一种用户兴趣点推荐方法及装置
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及兴趣点推荐领域,特别是涉及一种用户兴趣点推荐方法及装置。
背景技术
现有的基于深度学习的POI(兴趣点)推荐方案主要包括:基于RNN(循环神经网络)、基于LSTM(长短期记忆网络)、基于注意力机制、基于graph embedding(图嵌入)的方案。其中,主流方法是基于LSTM和基于注意力机制的方法。
在基于LSTM的方法中,有方法对基于用户签到的时空信息,将时间门和距离门引入LSTM单元中,用以捕捉连续签到点的时空信息。一个时间门和一个距离门用以更新用户的短期兴趣,另外的时间门和距离门用来更新用户的长期兴趣。也有方法利用两个时间门和两个距离门分别模拟用户的长期偏好和短期偏好,并将原始LSTM中的输入门和输出门进行融合。为了更好地利用地理因素对POI预测的影响,有方法提出一个两阶段模型:兴趣点嵌入和连续签到行为建模。在兴趣点嵌入阶段,用相似度树对所有兴趣点进行分类,并运用Word2Vec模型(一群用来产生词向量的相关模型)得到兴趣点的嵌入向量;在序列建模阶段,所有的签到序列信息被送入LSTM单元中建模连续签到行为。
在基于注意力机制的方法中,有方法提出一个包含内容编码层和用户行为层的模型,内容编码层使用CNN和多头注意力,以及POI嵌入,捕获用户对POI各个角度的感兴趣程度。用户行为层使用Bi-LSTM(双向长短期记忆网络),最后多头输出来完成预测。也有方法设计一种基于LSTM单元的编码-解码框架自适应的学习深度时空表示,并用嵌入技术以一个统一的方式融合上下文信息。有方法在RNN中引入空间注意力机制增强了序列数据的上下文信息约束,在连续签到点中,从用户的时间间隔和地理距离权衡兴趣点的重要性,其中的空间注意力层基于距离捕获过去和未来兴趣点之间的地理相关性,并用贝叶斯成对算法进行排序。
但现有的兴趣点推荐方法还存在用户隐私数据泄露风险较大的问题。隐私泄露不仅对个人用户造成严重影响,也会对企业造成重大的经济和信誉损失,甚至影响社会稳定。
发明内容
本发明的目的在于解决在推荐用户兴趣点的同时保护用户隐私的技术问题,提出了一种用户兴趣点推荐方法及装置。
本发明的技术问题通过以下的技术方案予以解决:
一种用户兴趣点推荐方法,包括如下步骤:
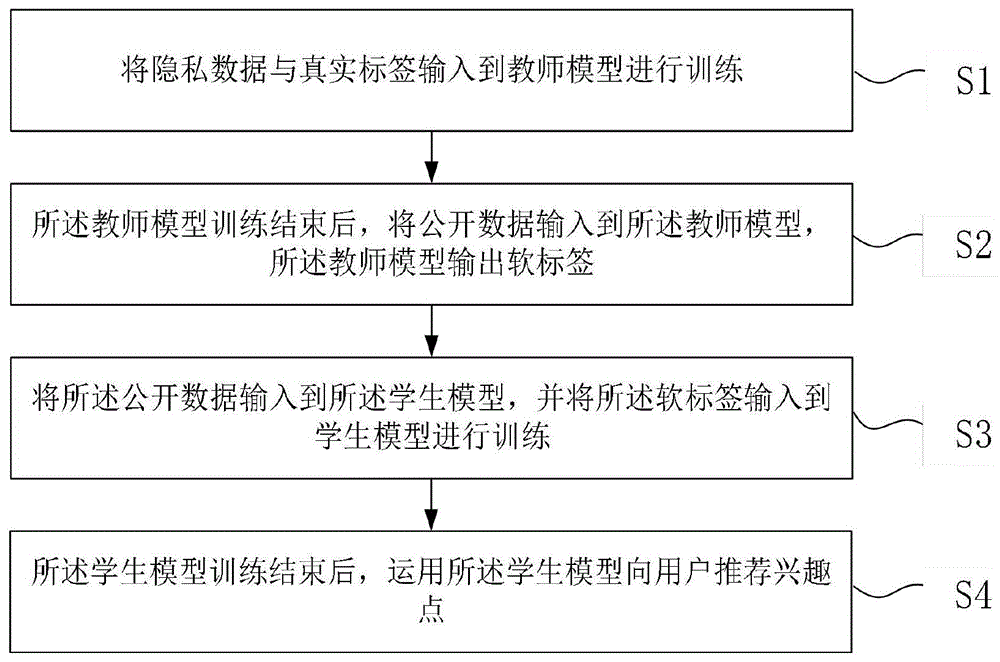
S1:将隐私数据与真实标签输入到教师模型进行训练;
S2:所述教师模型训练结束后,将公开数据输入到所述教师模型,所述教师模型输出软标签;
S3:将所述公开数据输入到所述学生模型进行训练,并将所述软标签输入到学生模型进行训练;
S4:所述学生模型训练结束后,运用所述学生模型向用户推荐兴趣点。
在一些实施例中,所述教师模型包括嵌入编码模块,时间编码器模块和空间增强编码器模块,其中,
所述嵌入编码模块将隐私数据编码为用户总体偏好的初步表征,并将所述初步表征传递到Transformer网络;
所述时间编码器模块捕捉所述初步表征的时间依赖性;
所述空间增强编码器模块捕捉所述初步表征的空间-时间的依赖性。
在一些实施例中,在步骤S1中,输入教师模型的隐私数据包括每条用户历史到访序列中的兴趣点ID、时间信息、坐标信息,所述坐标信息包括访问地点经度和访问地点纬度信息;
使用四叉树键值算法将所述用户历史到访序列中的坐标信息转换成空间ID;
所述时间信息包括日期数据和小时数据,使用离散化的方法编码所述时间信息,所述日期数据以周为区间映射成0-6,所述小时数据以日为区间映射成0-23,将所述日期数据和所述小时数据拼接得到时间ID。
