一种面向多属性词抽取的数据增广方法
文献发布时间:2024-01-17 01:26:37
技术领域
本发明涉及数据处理领域,具体涉及一种面向多属性词抽取的数据增广方法。
背景技术
本节中的陈述仅提供与本公开相关的背景信息,并且可能不构成现有技术。
在机器学习中,有监督学习以其良好的性能得到了广泛应用。但是,有监督学习中的模型训练需要充足的标注数据,而标注数据通常会耗费大量的人力和财力,导致现有标注数据集规模普遍偏小,难以使模型从标注数据中学习到足够多的特征,从而限制了模型性能的提升。为了缓解有监督学习中标注数据不足的问题,提供给模型更多的训练数据,研究者提出了数据增广技术,该技术基于现有训练数据集,新建或合成新的数据,扩充原训练数据集。数据增广技术有利于增强模型的鲁棒性,防止过拟合,提高泛化能力,已广泛用于计算机视觉、自然语言处理等领域。在自然语言处理领域中,目前所采用的数据增广技术主要有5大类:(1)基于单词替换的数据增广方法,例如采用词典WordNet的同义词替换、不同语言的回译等方法来生成新的训练数据;(2)基于生成的数据增广方法,例如借助深度学习模型来生成新的训练数据;(3)基于样本采样的数据增广方法,包括对数据集中的少数类数据上采样和从多数类数据下采样;(4)基于噪声注入的数据增广方法,对原训练数据进行随机插入、随机交换和随机删除等操作;(5)基于预训练语言模型的数据增广方法,借助高性能的预训练语言模型来生成新的训练数据。
属性词抽取是自然语言处理中观点挖掘(Opinion mining)应用的一项重要子任务,用于从文本句子中抽取出属性词,该词是指句子中出现的实体词,由单个词或短语构成。例如,在针对一款笔记本电脑的评论文本“这款笔记本性能不错,就是显示屏有点大,重量有点重”中,厂商或消费者想了解该条评论针对笔记本的哪些具体属性分别做出的评价,首先要从评论文本中自动抽取所有的相关属性,如“性能”、“显示屏”和“重量”等。属性词抽取任务目前主要基于有监督学习方法完成,虽然该任务在深度学习技术推动下取得了显著的进步,但其性能往往受限于有限的标注数据。为此,研究者通常引入数据增广技术来提升属性词抽取任务的性能。
然而,上述数据增广方法仍存在以下一些不足:
(1)基于单词替换的数据增广方法可能会替换到文本句子样本中待抽取的信息,从而破坏了待抽取信息的语义。为了防止此类操作,需要在数据增广过程中增加信息保护机制,但是这会增加信息抽取任务方法的复杂性。(2)基于生成的数据增广方法生成的句子样本可能会更改句中的属性词信息和标签,不适用于信息抽取任务。(3)基于样本采样的数据增广方法难以对观点挖掘数据集进行数据增广处理,这是因为在属性词抽取标注数据集中,文本句子样本没有被标注类别标签,而只是对句中的各个属性词进行细粒度标注(如采用BIO标注方法)。(4)基于噪声注入的数据增广方法对原训练数据进行随机插入符号,以及句中词进行随机交换和随机删除时,可能会带来属性词和标签位置不一致的问题。(5)基于预训练语言模型的数据增广方法能产生较好的效果,但是该方法实现效率低、成本高,在属性词抽取任务中不常用。
总之,上述数据增广方法可能会改变句子的词序、属性词及其标签信息,容易破坏短语型属性词的整体语义,不能有效解决属性词标注数据匮乏问题。
此外,上述数据增广方法侧重于对样本中的文本数据处理进行数据增广,忽略了通过标签来进行数据增广的潜力。
发明内容
本发明的目的在于:针对现有技术中存在的问题,提供了一种面向多属性词抽取的数据增广方法,缓解有监督学习中标注数据匮乏的问题,提升模型在多属性词抽取应用场景中的性能,从而解决了上述问题。
本发明的技术方案如下:
一种面向多属性词抽取的数据增广方法,包括:
步骤S1:对于包含多个属性词的原训练样本句子,基于文本片段,进行属性词标注;
步骤S2:根据标注结果,构造多属性词标签数据集;
步骤S3:将多属性词标签数据集中的各个子集与原样本句子进行结合,生成新的训练样本。
进一步地,所述步骤S1,包括:
将每个属性词对应的文本片段视为一个整体,并对所对应的文本片段的起始和结束位置进行标注。
进一步地,所述步骤S2,包括:
步骤S21:根据标注结果,生成属性词列表及其对应的标签对集合;
步骤S22:基于属性词列表和标签对集合,构建非空真子集的集合G
进一步地,所述步骤S22,包括:
在属性词列表所对应的标签对集合中,分别取任意数量标签对,构成集合G
进一步地,所述步骤S3,包括:
将集合G
进一步地,所述步骤S21,包括:
属性词列表A={a
对属性词列表A={a
进一步地,所述步骤S22,包括:
非空真子集的集合G
进一步地,所述包含多个属性词的原训练样本句子能够生成的新的训练样本总数T计算如下式:
进一步地,还包括:
将新的训练样本添加到原始训练集中,实现数据增广。
与现有的技术相比本发明的有益效果是:
1、一种面向多属性词抽取的数据增广方法,包括:步骤S1:对于包含多个属性词的原训练样本句子,基于文本片段,进行属性词标注;步骤S2:根据标注结果,构造多属性词标签数据集;步骤S3:将多属性词标签数据集中的各个子集与原样本句子进行结合,生成新的训练样本;本发明,降低了人工数据标注成本,缓解标注数据不足的问题,在多属性抽取应用场景中设计了基于文本片段标签的数据增广方法,合成了新的训练样本,扩充了训练数据;增广后的训练数据集使模型能够从数据中学习到更多的特征,增强模型的鲁棒性,防止过拟合,提高泛化能力。
2、一种面向多属性词抽取的数据增广方法,其技术方案实现简单且有效,不需要额外的工具和资源;且解决了多属性词抽取中现存的一些技术问题,具有重要的现实意义和应用价值,不仅可应用于自然语言处理领域中的多属性词抽取任务,也可应用于多命名实体识别等任务中,也可设计类似的数据增广方法并应用于计算机视觉领域中。
附图说明
图1为一种面向多属性词抽取的数据增广过程示意图。
具体实施方式
需要说明的是,术语“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
下面结合实施例对本发明的特征和性能作进一步的详细描述。
实施例一
在属性级观点挖掘数据集中,存在一些包含多个属性词的样本,其占比相对较少,且每个属性词包含的单词个数也不尽相同;例如,在国际语义测评大会SemEval 2014Task4Restaurant数据集和Laptop数据集中,包含多个属性的句子样本数分别约占42.95%和37.23%,大多数属性词包含1至2个单词,少数属性词则包含更多单词,Restaurant数据集中有的属性词包含14个单词,在Laptop数据集中有的属性词包含9个单词。
本发明针对当前属性级观点挖掘数据集中包含多个属性词的样本数量较少,且属性词长度不等的特性,基于文本片段标注,设计了一种面向多属性词抽取的数据增广方法,主要解决以下两类技术问题:
(1)解决现有序列标注方法(如BIO标注方法)容易造成短语型属性词抽取准确性下降的问题。现有序列标注方法常用BIO标签为句中的每个词进行标注,该方法在信息抽取任务中,容易将单个短语型属性词分解为多个属性词,错误地抽取出多个属性词。通过本发明提出的数据增广方法,将每个属性词视为一个整体进行标注,从而保护了短语型属性词的整体语义。
(2)解决现有数据增广方法容易影响样本原语义的问题。现有技术可能会改变句子及其中属性词的词序、标签信息,导致引入过多数据噪声,从而改变样本原语义。通过本发明提出的数据增广方法,可以在不改变样本文本原语义的情况下,通过标签集的不同组合方式,来构造出新的训练样本,为模型训练提供了更多的监督信息。
