基于深度强化学习的动态试飞任务规划方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及的是一种飞机制造领域的技术,具体是一种基于深度强化学习的动态试飞任务规划方法。
背景技术
试飞任务规划问题作为一类NP难问题,存在三大类求解算法。第一类为精确算法,此类方法可以求出结构化的组合优化问题的最优解,例如,分支定界法、数学规划法等。精确方法是一类完备的优化问题求解方法,但精确方法在解决大规模问题时效率低下。启发式算法,是一种基于直观或经验构造的面向问题的方法,在实际应用时,通常根据一定规则,逐步进行搜索生成任务执行的方案。启发式算法简单、直观易实现,提高算法的效率,容易陷入局部最优。元启发式算法,在仿生学的启发下,从自然界中的随机现象中获取灵感。典型的算法有蚁群算法,遗传算法等。元启发式算法虽然可以一种可以在一定时间内得到一个近似最优解,但在实时问题中,由于其差的泛化性导致在系统每次发生变化的情况下都需要重新计算,计算成本会随着系统的复杂程度的提高大幅度增加。因此为同时平衡全局性和计算效率,为满足实际试飞执行过程的要求,需要发明一种能够快速响应动态事件并在可接受的时间内生成可行有效的任务规划方案的方法。
发明内容
本发明针对现有技术存在的上述不足,提出一种基于深度强化学习的动态试飞任务规划方法,针对三种常见的动态事件建立针对试飞任务规划问题的马尔可夫决策过程模型,使得深度学习方法适用于解决动态试飞任务规划问题的同时,设计相应的状态特征、动作策略以及奖励函数并结合多种启发式规则作为动作策略,既保证算法的计算效率,也可以提高启发式规则的全局最优能力,显著优化试飞周期和任务延期度。
本发明是通过以下技术方案实现的:
本发明涉及一种基于深度强化学习的动态试飞任务规划方法,包括:
步骤1、以同时最小化试飞周期和任务延期度为目标,构建试飞任务规划问题模型:针对m架试验机AC={AC
所述的试飞任务,受到以下动态事件影响而更新,包括:
1)任务的试飞时长改变:随着试飞试验的进行,一些任务的试飞时长可能会由于初始评估不准确或技术/人为因素而发生变化。
2)无效的任务测试结果:任务测试结果无法确认,无效的任务将不会从未完成的飞行任务集中删除。
3)飞机停飞:飞机故障或支持设备故障将导致飞机停飞以进行维修。
步骤2、构建试飞任务选择规则和驾机安排的启发式规则;
所述的试飞任务选择规则包括:
1)选择具有最早完成时间最小值的任务:对于任务T
2)选择前向等级和最早开始时间之和最小的任务:对于任务T
3)选择具有后向等级最小值的任务:对于任务T
4)选择前向等级和后向等级之和最小的任务。
所述的驾机安排的启发式规则包括:
a)选择具有最早空闲时间的驾机。
b)选择驾机利用率最小的驾机:驾机k在时刻t的利用率为:
c)随机选择可兼容的驾机。
步骤3、定义包括试验驾机特征信息、系统特征信息和未完成任务特征信息的试飞任务规划环境的状态信息。
所述的试验驾机特征信息包括:
1)试验架机数量m;
2)试验驾机平均利用率
3)试验驾机利用率标准差
所述的系统特征信息包括:
1)未完成任务比率
2)未完成任务时间比率
3)未完成任务中存在完成时间节点的比率
4)实际延迟任务比率
5)预计延迟任务比率
6)就绪任务比率
7)紧急任务比率
所述的未完成任务特征信息包括:
1)平均前向等级
2)前向等级标准差
3)平均后向等级
4)后向等级标准差
5)平均后置科目数
6)后置科目数标准差
步骤4、定义基于规划目标的奖励函数,具体包括:
步骤5、建立基于决策-评价的近端策略优化(PPO)模型,利用训练数据对优化模型进行训练后,在线动态规划试飞任务;其中决策网络和评价网络均为非线性神经网络近似器构成,决策网络π(s