在一些实施例中,使用全连接层将所述兴趣点ID、空间ID和时间ID转换成低维稠密向量,所述低维稠密向量包括兴趣点向量、空间向量和时间向量,将所述兴趣点向量、空间向量和时间向量拼接来表示用户历史到访序列中每条记录的嵌入降维。
在一些实施例中,所述时间编码器模块使用Transformer网络捕捉所述初步表征长期和短期偏好的时序依赖性,所述Transformer网络中的多头关注机制能够提取多通道特征,并捕捉长距离的依赖关系。
在一些实施例中,所述空间增强编码器模块将嵌入编码模块的空间嵌入
Q′=K′=V′=S
其中,“Q'”、“K'”、“V'”是空间嵌入转换时的中间变量;“Q”、“K”、“V”是时间编码器输出结果转换时的中间变量;
最终在输出的第一个用户偏好表征可以用来表示用户的全局偏好,所述教师模型使用一次全连接层的线性变换将用户偏好的表征矩阵中用来分类的向量表征映射成到访下一兴趣点的概率。
在一些实施例中,所述学生模型包括嵌入编码模块和时间编码器模块。
在一些实施例中,所述软标签为预测概率向量,编码了教师模型所包含的类别信息和类别关系信息。
本发明还提供了一种兴趣点推荐装置,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现上述的兴趣点推荐方法。
本发明还提供了一种存储介质,所述存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述存储介质所在设备执行上述的兴趣点推荐方法。
本发明具有如下有益效果:
本发明提出的用户兴趣点推荐方法通过教师模型利用隐私数据和公开数据进行训练,而学生模型仅利用公开数据进行训练等技术特征的设置,能够实现充分利用教师-学生蒸馏框架中教师模型知识被学生模型吸收的特性,学生模型在不直接使用教师模型训练数据(隐私数据)的情况下完成训练,实现了学生模型和隐私数据的隔离,可以有效应对深度学习模型的反向推演攻击;又因为对学生模型进行反演攻击只能获得学生模型的训练输入分布,而无法获得原始教师模型的训练数据分布,即使有被攻击的风险,也不会造成隐私数据的泄露,从而实现了对用户隐私数据的保护。
此外,在一些实施例中,还具有如下有益效果:
本发明的一些实施例中,通过在学生模型中去除空间增强编码器模块、软标签编码等技术特征的设置,学生模型在推广到线上使用进行运算推理时,能够在保持性能的情况下实现压缩模型、提高计算效率、减少运算成本的效果。同时,软标签编码也有助于提高学生模型在外部数据集上的泛化能力,同时增强学生模型对扰动攻击的抵抗能力。
本发明实施例中的其他有益效果将在下文中进一步述及。
附图说明
图1是本发明实施例中一种用户兴趣点推荐方法的流程图;
图2是本发明实施例中用户兴趣点推荐系统的示意图。
具体实施方式
下面对照附图并结合优选的实施方式对本发明作进一步说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
需要说明的是,本实施例中的左、右、上、下、顶、底等方位用语,仅是互为相对概念,或是以产品的正常使用状态为参考的,而不应该认为是具有限制性的。
POI预测任务是指通过融合用户上传的社交网络及地理位置信息,基于用户历史位置数据建立模型,并预测用户下一个可能到访的POI。举例来说,一名用户近一年在本地生活类手机软件上传过40次签到记录,这些签到记录包括用户ID、地理位置、时间、POI名称、POI类别等信息,那么POI预测模型可以通过这些签到数据来预测用户下次可能想去的POI,进而丰富用户的选择。
