一种利用最小二乘DSLOpt优化的实时ARAP网格变形方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及一种利用最小二乘DSLOpt优化的实时尽可能刚性ARAP(ARAP:as-rigid-as possible)网格变形方法,属于计算机图形学研究领域。
背景技术
元宇宙是目前数字技术的发展热点。元宇宙是利用数字科技手段创造与现实世界映射与交互的虚拟世界空间。物体运动和变化在现实世界无处不在,相应地元宇宙中需要物体的运动与变形。
网格变形是计算机图形学领域的研究热点,主要有经典的拉普拉斯网格变形,基于保体积的网格变形,尽可能刚性ARAP(As-Rigid-As-Possible)网格变形等,这些方法的共同目标是求解给定物体网格以在固定锚点条件下的变形结果,拉普拉斯和ARAP网格变形均为基于线性/非线性最小二乘的网格变形方法。为了便于后面的介绍,首先对拉普拉斯变形进行叙述,拉普拉斯网格变形所基于的能量函数如下:
其中L为拉普拉斯算子,式中p
从而可以构建一个线性最小二乘模型:
A
其中A,x,y有如下形式:
求解此线性方程组即可得到目标网格的每一个顶点的坐标,但是由于拉普拉斯形变仅考虑了拉普拉斯算子的计算结果,即只考虑了局部作用域(只和顶点坐标相关),所以通常在变形过程不具有旋转不变性,即如果形变过程中出现了旋转操作,则会出现变形后的目标网格存在局部放大或缩小的问题。
ARAP网格变形则是对拉普拉斯网格变形的改进,ARAP将关注点放在三维网格顶点之间的邻边上,在网格变形的过程中尽可能地去保证边长一定,这样便可以在尽可能符合约束的条件下尽可能去满足局部不变性,有如下的能量函数。
其中W权值可选为定值1(Laplacian)或cotangent Laplacian,p
对于上式的求解方法可以使用局部式、全局式方法,即交替求解R和p
1)局部式求解(构造法):已知p
所以
令
S
并令R
2)全局式求解(线性最小二乘),已知R,求解p
上式为方程组中,从上向下第i个方程,对于锚点约束,只需要在最后添加即可,最终仍是求解线性系统
A
使用ARAP算法所得到的网格变形通常能较好地保留原始网格的局部形状信息,并且最重要的一点是ARAP网格变形具有旋转不变性。
但是不论是拉普拉斯网格变形还是ARAP变形都要求一次变形的位置变化不能过大,通俗来讲就是锚点的位置变化不能太大,只能一小步一小步进行交互式变形,当位置变化过大则会出现严重的失真问题。
对于ARAP存在的以上问题即使用手工求解线性系统(CPU端或GPU端)的方式会存在鲁棒性问题(对于不同的参数设置对于不同的情况会有不同的变形效果),并不能始终保持鲁棒性。
发明内容
本发明的目的是基于DSL实现高性能GPU非线性最小二乘求解器并应用于高精度高鲁棒性的实时尽可能刚性ARAP三维网格变形方法。
为实现上述目的,本发明采取的技术方案是:一种利用最小二乘DSLOpt优化的实时ARAP网格变形方法,其包括如下步骤:
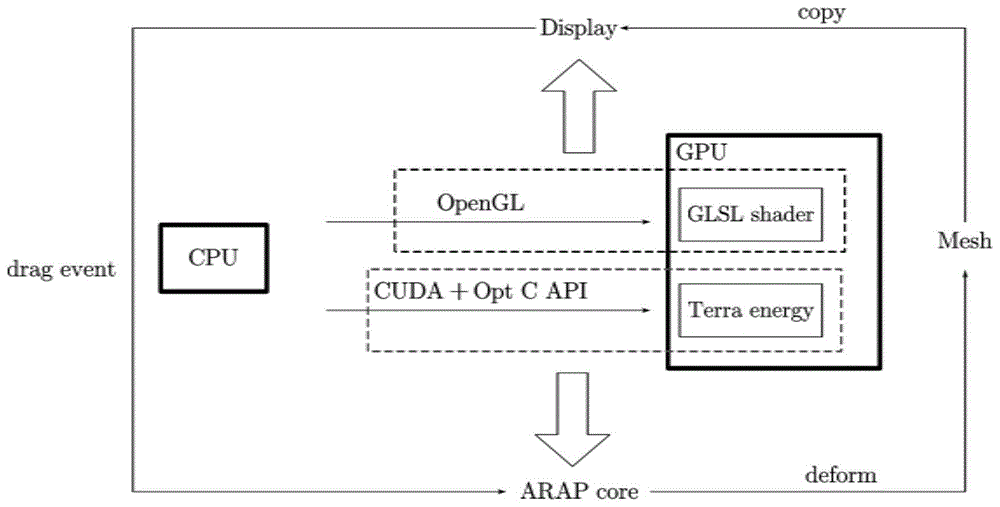
步骤1:OpenMesh模型读入处理;
步骤2:利用OpenGL渲染载入模型;
步骤3:CPU利用CUDA、Opt C++API和GPU求解器的数据通信;
步骤4:Opt非线性最小二乘求解ARAP。
进一步的,所述步骤1的具体步骤如下:
步骤1.1:利用OpenMesh以连通图的方式读入模型;
步骤1.2:利用形心计算公式对Mesh进行Geometry to Origin处理,公式如下:
For v in Mesh:
步骤1.3:计算Mesh的顶点法线。
进一步的,所述步骤2的具体步骤如下:
步骤2.1:基于OpenGL4.5编写渲染所需GLSL shader,包括网格shader,线框模型shader以及锚点shader;
步骤2.2:准备材质贴图(用以以较低的成本获得较好的视觉效果);
步骤2.3:初始化MVP矩阵,编译shader,读取贴图以及利用OpenGL进行显存分配,将绘制调用单独封装,用于实时更新。
进一步的,所述步骤3的具体步骤如下:
步骤3.1:在GPU端创建求解ARAP所需量如下:
fit
reg
result
angle
ref
constrains
from
to
