一种去噪扩散的微表情数据生成方法及分类网络训练方法
文献发布时间:2024-04-18 19:48:15
技术领域
本发明属于表情识别技术领域,具体涉及一种去噪扩散的微表情数据生成方法及分类网络训练方法。
背景技术
面部微表情是一个人在经历情绪时自发地、不自觉地发生的面部动作。这些微表情通常出现在高风险的场合,比如刑事审讯、面试、政治辩论等。因此,多任务计算分析和微表情自动识别已成为人脸研究的一个新兴领域。
微表情具有强度低、振幅弱、持续时间短的特点,大多数自发的微表情无法被肉眼观察到,因此微表情识别是一项具有挑战性的任务。由于微表情的短暂性和微小性,收集和检测微表情的难度较大,从而导致了微表情数据的严重不足,没有大规模的数据集可用。
在中小数据集的训练过程中,数据扩充一直是防止过拟合的重要环节。传统的数据增强方法包括对图像进行随机翻转、旋转、剪切、变形缩放、添加噪声、颜色扰动等。但是,对于数据多样性的增加有一定的局限性。近年来,卷积神经网络(convolutional neuralnetworks,CNNs)在计算机视觉中得到了广泛的应用,提取合适的特征通常可以提高网络的性能,这就是现在很多研究倾向于设计一种新的特征提取方法的原因。许多方法都致力于改造网络模型和改进特征提取器,使网络能够提取不同的特征。然而,对微表情数据增强的研究还很少。因此,数据集不足仍然是一个致命的问题。如果不能有效解决这一问题,就很难有效提高微表情识别的精度。
发明内容
基于现有技术中存在的上述缺点和不足,本发明的目的之一是至少解决现有技术中存在的上述问题之一或多个,换言之,本发明的目的之一是提供满足前述需求之一或多个的一种去噪扩散的微表情数据生成方法。
为了达到上述发明目的,本发明采用以下技术方案:
一种去噪扩散的微表情数据生成方法,包括:
S1、获取微表情序列;
S2、在微表情序列中提取顶点帧,提取顶点帧及左右的若干帧作为选定帧;
S3、使用选定帧训练微表情扩散模型,微表情扩散模型用于生成微表情数据;微表情扩散模型中包含了交叉注意力U-Net模型,交叉注意力U-Net模型用于对加噪后的选定帧图片去噪,预测将加噪样本还原所需的去噪数据,通过计算正向加噪扩散生成的图片与反向去噪还原生成的图片的损失训练微表情扩散模型;
S4、将纯高斯噪声和选定帧作为输入进行融合采样,融合采样过程包括根据纯高斯噪声通过训练好的微表情扩散模型生成生成图片,根据生成图片和选定帧计算生成图片的FID指标,以FID指标对生成图片进行筛选。
作为一种优选方案,步骤S3包括如下步骤:
S31、对选定帧逐步加噪扩散,生成若干加噪样本;
S32、使用微表情扩散模型预测将加噪样本还原所需的去噪数据;
S33、使用去噪数据将加噪样本反向还原;
S34、计算每一次加噪的样本与加噪后反向去噪的样本的损失,根据损失修正预测过程。
作为一种优选方案,步骤S4包括:
S41、随机生成纯高斯噪声图像;
S42、将纯高斯噪声图像输入训练好的微表情扩散模型;
S43、利用训练好的微表情扩散模型对纯高斯噪声图像去噪,从而生成对应的生成图片;
S44、根据选定帧计算生成图片的FID指标,以FID指标对生成图片进行筛选。
作为一种进一步优选的方案,筛选具体为:根据选定帧计算生成图片的FID指标;
删除FID指标高于预设值的生成图片。
作为一种进一步优选的方案,纯高斯噪声图像的大小为224×224,由纯高斯噪声组成。
作为一种优选方案,步骤S2中,提取顶点帧及左右各两帧作为选定帧。
作为一种优选方案,交叉注意力U-Net模型包括下采样部分、中间部分、上采样部分和输出部分。