目前在POI预测任务中还没有考虑到保护用于模型训练的用户隐私数据的方案,因此攻击者可以通过反向推演等方法攻击模型来得到训练数据的分布和统计特征,进而获取用户隐私数据,数据泄露风险较大。本发明实施例提出了一种在隐私保护的条件下,基于知识蒸馏的POI预测方法:设计一种教师-学生蒸馏框架,教师模型利用隐私数据和公开数据进行训练,而学生模型仅利用公开数据进行训练。学生模型提升在外部数据集上泛化能力的同时,也增强了对扰动攻击的抵抗能力。
本发明实施例在保护训练数据隐私安全的前提下训练深度学习模型,同时尽可能保持原有深度学习模型的性能。本实施例基于知识蒸馏技术,知识蒸馏的核心思想在于设计有效的方法,将知识从教师模型迁移至学生模型。由于经过知识蒸馏所获得的学生模型在结构/参数上和教师模型有较大区别,因此对学生模型进行反演攻击只能获得学生模型的训练输入分布,而无法获得原始教师模型的训练数据分布,这就使得知识蒸馏被大量应用于隐私保护任务。
以下是对本发明实施例的概述:
一种用户兴趣点推荐方法,包括如下步骤:
S1:将隐私数据与真实标签输入到教师模型进行训练;
其中教师模型包括嵌入编码模块,时间编码器模块和空间增强编码器模块,其中,
嵌入编码模块将隐私数据编码为用户总体偏好的初步表征,并将初步表征传递到Transformer网络;
时间编码器模块捕捉初步表征的时间依赖性;
空间增强编码器模块捕捉初步表征的空间-时间的依赖性。
具体的步骤S1实施如下:
通过隐私数据获取兴趣点ID、空间ID、时间ID包括如下步骤:
兴趣点ID:输入教师模型的隐私数据包括每条用户历史到访序列中的兴趣点ID、时间信息、坐标信息,坐标信息包括访问地点经度和访问地点纬度信息。
空间ID:使用四叉树键值算法将用户历史到访序列中的坐标信息转换成空间ID。
时间ID:用户历史到访序列中的时间信息包括日期数据和小时数据,使用离散化的方法编码时间信息,日期数据以周为区间映射成0-6,小时数据以日为区间映射成0-23,将日期数据和小时数据拼接得到时间ID。
之后使用全连接层将兴趣点ID、空间ID和时间ID转换成低维稠密向量,低维稠密向量包括兴趣点向量、空间向量和时间向量,将兴趣点向量、空间向量和时间向量拼接来表示用户历史到访序列中每条记录的嵌入降维。
时间编码器模块使用Transformer网络捕捉初步表征长期和短期偏好的时序依赖性,Transformer网络中的多头关注机制能够提取多通道特征,并捕捉长距离的依赖关系,时间编码器输出
空间增强编码器模块将嵌入编码模块的空间嵌入
/>
Q′=K′=V′=S
其中,“Q'”、“K'”、“V'”是空间嵌入转换时的中间变量;“Q”、“K”、“V”是时间编码器输出结果转换时的中间变量;
最终在输出的第一个用户偏好表征可以用来表示用户的全局偏好,教师模型使用一次全连接层的线性变换将用户偏好的表征矩阵中用来分类的向量表征映射成到访下一兴趣点的概率。
S2:教师模型训练结束后,将公开数据输入到教师模型,教师模型输出软标签;
S3:将公开数据和软标签输入到学生模型进行训练,并将软标签输入到学生模型进行训练;
其中学生模型包括嵌入编码模块和时间编码器模块;软标签为预测概率向量,编码了教师模型所包含的类别信息和类别关系信息。
S4:学生模型训练结束后,运用学生模型向用户推荐兴趣点。
本发明实施例还提出了一种兴趣点推荐装置,包括处理器、存储器以及存储在存储器中且被配置为由处理器执行的计算机程序,处理器执行计算机程序时实现上述的兴趣点推荐方法。
本发明实施例还提出了一种存储介质,存储介质包括存储的计算机程序,其中,在计算机程序运行时控制存储介质所在设备执行上述的兴趣点推荐方法。
实施例:
