一种发电厂碳排放的预测方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及数据预测领域,尤其涉及一种发电厂碳排放的预测方法及系统。
背景技术
国家对企业的碳排放量额度分配有一定的限制标准,现如今水力发电量的不确定性会影响火力发电量,煤炭火力发电在发电中还是占据主要地位,减少多少火力发电比重以降低碳排放来提升企业经济效益成为企业关心的重要问题,故提前预测当年的碳排放量问题是非常必要的。现有的几种预测方法均存在缺陷,基于萤火虫算法的预测方法对优秀个体依赖程度太高导致收敛速度降低,基于回归分析的预测方法在选用何种因子和该因子采用何种表达式只是一种推测,这影响了发电因子的多样性和某些因子的不可测性。目前的预测方法存在预测时间较长和预测结果不精确的问题。
发明内容
为了解决上述技术问题,本发明的目的是提供一种发电厂碳排放的预测方法及系统,能够快速精准地对碳排放进行预测。
本发明所采用的第一技术方案是:一种发电厂碳排放的预测方法,包括以下步骤:
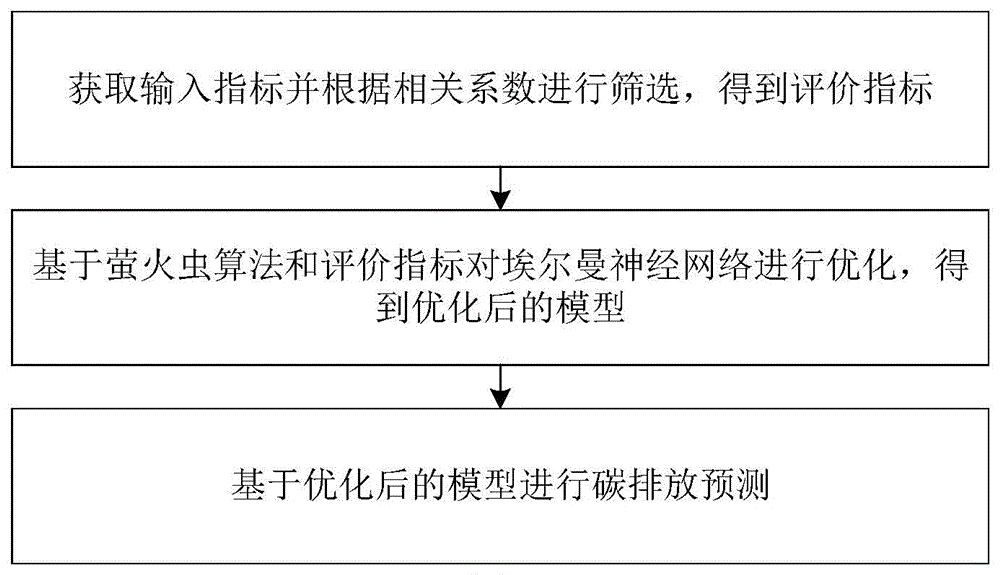
获取输入指标并根据相关系数进行筛选,得到评价指标;
基于萤火虫算法和评价指标对埃尔曼神经网络进行优化,得到优化后的模型;
基于优化后的模型进行碳排放预测。
进一步,所述输入指标包括总装机容量、清洁能源装机占比、发电量、市场电量、资产总额、净利润、耗用标准煤量、耗油总量、烟尘排放总量、二氧化硫排放总量、氮氧化物排放总量、在岗员工人数、二氧化碳排放总量,所述评价指标包括发电量、供电煤耗、氮氧化物排放率、二氧化硫排放率。
进一步,所述基于萤火虫算法和评价指标对埃尔曼神经网络进行优化,得到优化后的模型这一步骤,其具体包括:
以评价指标为输入的神经元;
初始化萤火虫的种群和位置并设置基本参数;
基于萤火虫算法对埃尔曼神经网络进行优化,输出最优参数解,得到优化后的模型。
进一步,所述基于萤火虫算法对埃尔曼神经网络进行优化,输出最优参数解,得到优化后的模型这一步骤,其具体包括:
导入特征处理过的数据并筛选出的重要因子和碳排放量;
计算萤火虫之间的吸引力;
更新步长向量;
更新萤火虫的位置;
判断到满足迭代终止条件,输出最优参数解,得到优化后的模型。
进一步,筛选的公式表示如下:
上式中,n为样本容量,ρ为相关系数,x,y为两个变量中对应的元素。
进一步,所述优化后的模型的目标函数表达式如下:
上式中,Y表示碳排放量,Y
本发明所采用的第二技术方案是:一种发电厂碳排放的预测系统,包括:
指标筛选模块,用于获取输入指标并根据相关系数进行筛选,得到评价指标;
优化模块,基于萤火虫算法和评价指标对埃尔曼神经网络进行优化,得到优化后的模型;
预测模块,基于优化后的模型进行碳排放预测。
本发明方法及系统的有益效果是:本发明提出一种基于距离相关系数和改进萤火虫算法优化的埃尔曼神经网络来预测发电厂碳排放的方法,通过距离相关系数方法找到与碳排放量关联度高的指标,解决了无关变量对预测结果的影响问题;改进的萤火虫算法全局搜索能力强,收敛速度快,具备较好的全局巡优能力,能够快速跳出局部最优点,并且具有并行处理能力以及鲁棒性强等特点,有效的解决了萤火虫算法对优秀个体依赖性较高的问题。
附图说明
图1是本发明一种发电厂碳排放的预测方法的步骤流程图;
图2是本发明具体实施例应用场景示意图;
图3是本发明一种发电厂碳排放的预测系统的结构框图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步的详细说明。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
本发明的应用场景图如图2所示
如图1所示,本发明提供了一种发电厂碳排放的预测方法,该方法包括以下步骤:
S1、获取输入指标并根据相关系数进行筛选,得到评价指标;