所述的策略,其更新的变化率
所述的优势函数,通过广义优势估计器(GAE)逼近其估计值
所述的近端策略优化模型,通过以下方式进行训练:产生N组(s
本发明涉及一种实现上述方法的系统,包括:试飞环境信息单元、近端策略优化单元和执行单元,其中:试飞环境信息单元采集若干试飞任务信息,试验机信息以及任务执行情况的信息;近端策略优化单元利用试飞环境信息单元提供的训练数据对优化模型进行训练;训练后的得到的优化策略在部署在执行单元以实现根据不同的环境状态进行决策,在线动态规划试飞任务。
所述的试飞任务信息包括:任务编号、任务名称、任务执行时长、前置任务集合、任务准备到位时间、兼容试验机集合。
所述的试验机信息包括:试验机的出厂时间,利用率以及故障信息。
所述的任务执行情况包括:已经执行任务的开始与结束时间,驾机安排与任务执行结果是否通过信息。
技术效果
本发明提出深度强化学习解决动态试飞任务规划问题的框架,针对动态试飞任务规划问题,实时根据试飞环境对试飞任务进行规划。与现有技术相比,本发明能够实时根据试飞环境对试飞任务进行规划,对试飞任务规划的试飞周期和任务延期度进行优化,实现对多个目标进行的任务规划的同时综合兼顾优化结果与优化效率,实现动态环境下的试飞任务规划。
附图说明
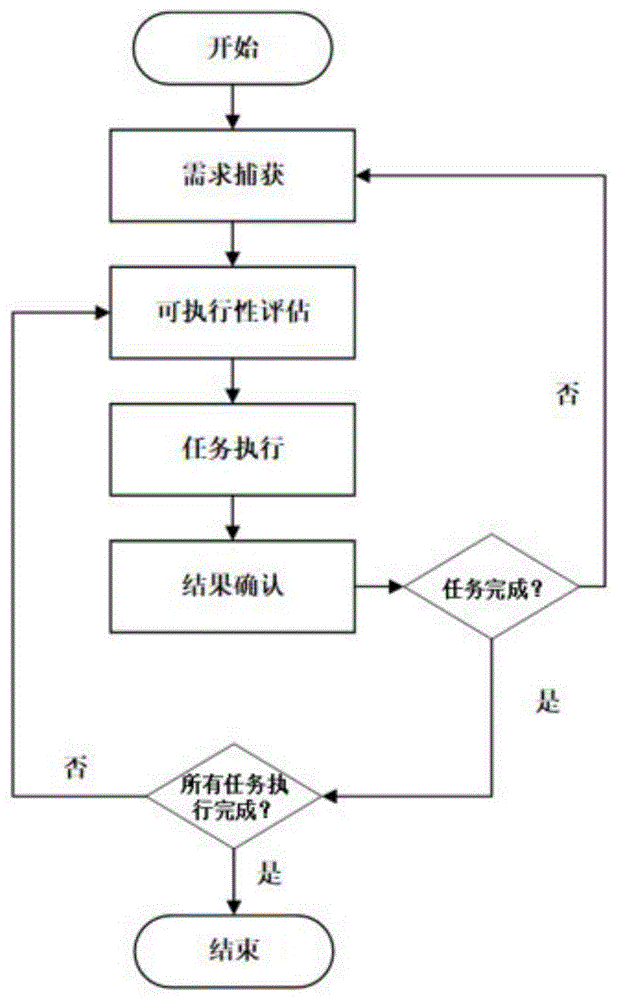
图1为动态试飞任务规划流程图;
图2为基于深度强化学习的动态试飞任务规划问题的框架。
具体实施方式
如图1所示,为本实施例涉及一种基于深度强化学习的动态试飞任务规划方法,包括以下步骤:
步骤1、需求捕获阶段:在规划前,需要根据各项试飞需求形成试飞任务集合TA。试飞需求包括研发需求、符合性验证飞行试验需求和运行需求等。一般来说,针对不同的需求,试飞任务以整体气动、机体结构、空调系统等分专业/系统特性为工作单元。每一试飞任务都包含试飞时长、前置任务集合、兼容驾机集合,以及时间窗口期信息。
步骤2、可执行性评估:为确保飞行试验的有效性,在需求捕获之后,应在试验前对飞行试验任务集合TA进行评估,以验证可执行性约束是否得到满足。通过评估的任务被添加到就绪任务队列RTq。
所述的飞行任务的评估包括:前置的任务状态、飞机部署时间,以及准备到位时间。在时刻t的可执行性评估条件为:
步骤3、任务执行:从就绪任务队列中选择任务,并将其安排到相应的试验驾机上。更新系统状态。
步骤4、结果确认:任务完成后,通过实际的任务执行程序以及收集的数据(包括机组评价)来确认测试结果的有效性。经确认的飞行试验任务将被从试飞任务集中删除。
如图2所示,为基于深度强化学习的动态试飞任务规划问题的框架。飞行任务调度的环境包含三个部分:任务集合(TA)、就绪任务队列(RTQ)和任务安排逻辑网络(TET)。根据试飞的任务需求,任务集合包含在规划时间t的所有未执行的任务,就绪的任务队列RTQ(t)包含通过可执行性评估的任务。任务安排逻辑网络存储试验机上所有任务的开始和完成时间信息。在将动态试飞任务规划问题转化为的马尔可夫决策模型后,智能体通过与调度环境进行交互来对算法进行训练。最终,最优策略可用于根据不同的环境状态进行决策,从而实现动态任务规划。
整体工作流程说明如下:在每个规划时间t,智能体根据当前环境状态s
为验证算法的可行性和有效性,本实施例构建不同的测试实例,实例的规模从60个任务×3架飞机到300个任务×5架飞机不等。在每个实例中,选择20%的任务具有开始时间,选择δ∈{0.1,0.2,0.3}的任务比例具有完成时间要求。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 基于深度强化学习的卫星实时引导任务规划方法及系统
- 一种基于深度强化学习的多无人机任务规划方法