另一方面,本发明还提供一种微表情分类网络训练方法,其特征在于,使用如前述任一项的方法生成生成图片,生成图片经筛选得到筛选后的图片,使用筛选后的图片与选定帧中划分出的训练集组成微表情分类数据,以训练分类网络。
本发明与现有技术相比,有益效果是:
本发明的方法针对微表情数据集不足的问题,基于扩散模型对微表情数据集进行扩充,通过对用于微表情扩散模型的数据进行加噪扩散与去噪逆扩散,训练微表情扩散模型,利用该模型实现微表情图片的生成构造,并利用融合采样过程对生成的图片加以筛选,从而有效地增加了微表情数据的数据量;另外,本发明的方法将上述微表情数据添加到分类网络中加以利用,从而有效提升各分类模型的识别精度和准确率。
附图说明
图1表示本发明中基于微表情扩散模型的微表情数据增强方法的流程图。
图2表示本发明中微表情扩散模型的结构图。
图3表示本发明中的微表情扩散模型的流程图。
图4表示本发明中的交叉注意力U-Net结构图。
图5表示本发明的交叉注意力U-Net结构中的交叉注意力块的详细结构图。
图6表示本发明的融合采样过程的结构图。
图7表示本发明提出的融合采样过程的流程图。
具体实施方式
下面将结合本申请实施例中的图,对本申请实施例中的技术方案进行清楚、完整的描述。
在下述介绍中提供了本申请的多个实施例,不同实施例之间可以替换或者合并组合,因此本申请也可认为包含所记载的相同和/或不同实施例的所有可能组合。因而,如果一个实施例包含特征A、B、C,另一个实施例包含特征B、D,那么本申请也应视为包括含有A、B、C、D的一个或多个所有其他可能的组合的实施例,尽管该实施例可能并未在以下内容中有明确的文字记载。
下面的描述提供了示例,并且不对权利要求书中阐述的范围、适用性或示例进行限制。可以在不脱离本申请内容的范围的情况下,对描述的元素的功能和布置做出改变。各个示例可以适当省略、替代或添加各种过程或组件。例如所描述的方法可以以所描述的顺序不同的顺序来执行,并且可以添加、省略或组合各种步骤。此外,可以将关于一些示例描述的特征组合到其他示例中。
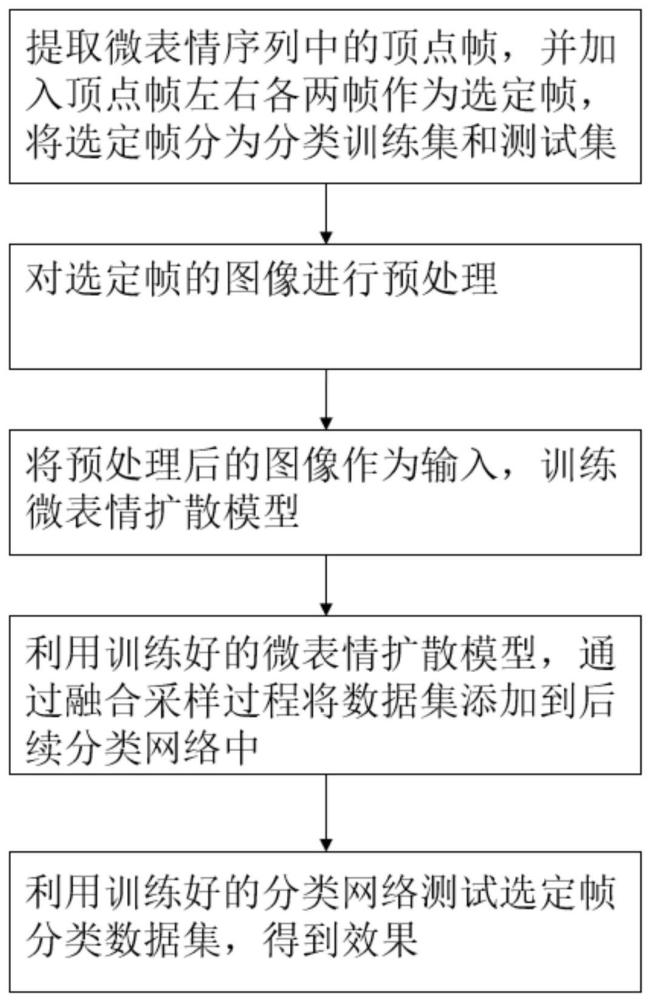
本申请提供一种去噪扩散的微表情数据生成方法,其流程图如图1所示,包括:
S1、获取微表情序列;这一微表情序列通过图像采集得到,并选取其中的关键片段生成。
S2、在微表情序列中提取顶点帧,提取顶点帧左右的若干帧作为选定帧。
其中,顶点帧是指微表情序列中表情最强烈的那一帧,它是一帧二维图像。
具体地,在该步骤S2中,提取顶点帧左右的若干帧,具体为提取顶点帧左右各两帧,再包括顶点帧,共计五帧作为选定帧,从而将额外的选定帧同样作为生成更多微表情数据所用的数据源。另外,本步骤还将这些选定帧分为分类训练集和测试集,以供后续步骤训练使用。
更具体地,步骤S2之中还包括步骤S21:对选定帧进行预处理。将所有选定帧图像裁剪成相同的大小,即224×224。并对图片进行随机翻转。然后将选定帧分为分类训练集Tra和测试集Tst。
S3、使用选定帧训练微表情扩散模型,微表情扩散模型用于生成微表情数据;微表情扩散模型中包含了交叉注意力U-Net模型,交叉注意力U-Net模型用于对加噪后的选定帧图片去噪,预测将加噪样本还原所需的去噪数据,通过计算正向加噪扩散生成的图片与反向去噪还原生成的图片的损失训练微表情扩散模型。
具体地,在本实施例中,如图2及图3所示,步骤S3包括如下步骤:
S31、对选定帧逐步加噪扩散,生成若干加噪样本;
定义如下后验概率分布形式:
其中,x
设噪声变量为∈~N(0,I),N为自然分布,则x
通过该公式,我们可以得到t时刻的图像分布,且x
输入图片x
根据公式(1)及贝叶斯公式可以得到,给定t-1时刻的图像x
此时x
由此,得到向后的每一步加噪扩散过程所应输出的加噪样本。
