS(O)
其中R
(i)R
其中R
(j)R
其中R
(k)N(R
其中R
Z为CH
Y选自O、S、N(R
R
其中:
a、f、T、A和U如上所定义;
h为0或1;以及
W选自O、S、NR
在一个实施方案中,如式(3)所示的Su(A)-Nuc中的A选自如上所定义的选项(a)至(j)。在另一个实施方案中,如式(3)所示的Su(A)-Nuc中的A选自如上定义的选项(a)至(d)和(g)至(k),更优选选自(a)至(d)和(g)至(j)。
如上所述,本发明用于修饰糖蛋白的方法提供了经修饰的糖蛋白。在本文中,经修饰的糖蛋白定义为包含式(4)或(5)的聚糖的糖蛋白:
/>
其中:
b、d、e和G如上所定义;以及
Su(A)是式(6)的糖衍生物:
其中:
R
在式(4)和(5)的经修饰的糖蛋白聚糖中,糖衍生物Su(A)的C1经由β-1,4-O-糖苷键连接至GlcNAc部分的C4。
用于修饰糖蛋白的方法可以进一步包括以下步骤:提供包含含有末端GlcNAc部分的聚糖的糖蛋白。因此,本发明还涉及用于修饰糖蛋白的方法,其包括以下步骤:
(1)提供包含含有末端GlcNAc部分的聚糖的糖蛋白,其中含有末端GlcNAc部分的聚糖如上文定义的式(1)或(2)所示;以及
(2)在糖基转移酶的存在下、更特别是在糖基转移酶的作用下,将所述糖蛋白与糖衍生物核苷酸Su(A)-Nuc接触,其中所述糖基转移酶为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶,并且其中Su(A)-Nuc如上文定义的式(3)所示。
下文更详细地描述了包含含有末端GlcNAc部分的聚糖的糖蛋白、糖衍生物核苷酸Su(A)-Nuc和经修饰的糖蛋白,及其优选的实施方案。
下文更详细地描述了为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶的糖基转移酶。
在本发明的方法的优选实施方案中,β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自SEQ ID NO:2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、25、26、27、28、29、30、31、32、33、34、46、47、49、50、51、52、53、54、55、56、57、58、59、71、72和73的序列。当R
在本发明的方法的另一个优选实施方案中,β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自SEQ ID NO:35、36、37、38、39、40、41、42、43、44、45、48、60、61、62、63、64、65、66、67、68、69、70和74。当R
在本发明的方法的另一个优选实施方案中,β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、25、26、27、28、29、30、31、32、33、34、46、47、49、50、51、52、53、54、55、56、57、58、59、71、72和73的序列具有至少50%的同一性。在该实施方案中进一步优选β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、25、26、27、28、29、30、31、32、33、34、46、47、49、50、51、52、53、54、55、56、57、58、59、71、72和73的序列具有至少55%的序列同一性,优选至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。当R
在本发明的方法的另一个优选实施方案中,β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:35、36、37、38、39、40、41、42、43、44、45、48、60、61、62、63、64、65、66、67、68、69、70和74的序列具有至少50%的同一性。在该实施方案中进一步优选β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:35、36、37、38、39、40、41、42、43、44、45、48、60、61、62、63、64、65、66、67、68、69、70和74的序列具有至少55%的序列同一性,优选至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。当R
糖蛋白
在本发明的方法中待修饰的糖蛋白包含聚糖,所述聚糖含有末端GlcNAc部分,即存在于聚糖的非还原端的GlcNAc部分。所述聚糖包含一个或多个糖部分,并且可以是直链的或支链的。含有末端GlcNAc部分的聚糖如式(1)或(2)所示:
其中:
b为0或1;
d为0或1;
e为0或1;以及
G为单糖,或包含2至20个糖部分的直链或支链寡糖。
所述待修饰的糖蛋白可包含多于一个含有末端GlcNAc部分的聚糖。当是这种情况时,两种或更多种聚糖可互不相同。所述糖蛋白还可以包含一种或多种不含有末端GlcNAc部分的其他聚糖。
核心GlcNAc部分(即连接至蛋白的GlcNAc部分)任选地被岩藻糖基化(b为0或1)。当核心GlcNAc部分被岩藻糖基化时,岩藻糖最通常地将α-1,6连接至所述GlcNAc部分的C6。
应注意,式(1)中b为1的聚糖的GlcNAc部分,即由岩藻糖基化的GlcNAc组成的聚糖中的GlcNAc部分,在本文中也被认为是末端GlcNAc部分。
在一个实施方案中,含有末端GlcNAc部分的聚糖由一个GlcNAc部分组成,并且所述聚糖是式(1)中b为0的聚糖。在另一个实施方案中,所述聚糖由岩藻糖基化的GlcNAc部分组成,并且所述聚糖是式(1)中b为1的聚糖。
在另一个实施方案中,所述聚糖是式(2)的聚糖,其中核心GlcNAc(如果存在)被任选地岩藻糖基化(b为0或1)。在式(2)的聚糖中,G表示单糖或包含1至20个,优选1至12个,更优选1至10个,甚至更优选1、2、3、4、5、6、7或8个,最优选1、2、3、4、5或6个糖部分的直链或支链寡糖。当G是支链寡糖时,G可以包含一个或多个末端GlcNAc部分。因此,式(2)的聚糖可包含一个以上的末端GlcNAc部分。在聚糖(2)中,优选当d为0时,e为1,以及当e为0时,d为1。更优选地,在聚糖(2)中d为1,甚至更优选d为1且e为1。
可存在于聚糖中的糖部分是本领域技术人员已知的,包括例如葡萄糖(Glc)、半乳糖(Gal)、甘露糖(Man)、岩藻糖(Fuc)、N-乙酰葡萄糖胺(GlcNAc)、N-乙酰半乳糖胺(GalNAc)、N-乙酰神经氨酸(NeuNAc)或唾液酸以及木糖(Xyl)。
在本发明的方法的一个优选的实施方案中,含有末端GlcNAc部分的聚糖如式(1)所示,如上所定义。在另一个优选的实施方案中,含有末端GlcNAc部分的聚糖如式(2)所示。进一步优选聚糖是N-连接的聚糖。当聚糖是如式(2)所示的N-连接的聚糖时,优选d为1。
当含有末端GlcNAc部分的聚糖如式(2)所示时,进一步优选如式(2)所示的聚糖是如式(9)、(10)、(11)、(12)、(13)或(14)所示的聚糖:
/>
其中b为0或1。
在本发明的方法的一个优选的实施方案中,含有末端GlcNAc部分的聚糖是如式(1)、(9)、(10)、(11)、(12)、(13)或(14)所示的聚糖,更优选如式(1)、(9)、(10)、(11)、(12)、(13)或(14)所示的N-连接的聚糖。在其他优选的实施方案中,含有末端GlcNAc部分的聚糖是如式(1)、(9)、(10)或(11)所示的聚糖,更优选如式(1)、(9)、(10)或(11)所示的N-连接的聚糖。最优选地,含有末端GlcNAc部分的聚糖是如式(1)或(10)所示的聚糖,更优选如式(1)所示的N-连接的聚糖。
包含含有末端GlcNAc部分的聚糖的糖蛋白优选如式(7)、(8)或(8b)所示:
其中:
b、d、e和G及其优选的实施方案如上所定义;
y独立地为1至24的整数;以及
Pr为蛋白。
在本发明的方法中待修饰的糖蛋白包含一个或多个含有末端GlcNAc部分的聚糖(y为1至24)。优选地,y是1至12的整数,更优选地是1至10的整数。更优选地,y是1、2、3、4、5、6、7或8,还更优选地,y是1、2、3、4、5或6。甚至更优选地,y是1、2、3或4。当所述待修饰的糖蛋白包含多于一个聚糖时(y为2或更多),所述聚糖可互不相同。如上文所述,糖蛋白还可以包含一个或多个不具有末端GlcNAc部分的聚糖。
当本发明的方法中待修饰的糖蛋白如式(7)、(8)或(8b)所示时,还优选含有末端GlcNAc部分的聚糖是如式(1)、(9)、(10)、(11)、(12)、(13)或(14)所示的聚糖,优选N-连接的聚糖,如上文所述,更优选如式(1)、(9)、(10)或(11)所示且甚至更优选如式(1)或(10)所示的聚糖,优选N-连接的聚糖。最优选地,含有末端GlcNAc部分的聚糖是如式(1)所示的N-连接的聚糖。
在本发明的方法的一个优选的实施方案中,包含含有末端GlcNAc部分的聚糖的糖蛋白是抗体,更优选如式(7)、(8)或(8b)所示的抗体,其中蛋白(Pr)是抗体(Ab)。并且,当待修饰的糖蛋白是抗体且所述抗体包含多于一个聚糖(y为2或更多)时,所述聚糖可互不相同。抗体还可以包含一个或多个不含有末端GlcNAc部分的聚糖。并且,当待修饰的糖蛋白是抗体时,优选含有末端GlcNAc部分的聚糖是如式(1)、(9)、(10)、(11)、(12)、(13)或(14)所示,更优选如式(1)、(9)、(10)或(11)所示,甚至更优选如式(1)或(10)所示的聚糖,如上文所述。在该实施方案中,进一步优选含有末端GlcNAc部分的聚糖是如式(1)、(9)、(10)、(11)、(12)、(13)或(14)所示的N-连接的聚糖,更优选如式(1)、(9)、(10)或(11)所示的N-连接的聚糖,最优选如式(1)或(10)所示的N-连接的聚糖。
当待修饰的糖蛋白是抗体时,优选y为1、2、3、4、5、6、7或8,更优选y为1、2、4、6或8,甚至更优选y是1、2或4,最优选y是1或2。
如上所定义,所述抗体可以是全抗体,但也可以是抗体片段。当抗体是全抗体时,所述抗体优选在每条重链上包含一个或多个,更优选一个末端非还原性GlcNAc聚糖。因此,所述全抗体优选包含2种或更多种,优选2种、4种、6种或8种所述聚糖,更优选2种或4种,最优选2种聚糖。换言之,当所述抗体是全抗体时,y优选为2、4、6或8,更优选y为2或4,最优选y为2。当所述抗体是抗体片段时,优选y为1、2、3或4,更优选y为1或2。
在一个优选的实施方案中,所述抗体是单克隆抗体(mAb)。优选地,所述抗体选自IgA、IgD、IgE、IgG和IgM抗体。更优选地,所述抗体是IgG1、IgG2、IgG3或IgG4抗体,最优选地,所述抗体是IgG1抗体。
在本发明的方法中,包含岩藻糖基化以及非岩藻糖基化的聚糖的糖蛋白混合物可以用作起始糖蛋白。所述混合物例如可以包含含有一个或多个岩藻糖基化的(b为1)聚糖(1)和/或(2)和/或一个或多个非岩藻糖基化的(b为0)聚糖(1)和/或(2)的糖蛋白。因此,在本发明的方法之前从岩藻糖基化的聚糖中除去岩藻糖不是必需的,而是任选的。
包含含有末端GlcNAc部分的聚糖的糖蛋白在本文中也称为“末端非还原性GlcNAc蛋白”,含有末端GlcNAc部分的聚糖在本文中也称为“末端非还原性GlcNAc聚糖”。应注意,术语“末端非还原性GlcNAc蛋白”包括其中b为1的式(7)的蛋白,术语“末端非还原性GlcNAc聚糖”包括其中b为1的式(1)的聚糖。
末端非还原性GlcNAc蛋白可以包含一个或多个直链和/或一个或多个支链的末端非还原性GlcNAc聚糖。聚糖经由聚糖核心糖部分的C1键合至蛋白,并且所述核心糖部分优选是核心GlcNAc部分。因此,当键合至蛋白的末端非还原性GlcNAc聚糖是如式(2)所示的聚糖时,优选d是1。更优选地,当聚糖如式(2)所示时,d为1且e为1。
在优选的实施方案中,末端非还原性GlcNAc聚糖的核心糖部分的C1经由N-糖苷键键合至蛋白,所述N-糖苷键键合至所述蛋白中的氨基酸残基中的氮原子,更优选键合至天冬酰胺(Asn)或精氨酸(Arg)氨基酸的侧链中的氮原子。然而,非还原性GlcNAc聚糖的核心糖部分的C1也可以经由O-糖苷键键合至蛋白,所述O-糖苷键键合至所述蛋白中的氨基酸残基中的氧原子,更优选键合至丝氨酸(Ser)或苏氨酸(Thr)氨基酸的侧链中的氧原子。在该实施方案中,优选所述聚糖的核心糖部分是GlcNAc部分或GalNAc部分,优选GlcNAc部分。非还原性GlcNAc聚糖的核心糖部分的C1也可以经由C-糖苷键键合至蛋白,所述C-糖苷键键合至蛋白上的碳原子,例如键合至色氨酸(Trp)。如上文所述,糖蛋白可以包含多于一个聚糖,并且可以包含N-连接的、O-连接的和/或C-连接的聚糖的组合。
末端非还原性GlcNAc聚糖可以存在于蛋白的天然糖基化位点,但也可以被引入蛋白的不同位点上。
当糖蛋白是抗体时,优选包含末端GlcNAc部分的聚糖连接至Fc片段中的区域290-305中的天冬酰胺处(通常在N297处)的保守N-糖基化位点。
可在本发明的方法中被修饰的末端非还原性GlcNAc蛋白的几个实例示于图1中。图1(A)示出了包含单个、任选地岩藻糖基化的GlcNAc部分的糖蛋白。该GlcNAc聚糖可以例如经由N-糖苷键或O-糖苷键连接至蛋白。图1(A)中的糖蛋白可以例如通过常规表达,然后用内切糖苷酶或内切糖苷酶的组合修剪(trimming)而获得。图1(B)示出了包含支链寡糖聚糖的糖蛋白,其中支链之一含有末端GlcNAc部分(该聚糖也称为GnM
在图2中示出了用于修饰糖蛋白的方法的实施方案,其中糖蛋白是抗体。在该实施方案中,在为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶的糖基转移酶的作用下,将糖衍生物Su(A)从Su(A)-Nuc转移至抗体聚糖的末端GlcNAc部分,以形成经修饰的抗体。
如上文所述,本发明的用于修饰糖蛋白的方法还可以包括以下步骤:提供包含含有末端GlcNAc部分的聚糖的糖蛋白,因此本发明还涉及用于修饰糖蛋白的方法,其包括以下步骤:
(1)提供包含含有末端GlcNAc部分的聚糖的糖蛋白,其中含有末端GlcNAc部分的聚糖如式(1)或(2)所示,如上文所定义;以及
(2)在糖基转移酶的存在下、更特别是在糖基转移酶的作用下,使所述糖蛋白与糖衍生物核苷酸Su(A)-Nuc接触,其中所述糖基转移酶为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶,其中Su(A)-Nuc如式(3)所示,如上所定义。
当例如在本发明的方法中待修饰的糖蛋白包含式(1)的聚糖时,在方法的步骤(1)中,待修饰的糖蛋白可以通过包括以下步骤的方法来提供:在合适的酶,优选内切糖苷酶的作用下修剪包含寡糖聚糖的糖蛋白。
在大量的聚糖中,第二GlcNAc残基与直接键合至糖蛋白的GlcNAc残基键合,也如图1(B)和(C)所示。可以修剪其中第二GlcNAc残基与直接键合至糖蛋白的GlcNAc残基键合的聚糖,以获得包含式(1)的聚糖的糖蛋白。修剪发生在所述两个GlcNAc残基之间。