当给定一段用户签到历史记录,本实施例的目标是隐私保护的条件下求出用户下一个可能到访的POI。通过基于transformer架构(编码器-解码器架构的一种变体)的教师-学生知识蒸馏框架来帮助解决这一问题。
本发明实施例中的用户兴趣点推荐方法如图1所示,包括如下步骤:
S1:将隐私数据与真实标签输入到教师模型进行训练;
S2:教师模型训练结束后,将公开数据输入到教师模型,教师模型输出软标签;
S3:将公开数据和软标签输入学生模型进行训练,并将软标签输入到学生模型进行训练;
S4:学生模型训练结束后,运用学生模型向用户推荐兴趣点。
本发明实施例中的用户兴趣点推荐系统框架:
用户兴趣点推荐系统框架如图2所示,用户兴趣点推荐系统框架主要包含教师模型和学生模型两部分,两部分的模型主体都是基于Transformer编码器。教师模型是预先训练的模型,学生模型根据教师模型输出的软标签进行训练。
知识蒸馏的训练过程分为两个阶段:
(1)在蒸馏之前,重量级的教师模型首先在完整训练样本上进行训练。
(2)在蒸馏过程中,从教师模型中抽取输出层的知识,然后使用这些知识指导学生模型的训练。
下面对教师模型和学生模型进行详细介绍:
教师模型:
教师模型包含三个主要模块,包括嵌入编码模块,时间编码器和空间增强编码器。
在嵌入编码模块中,教师模型将原始隐私数据编码为用户总体偏好的初步表征,并将其传递给Transformer网络。其中隐私数据包括每条用户历史到访序列中的兴趣点ID、时间信息、坐标信息,其中坐标信息包括访问地点经度和访问地点纬度信息。
在时间编码器中,教师模型捕捉偏好初步表征的时间依赖性。
在增强的空间增强编码器中,教师模型利用空间嵌入来增强用户偏好初步表征中的空间信息,并捕捉空间-时间的依赖性。
最后输出的用户偏好初步表征被用来表示用户对POI的总体偏好,并预测下一个可能到访的POI。
在嵌入编码模块中,用户历史到访序列被一个统一模型用同样的方式进行初步编码得到embedding(嵌入降维)。
对于用户u来说,用户历史到访序列记录
其中p
对于每条坐标信息lon
不同于之前工作直接对经纬度数据(包括访问地点经度和访问地点纬度信息)做离散化,Quadkey索引算法将一块二维平面区域均分,将每个图块用一个Quadkey表示,得到Spatial ID。
Quadkeys具有以下两个特点:
(1)Quadkey的长度(位数)等于相应图块的缩放级别,本工作采用14位长度。
(2)Quadkeys提供的一维索引键通常保留图块在XY空间中的邻近性。换句话说,如果两个图块的XY坐标相邻,通常它们的Quadkeys也相对接近。
对于每条时间信息t
将以上高维的离散ID(兴趣点ID,时间ID,空间ID)转换成one-hot向量(一种状态编码)后,通过全连接层转换为低维稠密向量,包括POI向量
最后将三者拼接来表示用户历史到访序列中每条记录的嵌入降维,即embedding:
时间编码器模块利用一个统一的Transformer编码器捕捉长期和短期偏好的时序依赖。Transformer网络中的多头关注机制可以有效地提取多通道特征,并捕捉长距离的依赖关系,这有助于模型提炼出用户的全局兴趣。
其中时间编码器的输出
E
Q=K=V=E
其中Eu’是Eu通过多头注意力机制、加和与规范化操作之后转换而成的;Q、K、V在多头注意力机制的算法中,分别表示query、key和value,且三者相等;l=LNo(.)表示LayerNorm(层规范),FFN(.)表示全连接前馈网络,MulH(.)表示多头注意力机制。
在教师模型中时间编码器仅仅对时间维度上的依赖进行建模,空间信息关注较少,因此输出的
Q′=K′=V′=S