其中,result为ARAP求解结果,angle为三个分量旋转角,ref为参考模型(即初始Mesh,算法执行过程保持不改变),constrains为对锚点位置的约束(与模型中的顶点位置一一对应),from、to存储了Mesh中所有连通顶点,fit和reg分别表示锚点的约束度和非锚点的约束度;
步骤3.2:将如上变量组成problem_data数组从而进行进一步的问题求解。
进一步的,所述步骤4的具体步骤如下:
步骤4.1:利用Terra语言编写求解器文件arap.t,即问题定义,参照如下公式:
即对于第i个顶点优化如下公式(采用全局/局部优化策略,交替求解R和p’):
对Opt求解器进行初始化,包括精度,日志,上下文创建,问题定义,线性/非线性迭代次数等;
步骤4.2:利用Opt_ProblemSolve将步骤3.2中的problem_data传送到求解器,进行求解。
本发明的有益效果是:本发明可以实现高精度高鲁棒性的三维ARAP网格变形,与此同时有较优的时间复杂度,能够满足实时CG要求。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
图1是本发明简要架构图。
图2是本发明中的数据输送过程图。
图3是Opt的抽象求解过程图。
图4是基于Opt的ARAP求解结果和CPU Eigen线性求解的对比。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
本发明使用DSL实现高性能GPU非线性求解器并应用于实时尽可能刚性ARAP变形,下面对相关技术、方法以及优化部分进行介绍。
一、相关技术
1.Terra
Terra作为Lua的low-level counterpart。高性能计算应用程序,例如自动调节器auto-tuner和领域特定语言DSL(domain specific language),依赖于生成式编程技术以实现高性能和便携性。然而,这些系统通常以多种不同的语言实现,并且在与程序执行不同的进程中执行代码生成化,使得某些优化难以设计。而Terra使用流行的脚本语言Lua来分阶段执行。用户可以实现优化高级语言中的选项,并使用内置结构来生成和执行高性能Terra代码。为了简化元编程,Lua和Terra共享相同的词法环境,但是,为了确保性能,Terra代码可以独立执行Lua的运行库Runtime。基于Terra模板计算的DSL比纯手写C的运行速度快2.3倍,本发明主要会利用Terra编写GPU端问题定义、求解。
2.CUDA
CUDA(Compute Unified Device Architecture,统一计算架构)是由英伟达NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。基于该技术,可利用NVIDIA的GPU进行图像处理之外的运算,亦可利用GPU作为C-编译器的开发环境。CUDA开发包(CUDA Toolkit)只能将自家的CUDA C语言(对OpenCL只有链接的功能),也就是执行于GPU的部分编译成PTX(Parallel Thread Execution)中间语言或是特定NVIDIA GPU架构的机器代码(NVIDIA官方称为"device code");而执行于中央处理器部分的C/C++代码(NVIDIA官方称为"host code")仍依赖于外部的编译器,Microsoft Windows下需要Microsoft Visual Studio;Linux下则主要依赖于GCC。本发明主要利用CUDA实现GPU显存分配。
3.OpenGL
OpenGL(Open Graphics Library)是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API)。该接口由近350个不同的函数调用组成,用来从简单的图形比特绘制复杂的三维景象。而另一种程序接口系统是仅用于Microsoft Windows上的Direct3D。OpenGL常用于CAD、虚拟现实、科学可视化程序和电子游戏开发,本发明利用OpenGL做三维绘制,可视化。
4.OpenMesh
OpenMesh是一种表示和管理多边形网格,通用并且有效的数据结构,和相关的支承函数组成的库,由RWTH Aachen在计算机图形集的基础上开发出来。OpenMesh既可以表示任意多边形网格,也可以表示纯三角形网格;点,半边,边和面的清晰表达;快速的局部区域访问,尤其是环状区域;较高的用户化性能,例如用户可以选择用户坐标类型和网格项目的存储结构,给网格添加用户自定义的元素或者函数,在运行过程用动态特性添加数据等。本发明利用OpenMesh以连通图的方式读入模型的特性实现邻接点存储。