“合适的酶”定义为待修剪的聚糖是其底物的酶。在本发明的方法的该具体实施方案的步骤(1)中待使用的酶的优选类型取决于被修剪的特定的聚糖。在本发明的方法的该具体实施方案的一个优选实施方案中,所述方法的该具体实施方案的步骤(1)中的酶选自内切糖苷酶。
内切糖苷酶能够切割聚糖结构中的内部糖苷键,这为重构和合成工作提供了益处。例如,当内切糖苷酶在保守的聚糖区域内的可预测位点切割时,可以用于使异源聚糖群体容易均化。在这方面,最重要的一类糖苷内切酶包括内-β-N-乙酰葡糖苷酶(EC3.2.1.96,通常称为Endo和ENGase),一类通过水解N,N’-二乙酰基壳二糖核心中的β-1,4-糖苷键从糖蛋白中除去N-聚糖的水解酶(Wong等人Chem.Rev.2011,111,4259的综述,通过引用的方式纳入本文),留下单核心N-连接的GlcNAc残基。发现内-β-N-乙酰葡糖苷酶以普通的化学酶变体广泛分布于自然界,所述化学酶变体包括对寡甘露糖特异的Endo D;对高甘露糖特异的Endo A和Endo H;范围从高甘露糖到双触角复合物的Endo F亚型;可以切割除藻糖基化聚糖以外的大多数N-聚糖结构(高甘露糖/复合型/杂合型),并且对高甘露糖型寡糖的水解活性显著高于对复合型和杂合型寡糖的水解活性的Endo M。这些ENGase对远端N-聚糖结构而不是显示其的蛋白表现出特异性,使得它们可用于在天然条件下从糖蛋白切割大多数N-连接的聚糖。
内切糖苷酶F1、F2和F3最适合天然蛋白的去糖基化。endo F1、F2和F3的连接特异性表明可除去所有类别的N-连接的寡糖而不使蛋白变性的蛋白去糖基化的一般策略。双触角和三触角结构可以分别通过内切糖苷酶F2和F3立即除去。低聚甘露糖和杂合结构可以通过Endo F1除去。
Endo F3的独特之处在于其裂解对寡糖的肽键的状态以及核心岩藻糖基化的状态敏感。内切糖苷酶F3切割天冬酰胺连接的双触角和三触角复合寡糖。它将以缓慢的速率切割非岩藻糖基化的双触角和三触角结构,但仅当肽连接时。核心岩藻糖基化的双触角结构是Endo F3的有效底物,其活性最高达高400倍。对寡甘露糖和杂合分子没有活性。参见例如Tarentino等人Glycobiology 1995,5,599,通过引用的方式纳入本文。
Endo S是来自酿脓链球菌(Streptococcus pyogenes)的分泌的糖苷内切酶,并且也属于糖苷水解酶家族18,如由Collin等人(EMBO J.2001,20,3046,通过引用的方式纳入本文)所公开的。与上述ENGase相比,Endo S具有更明确的特异性,并且仅特异性用于切割人IgG的Fc结构域中的保守N-聚糖(迄今为止尚未鉴定到其他底物),这表明酶和IgG之间的蛋白-蛋白相互作用提供了这种特异性。
Endo S49,也称为Endo S2,记载于WO 2013/037824(Genovis AB)中,其通过引用的方式纳入本文。Endo S49分离自酿脓链球菌NZ131,并且是Endo S的同源物。Endo S49对天然IgG具有特异性内切糖苷酶活性,并且比Endo S切割更多种类的Fc聚糖。
在一个优选的实施方案中,本实施方案步骤(1)中的酶是内-β-N-乙酰葡糖苷酶。在其他优选的实施方案中,内-β-N-乙酰葡糖苷酶选自Endo S、Endo S49、Endo F1、EndoF2、Endo F3、Endo H、Endo M和Endo A或其组合。
当待修剪的聚糖是复合型的双触角结构时,内-β-N-乙酰葡糖苷酶优选选自EndoS、Endo S49、Endo F1、Endo F2和Endo F3或其组合。
当糖蛋白是抗体并且待修剪的寡糖是复合型的双触角结构(即如图1(C)所示),并且其存在于N297处的IgG保守的N-糖基化位点时,内-β-N-乙酰葡糖苷酶优选选自Endo S、Endo S49、Endo F1、Endo F2和Endo F3或其组合,更优选选自Endo S和Endo S49或其组合。
当糖蛋白是抗体并且待修剪的聚糖是复合型的双触角结构,并且其不存在于N297处的IgG保守的N-糖基化位点时,内-β-N-乙酰葡糖苷酶优选选自Endo F1、Endo F2和EndoF3或其组合。
当待修剪的聚糖为高甘露糖时,内-β-N-乙酰葡糖苷酶优选选自Endo H、Endo M、Endo A和Endo F1。
因此,当在本发明的方法中待修饰的糖蛋白包含式(1)的聚糖时,在所述方法的步骤(1)中,优选通过包括以下步骤的方法提供待修饰的糖蛋白:通过内-β-N-乙酰葡糖苷酶的作用修剪包含寡糖聚糖的糖蛋白的聚糖,以提供包含式(1)的聚糖的糖蛋白。
在其他优选的实施方案中,内-β-N-乙酰葡糖苷酶选自Endo S、Endo S49、EndoF1、Endo F2、Endo F3、Endo H、Endo M和Endo A及其任意组合。更优选地,内-β-N-乙酰葡糖苷酶选自Endo S、Endo S49、Endo H、Endo F1、Endo F2和Endo F3及其任意组合。甚至更优选地,内-β-N-乙酰葡糖苷酶为Endo S或Endo S49。最优选地,内-β-N-乙酰葡糖苷酶是EndoH或Endo S的组合。
通过用内切糖苷酶处理糖型G0、G1、G2、G0F、G1F和G2F的混合物来提供包含式(1)的聚糖的糖蛋白的方法示于图4中。图4示出了用内切糖苷酶处理包含糖型G0、G1、G2、G0F、G1F和G2F(所述糖型示于图3中)的混合物的糖蛋白(在这种情况下为抗体),然后使用β-(1,4)-GalNAcT酶从UDP-GalNAz转移例如N-叠氮基乙酰半乳糖胺(GalNAz),产生式(32)的经修饰的抗体。
当例如在本发明的方法中待修饰的糖蛋白包含式(9)的聚糖时,可以以多种方式提供包含所述聚糖的糖蛋白(也称为“GnM5”)。在该实施方案中,优选糖蛋白通过在苦马豆素存在下杂合的N-糖蛋白的表达来提供,例如在Kanda等人,Glycobiology 2006,17,104中所述的(通过引用的方式纳入本文),并且如果必要的话随后进行唾液酸酶/半乳糖苷酶处理。替代方法包括对宿主生物体的基因工程。例如,LeC1CHO是缺乏表达Mns-II的基因的敲除CHO细胞系。因此,N-聚糖的生物合成不可避免地停止在聚糖(可从上清液中分离纯化)的GnM
因此,当在本发明的方法中待修饰的糖蛋白包含式(9)的聚糖时,在所述方法的步骤(1)中,包含式(9)的任选岩藻糖基化的聚糖的糖蛋白优选通过包括在苦马豆素存在下在宿主生物体中表达糖蛋白的方法来提供。优选地,所述宿主生物体是哺乳动物细胞系,例如HEK293或NS0或CHO细胞系。所得糖蛋白可作为包含以下聚糖的蛋白的混合物而获得:式(9)的聚糖(也称为GnM
(1a)在苦马豆素存在下,在宿主生物体中表达糖蛋白;以及
(1b)用唾液酸酶和/或β-半乳糖苷酶处理所获得的糖蛋白,以获得包含式(9)的聚糖的糖蛋白。
当在本发明的方法中待修饰的糖蛋白包含式(10)的聚糖时,在所述方法的步骤(1)中,待修饰的糖蛋白可以例如通过包括以下步骤的方法提供:用唾液酸酶和半乳糖苷酶处理糖蛋白的糖型G0、G1、G2、G0F、G1F和G2F的混合物。在图3中,示出了包含双触角聚糖的抗体的糖型G0、G1、G2、G0F、G1F和G2F。
图4示出了提供包含式(10)的聚糖的糖蛋白(在这种情况下为抗体)的方法:用唾液酸酶和半乳糖苷酶处理糖型G0、G1、G2、G0F、G1F和G2F的混合物,然后在为β-(1,4)-GalNAcT或衍生自β-(1,4)-GalNAcT的糖基转移酶的作用下从糖衍生物核苷酸Su(A)-UDP(其中A是叠氮基,例如6-叠氮基-GalNAc-UDP)转移糖部分,得到式(33)的经修饰的抗体。
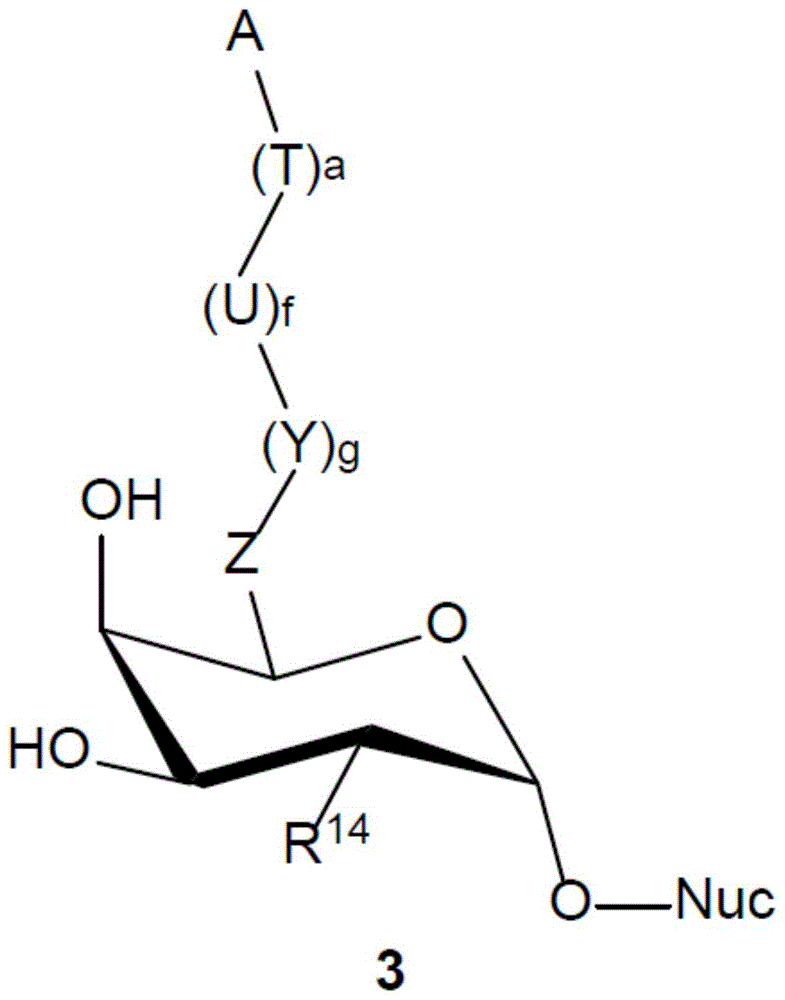
糖衍生物核苷酸Su(A)-Nuc
在本发明的修饰糖蛋白的方法中,包含式(1)或(2)的聚糖的糖蛋白在为β-(1,4)-GalNAcT或衍生自β-(1,4)-GalNAcT的糖基转移酶的作用下与糖衍生物核苷酸Su(A)-Nuc接触。糖衍生物核苷酸Su(A)-Nuc如式(3)所示:
其中Nuc、R
Nuc在本文中定义为核苷酸。Nuc优选选自核苷一磷酸和核苷二磷酸,更优选选自尿苷二磷酸(UDP)、鸟苷二磷酸(GDP)、胸苷二磷酸(TDP)、胞苷二磷酸(CDP)和胞苷一磷酸(CMP),更优选选自尿苷二磷酸(UDP)、鸟苷二磷酸(GDP)和胞苷二磷酸(CDP)。最优选地,Nuc为尿苷二磷酸(UDP)。因此,在本发明的方法的一个优选的实施方案中,Su(A)-Nuc(3)是Su(A)-UDP(34):
其中R
在一个实施方案中,A是叠氮基-N
在另一个实施方案中,A是酮基-C(O)R
在另一个实施方案中,A是炔基。换言之,A是包含C≡C键的官能部分,优选(杂)环炔基或-(CH
在另一个实施方案中,A是巯基-SH。
在另一个实施方案中,A是巯基-SC(O)R
在另一个实施方案中,A是-SC(V)OR
在另一个实施方案中,A是卤素X。X选自F、Cl、Br和I,优选选自Cl、Br和I,更优选选自Cl和Br。最优选地,X是Cl。
在另一个实施方案中,A是磺酰氧基-OS(O)
在另一个实施方案中,A是R
术语“末端烯基”在本文中是指其中碳-碳双键位于烯基的末端的烯基。当R
当R
当R
在另一个实施方案中,A是R
在另一个实施方案中,A是N(R
在本发明的方法的优选实施方案中,Su(A)-Nuc(3)中的A和下文更详细描述的(3)的优选实施方案选自-N
在糖衍生物核苷酸Su(A)-Nuc(3)及其优选实施方案(例如(34))中,R
其中W、h、a、f、T、A和U如上所定义。
在糖衍生物核苷酸Su(A)-Nuc(3)的优选实施方案中,R
其中W、h、a、f、T、A和U如上文所定义。
最优选R
当R
在本发明的方法的优选实施方案中,Su(A)-Nuc(3)中的R
其中Nuc、Z、Y、U、T、A、g、f和a如上文所定义。
此外,当糖衍生物核苷酸Su(A)-Nuc如式(3a)所示或根据其优选实施方案时,优选Nuc为UDP。
此外,同样在Su(A)-Nuc(3a)中,A优选选自-N
在特别优选的实施方案中,在Su(A)-Nuc(3a)中Nuc是UDP,A选自-N
在本发明的方法的另一个优选实施方案中,R
/>
其中Nuc、Z、Y、U、T、A、W、h、g、f和a如上文所定义。
在糖衍生物核苷酸Su(A)-Nuc(3b)中,独立地选择A、T、U、a和f。换言之,(3b)的C2上的取代基中的A、T、U、a和f可以不同于(3b)的C6上的取代基中的A、T、U、a和f。
此外,当Su(A)-Nuc如式(3b)所示或根据其优选实施方案时,优选Nuc为UDP。
此外,同样在Su(A)-Nuc(3b)中,A优选选自-N
在特别优选的实施方案中,在Su(A)-Nuc(3b)中Nuc是UDP,A选自-N
在本发明的方法的另一个优选实施方案中,R
其中Nuc、Z、Y、U、T、A、g、f和a如上所定义。
此外,当糖衍生物核苷酸Su(A)-Nuc如式(3c)所示或根据其优选实施方案时,优选Nuc为UDP。
此外,同样在Su(A)-Nuc(3c)中,A优选选自-N
在特别优选的实施方案中,在Su(A)-Nuc(3c)中Nuc是UDP,A选自-N
在本发明的方法的另一个优选实施方案中,R
其中Nuc、Z、Y、U、T、A、g、f和a如上文所定义。
此外,当糖衍生物核苷酸Su(A)-Nuc如式(3d)所示或根据其优选实施方案时,优选Nuc为UDP。
此外,同样在Su(A)-Nuc(3d)中,A优选选自-N
在特别优选的实施方案中,在Su(A)-Nuc(3d)中Nuc是UDP,A选自-N
在Su(A)-Nuc(3)及其优选实施方案(例如(34)、(3a)、(3b)、(3c)或(3d))中,T是C
(杂)亚芳基T任选进一步被一个或多个取代基R
当R
优选地,R
更优选地,R
甚至更优选地,R
还甚至更优选地,R
在一个优选的实施方案中,(3)中的(杂)亚芳基是未取代的。在另一个优选实施方案中,(3)中的(杂)亚芳基包含一个或多个取代基R
术语“(杂)亚芳基”在本文中是指亚芳基以及杂亚芳基。术语“(杂)亚芳基”在本文中是指单环(杂)亚芳基以及双环(杂)亚芳基。Su(A)-Nuc(3)中的(杂)亚芳基可以是任何亚芳基或任何杂亚芳基。
在本发明的方法的一个优选实施方案中,(3)中的(杂)亚芳基T选自亚苯基、亚萘基、亚蒽基、亚吡咯基、亚吡咯鎓(pyrroliumylene)基、亚呋喃基、亚噻吩(thiophenylene)基(即亚噻吩(thiofuranylene)基)、亚吡唑基、亚咪唑基、亚嘧啶鎓(pyrimidiniumylene)基、亚咪唑鎓(imidazoliumylene)基、亚异噁唑基、亚噁唑基、亚噁唑鎓(oxazoliumylene)基、亚异噻唑基、亚噻唑基、1,2,3-亚三唑基、1,3,4-亚三唑基、亚二唑基、1-氧杂-2,3-亚二唑基、1-氧杂-2,4-亚二唑基、1-氧杂-2,5-亚二唑基、1-氧杂-3,4-亚二唑基、1-硫杂-2,3-亚二唑基、1-硫杂-2,4-亚二唑基、1-硫杂-2,5-亚二唑基、1-硫杂-3,4-亚二唑基、亚四唑基、亚吡啶基、亚哒嗪基、亚嘧啶基、亚吡嗪基、亚吡二嗪基、亚吡啶鎓(pyridiniumylene)基、亚嘧啶鎓(pyrimidiniumylene)基、亚苯并呋喃基、亚苯并噻吩基、亚苯并咪唑基、亚吲唑基、亚苯并三唑基、吡咯并[2,3-b]亚吡啶基、吡咯并[2,3-c]亚吡啶基、吡咯并[3,2-c]亚吡啶基、吡咯并[3,2-b]亚吡啶基、咪唑并[4,5-b]亚吡啶基、咪唑并[4,5-c]亚吡啶基、吡唑并[4,3-d]亚吡啶基、吡唑并[4,3-c]亚吡啶基、吡唑并[3,4-c]亚吡啶基、吡唑并[3,4-b]亚吡啶基、亚异吲哚基、亚吲唑基、亚嘌呤基、亚二氢吲哚基(indolininylene group)、咪唑并[1,2-a]亚吡啶基、咪唑并[1,5-a]亚吡啶基、吡唑并[1,5-a]亚吡啶基、吡咯并[1,2-b]亚哒嗪基、咪唑并[1,2-c]亚嘧啶基、亚喹啉基、亚异喹啉基、亚噌啉基、亚喹唑啉基、亚喹喔啉基、亚酞嗪基、1,6-亚萘啶基、1,7-亚萘啶基、1,8-亚萘啶基、1,5-亚萘啶基、2,6-亚萘啶基、2,7-亚萘啶基、吡啶并[3,2-d]亚嘧啶基、吡啶并[4,3-d]亚嘧啶基、吡啶并[3,4-d]亚嘧啶基、吡啶并[2,3-d]亚嘧啶基、吡啶并[2,3-b]亚吡嗪基、吡啶并[3,4-b]亚吡嗪基、嘧啶并[5,4-d]亚嘧啶基、吡嗪并[2,3-b]亚吡嗪基和嘧啶并[4,5-d]亚嘧啶基,所有的基团任选地用一个或多个取代基R
在其他优选的实施方案中,(杂)亚芳基T选自亚苯基、亚吡啶基、亚吡啶鎓基、亚嘧啶基、亚嘧啶鎓基、亚吡嗪基、亚吡二嗪基、亚吡咯基、亚吡咯鎓基、亚呋喃基、亚噻吩基(即亚噻吩(thiofuranylene)基)、亚二唑基、亚喹啉基、亚咪唑基、亚嘧啶鎓基、亚咪唑鎓基、亚噁唑基和亚噁唑鎓基,所有的基团任选地用一个或多个取代基R
甚至更优选地,(杂)亚芳基T选自亚苯基、亚吡啶基、亚吡啶鎓基、亚嘧啶基、亚嘧啶鎓基、亚咪唑基、亚嘧啶鎓基、亚咪唑鎓基、亚吡咯基、亚呋喃基和亚噻吩基,所有的基团任选地用一个或多个取代基R
最优选地,(杂)芳基T选自亚苯基、亚咪唑基、亚咪唑鎓基、亚嘧啶鎓基、亚吡啶基、亚吡啶鎓基,所有的基团任选地用一个或多个取代基R
在Su(A)-Nuc(3)及其优选实施方案(例如(34)、(3a)、(3b)、(3c)或(3d))中,U可以存在(f是1)或不存在(f是0)。存在时,U是[C(R
