一种基于深度学习的动物定位模型及方法
文献发布时间:2024-04-18 19:44:28
技术领域
本发明涉及深度学习技术领域,更具体地说,涉及一种基于深度学习的动物定位模型及方法。
背景技术
野生动物资源是大自然留给人类的宝贵财富,野生动物资源不仅具有商业价值更具有重大的生态价值和科学价值。在生态学和野生动物学研究领域,为了更好地理解自然生态系统的复杂性,研究物种生存和迁徙状况,拯救濒危野生动物,保护生态环境,全球各大自然生态研究机构和野生动物保护组织在各个自然野生动物活动区域密集布设了大量运动传感相机,对监控范围内的野生动物的行踪进行拍照捕获,采集到了海量的图像数据。生态学家和动物保护志愿者通过对这些数据进行处理和分析,研究监控区域内的自然野生物种和种群的生存状况和行为特点,以使人类对自然生态有更多的了解和更好的保护。
在近年的野生动物识别与定位研究中,最常用的方法是使用基于深度学习的全监督方法,基于完整的标注信息训练卷积神经网络来进行图像特征提取,再对图像中的野生动物实现高效地定位和分类。而野生动物数据的整理和分类识别工作传统上是由人类也就是专家或者社区志愿者来完成的。志愿者们手动一张张地浏览分析采集到的照片数据,根据图像内出现的野生动物物种进行多种属性的标注,比如这里有一只羚羊、那里有头大象、这幅图像中共有多少匹斑马、以及动物的具体行为等等。一个区域内的相机陷阱在几个月的时间采集到的图像数量可能就有几十万张的级别,如此巨量的数据如果光靠人的手工筛选和整理需要付出非常高的时间和成本。人工处理这些数据的缺点显而易见,这是一项耗时的、昂贵的劳动密集型工作。另外,由于人的不确定因素,一个刚开始从事这项工作的新手与长期工作熟练人员在处理速度、准确率上存在很大差别,同时也受到人的主观态度影响,导致数据的处理和分析很难做到高度的一致性和无偏性。此时,弱监督学习的优势日益凸显。弱监督学习依赖弱于全监督学习的标注信息实现图像特征的识别和理解,能够达到与全监督学习相媲美的性能,其对低成本标注的需求带来了更多的关注。因此,研究如何通过弱监督方式进行高质量的目标定位是一个非常具有挑战性和实用价值的研究方向。
与全监督的方法不同,弱监督目标定位仅使用图像级标注来实现对象的定位,大大减少了标注成本。通过将弱监督技术应用于生态学领域,自动化信息提取的过程,可以将生态研究者从繁杂的数据预处理工作中解放出来,使之能够专注于自然生态环境和野生动物的研究、管理和保护工作,并且能够扩大相机陷阱的部署范围,更加广泛地应用于野生动物的实时监测与识别,而无需人工驻守监视。由此,需要构建一种野生动物定位模型,模型需要学会从整个图像中自适应地学习目标的位置、形状和大小等信息,实现快速定位与识别野生动物。
经检索,中国专利申请,申请号202110194977.1,申请日2021年2月20日,公开了一种基于深度学习的动物识别方法、装置、设备及存储介质。该方法包括:获取待检测图像,根据待检测图像通过目标检测模型检测得到待检测图像中各个动物的种类以及对应的位置区域;根据动物的种类筛选出目标动物,并根据目标动物确定所述目标动物所属的目标检测位置区域;根据目标检测位置区域对所述待检测图像进行调整,得到目标子图;通过关键点检测模型对目标子图进行关键点识别,得到目标关键点以及目标关键点在目标子图中的参考位置坐标,并结合目标子图确定目标关键点在待检测图像中的目标位置坐标,以通过所述目标位置坐标对动物进行识别。该方法能够在通用环境下实现对动物关键点的检测识别,但是该方法并未考虑到基于图像对目标动物进行标注识别存在边框级别和像素级别标注信息缺乏的问题。