5.Opt
Opt是一种新语言,用户只需在图像或图形结构的未知数上编写能量函数,编译器会自动生成最先进的GPU优化内核。最终结果是一个系统,其中图形和视觉应用程序中的真实世界能量函数可以用数十行代码表示。它们直接编译成高度优化的GPU求解器实现,其性能可与已发布的最佳手动调整、特定于应用程序的GPU求解器相媲美,并且比通用自动生成的求解器高1-2个数量级。使用方式类似于Ceres等可直接支持能量函数定义求解的函数库。
Opt可以在GPU端生成非线性最小二乘求解器,Opt求解非线性最小二乘主要应用Gaussian-Newton算法以及levenberg-marquardt算法,求解线性最小二乘依赖于PCG算法和雅可比算法,以此可以通过预置求解过程中的非线性迭代次数和线性迭代次数来优化求解结果。
二、方法
本发明的方法主要包括:利用Terra语言在GPU端定义能量,通过CUDA和Opt C API将求解所需变量传送至GPU端,进行基于Opt的问题求解,下面具体分析介绍:
1.基于Terra的能量函数编写(GPU端问题定义)
Terra可以嵌入在Lua中进行编程,可以直接在Lua中调用Terra函数,Terra最重要的特点是嵌入在Lua中的Terra函数可以直接利用LLVM进行JIT编译。本发明主要涉及到使用Terra进行GPU端能量函数编写,GPU问题定义如下,其中N为网格顶点个数为单个整型数据,w_fitSqrt,w_regSqrt分别是fit和reg开根号,因为能量函数会将两者再平方所以传入开根后的fit和reg,Offset指的是结果网格,Angle指的是三个轴上的旋转角度,UrShape指的是参考网格,Constrains指的是锚点约束,G存储邻接顶点,UsePreconditioner(true)即在求解线性最小二乘时使用PCG,整个在Terra中定义的ARAP包括两个能量函数一个是锚点能量,另一个是ARAP边长旋转能量。
local N=opt.Dim("N",0)
localw_fitSqrt=Param("w_fitSqrt",float,0)
localw_regSqrt=Param("w_regSqrt",float,1)
local Offset=Unknown("Offset",opt_float3,{N},2)
local Angle=Unknown("Angle",opt_float3,{N},3)
localUrShape=Array("UrShape",opt_float3,{N},4)
local Constraints=Array("Constraints",opt_float3,{N},5)
local G=Graph("G",6,"v0",{N},7,"v1",{N},8)
UsePreconditioner(true)
locale_fit=Offset(0)-Constraints(0)
local valid=greatereq(Constraints(0,0),-999999.9)
Energy(Select(valid,w_fitSqrt*e_fit,0))
localARAPCost=(Offset(G.v0)-Offset(G.v1))-Rotate3D(Angle(G.v0),UrShape(G.v0)-UrShape(G.v1))
Energy(w_regSqrt*ARAPCost)。
2.基于Opt C API和CUDA的CPU和GPU之间的数据传输
具体操作方式是先通过CUDA API实现在图形卡上分配显存,主要涉及到cudaMalloc,再将数据通过cudaMemcpy将CPU中的数据拷贝到显存中,至此GPU设备上就已经存在用于求解ARAP最小二乘的全部数据了,此后通过Opt的C API实现将显存中的数据传送到1中所定义的求解器中。
cudaMalloc(&g_offset,sizeof(Vec3f)*nvertices);
cudaMalloc(&g_angle,sizeof(Vec3f)*nvertices);
cudaMalloc(&g_ref,sizeof(Vec3f)*nvertices);
