基于多尺度特征聚合的场景图像文字检测方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及场景文本内容理解过程中的文字检测技术领域,尤其涉及一种基于多尺度特征聚合的场景图像文字检测方法。
背景技术
场景图像文字检测,是指对场景文本图片上的文字进行检测定位,获取到文字在图像中的具体位置。其中,自然场景的图片是指生活中的各种各样的场景图像,比如商品包装、门店招牌、菜单、车辆、屏幕和海报。场景文字检测是文字信息提取的第一步,在文字内容理解领域有着广泛的应用和研究前景。
受到通用的目标检测方法的启发,现有的场景文本检测器通过修改通用目标检测器的区域提议和边界框回归模块来直接定位文本实例。例如,TextBoxes文本检测方法使用一阶段的通用目标检测方法SSD,把默认框更改为适应文本的具有不同宽高比的四边形;RRPN模型将旋转因素并入经典区域候选网络,将一个文本区域表示为具有5元组(x,y,h,w,θ)的旋转边框,其中(x,y)表示边框的几何中心,h表示边框的短边,w为长边,θ是长边的方向。相比于通用物体,文本行长度、长宽比例变化范围很大。当文本图像中存在弯曲,定向或长文本时,模型的性能较差。此外,该类方法以单尺度图像作为输入,受限于感受野的大小,不能很好的检测出小字的位置区域。
目前基于分割的方法在场景文本检测领域很流行,基于分割的方法先在像素层面做分类,判别每一个像素点是否属于一个文本目标,再将相邻像素结果整合为一个文本框,该方法可以较好的适应弯曲的文本。但基于分割的方法需要复杂的后处理将像素级别的结果组合成文字行,在预测时开销往往很大。此外,该类方法需要额外设计相邻文字间的操作,否则容易出现文字黏连的现象。
现阶段也有文本检测方法采用了特征聚合的策略来提升文字检测模型的性能。一种策略对文本图像进行不同尺度的缩放,之后利用独立的检测模型对文字进行检测,将每个尺度的检测结果进行合并得到最后的文字检测结果。另一种策略如图1所示,特征提取模型从场景文本图像中获取多尺度的特征,最后对多尺度特征进行操作得到最终的文本检测结果。策略1提及的文本检测方法需要独立的检测模型得到每一个尺度的检测结果,最后对结果进行聚合,模型参数较大,比较冗余;策略2的方法,图像特征来自于同一尺度的文本图像,特征比较单一,检测结果比较容易遗漏部分文字。
发明内容
本发明提出了一种基于多尺度特征聚合的场景文字检测方法,主要缓解现阶段场景文本检测方法不能很好的处理弯曲文字,容易遗漏小字,后处理操作繁琐以及文字黏连的问题。
本发明的技术方案具体介绍如下。
本发明提供一种基于多尺度特征聚合的场景文字检测方法,其基于场景文字检测模型进行检测,所述场景文字检测模型包括特征提取模块、堆叠的基于Transformer的编码器和基于Transformer的解码器;具体步骤如下:
(1)对原始场景文本图像进行不同尺度的缩放;