在机器学习中,有监督学习方法以其良好的性能得到了广泛应用。但是基于有监督学习的模型通常依赖于高质量、充足的标注数据,不足的标注数据会限制模型的性能提升空间。因此,在基于有监督方法的多属性抽取任务中,为缓解标注数据匮乏的问题,本发明提出一种新的数据增广方法。
由于在属性词抽取任务的标注数据集中,每个训练样本包括文本、标签两类数据,因此,训练样本的增广方法可以从文本、标签两个角度进行设计。然而,大多数现有的研究侧重于从文本角度实现数据增广,忽略了从标签数据在数据增广的潜力。因此,本发明针对多属性词抽取应用场景,在不需要增加额外外部计算资源的前提下,通过标签数据来增广训练数据。
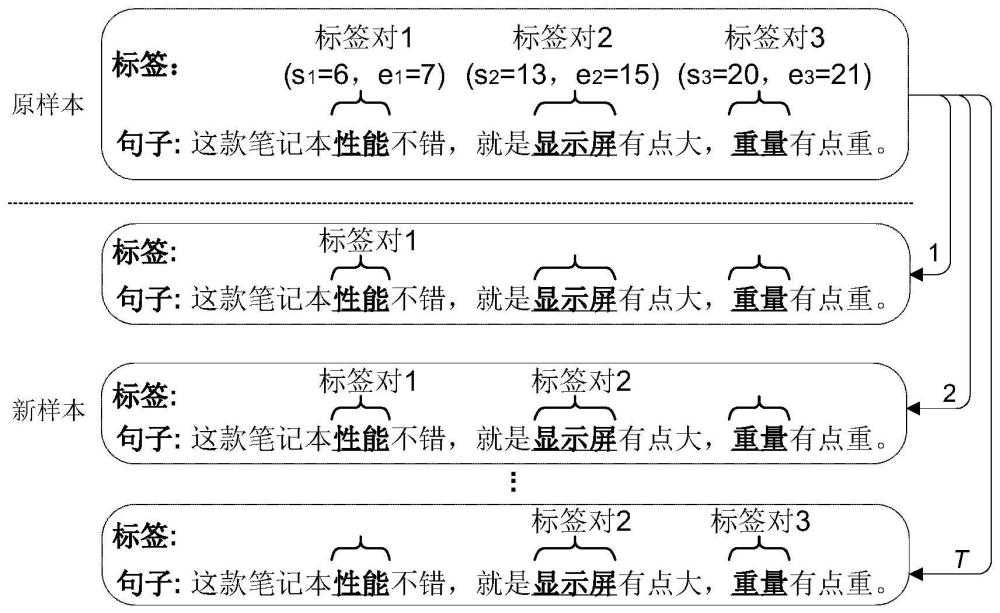
本发明提出的方法主要包括基于文本片段的属性词标注、多属性词标签数据集构造和新训练样本生成等三个部分。为使发明目的、技术方案和优点更加清楚,下面将结合附图对本发明做进一步的详细描述,请参阅图1,一种面向多属性词抽取的数据增广方法,具体如下:
步骤S1:对于包含多个属性词的原训练样本句子,基于文本片段,进行属性词标注;
步骤S2:根据标注结果,构造多属性词标签数据集;
步骤S3:将多属性词标签数据集中的各个子集与原样本句子进行结合,生成新的训练样本。
在本实施例中,需要说明的是,原训练样本句子的属性词由单个词或多个词组合构成,其长度不等;对于其中的包含多个词的短语型属性词,由于现有BIO等序列标注方法容易将其错误地抽取为多个属性词,破坏其整体语义,因此,在本实施例中,所述步骤S1,具体包括:
将每个属性词对应的文本片段(Snippet)视为一个整体,并对所对应的文本片段的起始和结束位置进行标注;其标注如附图1所示,原训练样本句子为:“这款笔记本性能不错,就是显示器有点大,重量有点重。”;通过步骤S1可得出如下文本片段(也就是属性词)并进行如下标注:
1、“性能”,“性能”所对应的标注后的标签对为“(s
2、“显示器”,“显示器”所对应的标注后的标签对为“(s
3、“重量”,“重量”所对应的标注后的标签对为“(s
需要说明的是,其中的数字表示文本片段中起始词或结束词在原训练样本句子中的位置;例如:(s
在本实施例中,具体的,所述步骤S2,包括:
步骤S21:根据标注结果,生成属性词列表及其对应的标签对集合;优选地,可在原始训练集(原训练样本句子包括在原始训练集中)中选择所有包含多个属性词的原训练样本句子,并获取每个原训练样本句子的属性词列表和标签对集合;
步骤S22:基于属性词列表和标签对集合,构建非空真子集的集合G
在本实施例中,具体的,所述步骤S22,包括:
在属性词列表所对应的标签对集合中,分别取任意数量标签对,构成集合G
在本实施例中,具体的,所述步骤S3,包括:
将集合G
在本实施例中,具体的,所述步骤S21,包括:
属性词列表A={a
对属性词列表A={a
在本实施例中,具体的,所述步骤S22,包括:
非空真子集的集合G
在本实施例中,具体的,每个包含多个属性词的原训练样本句子能够生成的新的训练样本总数T计算如下式:
以上所述实施例仅表达了本申请的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。
提供本背景技术部分是为了大体上呈现本发明的上下文,当前所署名的发明人的工作、在本背景技术部分中所描述的程度上的工作以及本部分描述在申请时尚不构成现有技术的方面,既非明示地也非暗示地被承认是本发明的现有技术。
- 一种基于图模型和词嵌入模型面向新闻领域的关键词抽取方法
- 一种面向实时大数据平台Storm的属性抽取系统