在优选的实施方案中,U不存在,即f是0。
在另一个优选的实施方案中,U存在,即f是1。
当U是[C(R
R
当U为[C(R
当U为[C(R
当U为[C(R
当U为[C(R
当U是[C(R
在糖衍生物核苷酸Su(A)-Nuc(3)及其优选实施方案(例如(34)、(3a)、(3b)、(3c)或(3d))中,优选a和f不都为0。在另一个优选的实施方案中,a为0且f为1,或者a为1且f为0。在这些实施方案中,g可为0或1。
在本发明方法的优选实施方案中,a为0,f为1且U为[C(R
在本发明的方法的另一个优选实施方案中,a为0,f为1且U为[C(R
在另一个优选实施方案中,a为1,f为1且U为[C(R
在另一个优选实施方案中,a为1,f为1且U为[C(R
如上文所定义,在Su(A)-Nuc(3)及其优选实施方案(例如(34)、(3a)、(3b)、(3C)或(3d))中,Z为CH
在Su(A)-Nuc(3)及其优选实施方案(例如(34)、(3a)、(3b)、(3C)或(3d))中,Y可以不存在(g为0)或存在(g为1)。当Y存在时,Y选自O、S、N(R
在优选的实施方案中,Z是CH
在另一个优选的实施方案中,Z是C(O),g是1。在该实施方案中,进一步优选Y是N(R
因此,在本发明的方法的优选实施方案中,糖衍生物核苷酸Su(A)-Nuc如式(15)、(16)、(17)或(18)所示:
其中Nuc、a、f、R
在(15)、(16)、(17)和(18)的优选实施方案中,R
(15)、(16)、(17)和(18)中的U、T、a和f的优选实施方案如上文所述。如上文所定义的A的优选实施方案也适用于(15)、(16)、(17)和(18)。
在(15)、(16)、(17)和(18)的特别优选的实施方案中,a是0,f是1,U是-CH
在(15)、(16)、(17)和(18)的另一个特别优选的实施方案中,a是1,T优选为任选取代的苯基。如上所述,苯基任选被R
在本发明的方法的优选实施方案中,糖衍生物核苷酸Su(A)-Nuc如式(19)、(20)、(21)、(22)、(23)、(24)、(25)、(26)、(65)或(66)所示,优选地如(19)、(20)、(21)、(22)、(23)、(24)、(25)或(26)所示:
/>
其中:
R
R
在本发明的方法的优选实施方案中,糖衍生物核苷酸Su(A)-Nuc如式(67)、(68)或(69)所示:
其中R
在其他优选的实施方案中,R
在如上所述的(19)、(20)、(21)、(22)、(23)、(24)、(25)、(26)、(65)、(66)、(67)、(68)和(69)及其优选实施方案的优选实施方案中,R
在优选的实施方案中,R
其中a、f、h、T、A、U和W及其优选实施方案如上文所定义。
在本发明的方法的其他优选的实施方案中,糖衍生物核苷酸Su(A)-Nuc如式(27)、(28)、(29)、(30)或(31)所示,或如式(36)所示:
其中Nuc如上文所定义。
在本发明的方法进一步优选的实施方案中,其中R
其中Nuc如上文所定义。
此外,当Su(A)-Nuc如式(27)、(28)、(29)、(30)、(31)、(35)或(36)所示时,优选Nuc是UDP。
酶
本发明的方法包括以下步骤:在糖基转移酶的存在下、更特别是在糖基转移酶的作用下,将包含含有末端GlcNAc部分的聚糖的糖蛋白与糖衍生物核苷酸Su(A)-Nuc接触,以提供经修饰的糖蛋白,其中所述糖基转移酶为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶。在本文中,β-(1,4)-N-乙酰半乳糖胺转移酶也称为β(1,4)-GalNAcT酶、或β-(1,4)-GalNAcT或GalNAcT。
β-(1,4)-N-乙酰半乳糖胺转移酶(β-(1,4)-GalNAcT)是本领域已知的。通常,β-(1,4)-GalNAcT是催化N-乙酰半乳糖胺(GalNAc)从尿苷二磷酸-GalNAc(UDP-GalNAc,也称为GalNAc-UDP)转移至糖蛋白聚糖的末端GlcNAc部分的酶,其中GalNAc部分的C1经由β-1,4-O-糖苷键连接至GlcNAc部分的C4。如上文更详细描述的,其中b是1的式(1)的聚糖中的GlcNAc部分,即由岩藻糖基化的GlcNAc组成的聚糖中的GlcNAc部分在本文中也被认为是末端GlcNAc部分。
在本发明的方法中,为或衍生自β-(1,4)-GalNAcT的糖基转移酶催化糖衍生物Su(A)从糖衍生物核苷酸Su(A)-Nuc转移至糖蛋白聚糖的末端GlcNAc部分,以提供经修饰的糖蛋白,其中Su(A)如式(6)所示、Su(A)-Nuc如式(3)所示、含有末端GlcNAc部分的聚糖如式(1)或(2)所示且经修饰的糖蛋白如式(4)或(5)所示,如上文所述。在该方法中,Su(A)部分的C1经由β-1,4-O-糖苷键连接至GlcNAc部分的C4。
优选地,本发明的方法中使用的β-(1,4)-GalNAcT酶为或衍生自无脊椎动物β-(1,4)-GalNAcT酶,即为或衍生自来源于无脊椎动物物种的β-(1,4)-GalNAcT。β-(1,4)-GalNAcT酶可以为或可以衍生自本领域技术人员已知的任何无脊椎动物β-(1,4)-GalNAcT酶。优选地,β-(1,4)-GalNAcT酶为或衍生自来源于线虫动物门(Nematoda)、优选来源于色矛纲(Chromadorea)或胞管肾纲(Secernentea),或来源于节肢动物门(Arthropoda),优选来源于昆虫纲(Insecta)的β-(1,4)-GalNAcT酶。优选地,β-(1,4)-GalNAcT酶为或衍生自来源于秀丽隐杆线虫(Caenorhabditis elegans)、腐生水果线虫(Caenorhabditisremanei)、Caenorhabditis briggsae、猪蛔虫(Ascaris suum)、粉纹夜蛾(Trichoplusiani)、黑腹果蝇(Drosophila melanogaster)、吴策线虫(Wuchereria bancrofti)、罗阿丝虫(Loa loa)、毕氏粗角猛蚁(Cerapachys biroi)、湿木白蚁(Zootermopsis nevadensis)、佛罗里达弓背蚁(Camponotus floridanus)、长牡蛎(Crassostrea gigas)或大红斑蝶(Danaus plexippus),优选来源于秀丽隐杆线虫、猪蛔虫、粉纹夜蛾或黑腹果蝇的β-(1,4)-GalNAcT酶。更优选地,β-(1,4)-GalNAcT酶为或衍生自来源于秀丽隐杆线虫、猪蛔虫或粉纹夜蛾的β-(1,4)-GalNAcT酶。在其他优选的实施方案中,β-(1,4)-GalNAcT酶为或衍生自来源于猪蛔虫的β-(1,4)-GalNAcT酶。在另一个优选的实施方案中,β-(1,4)-GalNAcT酶为或衍生自来源于粉纹夜蛾的β-(1,4)-GalNAcT酶。在另一个优选的实施方案中,β-(1,4)-GalNAcT酶为或衍生自来源于秀丽隐杆线虫的β-(1,4)-GalNAcT酶。
在本文中,秀丽隐杆线虫也称为Ce,猪蛔虫也称为As,粉纹夜蛾也称为Tn,黑腹果蝇也称为Dm。
优选地,用于本发明的方法的β-(1,4)-GalNAcT酶与选自SEQ ID NO:2-5和15-23的序列,更优选与选自SEQ ID NO:2-5的序列具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。换言之,优选用于本发明的方法的β-(1,4)-GalNAcT酶与选自SEQ IDNO:2、SEQ ID NO:3、SEQ ID NO:4和SEQ ID NO:5、SEQ IDNO:15、SEQ ID NO:16、SEQ ID NO:17、SEQ ID NO:18、SEQ ID NO:19、SEQ ID NO:20、SEQ ID NO:21、SEQ ID NO:22和SEQ IDNO:23的序列,更优选与选自SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4和SEQ ID NO:5的序列,甚至更优选与选自SEQ ID NO:2、SEQ ID NO:3和SEQ ID NO:4的序列,甚至更优选与选自SEQ ID NO:3和SEQ IDNO:4的序列,最优选与SEQ ID NO:4具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
优选地,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自选自如下的任何天然存在的或野生型β-(1,4)-GalNAcT酶:本文中命名为CeGalNAcT的秀丽隐杆线虫β-(1,4)-GalNAcT(SEQ ID NO:2)、本文中命名为AsGalNAcT的猪蛔虫β-(1,4)-GalNAcT(SEQ ID NO:3)、本文中命名为TnGalNAcT的粉纹夜蛾β-(1,4)-GalNAcT(SEQ ID NO:4)、本文中命名为DmGalNAcT的黑腹果蝇β-(1,4)-GalNAcT(SEQ ID NO:5)、腐生水果线虫β-(1,4)-GalNAcT(SEQ ID NO:15)、Caenorhabditis briggsaeβ-(1,4)-GalNAcT(SEQ ID NO:16)、吴策线虫β-(1,4)-GalNAcT(SEQ IDNO:17)、罗阿丝虫β-(1,4)-GalNAcT(SEQ ID NO:18)、毕氏粗角猛蚁β-(1,4)-GalNAcT(SEQ ID NO:19)、湿木白蚁β-(1,4)-GalNAcT(SEQ ID NO:20)、佛罗里达弓背蚁β-(1,4)-GalNAcT(SEQ ID NO:21)、长牡蛎β-(1,4)-GalNAcT(SEQ ID NO:22)和大红斑蝶β-(1,4)-GalNAcT(SEQ ID NO:23)。
在优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自选自如下的任何天然存在的或野生型β-(1,4)-GalNAcT酶:本文中命名为CeGalNAcT的秀丽隐杆线虫β-(1,4)-GalNAcT(SEQ ID NO:2)、本文中命名为AsGalNAcT的猪蛔虫β-(1,4)-GalNAcT(SEQ ID NO:3)、本文中命名为TnGalNAcT的粉纹夜蛾β-(1,4)-GalNAcT(SEQ ID NO:4)和本文中命名为DmGalNAcT的黑腹果蝇β-(1,4)-GalNAcT(SEQ ID NO:5)。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自选自如下的任何天然存在的或野生型β-(1,4)-GalNAcT酶:本文中命名为CeGalNAcT的秀丽隐杆线虫β-(1,4)-GalNAcT(SEQ ID NO:2)、本文中命名为AsGalNAcT的猪蛔虫β-(1,4)-GalNAcT(SEQ ID NO:3)和本文中命名为TnGalNAcT的粉纹夜蛾β-(1,4)-GalNAcT(SEQ IDNO:4)。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自选自如下的任何天然存在的或野生型β-(1,4)-GalNAcT酶:本文中命名为AsGalNAcT的猪蛔虫β-(1,4)-GalNAcT(SEQ ID NO:3)和本文中命名为TnGalNAcT的粉纹夜蛾β-(1,4)-GalNAcT(SEQ ID NO:4)。
在特别优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自本文中命名为TnGalNAcT的粉纹夜蛾β-(1,4)-GalNAcT(SEQ ID NO:4)。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶是β-(1,4)-GalNAcT酶,其为或衍生自来源于无脊椎动物物种的β-(1,4)-GalNAcT酶,所述无脊椎动物为线虫动物门、优选色矛纲(Chromadorea)、优选杆线虫目(Rhabditida)、优选小杆科(Rhabditidae)、优选新杆状线虫属(Caenorhabditis)。优选地,用于本发明的方法的β-(1,4)-GalNAcT酶与SEQ ID NO:2、15和16的序列具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。更优选地,所述无脊椎动物物种是秀丽隐杆线虫。优选地,用于本发明的方法的β-(1,4)-GalNAcT酶与SEQ ID NO:2具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自来源于无脊椎动物物种的β-(1,4)-GalNAcT酶,所述无脊椎动物为线虫动物门、优选胞管肾纲(Secernentea)、优选蛔目(Ascaridida)、优选蛔虫科(Ascarididae)、优选蛔虫属(Ascaris)。更优选地,所述无脊椎动物物种是猪蛔虫(Ascaris Sum)。优选地,用于本发明的方法的β-(1,4)-GalNAcT酶与SEQ ID NO:3的序列具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自来源于无脊椎动物物种的β-(1,4)-GalNAcT酶,所述无脊椎动物物种为节肢动物门(Anthropoda)、优选昆虫纲(Insecta)、优选鳞翅目(Lepidoptera)、优选夜蛾科(Noctuidae)、优选粉纹夜蛾属(Trichoplusia)。更优选地,所述无脊椎动物物种是粉纹夜蛾。粉纹夜蛾有时也可称为Phytometra brassicae、Plusia innata或甘蓝银纹夜蛾(cabbage looper)。优选地,用于本发明的方法的β-(1,4)-GalNAcT酶与SEQ ID NO:4的序列具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-GalNAcT酶为或衍生自来源于无脊椎动物物种的β-(1,4)-GalNAcT酶,所述无脊椎动物物种为节肢动物门、优选昆虫纲(Insecta)、优选双翅目(Diptera)、优选果蝇科(Drosophilidae)、优选果蝇属(Drosophila)。更优选地,所述无脊椎动物物种是黑腹果蝇。优选地,用于本发明的方法的β-(1,4)-GalNAcT酶与SEQ ID NO:5的序列具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在本文中,“衍生自”β-(1,4)-GalNAcT酶应理解为具有分别通过置换、插入、缺失或添加一个或多个,优选1、2、3、4、5、6、7、8、9、10、12、14、16、18、20或更多个氨基酸而改变自天然存在的β-(1,4)-GalNAcT酶的氨基酸序列的β-(1,4)-GalNAcT酶。在本文中,衍生自β-(1,4)-GalNAcT酶的β-(1,4)-GalNAcT酶也称为衍生的β-(1,4)-GalNAcT酶或修饰的β-(1,4)-GalNAcT酶或β-(1,4)-GalNAcT突变酶或β-(1,4)-GalNAcT突变体。