S1.1、选取输入指标:x
发电厂的指标输入有:总装机容量、清洁能源和可再生能源装机占比、发电量、市场电量、资产总额、净利润、耗用标准煤量、耗油总量、烟尘排放总量、二氧化硫排放总量、氮氧化物排放总量、在岗员工人数、二氧化碳排放总量。
筛选后的评价指标包括发电量、供电煤耗、氮氧化物排放率、二氧化硫排放率。
S1.2、由距离相关系数方法确定出k个重要性指标作为输入的神经元,u
筛选的公式表示如下:
上式中,n为样本容量,ρ为相关系数,x,y为两个变量中对应的元素。
S2、基于萤火虫算法和评价指标对埃尔曼神经网络进行优化,得到优化后的模型;
输入层参数的选择是建立合理的神经网络模型的关键,但随着输入层参数的增加,会增加神经网络迭代的次数,降低整个模型的运行效率,并影响神经网络最终预测值的准确性。
S2.1、以评价指标为输入的神经元;
还包括训练步骤:输入的是筛选出来的重要指标(即评价指标)和碳排放量,输出是预测的碳排放量。这样可以找到预测模型的最小预测误差进行预测。
S2.2、初始化萤火虫的种群和位置并设置基本参数;
具体地,所述基本参数包括步进系数、光吸引强度系数、最大吸引力和最大迭代次数。
在Elman中初始化w
S2.3、基于萤火虫算法对埃尔曼神经网络进行优化,输出最优参数解,得到优化后的模型。
S2.3.1、导入特征处理过的数据并筛选出的重要因子和碳排放量;
S2.3.2、计算萤火虫之间的吸引力:
S2.3.3、更新步长向量:
S2.3.4、更新萤火虫的位置:x
S2.3.5、判断到满足迭代终止条件,输出最优参数解,得到优化后的模型。
所述优化后的模型的目标函数表达式如下:
上式中,Y表示碳排放量,Y
S3、基于优化后的模型进行碳排放预测。
模型的主要结构包括输入层、隐含层、输出层,其每一层之间连接权可以进行学习修正;反馈连接由一组“结构”单元构成,用来记忆前一时刻的输出值,其连接权值是固定的。除了普通的隐含层外,还有一个特别的隐含层,称为关联层,该层从隐含层接收反馈信号,每一个隐含层节点都有一个与之对应的关联层节点连接。关联层的作用是通过联接记忆将上一个时刻的隐层状态连同当前时刻的网络输入一起作为隐层的输入,相当于状态反馈。
本专利主要通过距离相关系数法对碳排放指标进行重要因素筛选,再使用AFSA优化的埃尔曼神经网络来预测当年企业的碳排放量以达到企业决定是否进行技术改革来降低碳税并提升企业收入以及控制碳排放量在国家政策规定的限度内的目的。
如图3所示,一种发电厂碳排放的预测系统,包括:
指标筛选模块,用于获取输入指标并根据相关系数进行筛选,得到评价指标;
优化模块,基于萤火虫算法和评价指标对埃尔曼神经网络进行优化,得到优化后的模型;
预测模块,基于优化后的模型进行碳排放预测。
上述方法实施例中的内容均适用于本系统实施例中,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
一种发电厂碳排放的预测装置:
至少一个处理器;
至少一个存储器,用于存储至少一个程序;
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如上所述一种发电厂碳排放的预测方法。
上述方法实施例中的内容均适用于本装置实施例中,本装置实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
一种存储介质,其中存储有处理器可执行的指令,其特征在于:所述处理器可执行的指令在由处理器执行时用于实现如上所述一种发电厂碳排放的预测方法。
上述方法实施例中的内容均适用于本存储介质实施例中,本存储介质实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 一种基于组织碳排放预测的碳资产管理方法及系统
- 一种用于燃煤机组碳排放量的飞灰含碳量预测方法及系统