发明内容
1.要解决的技术问题
针对现有技术中存在的对于动物的识别和定位需要大量实例级标注数据导致现人工标注成本高、工作效率低等问题,本发明提供了一种基于深度学习的动物定位模型及方法,使用图像级分类标签和文本描述实现对动物的定位和识别,减少人工标注成本,有效提高识别的准确性。
2.技术方案
本发明的目的通过以下技术方案实现。
一种基于深度学习的动物定位模型,包括:
输入模块,采集动物图像、动物类别和类别特征描述;获取动物图像特征,所述动物图像特征包括全局图像特征和图像块特征集合;获取动物类别和类别特征描述的文本描述特征;
构建模块,通过多层感知头和类激活头构建动物定位模型;多层感知头包括多层感知模块和投影头,将图像块特征集合的平均特征与全局图像特征拼接后输入到多层感知模块中,多层感知模块输出混合图像特征后,通过投影头对混合图像特征进行分类预测,计算多层感知头的分类损失;将图像块特征集合转换为空间特征图,通过类激活头对空间特征图进行分类预测,计算类激活头的分类损失;
训练模块,通过自蒸馏损失函数约束多层感知头和类激活头的输出分布,训练动物定位模型;
输出模块,通过动物定位模型对动物图像进行定位得到定位结果,输出定位结果。
进一步地,通过投影头对混合图像特征进行分类预测的预测公式为:
其中,teacher表示多层感知头在动物定位模型结构中作为教师模型,c表示在教师模型中某一类动物类别,C表示动物类别总数,j表示遍历所有动物类别时的某一类动物类别,
进一步地,投影头对混合图像特征进行分类预测后,通过交叉熵函数计算多层感知头的分类损失,计算公式为:
其中,
进一步地,通过类激活头对空间特征图进行分类预测的预测公式为:
其中,student表示类激活头在动物定位模型结构中作为学生模型,i表示在学生模型中某一类动物类别,
进一步地,对空间特征图进行分类预测后,通过交叉熵函数计算类激活头的分类损失,计算公式为:
其中,
进一步地,自蒸馏损失函数约束多层感知头和类激活头的输出分布后,计算自蒸馏损失,计算公式为:
其中,
进一步地,通过自蒸馏损失和类激活头分类损失的加权和定义并优化学生模型类激活头,学生模型类激活头的损失函数表示为:
其中,L
进一步地,多层感知模块输出混合图像特征后,计算混合图像特征和文本描述特征的相似度。
一种基于深度学习的动物定位方法,包括以下步骤:
构建基于所述的一种基于深度学习的动物定位模型;
获取动物图像特征,所述动物图像特征包括图像块特征集合;
将图像块特征集合转换为空间特征图,将空间特征图送入类激活头进行分类预测,得到分类预测分数最高的类别;
将类激活头中分类预测分数最高的类别的全连接层的参数作为系数,对类激活头中最后一层卷积层输出的语义特征图进行加权求和,得到定位结果。
进一步地,通过全局平均池化层对语义特征图进行池化后得到特征向量,将特征向量输入到全连接层中,设定全连接层参数,得到定位结果,定位结果表示为:
其中,
3.有益效果
相比于现有技术,本发明的优点在于:
本发明的一种基于深度学习的动物定位模型及方法,基于深度学习,利用全局图像特征信息、局部图像特征信息以及动物文本描述特征,通过多层感知头和类激活头构建动物定位模型,通过自蒸馏结构训练动物定位模型,从而在进行动物定位时,有效减少人工标注成本,加快训练进程,提高动物细粒度定位的准确度。
附图说明
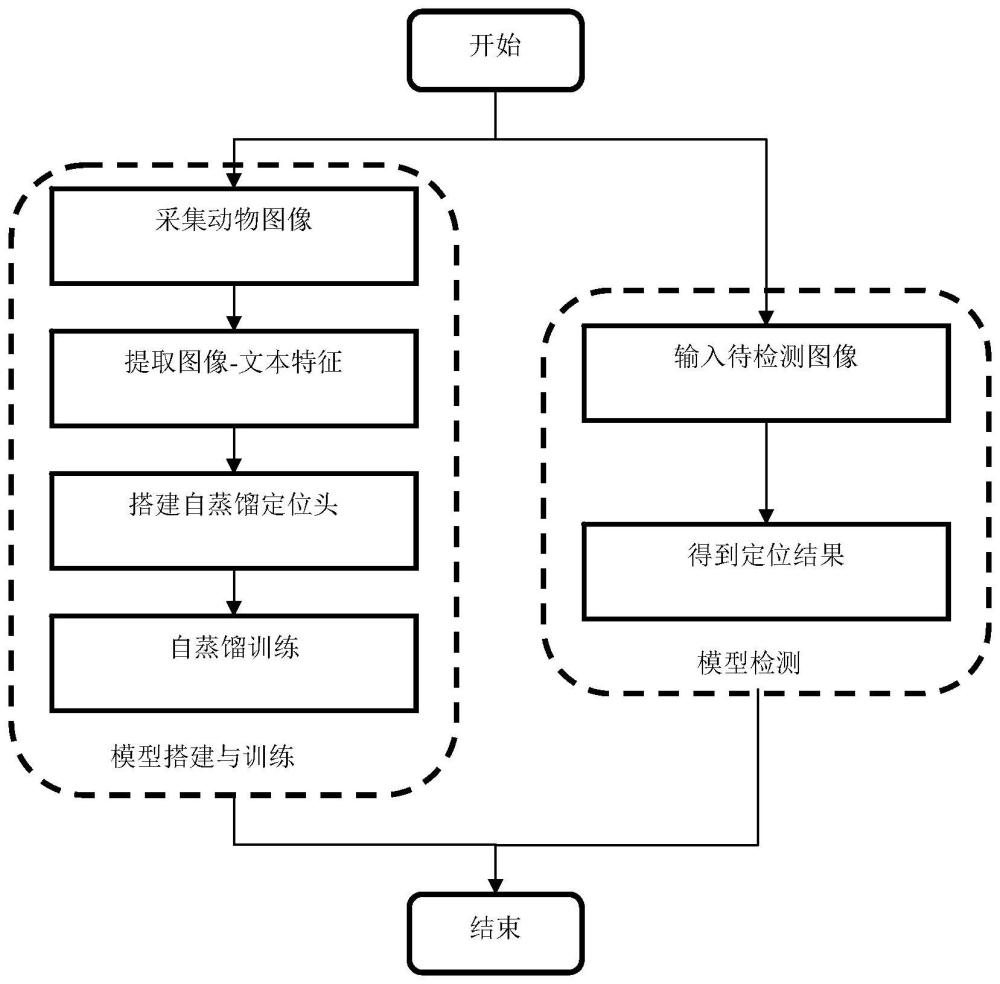
图1为本发明实施例动物定位方法流程图;
图2为本发明实施例动物定位方法网络结构图。
具体实施方式
下面结合说明书附图和具体的实施例,对本发明作详细描述。
实施例
如图1所示,为本实施例提供的一种基于深度学习的动物定位模型。动物定位模型包括输入模块、构建模块、训练模块以及输出模块。输入模块,采集动物图像、动物类别和类别特征描述;获取动物图像特征,动物图像特征包括全局图像特征和图像块特征集合;获取动物类别和类别特征描述的文本描述特征。构建模块,通过多层感知头和类激活头构建动物定位模型;多层感知头包括多层感知模块和投影头,将图像块特征集合的平均特征与全局图像特征拼接后输入到多层感知模块中,多层感知模块输出混合图像特征后,通过投影头对混合图像特征进行分类预测,计算多层感知头的分类损失;将图像块特征集合转换为空间特征图,通过类激活头对空间特征图进行分类预测,计算类激活头的分类损失。训练模块,通过自蒸馏损失函数约束多层感知头和类激活头的输出分布,训练动物定位模型。输出模块,通过动物定位模型对动物图像进行定位得到定位结果,输出定位结果。
具体到本实施例中,在输入模块中,首先采集动物图像、动物类别和类别特征描述。本实施例中,采集动物图像样本,同时按照动物类别构建动物类别特征描述库,由此构建多场景下的动物数据集,包含多天气环境、多季节、多地点的动物图像,以及不同动物类别对应的细粒度动物类别特征描述文本。如图2所示,采集的动物类别包括长颈鹿、黄羊等,而对于长颈鹿的类别特征描述为:毛为棕黄色或栗红色,在背脊两旁和体侧下缘存在排列有序的白色斑点;对于黄羊的类别特征描述为:毛为浅红棕色,腹面和四肢的内侧为白色,臀部有白色的斑。
进一步地,获取动物图像特征,动物图像特征包括全局图像特征和图像块特征集合。具体地,如图2所示,设定输入的动物图像为x,则动物图像x的高为H,宽为W,进而将动物图像x切分为高和宽均为k的N个图像块,将N个图像块以图像块为基本单位的序列输入到图像编码器(Image Encoder)中进行特征提取,由此得到图像块特征组成的图像块特征集合(patch tokens),将图像块特征集合记作
在构建模块中,通过多层感知头和类激活头构建动物定位模型。具体地,如图2所示,求取图像块特征集合的平均特征,将图像块特征集合的平均特征记作
其中,teacher表示多层感知头在动物定位模型结构中作为教师模型,c表示在教师模型中某一类动物类别,C表示动物类别总数,j表示遍历所有动物类别时的某一类动物类别,
进而,投影头对混合图像特征进行分类预测后,通过交叉熵函数计算多层感知头的分类损失,计算公式为:
其中,
