一种基于跨点云上下文信息的点云语义分割方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于人工智能、计算机视觉领域,涉及点云语义分割技术,具体为一种基于跨点云上下文信息的点云语义分割方法。
背景技术
近年来,随着激光雷达等三维采集设备的成熟,点云的获取变得越来越容易。由于点云在自动驾驶和虚拟现实等领域都有广泛的应用,所以点云的相关算法研究也变得越来越多。其中点云语义分割是一个重要的研究课题。
点云语义分割旨在推理得到每个点的类别,是计算机视觉领域的重要任务之一。在近年来的点云语义分割算法中,PointNet++
参考文献:
[1]Qi C R,Yi L,Su H,et al.Pointnet++:Deep hierarchical featurelearning on point sets in a metric space[J].Advances in neural informationprocessing systems,2017,30.
[2]Qian G,Li Y,Peng H,et al.PointNeXt:Revisiting PointNet++withImproved Training and Scaling Strategies[J].arXiv preprint arXiv:2206.04670,2022.
发明内容
本发明提供了一种基于跨点云上下文信息的点云语义分割方法,利用记忆体中存储的跨点云上下文信息来对点云中的点特征进行增强,提供更丰富的上下文信息。本方法可用于目前大多数的点云语义分割神经网络,可以做到即插即用,实现更准确的点云语义分割结果。本发明是通过以下技术方案实现的:
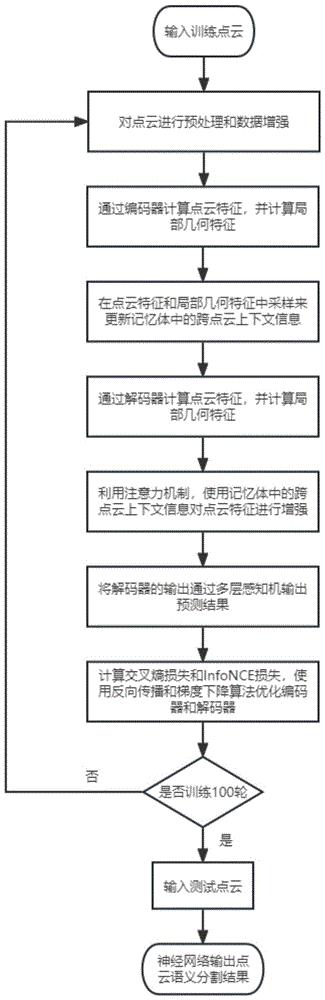
一种基于跨点云上下文信息的点云语义分割方法,所采用的点云语义分割网络分为编码器和解码器两部分,编码器由多个阶段组成,每个阶段有一个用于点云下采样的模块即SA模块,解码器也由多个阶段组成,且阶段数量和编码器相同,每个阶段有一个用于点云上采样的模块即FP模块;其特征在于,包括下列步骤:
第一步,对数据集进行数据预处理并进行数据增强;
第二步,将经过预处理和数据增强的点云通过编码器,编码器的每个阶段都会输出该阶段的点云特征,将编码器的第i个阶段输出的点云特征记为
(1)将经过预处理和数据增强的点云通过编码器,编码器的第i个阶段输出的点云特征记为
(2)对
(3)对于每个类别,都在
(4)在第i个阶段设置记忆体
这里μ取0.9;上述更新过程对每个类别迭代进行一遍,在更新之后,记忆体中存储了该阶段的跨点云上下文信息;
第三步,将编码器输出的点云特征通过解码器,解码器的每个阶段都会输出该阶段的点云特征,将解码器的第i个阶段输出的点云特征记为
第四步,在输出结果
第五步,完成整个神经网络模型的训练;
第六步,将待测试的点云输入训练好的神经网络模型,预测得到每个点的概率分布,取每个点概率分布中的最大概率值作为该点的预测类别,得到最终的点云语义分割结果。
本发明提供的技术方案的有益效果是:
现有的点云语义分割方法,都是只利用点所在邻域范围内的上下文信息,这样的做法使得点云中稀疏部分的点难以获取到丰富的上下文信息。本发明采用跨点云上下文信息的点云语义分割方法,利用记忆体中存储的跨点云上下文信息来增强点云中点的特征,使得点云中的稀疏部分可以获取到更丰富的上下文信息,从而实现更准确的点云语义分割结果。
附图说明
图1为一种基于跨点云上下文信息的点云语义分割方法流程图;
图2和图3为本发明方法与现有最优方法的实验结果比较;
具体实施方式
下面结合附图对本发明中的技术方案进行清楚、完整地描述。基于本发明中的技术方案,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明所采用的点云语义分割基础网络为文献[1]中涉及的点云语义分割网络,对其点云语义分割网络进行改进,增加了记忆体。
文献1中的点云语义分割网络分为编码器和解码器两部分,编码器由多个阶段组成,每个阶段有一个SA模块,解码器也由多个阶段组成,且阶段数量和编码器相同,每个阶段有一个FP模块。SA模块是用于点云下采样的模块,输入点云特征,它首先使用最远点采样(Farthest Point Sampling)算法采样得到一批点,称这批点为中心点。之后寻找每个中心点周围最近的k个点,将这k个点的特征输入多层感知机进行映射,再使用最大池化进行聚合,输出下采样的点云特征。FP模块是用于点云上采样的模块,输入点云特征和下采样点云特征,对于点云特征中的每个点,在下采样点云特征中找到最近的3个点,对其特征进行聚合,将聚合后的特征和点云中的点特征拼接在一起,通过多层感知机得到上采样的点云特征。