S32、使用微表情扩散模型预测将加噪样本还原所需的去噪数据。
S33、使用去噪数据将加噪样本反向还原。
具体地,步骤S32和S33使用如下方法:
假设本次执行步骤S32是预测将时刻t的加噪样本反向还原所需的去噪数据,逆向t时刻的图像分布用
其中,
具体地,下采样部分如下:
输入x
具体地,中间部分如下:
h
其中,Layer Normalization公式如下,a表示特征,μ表示均值,Var表示方差,ε表示为防止分母为0而加的一个较小的数,一般为1e-05,γ和β是可学习的仿射变换的参数:
激活函数Sigmoid公式如下,a表示特征:
具体地,上采样部分如下:
h
具体地,输出部分如下:
h
其中,组归一化的公式同公式(5),区别为组归一化会对通道方向上进行分组,再对每个组进行归一化处理,算出“通道数//组数*高*宽”的均值。
此时得到的是
得到该x
S34、计算每一次加噪的样本与加噪后反向去噪的样本的损失,根据损失修正预测过程;这一修正过程具体通过优化损失函数的方法修正去噪过程,以如下公式计算损失优化θ。
其中,E表示期望值。
S4、将纯高斯噪声和选定帧作为输入进行融合采样,融合采样过程包括根据纯高斯噪声通过训练好的微表情扩散模型生成生成图片,根据生成图片和选定帧计算生成图片的FID指标,以FID指标对生成图片进行筛选。
本实施例中,步骤S4包括如下步骤:
参考图6和图7。
S41、随机生成纯高斯噪声图像;具体地,步骤S41可以为生成224×224大小的纯高斯噪声组成的图像G。
S42、将纯高斯噪声图像输入训练好的微表情扩散模型;
S43、利用训练好的微表情扩散模型对纯高斯噪声图像去噪,从而生成对应的生成图片,具体为微表情图片Z。
具体地,由上式(7)可以得到
最后生成的x
S44、根据选定帧计算生成图片的FID指标,以FID指标对生成图片进行筛选。
作为一种进一步优选的实施方式,筛选具体为:根据选定帧计算生成图片的FID指标;
删除FID指标高于预设值的样本。
具体地,由于通过上述方法生成的生成图片质量不稳定,本实施例采用计算FID的方式对其进行筛选,FID全称Fréchet Inception Distance,是一个用来评价生成图像多样性和质量的指标,其值越小,则生成的图像多样性越好,质量越好。其中FID的计算公式如下:
其中,Tr表示矩阵对角线上元素的总和,即为矩阵的迹;c和d表示原始的图片和生成的图片,μ表示均值,∑是协方差矩阵。
若某一生成图片的FID指标高于预设值,则说明该生成图片的图像多样性和质量不足,将其删除。
上述步骤S44优选地设置为步骤S43之后。
本申请的一个实施例还提供一种微表情分类网络训练方法,其特征在于,使用如前述任一实施例的方法生成生成图片,生成图片经筛选得到筛选后的图片,使用筛选后的图片与选定帧中划分出的训练集组成微表情分类数据,以训练分类网络。具体地,将这些筛选后的生成图片与Tra一同作为训练集加入到分类网络中,Tst则作为测试集。
实验结果
为了验证本发明的有效性,通过实验,对几种方法进行横向比较。验证了所提数据增强方法的有效性。比较了加入融合采样过程(Fusion Sampling Process,FSP)后不同方法的UF1(Unweighted F1 Score)和UAR(Unweighted Average Recall),w/o FSP表示不加FSP,w/FSP表示加FSP。从表1可以看出,加入FSP后,每种方法的效果都有不同程度的提高,考虑到方法本身提取的信息有限,LBP-TOP略有提高。在三个数据集上,SMIC和SAMM有明显的改善效果,但在CASMEII数据集上,改善不明显。主要原因可能是CASMEII数据集容易被识别,而其他两个数据集由于实验采样环境造成的天然缺陷,或多或少需要大量的数据进行训练,这样网络才能学习到更多有效的特征。本发明提出一种基于扩散模型的微表情数据增强技术,能够有效地扩充微表情数据集,提高微表情识别的准确率和稳定性。该技术具有实用性和广泛的应用前景,值得在相关领域进行深入研究和应用。