衍生的酶是本领域已知的,包括已经经过氨基酸序列的常规和标准修饰的酶,例如去除跨膜结构域、包含标签(例如如本文所述的溶解性和/或纯化标签)。得到具有经修饰的氨基酸序列的酶的这些方法是本领域公知的,并且包括在本发明的方法中。
在一个实施方案中,衍生的酶——即与本文提及的天然存在的β-(1,4)-GalNAcT酶具有小于100%的序列同一性——优选具有天然存在的β-(1,4)-GalNAcT酶的酶活性的至少10%、20%、30%、40%、50%、60%、70%或优选至少80%或90%或至少100%的酶活性。在本文中,将活性方便地测定为将(修饰的)GalNAc残基掺入糖蛋白的末端GlcNAc残基上的功效。
所述酶不是半乳糖基转移酶。在一个实施方案中,所述酶不是归类为E.C.2.4.1.38或归类为E.C.2.4.1.133的酶,优选不是归类为E.C.2.4.1.22、归类为E.C.2.4.1.38、归类为E.C.2.4.1.90或归类为E.C.2.4.1.133的酶。
在一个实施方案中,所述酶是归类为E.C.2.4.1.41、归类为E.C.2.4.1.92、归类为E.C.2.4.1.174或归类为E.C.2.4.1.244的酶,优选归类为E.C.2.4.1.92或归类为E.C.2.4.1.244的酶。
优选地,通过添加额外的N-或C-末端氨基酸或化学部分,或通过缺失N-或C-末端氨基酸来修饰所述衍生的β-(1,4)-GalNAcT酶以增加稳定性、溶解性、活性和/或易于纯化。
优选地,通过缺失N-末端胞质结构域和跨膜结构域来修饰β-(1,4)-GalNAcT酶,其在本文中称为截短的酶。本领域已知这些结构域的缺失产生在水溶液中表现出增加的溶解度的酶。
例如,CeGalNAcT(30-383)在本文中应理解为由SEQ ID NO:2的第30-383位上的氨基酸表示的氨基酸序列组成的截短的秀丽隐杆线虫β-(1,4)-GalNAcT酶。类似地,AsGalNAcT(30-383)在本文中应理解为由SEQ ID NO:3的第30-383位上的氨基酸表示的氨基酸序列组成的截短的猪蛔虫β-(1,4)-GalNAcT酶,TnGalNAcT(33-421)在本文中应理解为由SEQ ID NO:4的第33-421位上的氨基酸表示的氨基酸序列组成的截短的粉纹夜蛾β-(1,4)-GalNAcT酶,DmGalNAcT(47-403)在本文中应理解为由SEQ ID NO:5的第47-403位上的氨基酸表示的氨基酸序列组成的截短的黑腹果蝇β-(1,4)-GalNAcT酶。
优选地,用于本发明的方法的β-(1,4)-GalNAcT酶与SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8或SEQ ID NO:9的任一序列,更优选与SEQ ID NO:6、SEQ ID NO:7或SEQ IDNO:8的序列,甚至更优选与SEQ ID NO:7或SEQ ID NO:8的序列,甚至更优选与序列SEQ IDNO:8具有至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选至少100%的序列同一性。
其中一个或多个氨基酸已被置换、添加或缺失的β-(1,4)-GalNAcT酶在本文中也称为衍生的β-(1,4)-GalNAcT酶。优选地,通过缺失N-末端胞质结构域和跨膜结构域来修饰,并通过置换一个或多个氨基酸来修饰β-(1,4)-GalNAcT酶。在本文中,一个或多个氨基酸的置换也称为突变。包含一个或多个置换的氨基酸的酶也称为突变酶。
在本发明的方法中,当糖基转移酶衍生自秀丽隐杆线虫β-(1,4)-GalNAcT酶或截短的β-(1,4)-GalNAcT酶时,优选所述酶还包含一个或多个突变。优选的突变包括在第257位由亮氨酸(Leu,也称为L)、甲硫氨酸(Met,也称为M)或丙氨酸(Ala,也称为A)置换异亮氨酸(Ile,也称为I)。优选的突变还包括在第312位由组氨酸(His,也称为H)置换甲硫氨酸(Met,也称为M)。因此,当糖基转移酶衍生自CeGalNAcT或CeGalNAcT(30-383)时,优选所述酶包含I257L、I257M或I257A突变,和/或M312H突变。
应注意,在本文中氨基酸位置的编号是基于野生型β-(1,4)-GalNAcT酶中氨基酸位置的编号。当β-(1,4)-GalNAcT酶是例如截短的酶时,本文中用来表示例如氨基酸置换的位置的数字对应于相应的野生型β-(1,4)-GalNAcT酶中的氨基酸位置的编号。
作为实例,在野生型CeGalNAcT(SEQ ID NO:2)中,异亮氨酸(Ile,I)存在于第257位氨基酸位置上。在CeGalNAcT(I257L)中,第257位的异亮氨酸氨基酸被亮氨酸氨基酸(Leu,L)置换。如上所述,CeGalNAcT(30-383)在本文中应理解为由SEQ ID NO:2的第30-383位的氨基酸表示的氨基酸序列组成的截短的CeGalNAcT酶,而CeGalNAcT(30-383)本身由SEQ ID NO:6表示。在CeGalNAcT(30-383;I257L)中,I257L中的数字“257”表示它是相应野生型CeGalNAcT中的第257位上的I氨基酸(即用L氨基酸置换的SEQ ID NO:2的数字257)。在SEQ ID NO:2的第257位的异亮氨酸氨基酸由SEQ ID NO:6的第228位的异亮氨酸氨基酸表示。
优选的截短的秀丽隐杆线虫β-(1,4)-GalNAcT突变酶包括CeGalNAcT(30-383;I257L)(SEQ ID NO:10)、CeGalNAcT(30-383;I257M)(SEQ ID NO:11)、CeGalNAcT(30-383;I257A)(SEQ ID NO:12)和CeGalNAcT(30-383;M312H)(SEQ ID NO:13)。
在本发明的方法中,当糖基转移酶衍生自粉纹夜蛾β-(1,4)-GalNAcT酶或截短的粉纹夜蛾β-(1,4)-GalNAcT酶时,优选所述酶还包含一个或多个突变。优选的突变包括在第336位由苯丙氨酸(Phe,也称为F)、组氨酸(His,也称为H)或缬氨酸(Val,也称为V)置换色氨酸(Trp,也称为W)。因此,当糖基转移酶衍生自TnGalNAcT或TnGalNAcT(33-421)时,优选所述酶包含W336F、W336H或W336V突变。TnGalNAcT或TnGalNAcT(33-421)的优选突变还包括在第339位由丙氨酸(Ala,也称为A)、甘氨酸(Gly,也称为G)、天冬氨酸(Asp,也称为D)或丝氨酸(Ser,也称为S)置换谷氨酸(Glu,也称为E)。因此,当糖基转移酶衍生自TnGalNAcT或TnGalNAcT(33-421)时,优选所述酶包含E339A、E339G、E339D或E339S突变。更优选地,当糖基转移酶衍生自TnGalNAcT或TnGalNAcT(33-421)时,第336位和第339位均如上所述突变。因此,当糖基转移酶衍生自TnGalNAcT或TnGalNAcT(33-421)时,优选所述酶包含W336F、W336H或W336V突变或E339A、E339G、E339D或E339S突变。
TnGalNAcT或TnGalNAcT(33-421)的优选突变还包括在第311位由酪氨酸(Tyr,也称为Y)置换异亮氨酸(Ile,也称为I)。因此,当糖基转移酶衍生自TnGalNAcT或TnGalNAcT(33-421)时,优选所述酶包含I311Y突变。
当糖基转移酶衍生自TnGalNAcT或TnGalNAcT(33-421)且包含I311Y突变时,所述酶还可以包含如上所述的第336位上的突变和/或如上所述的第339位上的突变。因此,当糖基转移酶衍生自包含I311Y突变的TnGalNAcT或TnGalNAcT(33-421)时,所述酶还可以包含W336F、W336H或W336V突变和/或E339A、E339G、E339D或E339S突变。
在本发明的方法的优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶是选自以下的粉纹夜蛾β-(1,4)-GalNAcT酶:TnGalNAcT(33-421;W336F)(SEQ ID NO:25)、TnGalNAcT(33-421;W336H)(SEQ ID NO:26)、TnGalNAcT(33-421;W336V)(SEQ ID NO:27)、TnGalNAcT(33-421;E339A)(SEQ ID NO:28)、TnGalNAcT(33-421;E339G)(SEQ ID NO:29)、TnGalNAcT(33-421;E339D)(SEQ IDNO:30)和TnGalNAcT(33-421;E339S)(SEQ ID NO:31)。
在本发明的方法的另一个优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶为选自TnGalNAcT(33-421;W336H、E339A)(SEQ ID NO:32)、TnGalNAcT(33-421;W336H、E339D)(SEQ ID NO:33)和TnGalNAcT(33-421;W336H、E339S)(SEQ IDNO:34)的粉纹夜蛾β-(1,4)-GalNAcT酶。
在本发明的方法的另一个优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶为粉纹夜蛾β-(1,4)-GalNAcT酶TnGalNAcT(33-421;I311Y)(SEQ ID NO:35)。
在本发明的方法的另一个优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶为选自TnGalNAcT(33-421;I311Y、W336F)(SEQ ID NO:36)、TnGalNAcT(33-421;I311Y、W336H)(SEQ ID NO:37)、TnGalNAcT(33-421;I311Y、W336V)(SEQ IDNO:38)、TnGalNAcT(33-421;I311Y、E339A)(SEQ ID NO:39)、TnGalNAcT(33-421;I311Y、E339G)(SEQID NO:40)、TnGalNAcT(33-421;I311Y、E339D)(SEQ ID NO:41)和TnGalNAcT(33-421;I311Y、E339S)(SEQ ID NO:42)的粉纹夜蛾β-(1,4)-GalNAcT酶。
在本发明的方法的另一个优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶为选自TnGalNAcT(33-421;I311Y、W336H、E339A)(SEQ ID NO:43)、TnGalNAcT(33-421;I311Y、W336H、E339D)(SEQ ID NO:44)和TnGalNAcT(33-421;I311Y、W336H、E339S)(SEQID NO:45)的粉纹夜蛾β-(1,4)-GalNAcT酶。
在本发明的方法中,当糖基转移酶衍生自猪蛔虫β-(1,4)-GalNAcT酶或截短的猪蛔虫β-(1,4)-GalNAcT酶时,优选所述酶还包含一个或多个突变。优选的突变包括在第282位由组氨酸(His,也称为H)置换色氨酸(Trp,也称为W),和/或在第285位由天冬氨酸(Asp,也称为D)置换谷氨酸(Glu,也称为E),和/或在第257位由酪氨酸(Tyr,也称为Y)置换异亮氨酸(Ile,也称为I)。因此,当糖基转移酶衍生自AsGalNAcT或AsGalNAcT(30-383)时,优选所述酶包含W282H突变、E285D突变和/或I257Y突变。
在本发明的方法的一个优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶是选自以下的猪蛔虫β-(1,4)-GalNAcT:AsGalNAcT(30-383;W282H)(SEQ ID NO:46)和AsGalNAcT(30-383;E285D)(SEQ ID NO:47)。
在本发明的方法的另一个优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶是猪蛔虫β-(1,4)-GalNAcT:AsGalNAcT(30-383;I257Y)(SEQ ID NO:48)。
在本发明的方法的另一个优选实施方案中,为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶是选自以下的猪蛔虫β-(1,4)-GalNAcT:AsGalNAcT(30-383;I257Y、W282H)和AsGalNAcT(30-383;I257Y、E285D)。
在本发明的方法的优选实施方案中,本文中定义的为或衍生自β-(1,4)-GalNAcT酶的糖基转移酶包含编码易于纯化的标签的序列。优选地,所述标签选自但不限于FLAG标签、聚(His)标签、HA标签、Myc标签、SUMO标签、GST标签、MBP标签或CBP标签,更优选所述标签为6xHis标签。其他优选的待被掺入酶中的标签为可溶性标签,例如AFV标签、SlyD标签、Tsf标签、SUMO标签、Bla标签、MBP标签和GST标签。在其他优选的实施方案中,所述标签共价连接至β-(1,4)-GalNAcT酶的C-末端。在另一个优选的实施方案中,所述标签共价连接至β-(1,4)-GalNAcT酶的N-末端。
当β-(1,4)-GalNAcT酶衍生自秀丽隐杆线虫β-(1,4)-GalNAcT时,His-标记的β-(1,4)-GalNAcT酶优选为CeGalNAcT(30-383)-His(SEQ ID NO:14)。
在本发明的方法的一个优选的实施方案中,当β-(1,4)-GalNAcT酶为或衍生自粉纹夜蛾β-(1,4)-GalNAcT时,His-标记的β-(1,4)-GalNAcT酶为或衍生自His-TnGalNAcT(33-421)(SEQ ID NO:49)。
在本发明的方法的另一个优选实施方案中,当β-(1,4)-GalNAcT酶为或衍生自粉纹夜蛾β-(1,4)-GalNAcT时,His-标记的β-(1,4)-GalNAcT酶为或衍生自His-TnGalNAcT(33-421;W336F)(SEQ ID NO:50)、His-TnGalNAcT(33-421;W336H)(SEQ ID NO:51)、His-TnGalNAcT(33-421;W336V)(SEQ ID NO:52)、His-TnGalNAcT(33-421;339A)(SEQ ID NO:53)、His-TnGalNAcT(33-421;E339G)(SEQ ID NO:54)、His-TnGalNAcT(33-421;E339D)(SEQID NO:55)、His-TnGalNAcT(33-421;E339S)(SEQ ID NO:56)、His-TnGalNAcT(33-421;W336H、E339A)(SEQ ID NO:57)、His-TnGalNAcT(33-421;W336H、E339D)(SEQ ID NO:58)或His-TnGalNAcT(33-421;W336H、E339S)(SEQ ID NO:59)。