本发明用于实验可行性验证的数据集分别为S3DIS(Stanford Large-Scale 3DIndoor Spaces)数据集和ShapeNetPart数据集。其中Stanford Large-Scale 3D IndoorSpaces数据集包含了从6个区域里面的271个房间的点云,一共13个语义类别,其中203个房间的点云用于训练,68个房间的点云用于测试;ShapeNetPart数据集包含16种物体,一共16880个。每种物体都被分为2到6个部分,所有物体一共包含50个部分。其中14006个物体用于训练,2874个物体用于测试。
第一步,对S3DIS或ShapeNetPart数据集进行数据预处理并进行数据增强。对于S3DIS数据集的训练集,使用网格下采样算法对点云首先进行下采样,然后在下采样的点云中随机挑选24000个点作为预处理的结果。预处理结束之后进行数据增强,在几何方面,采用点云缩放、点云旋转和点云抖动的方式对点云进行在线数据增强;在颜色方面,采用对比度增强和颜色丢弃的方式对点云进行在线数据增强。
对于ShapeNetPart数据集的训练集,在点云中随机挑选2048个点作为预处理的结果。预处理结束之后进行数据增强,在几何方面,采用点云缩放、点云旋转的方式对点云进行在线数据增强。这里没有使用颜色方面的数据增强。
第二步,将经过预处理和数据增强的点云通过编码器,编码器的每个阶段都会输出该阶段的点云特征,将编码器的第i个阶段输出的点云特征记为
(1)将经过预处理和数据增强的点云通过编码器,编码器的第i个阶段输出的点云特征记为
(2)对
根据上述公式求解
(3)对于每个类别,都在
(4)在第i个阶段设置记忆体
这里μ取0.9。上述更新过程对每个类别迭代进行一遍。在更新之后,记忆体中存储了该阶段的跨点云上下文信息。
第三步,将编码器输出的点云特征通过解码器,解码器的每个阶段都会输出该阶段的点云特征,将解码器的第i个阶段输出的点云特征记为
(1)将编码器输出的点云特征通过解码器,解码器的第i个阶段输出的点云特征记为
(2)将该阶段对应记忆体
(3)将
其中linear()表示线性映射函数,softmax()表示归一化指数函数,Norm()表示归一化函数,MLP()表示多层感知机。
(4)将最后一个阶段的增强点云特征输入多层感知机得到输出
第四步,在输出结果
(1)将o
(2)在编码器每个阶段输出的点云特征
(3)将交叉熵损失和InfoNCE损失进行加权求和:
然后使用反向传播算法和梯度下降算法对编码器和解码器中的参数进行优化。
第五步,重复第一步到第四步100轮,完成整个神经网络模型的训练。
第六步,将待测试的点云输入训练好的神经网络模型,预测得到每个点的概率分布,取每个点概率分布中的最大概率值作为该点的预测类别,得到最终的点云语义分割结果。
下面结合具体实例对本发明方法进行可行性验证:
在两个公开数据集上进行了对比试验,分别是S3DIS(Stanford Large-Scale 3DIndoor Spaces)数据集和ShapeNetPart数据集。其中Stanford Large-Scale 3D IndoorSpaces数据集包含了从6个区域里面的271个房间的点云,一共13个语义类别,其中203个房间的点云用于训练,68个房间的点云用于测试;ShapeNetPart数据集包含16种物体,一共16880个。每种物体都被分为2到6个部分,所有物体一共包含50个部分。其中14006个物体用于训练,2874个物体用于测试。
在S3DIS数据集上使用平均交并比(mIoU),平均类别准确率(mAcc)和整体准确率(OA)来定量评估点云语义分割的结果。在ShapeNetPart数据集上使用实例平均交并比(Ins.mIoU)和类别平均交并比(Cat.mIoU)来定量评估点云语义分割的结果。
根据图2和图3所展示的本方法和已有最优点云语义分割方法在不同数据集上的实验结果表明:无论是室内场景还是物体,本发明方法的点云语义分割结果都要比现有的最优方法要好。因此,可以表明本发明方法的可行性和优越性。
- 一种基于面片上下文特征的室内点云场景语义分割方法
- 一种基于上下文和注意力的三维点云语义分割方法