表1融合采样过程对数据分类结果的影响
现有技术的参考文献如下:
文献[1],G.Zhao,M.Pietikainen.Dynamic texture recognition using localbinary patterns with an application to facial expressions.IEEE Transactionson Pattern Analysis&Machine Intelligence,2007,29(6):915–928.
文献[2],Y.S.Gan,S.-T.Liong,W.-C.Yau,Y.-C.Huang,L.-K.Tan.OFF-ApexNeton micro-expression recognition system.Signal Process:Image Communication,2019,74:129–139.
文献[3]K.Simonyan,A.Zisserman.Very deep convolutional networks forlarge-scale image recognition.Computer Science,2014,1409(15):1556-1563.
文献[4]A.Krizhevsky,I.Sutskever,G.Hinton.ImageNet classification withdeep convolutional neural networks.Advances in Neural Information ProcessingSystems,2012,25(2):1097-1105.
文献[5]S.T.Liong,.YS.Gan,J.See,H.Q.Khor,Y.C.Huang.Shallow triplestream three-dimensional CNN(STSTNet)for micro-expressionrecognition.201914th IEEE international conference on automatic face&gesturerecognition(FG 2019),2019:1-5.
文献[6]B.Chen,K.H.Liu,Y.Xu,et al.Block division convolutional networkwith implicit deep features augmentation for micro-expressionrecognition.IEEE Transactions on Multimedia,2022.
以上所述者,仅为本公开的示例性实施例,不能以此限定本公开的范围。即但凡依本公开教导所作的等效变化与修饰,皆仍属本公开涵盖的范围内。本领域技术人员在考虑说明书及实践这里的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未记载的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的范围和精神由权利要求限定。
- 一种基于条件生成对抗网络的OCT成像中散斑去噪方法
- 一种基于海量单类单幅图像的图像分类网络训练方法
- 一种基于生成对抗网络的微表情判别模型训练方法
- 一种基于光流生成网络和重排序的微表情分类方法