cudaMalloc(&g_from,sizeof(int)*nedges);
cudaMalloc(&g_to,sizeof(int)*nedges);
cudaMalloc(&g_constrains,sizeof(Vec3f)*nvertices);
vector
for(autov:origin_mesh.vertices())
vertices.push_back(origin_mesh.point(v));
cudaMemcpy(g_ref,vertices.data(),vertices.size()*sizeof(Vec3f),cudaMemcpyHostToDevice);
cudaMemcpy(g_offset,vertices.data(),vertices.size()*sizeof(Vec3f),cudaMemcpyHostToDevice);/*important!*/
cudaMemcpy(g_from,c_from.data(),c_from.size()*sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(g_to,c_to.data(),c_to.size()*sizeof(int),cudaMemcpyHostToDevice)。
3.Opt求解器初始化以及问题求解、问题销毁
/>
基于上述分析介绍,本发明利用最小二乘DSLOpt优化的实时ARAP网格变形方法,步骤如下:
步骤1:OpenMesh模型读入处理;
步骤2:利用OpenGL渲染载入模型;
步骤3:CPU利用CUDA、Opt C++API和GPU求解器的数据通信;
步骤4:Opt非线性最小二乘求解ARAP。
具体的,所述步骤1的步骤如下:
步骤1.1:利用OpenMesh以连通图的方式读入模型;
步骤1.2:利用形心计算公式对Mesh进行Geometry to Origin处理,公式如下:
For v in Mesh:
步骤1.3:计算Mesh的顶点法线。
具体的,所述步骤2的步骤如下:
步骤2.1:基于OpenGL4.5编写渲染所需GLSL shader,包括网格shader,线框模型shader以及锚点shader;
步骤2.2:准备材质贴图(用以以较低的成本获得较好的视觉效果);
步骤2.3:初始化MVP矩阵,编译shader,读取贴图以及利用OpenGL进行显存分配,将绘制调用单独封装,用于实时更新。
具体的,所述步骤3的步骤如下:
步骤3.1:在GPU端创建求解ARAP所需量如下:
fit
reg
result
angle
ref
constrains
from
to
其中,result为ARAP求解结果,angle为三个分量旋转角,ref为参考模型(即初始Mesh,算法执行过程保持不改变),constrains为对锚点位置的约束(与模型中的顶点位置一一对应),from、to存储了Mesh中所有连通顶点,fit和reg分别表示锚点的约束度和非锚点的约束度;
步骤3.2:将如上变量组成problem_data数组从而进行进一步的问题求解。
具体的,所述步骤4的步骤如下:
步骤4.1:利用Terra语言编写求解器文件arap.t,即问题定义,参照如下公式:
即对于第i个顶点优化如下公式(采用全局/局部优化策略,交替求解R和p’):
对Opt求解器进行初始化,包括精度,日志,上下文创建,问题定义,线性/非线性迭代次数等;
步骤4.2:利用Opt_ProblemSolve将步骤3.2中的problem_data传送到求解器,进行求解。
综上,本发明为一种基于新型DSLOpt生成优化最小二乘求解器的实时尽可能刚性ARAP实现,主要包括模型读取,相关数据获取、预处理以及传输,能量函数编写(GPU侧问题定义),CPU和GPU以及Terra求解器的通信,问题求解,变量内存释放。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域的普通技术人员应该了解,上述实施例不以任何形式限制本发明的保护范围,凡采用等同替换等方式所获得的技术方案,均落于本发明的保护范围内。
本发明未涉及部分均与现有技术相同或可采用现有技术加以实现。
- 一种基于自适应网格变形的人脸图像去模糊方法
- 一种虚拟手术中可变形对象切割仿真的网格变形优化方法
- 一种虚拟手术中可变形对象切割仿真的网格变形优化方法