在本发明的方法的另一个优选实施方案中,当β-(1,4)-GalNAcT酶为或衍生自粉纹夜蛾β-(1,4)-GalNAcT时,His-标记的β-(1,4)-GalNAcT酶为或衍生自His-TnGalNAcT(33-421;I311Y)(SEQ ID NO:60)。
在本发明的方法的另一个优选实施方案中,当β-(1,4)-GalNAcT酶为或衍生自粉纹夜蛾β-(1,4)-GalNAcT时,His-标记的β-(1,4)-GalNAcT酶为或衍生自His-TnGalNAcT(33-421;I311Y、W336F)(SEQ ID NO:61)、His-TnGalNAcT(33-421;I311Y、W336H)(SEQ IDNO:62)、His-TnGalNAcT(33-421;I311Y、W336V)(SEQ ID NO:63)、His-TnGalNAcT(33-421;I311Y、E339A)(SEQ ID NO:64)、His-TnGalNAcT(33-421;I311Y、E336G)(SEQ ID NO:65)、His-TnGalNAcT(33-421;I311Y、E339D)(SEQ ID NO:66)、His-TnGalNAcT(33-421;I311Y、E339S)(SEQ ID NO:67)、His-TnGalNAcT(33-421;I311Y、W336H、E339A)(SEQ ID NO:68)、His-TnGalNAcT(33-421;I311Y、W336H、E339D)(SEQ ID NO:69)或His-TnGalNAcT(33-421;I311Y、W336H、E339S)(SEQ ID NO:70)。
在本发明的方法的另一个优选实施方案中,当β-(1,4)-GalNAcT酶为或衍生自猪蛔虫β-(1,4)-GalNAcT时,His-标记的β-(1,4)-GalNAcT酶为或衍生自His-AsGalNAcT(30-383)(SEQ ID NO:71)。
在本发明的方法的另一个优选实施方案中,当β-(1,4)-GalNAcT酶为或衍生自猪蛔虫β-(1,4)-GalNAcT时,His-标记的β-(1,4)-GalNAcT酶为或衍生自His-AsGalNAcT(30-383;W282H)(SEQ ID NO:72)、His-AsGalNAcT(30-383;E285D)(SEQ ID NO:73)或His-AsGalNAcT(30-383;I257Y)(SEQ ID NO:74)。
在本发明的方法的优选实施方案中,用于所述方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自SEQ ID NO:2-23和SEQ ID NO:25-74的序列。
在本发明的方法的优选实施方案中,用于所述方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自SEQ ID NO:2-23的序列。换言之,在优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自以下的序列:SEQ ID NO:2、SEQ IDNO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16、SEQ ID NO:17、SEQ ID NO:18、SEQ ID NO:19、SEQ ID NO:20、SEQ IDNO:21、SEQ ID NO:22和SEQ ID NO:23。
在本文中,术语“衍生自”包括例如截短的酶、突变酶和包含易于纯化的标签的酶,这些修饰在上文更详细地描述。术语“衍生自”还包括包含在上文更详细描述的修饰的组合的酶。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:2-23,即选自SEQ ID NO:2、SEQ IDNO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15、SEQ IDNO:16、SEQ ID NO:17、SEQID NO:18、SEQ ID NO:19、SEQ ID NO:20、SEQ ID NO:21、SEQ ID NO:22和SEQ ID NO:23的序列具有至少50%的同一性,优选至少55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在本发明的方法的优选实施方案中,用于所述方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自SEQ ID NO:2-9的序列。换言之,在优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自以下的序列:SEQ ID NO:2、SEQ IDNO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8和SEQ ID NO:9。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ IDNO:7、SEQ ID NO:8和SEQ ID NO:9的序列具有至少50%的同一性,优选至少55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在本发明的方法的另一个优选实施方案中,用于所述方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自SEQ ID NO:25-45和SEQ ID NO:50-70的序列。换言之,在优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自以下的序列:SEQ IDNO:25、SEQ ID NO:26、SEQ ID NO:27、SEQ ID NO:28、SEQ ID NO:29、SEQ IDNO:30、SEQ ID NO:31、SEQ ID NO:32、SEQ ID NO:33、SEQ ID NO:34、SEQ ID NO:35、SEQ IDNO:36、SEQ ID NO:37、SEQ ID NO:38、SEQ ID NO:39、SEQ ID NO:40、SEQ ID NO:41、SEQIDNO:42、SEQ ID NO:43、SEQ ID NO:44、SEQ ID NO:45、SEQ ID NO:50、SEQ ID NO:51、SEQID NO:52、SEQ ID NO:53、SEQ ID NO:54、SEQ ID NO:55、SEQ ID NO:56、SEQ ID NO:57、SEQID NO:58、SEQ ID NO:59、SEQ ID NO:60、SEQ ID NO:61、SEQ ID NO:62、SEQ IDNO:63、SEQID NO:64、SEQ ID NO:65、SEQ ID NO:66、SEQ ID NO:67、SEQ ID NO:68、SEQ ID NO:69和SEQ ID NO:70。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:25-45和SEQ ID NO:50-70的序列,即与选自SEQ ID NO:25、SEQ IDNO:26、SEQ ID NO:27、SEQ ID NO:28、SEQ ID NO:29、SEQ ID NO:30、SEQ ID NO:31、SEQ IDNO:32、SEQ ID NO:33、SEQ ID NO:34、SEQ ID NO:35、SEQ ID NO:36、SEQ ID NO:37、SEQ IDNO:38、SEQ ID NO:39、SEQ ID NO:40、SEQ IDNO:41、SEQ ID NO:42、SEQ ID NO:43、SEQ IDNO:44、SEQ ID NO:45、SEQ ID NO:50、SEQ ID NO:51、SEQ ID NO:52、SEQ ID NO:53、SEQ IDNO:54、SEQ ID NO:55、SEQ ID NO:56、SEQ ID NO:57、SEQ ID NO:58、SEQ ID NO:59、SEQ IDNO:60、SEQ ID NO:61、SEQ IDNO:62、SEQ ID NO:63、SEQ ID NO:64、SEQ ID NO:65、SEQ IDNO:66、SEQ ID NO:67、SEQ ID NO:68、SEQ ID NO:69和SEQ ID NO:70的序列具有至少50%的同一性,优选至少55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在本发明的方法的另一个优选实施方案中,用于所述方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自SEQ ID NO:46-49和SEQ ID NO:71-74的序列。换言之,在优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶为或衍生自选自以下的序列:SEQ IDNO:46、SEQ ID NO:47、SEQ ID NO:48、SEQ ID NO:49、SEQ ID NO:71、SEQ IDNO:72、SEQ ID NO:73和SEQ ID NO:74。
在另一个优选的实施方案中,用于本发明的方法的β-(1,4)-N-乙酰半乳糖胺转移酶与选自SEQ ID NO:46-49和SEQ ID NO:71-74的序列,即选自SEQ ID NO:46、SEQ ID NO:47、SEQ ID NO:48、SEQ ID NO:49、SEQ ID NO:71、SEQ ID NO:72、SEQ ID NO:73和SEQ IDNO:74的序列具有至少50%的序列同一性,优选至少55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性。
在本发明的方法中,糖衍生物核苷酸Su(A)-Nuc如式(3)或其优选的实施方案所示,如上文中更详细描述的。R
其中W、h、a、f、T、A和U及其优选实施方案如上文所定义。
当R
在本发明的方法的优选实施方案中,R
当Su(A)-Nuc如式(3a)或如上文所述的(3a)的优选实施方案所示时,在所述方法的优选实施方案中,为或衍生自β-(1,4)-GalNAcT的糖基转移酶为或衍生自野生型β-(1,4)-GalNAcT,优选无脊椎动物β-(1,4)-GalNAcT。在所述方法的另一个优选实施方案中,糖基转移酶为或衍生自无脊椎动物β-(1,4)-GalNAcT。在另一个优选的实施方案中,糖基转移酶为或衍生自秀丽隐杆线虫β-(1,4)-GalNAcT(CeGalNAcT)、猪蛔虫β-(1,4)-GalNAcT(AsGalNAcT)或粉纹夜蛾β-(1,4)-GalNAcT(TnGalNAcT)。为或衍生自(CeGalNAcT)、(AsGalNAcT)或(TnGalNAcT)的β-(1,4)-GalNAcT如上文中更详细描述的。
当糖衍生物核苷酸Su(A)-Nuc中的R
在另一个特别优选的实施方案中,当糖衍生物核苷酸Su(A)-Nuc中的R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在另一个优选的实施方案中,用于其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在本文描述的其中R
当R
在本发明的方法的另一个优选实施方案中,R
当Su(A)-Nuc如式(3b)或如上文所述的(3b)的优选实施方案所示时,在所述方法的优选实施方案中,为或衍生自β-(1,4)-GalNAcT的糖基转移酶为或衍生自野生型β-(1,4)-GalNAcT,优选无脊椎动物β-(1,4)-GalNAcT。在所述方法的另一个优选实施方案中,糖基转移酶为或衍生自无脊椎动物β(1,4)-GalNAcT。在另一个优选的实施方案中,糖基转移酶为或衍生自秀丽隐杆线虫β-(1,4)-GalNAcT(CeGalNAcT)、猪蛔虫β-(1,4)-GalNAcT(AsGalNAcT)或粉纹夜蛾β-(1,4)-GalNAcT(TnGalNAcT)。为或衍生自(CeGalNAcT)、(AsGalNAcT)或(TnGalNAcT)的β-(1,4)-GalNAcT如上文中更详细描述的。
当糖衍生物核苷酸Su(A)-Nuc中的R
在另一个特别优选的实施方案中,当糖衍生物核苷酸Su(A)-Nuc中的R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在另一个优选的实施方案中,用于其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在本文描述的其中R
当R
在本发明的方法的优选实施方案中,R
当Su(A)-Nuc如式(3c)或如上文所述的(3c)的优选实施方案所示时,在所述方法的优选实施方案中,糖基转移酶衍生自野生型β-(1,4)-GalNAcT,优选无脊椎动物β-(1,4)-GalNAcT。在所述方法的另一个优选实施方案中,糖基转移酶衍生自无脊椎动物β-(1,4)-GalNAcT。在其他优选的实施方案中,糖基转移酶衍生自秀丽隐杆线虫β-(1,4)-GalNAcT(CeGalNAcT)、猪蛔虫β-(1,4)-GalNAcT(AsGalNAcT)或粉纹夜蛾β-(1,4)-GalNAcT(TnGalNAcT)。衍生自(CeGalNAcT)、(AsGalNAcT)或(TnGalNAcT)的β-(1,4)-GalNAcT如上文中更详细描述的。
在其中R
在其中R
在其中R
在其中R
在其中R
在另一个优选的实施方案中,用于其中R
在其中R
在其中R
在其中R
在本文描述的其中R
当R
在本发明的方法的另一个优选实施方案中,R
当Su(A)-Nuc如式(3d)或如上文所述的(3d)的优选实施方案所示时,在所述方法的优选实施方案中,为或衍生自β-(1,4)-GalNAcT的糖基转移酶为或衍生自野生型β-(1,4)-GalNAcT,优选无脊椎动物β-(1,4)-GalNAcT。在所述方法的另一个优选实施方案中,糖基转移酶为或衍生自无脊椎动物β-(1,4)-GalNAcT。在其他优选的实施方案中,糖基转移酶为或衍生自秀丽隐杆线虫β-(1,4)-GalNAcT(CeGalNAcT)、猪蛔虫β-(1,4)-GalNAcT(AsGalNAcT)或粉纹夜蛾β-(1,4)-GalNAcT(TnGalNAcT)。为或衍生自(CeGalNAcT)、(AsGalNAcT)或(TnGalNAcT)的β-(1,4)-GalNAcT如上文中更详细描述的。
当糖衍生物核苷酸Su(A)-Nuc中的R
在另一个特别优选的实施方案中,当糖衍生物核苷酸Su(A)-Nuc中的R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在另一个优选的实施方案中,用于其中R
在其中R
在其中R
在其中R
在其中R
在其中R
在本文描述的其中R
酶
在一个方面,本发明涉及如本文中所定义的酶,即为或衍生自β-(1,4)-GalNAcT的糖基转移酶,特别是衍生自β-(1,4)-GalNAcT的糖基转移酶,即衍生的β-(1,4)-GalNAcT酶。在一个实施方案中,所述酶衍生自无脊椎动物物种。在一个实施方案中,根据该方面的酶为分离形式。根据本方面,在本发明方法的上下文中,酶及其优选实施方案在上文中进一步定义,这同样适用于酶自身。