同时,在构建模块中,如图2所示,将图像块特征集合转换为空间特征图,通过类激活头(CAM Head)对空间特征图进行分类预测,计算类激活头的分类损失。具体地,将图像块特征集合按照图像块在动物图像x中的空间位置进行还原,进而将图像块特征集合转换为空间特征图。进一步地,通过类激活头对空间特征图进行分类预测,预测公式为:
其中,student表示类激活头在动物定位模型结构中作为学生模型,i表示在学生模型中某一类动物类别,
进而,类激活头对空间特征图进行分类预测后,通过交叉熵函数计算类激活头的分类损失,计算公式为:
其中,
由此,在训练模块中,通过自蒸馏损失函数约束多层感知头和类激活头的输出分布,训练动物定位模型。本实施例中,自蒸馏损失函数约束多层感知头和类激活头的输出分布后,计算自蒸馏损失,计算公式为:
其中,
其中,L
在输出模块中,通过动物定位模型对动物图像进行定位得到定位结果,输出定位结果。
由此,本实施例提供的一种基于深度学习的动物定位模型,包括输入模块、构建模块、训练模块以及输出模块,在仅使用分类和文本描述的标注情况下,有效利用了全局图像特征、图像块特征集合以及文本描述特征,通过多层感知头和类激活头构建动物定位模型,通过自蒸馏损失训练动物定位模型,有效减少了人工标注成本,加速了动物定位模型的训练进程,减少了训练成本。
本实施例还提供一种基于深度学习的动物定位方法,包括以下步骤:构建基于上述所述的一种基于深度学习的动物定位模型;获取动物图像特征,所述动物图像特征包括图像块特征集合;将图像块特征集合转换为空间特征图,将空间特征图送入类激活头进行分类预测,得到分类预测分数最高的类别;将类激活头中分类预测分数最高类别的全连接层的参数作为系数,对类激活头中最后一层卷积层输出的语义特征图进行加权求和,得到定位结果。
具体到本实施例中,首先构建上述所述的一种基于深度学习的动物定位模型后,输入动物图像,将动物图像均等切分为图像块,并转换为以图像块为基本单位的序列输入到图像编码器中进行特征提取,得到图像块特征组成的图像块特征集合。进一步地,将图像块特征集合转换为空间特征图,将空间特征图输入到类激活头中,通过类激活头对空间特征图进行分类预测,将预测分数最高的类别作为分为预测的最终结果。进一步地,使用类激活头中分类预测分数最高类别的全连接层的参数作为系数,对类激活头中最后一层卷积层输出的语义特征图进行加权求和,得到定位结果。具体地,将空间特征图输入到类激活头中,通过卷积层处理后,定义最后一层卷积层输出的特征图为语义特征图,将语义特征图记作
其中,v
其中,
由此,本实施例提供的一种基于深度学习的动物定位方法,基于深度学习的动物定位模型,通过动物类别的细粒度特征文本描述,有效提升动物细粒度识别的准确度,增强动物定位与识别模型的精度和泛化能力。
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
- 一种基于深度学习的网页自动化测试缺陷定位方法
- 一种基于深度学习的多方位车牌定位方法
- 一种基于深度学习的RFID标签相对位置定位方法
- 一种基于深度学习的绝缘子故障定位识别方法
- 一种基于深度学习的运动物体三维模型重建方法
- 一种基于深度学习的运动物体三维模型重建方法