(2)利用特征提取模块对不同尺度的图像进行特征表示的提取,同时从最大尺度的图像中获取文字嵌入表示;
(3)将不同尺度的图像特征表示连同位置编码一起输入堆叠的基于Transformer的编码器中,输出得到加强的多尺度图像特征表示;
(4)将文字嵌入表示与加强的多尺度图像特征表示进行可变注意力计算,更新得到具有更丰富特征的文字嵌入表示;
(5)初始化一组查询向量,同时将加强的多尺度图像特征表示恢复到二维图像特征,之后将查询向量、二维图像特征以及更新的文字嵌入表示一起输入基于Transformer的解码器中,输出得到更新的具有文字特征表示的查询向量;
(6)基于更新的查询向量与更新的文字嵌入表示计算得到文字掩码,再经过后处理操作得到检测结果。
本发明中,步骤(2)中,特征提取模块由ViT模块,多个卷积层或者多个残差卷积块实现。
本发明中,步骤(3)中,每个Transformer的编码器单元包含一个多尺度可变形注意力模块和一个前向计算模块。
本发明中,步骤(6)中,文字掩码计算公式如下:
其中,M
本发明中,步骤(6)中,后处理操作具体为:利用非极大抑制算法过滤重复的文字掩码以及区域太小的掩码。
本发明中,场景文字检测模型训练时,损失函数L由掩码损失函数L
各个损失计算如下:
其中,N和K是查询向量的数量和采样的位置,
其中l
和现有技术相比,本发明的有益效果在于:多尺度的场景图像可以提供丰富的特征表示,相比于传统的基于单尺度的图像文本检测方法能够提升对小字的检测性能;设计了文字嵌入表示更新策略,能够更好的表示图像文本特征,进一步提升检测模型的性能;查询向量与更新的文字嵌入表示计算得到一系列的文本掩码,能够缓解文字黏连问题;相比于传统的文本检测方法需要对检测结果进行额外的计算处理,本发明仅仅需要过滤重复的文字掩码以及区域太小的掩码,后处理简单。
附图说明
图1:特征聚合策略2。
图2:场景图像文字检测结果图。
图3:基于多尺度特征聚合的场景文字检测方法。
图4:多尺度图像特征表示的加强与文字嵌入表示的更新流程图。
图5:解码过程图。
图6:最终结果获取过程。
具体实施方式
下面结合附图和实施例对本发明的技术方案进行详细介绍。
本发明中,基于场景文字检测模型对场景文字检测,场景文字检测模型包括特征提取模块、基于Transformer结构的编码器和解码器。
具体实施例中,先按照以下步骤训练场景文字检测模型:
1)对输入的文本图像进行不同尺度的缩放,缩放因子分别为{1/2,1,2},缩放的图像分别表示为{I
2)特征提取模块对不同尺度的文本图像进行特征表示的提取。具体操作为:将输入图像I∈R
3)将多尺度特征表示{X
4)加强的多尺度特征表示{X’
5)给定一组查询向量Q。对于第t个查询向量,利用加强的文字嵌入表示E与加强的特征嵌入表示{X’
/>
其中,sigmoid指sigmoid激活函数,MLP则用来增强特征Q
最后对掩码进行后处理得到最后的文本实例。
模型的损失函数L由掩码损失函数L
其中,N和K是查询向量的数量和采样的位置,