在一个实施方案中,根据本发明该方面的酶衍生自β-(1,4)-N-乙酰半乳糖胺转移酶,优选衍生自具有选自SEQ ID NO:2-23和SEQ ID NO:25-74,更优选选自SEQ ID NO:14和SEQ ID NO:25-74,最优选选自SEQ ID NO:10-13、SEQ ID NO:25-48、SEQ ID NO:50-70和SEQ ID NO:72-74的序列的β-(1,4)-N-乙酰半乳糖胺转移酶。根据该实施方案的酶通常为分离形式。
在一个实施方案中,根据本发明该方面的酶涉及与选自SEQ ID NO:2-23和SEQ IDNO:25-74的序列具有至少40%的序列同一性,优选至少45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性的β-(1,4)-N-乙酰半乳糖胺转移酶。根据该实施方案的酶通常为分离形式。优选地,本发明涉及与选自SEQ ID NO:10-14和SEQ ID NO:25-74,最优选选自SEQ ID NO:10-13、SEQ ID NO:25-48、SEQ ID NO:50-70和SEQ ID NO:72-74的序列具有至少40%的序列同一性,优选至少45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性的β-(1,4)-N-乙酰半乳糖胺转移酶。
在优选的实施方案中,根据本发明该方面的酶涉及与选自SEQ ID NO:6-14,即选自SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13和SEQ ID NO:14,优选选自SEQ ID NO:10-13,即选自SEQ IDNO:10、SEQ ID NO:11、SEQ ID NO:12和SEQ ID NO:13的序列具有至少40%的序列同一性,优选至少45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性的β-(1,4)-N-乙酰半乳糖胺转移酶。
在另一个优选的实施方案中,根据本发明该方面的酶涉及与选自SEQ ID NO:25-45和SEQ ID NO:50-70,即选自SEQ ID NO:25、SEQ ID NO:26、SEQ ID NO:27、SEQ ID NO:28、SEQ ID NO:29、SEQ ID NO:30、SEQ ID NO:31、SEQ ID NO:32、SEQ ID NO:33、SEQ IDNO:34、SEQ ID NO:35、SEQ ID NO:36、SEQ ID NO:37、SEQ ID NO:38、SEQ ID NO:39、SEQ IDNO:40、SEQ ID NO:41、SEQ ID NO:42、SEQ IDNO:43、SEQ ID NO:44、SEQ ID NO:45、SEQ IDNO:50、SEQ ID NO:51、SEQ ID NO:52、SEQ ID NO:53、SEQ ID NO:54、SEQ ID NO:55、SEQ IDNO:56、SEQ ID NO:57、SEQ ID NO:58、SEQ ID NO:59、SEQ ID NO:60、SEQ ID NO:61、SEQ IDNO:62、SEQ ID NO:63、SEQ ID NO:64、SEQ ID NO:65、SEQ ID NO:66、SEQ ID NO:67、SEQ IDNO:68、SEQ ID NO:69和SEQ ID NO:70的序列具有至少40%的序列同一性,优选至少45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性的β-(1,4)-N-乙酰半乳糖胺转移酶。
在另一个优选的实施方案中,根据本发明该方面的酶涉及与选自SEQ ID NO:46-48和SEQ ID NO:72-74,即选自SEQ ID NO:46、SEQ ID NO:47、SEQ ID NO:48、SEQ ID NO:72、SEQ ID NO:73和SEQ ID NO:74的序列具有至少40%的序列同一性,优选至少45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或优选100%的序列同一性的β-(1,4)-N-乙酰半乳糖胺转移酶。
本发明还涉及如上文所定义的本发明的酶在用于糖蛋白的修饰的方法中,优选在本发明的方法中的用途。所述方法包括以下步骤:在酶的存在下,使包含含有末端GlcNAc部分的聚糖的糖蛋白与糖衍生物核苷酸接触。在优选的实施方案中,所述糖蛋白如本文中所定义,最优选包含如本文中进一步定义的如式(1)或(2)所示的聚糖的糖蛋白。在优选的实施方案中,糖衍生物核苷酸是如本文中进一步定义的如式(3)所示的糖衍生物核苷酸Su(A)-Nuc。
经修饰的糖蛋白
本发明还涉及经修饰的糖蛋白,其通过本发明用于修饰糖蛋白的方法而获得。更特别地,本发明涉及包含如式(4)或(5)所示的聚糖的糖蛋白:
其中:
b为0或1;
d为0或1;
e为0或1;
G为单糖、或包含2至20个糖部分的直链或支链寡糖;以及
Su(A)如式(6)所示:
其中R
(6)中的R
在本发明的经修饰的糖蛋白中,Su(A)部分的C1经由β-1,4-O-糖苷键连接至GlcNAc部分的C4。
本发明的经修饰的糖蛋白可以包含多于一个如式(4)或(5)所示的聚糖。当为这种情况时,两种或更多种聚糖可互不相同。所述糖蛋白还可以包含一种或多种不包含Su(A)部分的另外的聚糖。
在优选的实施方案中,经修饰的糖蛋白包含如式(4)所示的聚糖,其中b为0。在另一个优选的实施方案中,经修饰的糖蛋白包含如式(4)所示的聚糖,其中b为1。
在另一个优选的实施方案中,经修饰的糖蛋白包含如式(5)所示的聚糖,其中b为0。在另一个优选的实施方案中,经修饰的糖蛋白包含如式(5)所示的聚糖,其中b为1。在如式(5)所示的聚糖中,G表示单糖或包含1至20,优选1至12,更优选1至10,甚至更优选1、2、3、4、5、6、7或8,最优选1、2、3、4、5或6个糖部分的直链或支链寡糖。在聚糖(5)中,优选当d为0时,e为1,当e为0时,d为1。更优选地,在聚糖(5)中,d为1,甚至更优选d为1且e为1。可存在于聚糖中的糖部分是本领域技术人员已知的,并且包括例如葡萄糖(Glc)、半乳糖(Gal)、甘露糖(Man)、岩藻糖(Fuc)、N-乙酰葡糖胺(GlcNAc)、N-乙酰半乳糖胺(GalNAc)、N-乙酰神经氨酸(NeuNAc)或唾液酸和木糖(Xyl)。当聚糖如式(5)所示时,进一步优选聚糖如式(37)、(38)、(39)、(40)、(41)或(42)所示:
其中b是0或1;以及
Su(A)如如上文所定义的式(6)所示。
在优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)、(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,更优选如式(4)、(37)、(38)、(39)、(40)、(41)或(42)所示的N-连接的聚糖。在其他优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)、(37)、(38)或(39)所示的聚糖,更优选如式(4)、(37)、(38)或(39)所示的N-连接的聚糖。最优选地,本发明的经修饰的糖蛋白包含如式(4)或(38)所示的聚糖,更优选如式(4)或(38)所示的N-连接的聚糖。
本发明的经修饰的糖蛋白优选如式(43)、(44)或(45)所示:
其中:
b、d、e和G及其优选实施方案如上文所定义;
Su(A)如上文所定义的式(6)所示;
y独立地为1至24的整数;以及
Pr为蛋白质。
经修饰的糖蛋白可以包含一种或多种聚糖(4)或(5)(y为1至24)。优选地,y为1至12的整数,更优选地为1至10的整数。更优选地,y为1、2、3、4、5、6、7或8,甚至更优选地,y为1、2、3、4、5或6。甚至更优选地,y为1、2、3或4。当y为2或更多时,聚糖可以互不相同。经修饰的糖蛋白还可以包含一种或多种聚糖(4)和一种或多种聚糖(5)的组合。如上文所述,糖蛋白还可以包含一个或多个不具有Su(A)部分的聚糖。
当本发明的经修饰的糖蛋白如式(43)、(44)或(45)所示时,还优选糖蛋白包含如上文所述的式(4)、(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,更优选如式(4)、(37)、(38)或(39)所示,甚至更优选如式(4)或(38)所示的聚糖,优选N连接的聚糖。最优选地,包含末端GlcNAc部分的聚糖是如式(4)或(38)所示的N-连接的聚糖。
在本发明的方法的优选实施方案中,包含含有末端GlcNAc部分的聚糖的糖蛋白是抗体,更优选如式(43)、(44)或(45)所示的抗体,其中蛋白质(Pr)是抗体(Ab),或更具体地,Pr是抗体的多肽部分。此外,当待修饰的糖蛋白是抗体并且所述抗体包含多于一个聚糖(y为2或更多)时,聚糖可以互不相同。抗体还可以包含一个或多个不具有Su(A)部分的聚糖。此外,当经修饰的糖蛋白是抗体时,优选经修饰的抗体包含如上文所定义的式(4)、(37)、(38)、(39)、(40)、(41)或(42)所示,更优选如式(4)、(37)、(38)或(39)所示,甚至更优选如式(4)或(38)所示的聚糖。在该实施方案中,进一步优选的是,抗体包含如式(4)、(37)、(38)、(39)、(40)、(41)或(42)所示的N-连接的聚糖,更优选如式(4)、(37)、(38)或(39)所示的N-连接的聚糖,最优选如式(4)或(38)所示的N-连接的聚糖。
当经修饰的糖蛋白是抗体时,优选y为1、2、3、4、5、6、7或8,更优选y为1、2、4、6或8,甚至更优选y为1、2或4,最优选y为1或2。
如上文所定义的,所述抗体可以是全抗体,也可以是抗体片段。当抗体是全抗体时,所述抗体优选在每个重链上包含一个或多个,更优选一个聚糖。因此,所述全抗体优选包含2个或更多个,优选2、4、6或8个所述聚糖,更优选2或4个,最优选2个聚糖。换言之,当所述抗体为全抗体时,y优选为2、4、6或8,更优选y为2或4,最优选y为2。当所述抗体为抗体片段时,优选y为1、2、3或4,更优选y为1或2。
在优选的实施方案中,所述抗体为单克隆抗体(mAb)。优选地,所述抗体选自IgA、IgD、IgE、IgG和IgM抗体。更优选地,所述抗体是IgG1、IgG2、IgG3或IgG4抗体,最优选地,所述抗体是IgG1抗体。
在本发明的经修饰的糖蛋白中,如式(6)所示的Su(A)中的R
其中W、h、a、f、T、A和U如上文所定义。
在本发明的经修饰的糖蛋白的优选实施方案中,如式(6)所示的Su(A)中的R
其中W、h、a、f、T、A和U如上文所定义。
最优选地,如式(6)所示的Su(A)中的R
在其他优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,更优选N-连接的聚糖,其中Su(A)(6)中的R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,优选N-连接的聚糖,更优选如式(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,甚至更优选N-连接的聚糖,其中Su(A)(6)如式(46)、(47)、(48)或(49)所示:
其中a、f、R
在其中Su(A)(6)如式(46)、(47)、(48)或(49)所示的这些实施方案中,在其他优选的实施方案中,R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,优选N-连接的聚糖,更优选如式(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,甚至更优选N-连接的聚糖,其中Su(A)(6)如式(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)或(71)所示,优选如式(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示:
/>
其中R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,优选N-连接的聚糖,更优选如式(37)、(38)、(39)、(40)、(41)或(42)所示的聚糖,甚至更优选N-连接的聚糖,其中Su(A)(6)如(72)、(73)或(74)所示:
其中R
在其他优选的实施方案中,本发明的经修饰的糖蛋白包含如式(37)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)、(71)、(72)、(73)或(74)所示,优选如式(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(38)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)、(71)、(72)、(73)或(74)所示,优选如式(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(39)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)、(71)、(72)、(73)或(74)所示,优选如式(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(40)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)、(71)、(72)、(73)或(74)所示,优选如式(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示。在另一个进一步优选的实施方案中,本发明的经修饰的糖蛋白包含如式(41)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)、(71)、(72)、(73)或(74)所示,优选如式(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(42)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)、(71)、(72)、(73)或(74)所示,优选如式(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示。
在其中Su(A)(6)如式(50)、(51)、(52)、(53)、(54)、(55)、(56)、(57)、(70)、(71)、(72)、(73)或(74)所示,优选如(50)、(51)、(52)、(53)、(54)、(55)、(56)或(57)所示的这些实施方案中,在其他优选的实施方案中,R
