一种调节阀动态仿真特性曲线的优化方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及调节阀动态仿真技术领域,具体涉及一种调节阀动态仿真特性曲线的优化方法。
背景技术
调节阀是化工过程中最常用的单元设备之一,通过接受调节控制单元输出的控制信号,借助动力操作去改变介质流量、压力、温度、液位等工艺参数的最终控制元件,一般由执行机构和阀门组成。
为了更好的模拟与最大限度的还原化工生产过程,通常需要对调节阀进行动态仿真,但在动态仿真过程中,由于调节阀的阀门特性与现场调节阀的阀门特性之间往往存在一定的差异,这就导致动态仿真中的调节阀阀门开度与现场调节阀的实际开度无法一致。因此在仿真调节阀中可自主配置特殊的阀门特性曲线,该曲线反映了现场调节阀真实开度(SetOP)与仿真调节阀综合开度(RealOP)之间的特性关系。
通过现场实际调节阀开度(SetOP)与该特性曲线,可以得到仿真调节阀中参与动态仿真计算的综合开度(RealOP),然而要准确获取该曲线却存在一定难度。
随着技术的进步,仿真调节阀的特性曲线可通过海量的现场调节阀历史数据计算得到,然而现场历史数据噪声的影响会导致基于历史数据所得到的调节阀特性曲线失真,若不进行必要的处理可能无法用于仿真调节阀。
期刊电力安全技术(09),59-61中《火电厂汽轮机阀门流量特性曲线优化》提供一种通过试验的方法对汽轮机现场阀门特性曲线进行调整和优化,该方法主要针对现场实际阀门的优化,需要通过试验的方法获得阀门的特性曲线,成本高、效率低、效果也具有较大的局限性。
发明内容
本发明要解决的技术问题在于提供一种调节阀动态仿真特性曲线的优化方法,提高动态仿真中调节阀的模拟精度与仿真真实性,得到高精确度、高真实性的仿真调节阀特性曲线。
为了解决上述技术问题,本发明提供如下技术方案。
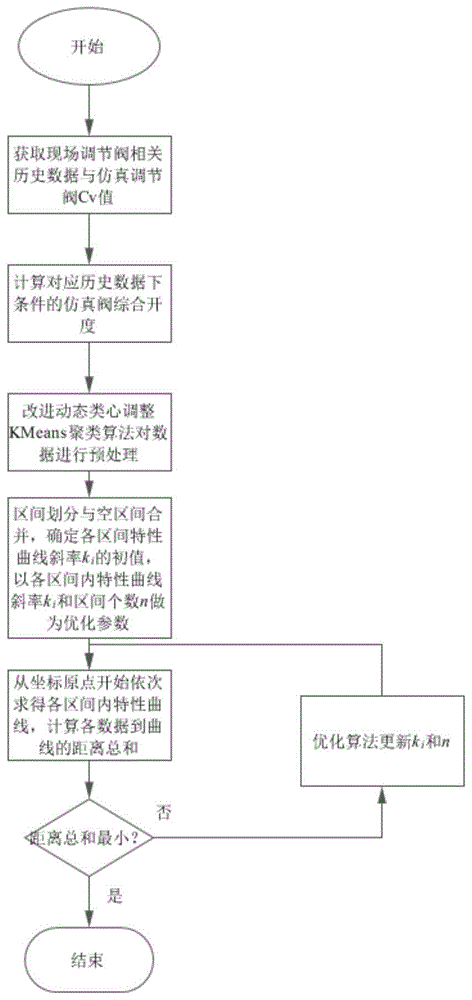
本发明提供一种调节阀动态仿真特性曲线的优化方法,包括如下步骤:
S1:获取现场调节阀的历史数据、仿真调节阀相关参数以及相关物性参数,计算得到对应历史数据下的仿真调节阀综合开度;
S2:基于现场调节阀真实开度和仿真调节阀综合开度数据,通过改进的动态类心调整的KMeans聚类方法,对数据进行预处理;
S3:根据现场调节阀给定开度将聚类获得的类心数据等分为n个区间,并将相邻区间内均无数据的区间合并为一个大空区间,合并后的区间个数为n’,基于合并后的各区间数据获得初始特性曲线;
S4:将各数据点到所述初始特性曲线的距离总和作为优化函数,将合并后每个区间内初始特性曲线斜率k
进一步的,所述现场调节阀的历史数据包括调节阀真实开度、阀门进口压力、阀门出口压力、阀门流量的相关历史数据;所述仿真调节阀相关参数为仿真调节阀阀门Cv值;所述相关物性参数为物质流密度值。
进一步的,所述仿真调节阀综合开度的计算公式为:
其中F为阀门流量;P
进一步的,步骤S2中,改进动态类心调整的KMeans聚类方法步骤为:
S201:设置数据偏差容忍度Δ和数据过滤容忍度(%)σ;
S202:设置类心个数K,随机选取K个数据作为初始类心,记为
S203:定义损失函数:
S204:令t=0,1,2,...为迭代步数,对于每一个样本x
S205:对于每一个聚类,重新计算该聚类的类心,第t+1步迭代时的第i个类心为:
S206:重复步骤4和5,直到J收敛;
S207:判断每一个样本x
S208:重复步骤2~7,至所有的样本x
S209:统计每个类内样本个数占总样本数的百分比,若类内样本数量占比小于数据过滤容忍度(%)σ,则剔除该类心。
进一步的,步骤S3中,获得初始特性曲线具体为:
以坐标原点(0,0)作为第一个区间初始特性曲线的起点,通过预设定的各区间初始特性曲线初始斜率k
进一步的,步骤S4中,数据点到该初始特性曲线的距离计算方式为:将通过聚类得到的各数据点(x
进一步的,步骤S4中,所述优化算法包括Nelder-Mead Simplex、PRincipal AXIS、Constrained Optimization BY Linear Approximations、BOBYQA、NEWUOA、based onSubplex中的一种或多种。