其中l
场景文字检测结果的可视化效果图如图2所示。
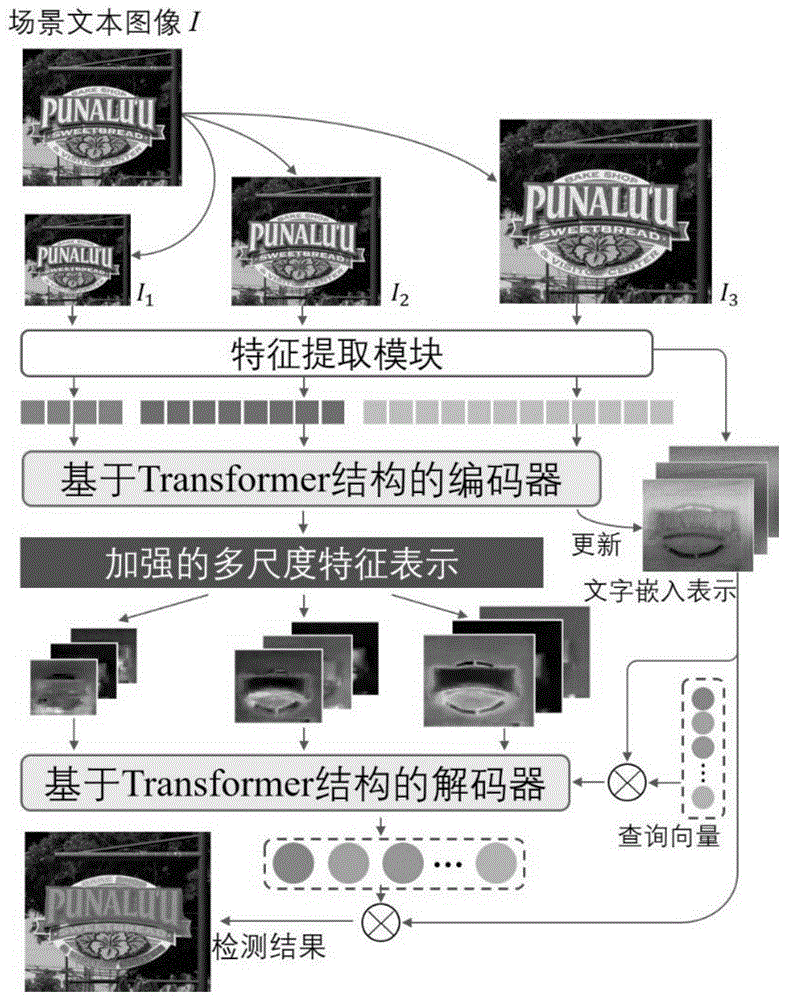
进一步基于训练好的场景文字检测模型对场景文字进行检测的主要流程如图3所示,详细步骤如下所示:
1)对原始文本图像进行不同尺度的缩放,得到不同尺度的文本图像,缩放因子分别是{1/2,1,2};
2)将缩放的文本图像输入特征提取模型,获取不同尺度的图像特征表示,同时也生成文字嵌入表示;
3)将多尺度文本图像特征表示连同位置编码一起输入堆叠的基于Transformer结构的编码器中,得到加强的多尺度特征表示;如图4所示,将多尺度文本图像特征聚合后输入基于Transformer的编码器中,主要对图像特征进行可变性注意力计算,将计算输出的结果与输入的多尺度图像特征进行相加和归一化操作,之后对相加归一化的结果输入前向计算模块,最后对前向计算模块的输入与输出进行相加与归一化操作,得到加强的图像特征表示;
4)利用加强的多尺度特征表示更新文字嵌入表示,使得文字嵌入表示的特征更加丰富;如图4所示,在文字嵌入表示更新部分,对输入的文字嵌入表示进行扁平化操作并加入位置编码,并将其与加强的图像特征表示输入多尺度可变卷积模块,经过相加、归一化、卷积以及相加计算之后,得到更新的文字嵌入表示;
5)对加强的多尺度特征表示进行重塑,得到二维的特征图;同时初始化一组查询向量,连同更新的文字嵌入表示一起输入基于Transformer的解码器中,经过多次迭代更新得到具有文字表示的查询向量,解码过程如图5所示。对尺度1的二维特征图进行扁平化操作,输入基于Transformer的解码器中,同时查询向量经过MLP操作与更新的文字嵌入表示进行相乘及阈值处理得到文字掩码。相似地,对尺度2、尺度3的二维图像特征进行相应的处理,迭代更新查询向量。
6)将更新后的查询向量与文字嵌入表示计算得到文字掩码,并对文字掩码进行后处理得到最后的文本实例结果,结果获取的过程如图6所示。对最后更新得到的查询向量进行MLP操作后与更新的文字嵌入表示进行相乘及阈值处理得到文字掩码。最后对文字掩码进行后处理操作,过滤重复的文字掩码以及区域太小的掩码得到最后的检测结果。
本发明在公开数据集(Total-Text、CTW1500以及MSRA-TD500)上对场景文本检测性能进行了评测,本发明的文本检测性能优于现有的公开文本检测方法。具体地,本发明提出方法在Total-Text数据集上准确率达到了91.9%,召回率达到了88.3%,F1指标达到了90.1%;在CTW1500数据集上准确率达到了89.7%,召回率达到了87.9%,F1指标达到了88.8%;在MSRA-TD500数据集上准确率达到了91.3%,召回率达到了90.5%,F1指标达到了90.9%。
- 一种自然场景图像敏感文字的检测识别方法
- 一种基于多尺度特征卷积神经网络的图像场景分类方法
- 基于多模型和多尺度特征的图像场景分类方法