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,优选N-连接的聚糖,更优选如式(37)、(38)、(39)、(40)、(41)或(42)所示聚糖,甚至更优选N-连接的聚糖,其中Su(A)(6)如式(58)、(59)、(60)、(61)或(62)所示:
在其他优选的实施方案中,本发明的经修饰的糖蛋白包含如式(38)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如式(58)、(59)、(60)、(61)或(62)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(39)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如式(58)、(59)、(60)、(61)或(62)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(40)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如式(58)、(59)、(60)、(61)或(62)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(41)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如式(58)、(59)、(60)、(61)或(62)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(42)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如式(58)、(59)、(60)、(61)或(62)所示。
在其中Su(A)(6)如式(58)、(59)、(60)、(61)或(62)所示的这些实施方案中,优选经修饰的糖蛋白如式(43)、(44)或(45)所示。
在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(4)或(5)所示的聚糖,优选N-连接的聚糖,更优选如式(37)、(38)、(39)、(40)、(41)或(42)所示聚糖,甚至更优选N-连接的聚糖,其中Su(A)(6)如式(63)或(64)所示:
在其他优选的实施方案中,本发明的经修饰的糖蛋白包含如式(38)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如式(63)或(64)所示。在另一个优选的实施方案中,本发明的经修饰的糖蛋白包含如式(39)所示的聚糖,优选N-连接的聚糖,其中Su(A)(6)如式(63)或(64)所示。
在其中Su(A)(6)如式(63)或(64)所示的这些实施方案中,优选经修饰的糖蛋白如式(43)、(44)或(45)所示。
本发明还涉及如上文所定义的本发明的经修饰的糖蛋白在制备生物缀合物(优选本发明的生物缀合物)的方法中的用途。所述方法优选用于制备抗体-药物缀合物(ADC)。所述方法包括使经修饰的糖蛋白与接头缀合物接触。在优选的实施方案中,接头缀合物如本文中所定义。在优选的实施方案中,生物缀合物是如式(75)、(76)或(77)所示的生物缀合物,如下文进一步定义的。
生物缀合物
本发明还涉及通过将接头缀合物与本发明的经修饰的糖蛋白缀合而获得的生物缀合物。接头缀合物在本领域中已知作为生物缀合反应中的反应物之一,其中糖蛋白——例如本发明的经修饰的糖蛋白——是其他反应物。接头缀合物在本文中定义为其中靶分子经由接头与反应基团Q
生物缀合反应是抗体-缀合物如抗体-药物缀合物(ADC)领域中已知的,其中它们用于制备抗体与靶分子(通常为细胞毒素)的缀合物。在这种生物缀合反应中,本发明的经修饰的糖蛋白通过存在于经修饰的糖蛋白上的官能团A与存在于接头缀合物上的反应基团Q
更具体地,本发明涉及如式(75)、(76)或(77)所示的生物缀合物:
/>
其中:
Pr是蛋白质
y独立地如上文针对(43)所定义的;
b、d、e和G独立地如上文针对(5)所定义的;
CG是将Su连接至Sp或D的连接基团;
Sp是间隔基;
D是靶分子;
j独立地为1、2、3、4或5,优选j为1;
k独立地为1至10的整数,优选k为1、2、3或4,最优选k为1;
m为0或1,优选m为1。
Su如式(78)所示:
其中R
(75)、(76)或(77)中的Pr和y的优选实施方案如上文针对(43)、(44)和(45)更详细描述的。在优选的实施方案中,糖蛋白是抗体。生物缀合物——特别是抗体——可包含多于一个官能化聚糖(y为2或更多),聚糖可以互不相同。抗体可以进一步包含一个或多个不具有Su-(CG-(Sp)
如上文所定义的,所述抗体可以是全抗体,也可以是抗体片段。当抗体是全抗体时,所述抗体优选在每个重链上包含一个或多个,更优选一个聚糖。因此,所述全抗体优选包含2个或更多个,优选2、4、6或8个所述官能化聚糖,更优选2或4个,最优选2个官能化聚糖。换言之,当所述抗体为全抗体时,y优选为2、4、6或8,更优选y为2或4,最优选y为2。当抗体为抗体片段时,优选y为1、2、3或4,更优选y为1或2。
在优选的实施方案中,所述抗体为单克隆抗体(mAb)。优选地,所述抗体选自IgA、IgD、IgE、IgG和IgM抗体。更优选地,所述抗体是IgG1、IgG2、IgG3或IgG4抗体,最优选地,所述抗体是IgG1抗体。
(75)、(76)或(77)中的聚糖链,特别是b、d、e和G的优选实施方案如上文针对(4)和(5)及其优选实施方案——例如(37)、(38)、(39)、(40)、(41)或(42)——所更详细描述的。
(78)中的R
在本发明的生物缀合物中,如式(78)所示的Su中的R
其中W、h、a、f、T、A和U如上文所定义。
在本发明的经修饰的糖蛋白的优选实施方案中,如式(78)所示的Su中的R
其中W、h、a、f、T、A和U如上文所定义。
最优选地,如式(78)所示的Su中的R
D是靶分子。在本文中,靶分子被定义为具有在缀合时赋予生物分子的所需性质的分子结构。靶分子D优选选自活性物质、报告分子、聚合物、固体表面、水凝胶、纳米颗粒、微粒和生物分子。最优选地,靶分子D是活性物质。
在本文中,术语“活性物质”涉及药理学和/或生物学物质,即具有生物学活性和/或药物活性的物质,例如药物、前药、诊断试剂、蛋白质、肽、多肽、肽标签、氨基酸、聚糖、脂质、维生素、类固醇、核苷酸、核苷、多核苷酸、RNA或DNA。肽标签的实例包括细胞穿透肽如人乳铁蛋白或聚精氨酸。聚糖的一个实例是寡甘露糖。氨基酸的实例是赖氨酸。当靶分子是活性物质时,活性物质优选选自药物和前药。更优选地,活性物质选自药物活性化合物,特别是低至中等分子量化合物(例如约200至约2500Da,优选约300至约1750Da)。在其他优选的实施方案中,活性物质选自细胞毒素,抗病毒剂、抗菌剂、肽和寡核苷酸。细胞毒素的实例包括秋水仙碱、长春花生物碱、蒽环类、喜树碱、多柔比星、柔红霉素、紫杉烷类、刺孢霉素、微管溶素、伊立替康、抑制肽、鹅膏蕈碱、deBouganin、多卡米星、美登素、auristatin或吡咯苯并二氮杂卓(PBD)。
在本文中,术语“报告分子”是指容易检测其存在的分子,例如诊断剂、染料、荧光团、放射性同位素标记、造影剂、磁共振成像剂或质量标签。多种荧光团,也称为荧光探针,是本领域技术人员已知的。在例如G.T.Hermanson,“Bioconjugate Techniques”,Elsevier,3
适合用作本发明的化合物中的靶分子D的聚合物是本领域技术人员已知的,并且在例如G.T.Hermanson,“Bioconjugate Techniques”,Elsevier,3
适合用作靶分子D的固体表面是本领域技术人员已知的。固体表面是例如功能性表面(例如纳米材料、碳纳米管、富勒烯或病毒壳体的表面)、金属表面(例如钛、金、银、铜、镍、锡、铑或锌表面)、金属合金表面(其中合金来自例如铝、铋、铬、钴、铜、镓、金、铟、铁、铅、镁、汞、镍、钾、钚、铑、钪、银、钠、钛、锡、铀、锌和/或锆)、聚合物表面(其中聚合物为例如聚苯乙烯、聚氯乙烯、聚乙烯、聚丙烯、聚(二甲基硅氧烷)或聚甲基丙烯酸甲酯、聚丙烯酰胺)、玻璃表面、硅氧烷表面、色谱载体表面(其中色谱载体为例如二氧化硅载体、琼脂糖载体、纤维素载体或氧化铝载体)等。当靶分子D是固体表面时,优选D独立地选自功能性表面或聚合物表面。
水凝胶是本领域技术人员已知的。水凝胶是由聚合物成分之间的交联形成的水溶胀网。参见例如A.S.Hoffman,Adv.Drug Delivery Rev.2012,64,18,其通过引用的方式纳入本文。当靶分子是水凝胶时,优选的是水凝胶由作为聚合物基体的聚乙二醇(PEG)组成。
适合用作靶分子D的微米颗粒和纳米颗粒是本领域技术人员已知的。各种合适的微米颗粒和纳米颗粒描述于例如G.T.Hermanson,“Bioconjugate Techniques”,Elsevier,3
靶分子D也可以是生物分子。当靶分子D是生物分子时,优选生物分子选自蛋白质(包括糖蛋白和抗体)、多肽、肽、聚糖、脂质、核酸、寡核苷酸、多糖、寡糖、酶、激素、氨基酸和单糖。
CG是连接基团。在本文中,术语“连接基团”是指连接化合物的一个部分和同一化合物的另一部分的结构元件。通常,生物缀合物通过存在于接头缀合物中的反应性基团Q
当A为例如硫醇基时,互补基团Q
当A为例如氨基时,互补基团Q
当A为例如酮基时,互补基团Q
当A为例如炔基时,互补基团Q
当A为例如烯基时,互补基团Q
当A为例如叠氮基时,互补基团Q
当A为例如环丙烯基、反式环辛烯基或环辛炔基时,互补基团Q
当A为例如卤素(X)时,互补基团Q
当A为例如–OS(O)
当A为例如丙二烯基时,互补基团Q
当A为例如–SC(O)R
A和Q
Sp是间隔基或接头。在本文中将接头定义为连接化合物的两个或更多个元素的部分。例如在生物缀合物中,生物分子和靶分子通过接头彼此共价连接;在接头缀合物中,反应性基团Q
在优选的实施方案中,Sp选自直链或支链C
更优选地,Sp选自直链或支链C
甚至更优选地,Sp选自直链或支链C
甚至更优选地,Sp选自直链或支链C
在这些优选的实施方案中,进一步优选亚烷基、亚烯基、亚炔基、亚环烷基、亚环烯基、亚环炔基、烷基亚芳基、芳基亚烷基、芳基亚烯基和芳基亚炔基是未被取代的并且任选地被一个或多个选自O、S和NR
最优选地,Sp选自直链或支链C
特别优选的Sp部分包括-(CH
实施例
实施例1.GalNAc转移酶的选择和设计
选择四个特异性序列用于初始评估,特别是Uniprot登录号:Q9GUM2(秀丽隐杆线虫;在本文中表示为SEQ ID NO:2)、U1MEV9(猪蛔虫;在本文中表示为SEQ ID NO:3)、Q6J4T9(粉纹夜蛾,在本文中表示为SEQ ID NO:4)和Q7KN92(黑腹果蝇;在本文中表示为SEQ IDNO:5)。
基于预测的胞质结构域和跨膜结构域的缺失来构建多肽。这些多肽包含预测的秀丽隐杆线虫(由SEQ ID NO:6表示的CeGalNAcT[30-383])、猪蛔虫(由SEQ ID NO:7表示的AsGalNAcT[30-383])、粉纹夜蛾(由SEQ ID NO:8表示的TnGalNAcT[33-421])和黑腹果蝇(由SEQ ID NO:9表示的DmGalNAcT[47-403])。
此外,针对AsGalNAcT[30-383](由SEQ ID NO:71表示的His-AsGalNAcT[30-383])和TnGalNAcT[33-421](由SEQ ID NO:49表示的His-TnGalNAcT[33-421])构建含有N-末端His-标签的多肽变体。
实施例2.设计粉纹夜蛾GalNAcT突变体和猪蛔虫GalNAcT突变体
基于与UDP-N-乙酰基-半乳糖胺(PDB条目1OQM)复合的牛β(1,4)-Gal-T1和由Qasba等人(J.Biol.Chem.2002,277:20833-20839,通过引用的方式纳入本文)报道的β(1,4)-Gal-T1(Y289L)突变体的晶体结构来设计TnGalNAcT和AsGalNAcT的突变体。基于TnGalNAcT和AsGalNAcT与牛β(1,4)Gal-T1的序列比对来设计TnGalNAcT和AsGalNAcT的突变体。这些蛋白之间的对应氨基酸残基示于表1中。
表1.不同物种的GalNAcT/GalT中对应氨基酸的编号
实施例3.His-TnGalNAcT(33-421)突变体的定点诱变
从Genscript获得含有在NdeI-BamHI位点之间的密码子优化序列(其编码TnGalNAcT(由SEQ ID NO:8表示)的残基33-421)的pET15b载体,产生His-TnGalNAcT(33-421)(由SEQ ID NO:49表示)。使用一组重叠引物通过线性扩增PCR从上述构建体扩增TnGalNaCT突变基因。用于每个突变体的重叠引物组示于表2中。为了构建His-TnGalNAcT(33-421;W336F)(由SEQ ID NO:50表示),用本文定义为SEQ ID NO:79和SEQ ID NO:80的一对引物扩增DNA片段。为了构建His-TnGalNAcT(33-421;W336H)(由SEQ ID NO:51表示),用本文定义为SEQ ID NO:81和SEQ ID NO:82的一对引物扩增DNA片段。为了构建His-TnGalNAcT(33-421;W336V)(由SEQ ID NO:52表示),用本文定义为SEQ ID NO:83和SEQ IDNO:84的一对引物扩增DNA片段。为了构建His-TnGalNAcT(33-421;E339A)(由SEQ ID NO:53表示),用本文定义为SEQ ID NO:85和SEQ ID NO:86的一对引物扩增DNA片段。为了构建His-TnGalNAcT(33-421;E339G))(由SEQ IDNO:54表示),用本文定义为SEQ ID NO:87和SEQID NO:88的一对引物扩增DNA片段。为了构建His-TnGalNAcT(33-421;E339D)(由SEQ IDNO:55表示),用本文定义为SEQ ID NO:89和SEQ ID NO:90的一对引物扩增DNA片段。为了构建His-TnGalNAcT(33-421;I311Y)(由SEQ ID NO:60表示),用本文定义为SEQ ID NO:91和SEQ ID NO:92的一对引物扩增DNA片段。在PCR扩增后,用DpnI处理反应混合物以消化模板DNA,随后转化到NEB 10-β感受态细胞(获自New England Biolabs)中。分离DNA并通过对于以下突变体的序列分析来确认序列:His-TnGalNAcT(33-421;W336F)(由SEQ ID NO:50表示)、His-TnGalNAcT(33-421;W336V)(由SEQ ID NO:52表示)、His-TnGalNAcT(33-421;E339A)(由SEQ ID NO:53表示)和His-TnGalNAcT(33-421;I311Y)(由SEQ ID NO:60表示)。
表2.所用引物的序列标识。对应于突变氨基酸的密码子以粗体显示。
实施例4.His-TnGalNAcT(33-421)、His-TnGalNAcT(33-421;W336F)、His-TnGalNAcT(33-421;W336V)和His-TnGalNAcT(33-421;E339A)在大肠杆菌中的表达和重折叠