相比于现有技术,本发明提供的调节阀动态仿真特性曲线的优化方法具有如下有益效果:
本发明提出了一种调节阀动态仿真特性曲线优化方法,首先通过历史数据和仿真模型中调节阀相关参数以及相关物性参数,获得基于现场数据条件下仿真调节阀的综合开度,再通过改进的动态类心个数的KMeans聚类方法,对计算得到的仿真调节阀综合开度和现场调节阀实际开度数据进行预处理,能够有效的剔除异常噪声数据,降低数据的重复率。其中,改进的KMeans聚类算法通过设置类心过滤容忍度和类心最大偏离距离来动态调整类心个数,使得到的类心更具有数据原始分部特性。将现场调节阀开度的0~100%的开度区间等分为n个区间,并对相邻区间内均无数据的区间进行合并,将合并后每个区间内的初始特性曲线斜率k
附图说明
图1(a)为本发明实施例仿真调节阀特性曲线优化前的配置示意图;
图1(b)为本发明实施例仿真调节阀特性曲线优化后的配置示意图;
图2为本发明调节阀动态仿真特性曲线的优化步骤流程图;
图3为本发明实施例中改进动态类心调整的KMeans聚类方法流程图;
图4为KMeans与改进KMeans算法聚类结果对比图;
图5为本发明实施例数据划分区间合并后的示意图;
图6为现场调节阀的实际流量数据、仿真调节阀特性曲线优化前的调节阀动态仿真得到的流量数据,以及仿真调节阀特性曲线经优化后的调节阀动态仿真得到的流量数据三者的对比图。
具体实施方式
为清晰地阐明本发明的目的、技术方案和优点,以下将参照本发明实施例中的附图,通过实施方式清楚、完整地描述本发明的技术方案。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
调节阀的特性曲线配置示意图如图1(a)所示,其中横坐标给定开度(%)为现场调节阀的实际开度(SetOP),纵坐标综合开度(%)为参与动态仿真计算的仿真调节阀开度(RealOP)。特性曲线可通过输入给定开度和综合开度进行自主配置,通过给定开度与该特性曲线,可以得到仿真调节阀中参与动态仿真计算的综合开度,因此配置的特性曲线的精度决定了模型仿真结果的准确性和真实性。
本发明提供一种调节阀动态仿真特性曲线的优化方法,具体包括如下步骤。
S1:获取现场调节阀的历史数据、仿真调节阀相关参数以及相关物性参数,计算得到对应历史数据下的仿真调节阀综合开度;
获取现场调节阀的历史数据包括调节阀真实开度(SetOP)、阀门进口压力(P
基于获取的现场调节阀的历史数据、仿真调节阀相关参数,以及相关物性参数,进行计算得到对应历史数据下的仿真调节阀综合开度(RealOP),所述计算公式为:
S2:基于现场调节阀真实开度(SetOP)和仿真调节阀综合开度(RealOP)数据,通过改进的动态类心调整的KMeans聚类方法,对数据进行预处理;
通过改进的动态类心调整的KMeans聚类方法对现场调节阀真实开度(SetOP)数据和仿真调节阀综合开度(RealOP)数据进行预处理,达到剔除其中的异常噪声数据目的的同时,还能将大量相似的数据聚类成同一个簇,并以该簇的聚类类心来表征这些相似数据,从而降低数据的重复率。
Kmeans算法是常用的聚类算法,在给定K值和K个初始类簇中心点的情况下,将每个数据样本划分至离其最近的类簇中心点所代表的类簇中,所有数据样本分配完毕后,根据每个类簇内的所有数据样本取平均值重新计算该类簇的中心点,再通过迭代的方式进行数据样本的分配和类簇中心点的更新,直至没有或最小数目对象被重新分配给不同的聚类、类簇中心具有极小的变化或者达到指定的迭代次数,其中,Kmeans算法的类心个数,即K值是超参数不易确定,需要按经验选择确定;并且聚类结果受离群值影响较大,聚类结果可能不是全局最优而是局部最优,可靠性低。
计算步骤如下:
1、设置类心个数K,随机选取K个数据为初始类心,记为
2、定义损失函数:
3、令t=0,1,2,...为迭代步数,对于每一个样本x
4、对于每一个聚类,重新计算该聚类的类心,第t+1步迭代时的第i个类心为:
5、重复步骤3和4,直到J收敛;