其中Q`、K`、V`是空间嵌入转换时的中间变量;Q、K、V是时间编码器输出结果转换时的中间变量。
最终在输出的第一个用户偏好表征可以用来表示用户的全局偏好,模型利用一次全连接层的线性变换将用户偏好的表征矩阵中用来分类的向量[CLS]表征映射成到访下一POI的概率。
学生模型:
学生模型的目的将教师模型学到的知识蒸馏到自身模型中,本实施例学生模型的主体采用与教师模型嵌入编码模块和时间编码器相同的结构,相较于教师模型去除了空间增强编码器模块,因此学生模型在推广到线上使用进行运算推理时,可以减少大量计算成本,实现模型轻量化。
学生模型的输入与教师模型不同。在学生模型训练之前,教师模型已经在隐私的训练数据上全监督训练完成。教师模型的输入是True Label(真实标签:隐私数据中需要预测每位用户历史数据中最新一条记录的POI。这项POI的ID即真实标签。)。而在知识蒸馏过程中,教师模型和学生模型均用无标签的公开数据进行训练,教师模型将输出的预测概率向量传递给学生模型作为输入,即Soft Lable(软标签)。这种类别预测概率向量被称为知识。知识蒸馏过程所采用的软标签编码了教师模型所包含的类别信息和类别关系信息。
学生模型的学习目标是使得预测概率结果逼近软标签,利用对数损失函数作为蒸馏损失函数,使得最终训练得到的学生模型能够达到和教师模型相近的性能,输出所有POI的预测概率。此外,软标签编码也有助于提高学生模型在外部数据集上的泛化能力,同时增强学生模型对扰动攻击的抵抗能力。
在知识蒸馏结束后,如果学生模型的性能满足要求,则可以将学生模型推广上线。此时线上运行的模型由于是用公开数据集进行训练的,即使有被攻击的风险,也不会造成隐私数据的泄露,实现了对用户隐私数据的保护。
实验例:
用户A在某app(应用程序)上共上传12条隐私数据记录,第一条记录包括如下信息:
时间2022.8.14,到访POI ID 456437,经度113°46′,纬度22°52′;剩余的隐私数据记录格式相同。隐私数据记录分别被编码成:POI向量
之后通过拼接得到用户总体偏好的初步表征用来表示该用户偏好的嵌入向量。教师模型对这些隐私记录的训练完成后,进行知识蒸馏过程。
教师模型和学生模型均用无标签的公开数据进行训练,教师模型将输出的预测概率向量传递给学生模型作为输入,学生模型的学习目标是使得预测概率结果逼近软标签,使得最终训练得到的学生模型能够达到和教师模型相近的性能。
最后将学生模型运用于线上的运算推理。
(1)通过实验分别统计教师模型与学生模型在全部测试数据上的推理时间,结果如下:教师模型294秒;学生模型167秒。
(2)学生模型相较于教师模型去除了空间增强编码器模块,因此该部分的参数计算被省去,减少了大量计算成本。
本实验例具有如下有益效果:
(1)本实验例采用的教师-学生蒸馏框架可以保障学生模型在不直接使用教师模型的训练数据的情况下完成模型训练,实现了学生模型和训练数据的隔离,因此可以有效应对深度学习模型的反向推演攻击,保护了训练数据的隐私安全。
(2)知识蒸馏使得学生模型可以学习到教师模型中的表征用户偏好的知识,在保持性能的情况下实现了压缩模型的效果,提高计算效率,减少运算成本。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 一种基于用户兴趣的电影推荐方法及其装置
- 一种取件点地址推荐方法及装置
- 用户兴趣点权重确定方法及装置、存储介质和电子设备
- 一种基于推荐系统的项目推荐方法、装置及设备
- 根据用户兴趣点/关注点进行个性化推荐的方法和系统
- 根据用户兴趣点/关注点进行个性化推荐的方法和系统