从如实施例3中所述获得的相应的pET15b构建体表达His-TnGalNAcT(33-421)、His-TnGalNAcT(33-421;W336F)、His-TnGalNAcT(33-421;W336V)和His-TnGalNAcT(33-421;E339A)。根据由Qasba等人(Prot.Expr.Pur.2003,30,219-76229,通过引用的方式纳入本文)报道的过程进行表达、包涵体分离和重折叠。重折叠后,通过离心(以8000×g离心10分钟)除去不溶性蛋白,随后通过0.45μM孔径的过滤器过滤。使用HisTrap HP 5mL柱(GEHealthcare)纯化和浓缩可溶性蛋白。首先用缓冲液A(20mM Tris缓冲液、20mM咪唑、500mMNaCl,pH 7.5)洗涤柱。用缓冲液B(20mM Tris、500mM NaCl、250mM咪唑,pH 7.5,10mL)洗脱保留的蛋白。通过SDS-PAGE在聚丙烯酰胺凝胶(12%)上分析级分,合并含有纯化的靶蛋白的级分,并通过在4℃下透析过夜,相对于20mM Tris pH 7.5和150mM NaCl交换缓冲液。使用Amicon Ultra-0.5、Ultracel-10Membrane(Millipore)将纯化的蛋白浓缩至至少2mg/mL,并在进一步使用之前储存在-80℃下。
实施例5.GalNAcT和突变体在CHO中的瞬时表达
用Evitria(苏黎世,瑞士)以20mL的量在CHO K1细胞中瞬时表达蛋白。表达以下的GalNAcT变体:CeGalNAcT(30-383)(由SEQ ID NO:6表示)、AsGalNAcT(30-383)(由SEQ IDNO:7表示)、TnGalNAcT(33-421)(由SEQ ID NO:8表示)、DmGalNAcT(47-403)(由SEQ ID NO:9表示)和TnGalNAcT(33-421;E339A)(由SEQ ID NO:28表示)。在典型的纯化实验中,将含有表达的GalNAcT的CHO产生的上清液相对于20mM Tris缓冲液(pH 7.5)透析。将上清液(通常为25mL)通过0.45μm孔径过滤器过滤,随后经阳离子交换柱(HiTrap SP HP 5mL柱,GEHealthcare)进行纯化,所述阳离子交换柱在使用前用20mM Tris缓冲液(pH 7.5)平衡。在配备有外部级分收集器的AKTA Prime色谱系统上进行纯化。从系统泵A装载样品。通过用10倍柱体积(CV)的20mM Tris缓冲液(pH 7.5)洗涤柱来从柱上洗脱未结合的蛋白。用洗脱缓冲液(20mM Tris,1NaCl,pH 7.5;10mL)洗脱保留的蛋白。通过SDS-PAGE在聚丙烯酰胺凝胶(12%)上分析收集的级分,合并含有靶蛋白的级分并使用自旋过滤浓缩至0.5mL的体积。除了TnGalNAcT(33-421;E339A)之外,接下来使用AKTA purifier-10系统(UNICORN v6.3)在Superdex200 10/300GL尺寸排阻色谱柱(GE Healthcare)上纯化蛋白以获得纯的单体级分。通过SDS-PAGE分析级分,并在进一步使用之前将含有单体蛋白的级分储存在-80℃下。
IgG的质谱分析的一般方案
在质谱分析之前,将IgG用DTT处理,这使得能够分析轻链和重链,或用Fabricator
实施例6.通过内切酶S处理制备经修剪的曲妥珠单抗。
用来自酿脓链球菌的内切酶S(可从Genovis,Lund,Sweden商购获得)进行曲妥珠单抗的聚糖修剪。因此,将曲妥珠单抗(10mg/mL)用于25mM Tris pH 8.0中的内切酶S(40U/mL)在37℃下孵育约16小时。将去糖基化的IgG浓缩,并使用Amicon Ultra-0.5,Ultracel-10Membrane(Millipore)用10mM MnCl
实施例7.在牛β(1,4)-Gal-T1的作用下,6-叠氮基-Gal-UDP糖基转移至经修剪的曲妥珠单抗
将通过如上文所述的曲妥珠单抗的内切酶S处理获得的经修剪的曲妥珠单抗(10mg/mL)用在10mM MnCl
实施例8.在牛β(1,4)-Gal-T1(130-402;Y289L,C342T)的作用下,6-叠氮基-N-乙酰半乳糖胺-UDP糖基转移至经修剪的曲妥珠单抗
使用衍生自牛β(1,4)-Gal-T1(由SEQ ID NO:1表示)的突变体,其含有Y289L和C342T突变且仅含有催化结构域(氨基酸残基130-402)。该牛β(1,4)-Gal-T1(130-402;Y289L,C342T)突变体由Qasba等人描述(J.Biol.Chem.2002,277,20833-20839,通过引用的方式纳入),并且根据Qasba等人报道的方法(Prot.Expr.Pur.2003,30,219-76229,通过引用的方式纳入)表达、包涵体分离和重折叠。将通过如上文所述的曲妥珠单抗的内切酶S处理获得的经修剪的曲妥珠单抗(10mg/mL)用在10mM MnCl
实施例9.在GalNAcT的作用下,6-叠氮基-N-乙酰半乳糖胺-UDP糖基转移至经修剪的曲妥珠单抗
测试如实施例5中所述的进行表达和纯化的CeGalNAcT(30-383)(由SEQ ID NO:6表示)、AsGalNAcT(30-383)(由SEQ ID NO:7表示)、TnGalNAcT(33-421)(由SEQ ID NO:8表示)和DmGalNAcT(47-403)(由SEQ ID NO:9表示)的6-叠氮基GalNAc掺入。将通过如上文所述的曲妥珠单抗的内切酶S处理获得的经修剪的曲妥珠单抗(10mg/mL)用在10mM MnCl
Fabricator
表3.通过不同酶浓度的GalNAcT将GlcNAc(Fuc)取代的曲妥珠单抗转化为6-叠氮基-GalNAc-GlcNAc(Fuc)取代的曲妥珠单抗的转化率(%)。
/>
方案1:化合物88-94的合成以及经修饰的糖蛋白95-96的合成(实施例10-26)
实施例10. 6-叠氮基-6-脱氧-GalNAc-1-单磷酸酯80的合成
可以根据Wang等人,Bioorg.Med.Chem.Lett.,2009,19,5433中的方法来制备乙酰化糖79。
向乙酰化糖79(4.9g,11.9mmol)在MeOH(15mL)中的悬浮液中加入25%的NH
1
实施例11. 6-氨基-6-脱氧-GalNAc-1-单磷酸酯81的合成
向叠氮化物80(5.9mmol)在H
1
实施例12. 6-(2-氯乙酰氨基)-6-脱氧-GalNAc-1-单磷酸酯82的合成
根据Hosztafi等人,Helv.Chim.Acta,1996,79,133中的方法制备氯乙酸琥珀酰亚胺酯。
在氮气气氛下,向糖81(12mg,0.040mmol)的无水DMF(0.5mL)溶液中加入氯乙酸琥珀酰亚胺酯(9mg,0.044mmol)和Et
1
实施例13. 6-(4-叠氮基苯甲酰氨基)-6-脱氧-GalNAc-1-单磷酸酯83的合成
根据Hartman等人,Chem.Comm.,2012,48,4755中的方法制备4-叠氮基苯甲酸琥珀酰亚胺酯。
在氮气气氛下,向糖81(38mg,0.127mmol)的无水DMF(1.5mL)溶液中加入Et
C
实施例14. 6-(N-2-叠氮基-2,2-二氟乙基氨基甲酸酯)-6-脱氧-GalNAc-1-单磷酸酯84的合成
根据WO2015/112016中所述的方法制备2-叠氮基-2,2-二氟乙醇。
在氮气气氛下,将2-叠氮基-2,2-二氟乙醇(200mg,1.63mmol)溶于DCM(10mL)中,加入4-硝基苯基氯甲酸酯(295mg,1.46mmol)和Et
1
实施例15. 6-(N-1-(2-叠氮基乙基)脲)-6-脱氧-GalNAc-1-单磷酸酯85的合成
根据Zhang等人,J.Am.Chem.Soc.,2015,137,6000中所述的方法制备2-叠氮基乙胺。
将羰基二咪唑(377mg,2.32mmol)溶于无水DMF(10mL)中,并在氮气气氛下搅拌。将2-叠氮基乙胺(200mg,2.32mmol)溶于无水DMF(5mL)中并滴加到CDI中。将所得溶液在室温下搅拌1h,然后加热至60℃。将糖81溶于H
1
实施例16. 6-(N-(2-S-乙酰基)巯基乙酰氨基)-6-脱氧-GalNAc-1-单磷酸酯86的合成
将糖81(105mg,0.35mmol)溶于H
1
实施例17. 6-(N-2-叠氮基乙酰胺基)-6-脱氧-GalNAc-1-单磷酸酯87的合成
将叠氮基乙酸(101mg,1.0mmol)溶于DMF(2mL)中,加入EDC(192mg,1.0mmol)、NHS(115mg,1.0mmol)和DMAP(4mg,0.03mmol)。接下来,将糖81(100mg,0.33mmol)溶于H
1
实施例18. 6-(2-氯乙酰胺基)-6-脱氧-GalNAc-UDP 88的合成
根据由Baisch等人Bioorg.Med.Chem.,1997,5,383描述的方法将单磷酸酯82与UMP偶联。
简言之,在氮气气氛下将尿苷-5'-单磷酸三丁基铵(31mg,0.06mmol)溶于无水DMF(0.5mL)中。加入羰基二咪唑(13mg,0.04mmol),将反应混合物在室温下搅拌30min。接下来,加入无水MeOH(2.5μL)并搅拌15min以除去过量的CDI。在高真空下15min除去剩余的MeOH。随后,将单磷酸酯82(15mg,0.04mmol)溶于无水DMF(0.5mL)中,加入到反应混合物中,然后加入N-甲基咪唑、HCl盐(25mg,0.16mmol)。将反应在室温下搅拌过夜,然后真空浓缩。通过MS监测单磷酸盐中间体的消耗。用离子交换色谱法(Q-HITRAP,1×5mL柱)进行纯化。通过加载缓冲液A(10mM NH
C
实施例19. 6-(4-叠氮基苯甲酰氨基)-6-脱氧-GalNAc-UDP 89的合成
根据由Baisch等人Bioorg.Med.Chem.,1997,5,383描述的方法将单磷酸酯83与UMP偶联。
简言之,在氮气气氛下将尿苷-5'-单磷酸三丁基铵(77mg,0.15mmol)溶于无水DMF(1mL)中。加入羰基二咪唑(41mg,0.25mmol),将反应混合物在室温下搅拌30min。接下来,加入无水MeOH(6.2μL)并搅拌15min以除去过量的CDI。在高真空下15min除去剩余的MeOH。随后,将单磷酸酯83(56mg,0.13mmol)溶于无水DMF(1mL)中,加入到反应混合物中,然后加入N-甲基咪唑、HCl盐(79mg,0.51mmol)。将反应在室温下搅拌过夜,然后真空浓缩。通过MS监测单磷酸盐中间体的消耗。用离子交换色谱法(Q-HITRAP,3×5mL柱,1×15mL柱)进行纯化。通过加载缓冲液A(10mM NH
C
实施例20. 6-(N-2-叠氮基-2,2-二氟乙基氨基甲酸酯)-6-脱氧-GalNAc-UDP 90的合成
根据由Baisch等人Bioorg.Med.Chem.,1997,5,383描述的方法将单磷酸酯84与UMP偶联。
简言之,在氮气气氛下将尿苷-5'-单磷酸三丁基铵(200mg,0.39mmol)溶于无水DMF(3mL)中。加入羰基二咪唑(106mg,0.65mmol),将反应混合物在室温下搅拌30min。接下来,加入无水MeOH(16μL)并搅拌15min以除去过量的CDI。在高真空下15min除去剩余的MeOH。随后,将单磷酸酯84(147mg,0.33mmol)悬浮于无水DMF(3mL)中,加入到反应混合物中,然后加入N-甲基咪唑、HCl盐(204mg,1.31mmol)。通过MS监测单磷酸盐中间体的消耗。将反应在室温下搅拌3天。将另一部分的UMP如上所述地活化,并与1mL H
C
实施例21. 6-(N-1-(2-叠氮基乙基)脲)-6-脱氧-GalNAc-UDP 91的合成
根据由Baisch等人Bioorg.Med.Chem.,1997,5,383描述的方法将单磷酸酯85与UMP偶联。
简言之,在氮气气氛下将尿苷-5'-单磷酸三丁基铵(126mg,0.25mmol)溶于无水DMF(2mL)中。加入羰基二咪唑(67mg,0.41mmol),将反应混合物在室温下搅拌30min。接下来,加入无水MeOH(10μL)并搅拌15min以除去过量的CDI。在高真空下15min除去剩余的MeOH。随后,将单磷酸酯85(85mg,0.21mmol)溶于无水DMF(2mL)中,加入到反应混合物中,然后加入N-甲基咪唑、HCl盐(129mg,0.82mmol)。将反应在室温下搅拌2天,然后真空浓缩。通过MS监测单磷酸盐中间体的消耗。用离子交换色谱法(Q HITRAP,3×5mL柱,1×15mL柱)进行纯化。通过加载缓冲液A(10mM NH
C
实施例22. 6-(N-(2-S-乙酰基)-巯基乙酰胺基)-6-脱氧-GalNAc-UDP 92的合成
根据由Baisch等人Bioorg.Med.Chem.,1997,5,383描述的方法将单磷酸酯86与UMP偶联。
简言之,在氮气气氛下将尿苷-5'-单磷酸三丁基铵(139mg,0.27mmol)溶于无水DMF(2mL)中。加入羰基二咪唑(74mg,0.46mmol),将反应混合物在室温下搅拌30min。接下来,加入无水MeOH(11μL)并搅拌15min以除去过量的CDI。在高真空下15min除去剩余的MeOH。随后,将单磷酸酯86(95mg,0.27mmol)溶于无水DMF(2mL)中,加入到反应混合物中,然后加入N-甲基咪唑、HCl盐(142mg,0.91mmol)。将反应在室温下搅拌3天,然后真空浓缩。通过MS监测单磷酸盐中间体的消耗。用快速色谱(7:2:1-4:2:1EtOAc:MeOH:H
C
实施例23. 6-(2-叠氮基乙酰氨基)-6-脱氧-GalNAc-UDP 93的合成
根据由Baisch等人Bioorg.Med.Chem.,1997,5,383描述的方法将单磷酸酯87与UMP偶联。
简言之,在氮气气氛下将尿苷-5'-单磷酸三丁基铵(191mg,0.38mmol)溶于无水DMF(3mL)中。加入羰基二咪唑(102mg,0.63mmol),将反应混合物在室温下搅拌30min。接下来,加入无水MeOH(16μL)并搅拌15min以除去过量的CDI。在高真空下15min除去剩余的MeOH。随后,将单磷酸酯87(120mg,0.31mmol)溶于无水DMF(3mL)中,加入到反应混合物中,然后加入N-甲基咪唑、HCl盐(195mg,1.25mmol)。通过MS监测单磷酸盐中间体的消耗。将反应在室温下搅拌16h。为了溶解反应物中的所有组分,加入1mL H
C
实施例24. 6-氨基-6-脱氧-GalNAc-UDP 94的合成
向6-叠氮基-GalNAc-UDP(25mg,0.04mmol)的H
C
实施例25.本妥昔单抗–(6-氨基-6-脱氧-GalNAc),95的制备
类似于实施例6中所述的对曲妥珠单抗的修剪来修剪本妥昔单抗。
将经修剪的本妥昔单抗(15mg/mL)用在10mM MnCl
实施例26.本妥昔单抗-(6-(2-叠氮基乙酰氨基)-6-脱氧-GalNAc),96的制备
将经修剪的本妥昔单抗(15mg/mL)用10mM MnCl
- 用为或衍生自β-(1,4)-N-乙酰半乳糖胺转移酶的糖基转移酶修饰糖蛋白的方法
- 用为或衍生自β‑(1,4)‑N‑乙酰半乳糖胺转移酶的糖基转移酶修饰糖蛋白的方法