本发明在KMeans聚类的基础上提出了改进动态类心调整的KMeans聚类方法,能动态调整类心K的个数,并且能有效剔除离群值造成的影响,具体参见图3,计算步骤如下:
S301:设置数据偏差容忍度Δ和数据过滤容忍度(%)σ;
S302:设置类心个数K,随机选取K个数据作为初始类心,记为
S303:定义损失函数:
S304:令t=0,1,2,...为迭代步数,对于每一个样本x
S305:对于每一个聚类,重新计算该聚类的类心,第t+1步迭代时的第i个类心为:
S306:重复步骤4和5,直到J收敛;
S307:判断每一个样本x
S308:重复步骤2~7,至所有的样本x
S309:统计每个类内样本个数占总样本数的百分比,若类内样本数量占比小于数据过滤容忍度(%)σ,则剔除该类心。
参见图4,将KMeans聚类算法得到的聚类结果与改进动态类心调整的KMeans聚类方法得到的聚类结果进行了对比。本实施例中,改进动态类心调整的KMeans聚类方法的数据偏差容忍度Δ设为0.5,数据过滤容忍度(%)σ设为1%,最终在剔除异常类心前得到的类心个数K为25,由于无法确定KMeans聚类算法的初始类心K的个数,因此将KMeans聚类算法的类心个数K也设为25。KMeans聚类方法存在5个离群类心,类心中的数据个数占总数据个数的百分比小于1%,属于异常类心,应当剔除,降低异常噪声数据的影响。
本实施例中对KMeans聚类算法进行了改进,通过设置类心过滤容忍度和类心最大偏离距离来动态调整类心个数,使得到的类心更具有数据最原始的分布特性,同时还能有效剔除离群点,离群点会影响仿真阀门特性曲线的优化结果,使优化结果偏离正常值范围,导致优化结果不可靠。
S3:根据现场调节阀给定开度将聚类获得的类心数据等分为n个区间,并将相邻区间内均无数据的区间合并为一个大空区间,基于合并后的各区间数据获得初始特性曲线;
一般情况下,现场调节阀开度(SetOP)范围在0~100%区间内,在此范围内将该区间等分为n个区间,并将聚类得到的类心数据根据其现场调节阀开度(SetOP)数据划分至各区间内。由于区间划分程度的不同,部分区间内可能无数据划入,将相邻区间内均无数据的区间合并为一个空区间,合并后的区间个数记为n’,其数据划分示意图如图5所示,本实施例中具体将现场调节阀开度(SetOP)等分为10个区间,其中60-70区间和70-80区间由于均无数据,因此合并为一个空区间。
合并区间后,以坐标原点(0,0)作为第一个区间初始特性曲线的起点,通过预设定的各区间初始特性曲线初始斜率k
其中,设定初始斜率k
S4:将各数据点到该初始特性曲线的距离总和作为优化函数,将合并后每个区间内初始特性曲线斜率k
数据点到该初始特性曲线的距离计算具体为:将通过聚类得到的各数据点(x
将所有数据点均带入初始特性曲线,即可得到各数据点到该初始特性曲线的距离总和sum|y
优化算法众多,包括Nelder-Mead Simplex、PRincipal AXIS(PRAXIS)、Constrained Optimization BY Linear Approximations(COBYLA)、BOBYQA、NEWUOA、basedon Subplex(SBPLX)等,通过对多种优化算法进行对比,PRincipal AXIS算法收敛所需迭代次数相对较少,精度较高,优化得到的特性曲线更具有代表性,本实施例中选择PRincipalAXIS算法进行寻优操作,得到的优化后特性曲线,参见图1(b)。
参见图6,图中为现场调节阀的实际流量数据、仿真调节阀优化前原始特性曲线为线性时的调节阀动态仿真得到的流量数据,以及仿真调节阀特性曲线经过优化后的调节阀动态仿真得到的流量数据三者的对比图。由此可见,仿真调节阀特性曲线在经过优化后,调节阀仿真模拟得到的流量数据与现场调节阀的实际流量数据基本接近,本发明提供的调节阀动态仿真特性曲线优化方法对调节阀动态仿真精度具有显著的提高效果。
上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 一种适用于电厂汽轮机调节阀流量特性曲线优化方法
- 一种质量流量控制器的调节阀特性优化方法