一种基于虚拟人进行人机交互的方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及虚拟人物数字数据处理技术领域,尤其涉及一种基于虚拟人进行人机交互的方法。
背景技术
随着科技的不断发展,人工智能虚拟人物数字数据处理技术越来越受到人们的关注,在虚拟现实、游戏和人机交互等领域,虚拟人物的性格特点对于增加用户体验和提升人机互动的真实感非常重要。然而,目前大多数虚拟人物在人机交互中,仅仅是能简单地与用户进行交流而缺乏个性化和丰富性格属性的表现能力,无法满足用户的多样化需求。
本发明就是基于上述情况作出的。
发明内容
本发明克服了现有技术的不足,提供了一种能让虚拟人物以设定的性格属性与用户进行人机交互从而丰富虚拟人物的性格属性表现能力的基于虚拟人进行人机交互的方法。
本发明是通过以下技术方案实现的:
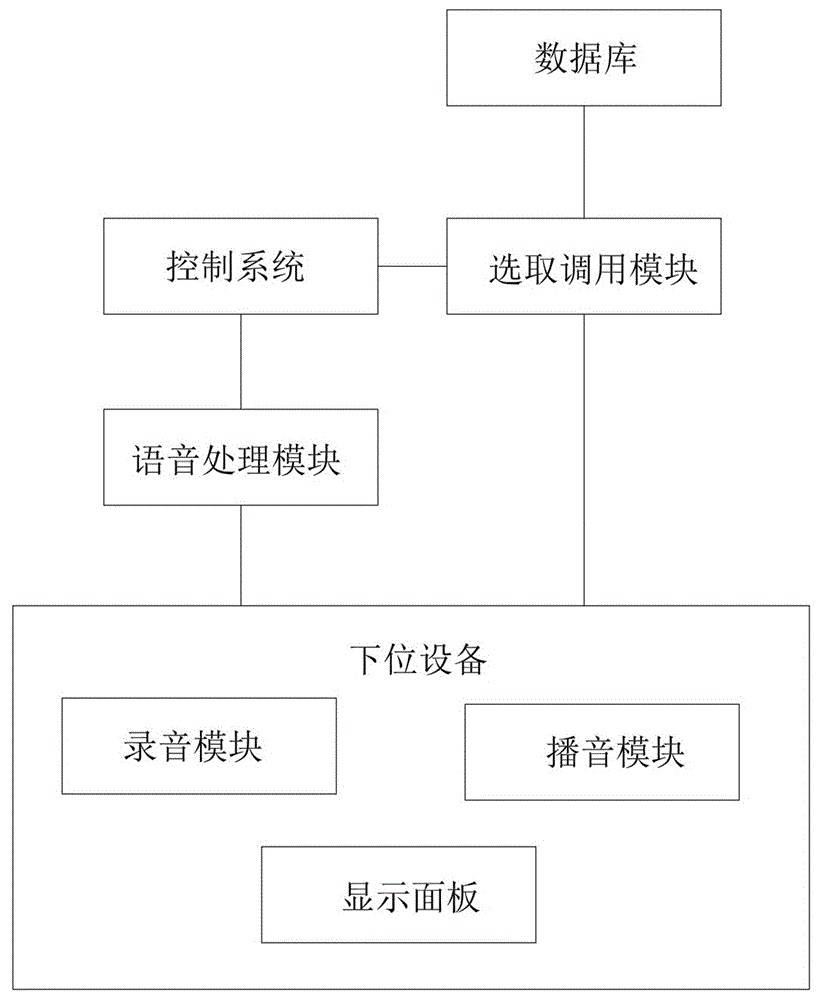
一种基于虚拟人进行人机交互的方法,包括控制系统、数据库、选取调用模块、语音处理模块、播音模块以及与控制系统通讯连接的下位设备;所述数据库内设有语音包数据集合;
所述基于虚拟人进行人机交互的方法包括以下步骤:
S1、预存语音包数据;
预先往语音包数据集合内传送多种不同性格的语音从而形成多个性格语音子集,每个性格语音子集分别对应一种性格,每个性格语音子集中包括有一种性格的语速特征、语调特征、语音韵律特征;
S2、用户语音信息采集;
将用户的语音通过下位设备传输到语音处理模块,通过语音处理模块对语音信号进行预处理,从而提高语音信号的清晰度;
S3、通过梅尔频率倒谱系数对预处理后的语音信号进行进一步处理;
S3.1、通过预加重滤波器y[n]=x[n]-0.95·x[n-1]对语音信号进行预加重;
S3.2、通过多个Mel滤波器组将200-8000Hz的语音信号分为若干个大小相等的Mel带,每个Mel滤波器组将语音信号从时域转换为梅尔频率域;
S3.3、通过将离散余弦变换应用于Mel频率滤波器组输出的对数能量,然后提取前K个系数所得到的一组特征参数,从而生成倒谱系数;
S4、通过ANN/HMM法对处理后的语音信号进行建模和训练从而取得基本模型并存储入数据库中;
S5、下位设备采集用户新的语音信息并传输至语音处理模块生成待识别的特征序列,将待识别的特征序列与训练好的基本模型进行匹配和比较,找出待识别特征所表达的文本或指令;
S6、通过语言模型根据文本的语义关联算法来预测当前词出现的概率,从而衡量不同词序列的合理性并结合声学模型的结果,选择出词序列作为识别结果;
S7、用户在下位设备选择所喜好的性格特征,控制系统控制选取调用模块调出语音包数据集合中对应性格的性格语音子集通过播音模块对识别结果进行回答或交流。
如上所述的一种基于虚拟人进行人机交互的方法,所述步骤S2中用户语音信息采集的具体方法包括:
S2.1、所述下位设备上设有录音模块,用户将一段或多段语音通过录音模块录入下位设备并传输至语音处理模块;
S2.2、语音处理模块对输入的语音信号进行预处理,进行去除噪声和增强语音;将语音信号运用通过傅里叶变换转换为频域表示,得到音频信号的频谱;
S2.3、通过带通滤波器选择性地保留频段内的信号,抑制其他频率的成分从而达到除噪效果;
S2.4、通过语音增强算法改善语音信号的清晰度。
如上所述的基于虚拟人进行人机交互的方法,所述步骤S3.2中Mel滤波器组的数量为50组。
如上所述的基于虚拟人进行人机交互的方法,所述步骤S3.3中的K为12。
如上所述的基于虚拟人进行人机交互的方法,所述数据库内还设有多个虚拟人物形象包集合,每种虚拟人物形象包集合对应一个性格语音子集,所述下位设备上设有显示面板,控制系统根据用户所选的虚拟人物性格,通过选取调用模块调取出对应的虚拟人物形象包集合在显示面板上进行展示。
如上所述的基于虚拟人进行人机交互的方法,所述的每个虚拟人物形象包集合中包含了男人物形象子集和女人物形象子集。
如上所述的基于虚拟人进行人机交互的方法,所述的性格语音子集包括温柔语音集合、开朗语音集合、沉稳语音集合、暴躁语音集合、内向语音集合。
如上所述的一种基于虚拟人进行人机交互的方法,所述的每种性格语音子集包含有男声子集和女声子集。
与现有技术相比,本发明有如下优点:
1、预先往语音包数据集合内传送多种不同性格的语音从而形成多个性格语音子集,用户选取喜好性格并通过录音模块与虚拟人物进行对话,从而丰富虚拟人物的性格属性表现能力,进而提高用户的满意度。
2、每种虚拟人物形象包集合对应一个性格语音子集,通过选取调用模块调取出对应的虚拟人物形象包集合在显示面板上进行展示,从而提高虚拟人物的个性化展示能力。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细说明,其中:
图1是本发明的模块示意图;
图2是本发明的流程示意图。
具体实施方式
下面结合附图对本发明作进一步描述:
如图1至图2所示的一种基于虚拟人进行人机交互的方法,包括控制系统、数据库、选取调用模块、语音处理模块、播音模块以及与控制系统通讯连接的下位设备;所述数据库内设有语音包数据集合;
所述基于虚拟人进行人机交互的方法包括以下步骤:
S1、预存语音包数据;
预先往语音包数据集合内传送多种不同性格的语音从而形成多个性格语音子集,每个性格语音子集分别对应一种性格,所述的性格语音子集包括温柔语音集合、开朗语音集合、沉稳语音集合、暴躁语音集合、内向语音集合等,每个性格语音子集中包括有一种性格的语速特征、语调特征、语音韵律特征;例如:内含温柔性格的性格语音子集中的语速较为缓慢、音调较低、语音韵律较为柔和舒缓;内含暴躁性格的性格语音子集中的语速较为快速、音调较高、语音韵律较为激烈急躁。
S2、用户语音信息采集;
将用户的语音通过下位设备传输到语音处理模块,通过语音处理模块对语音信号进行预处理,从而提高语音信号的清晰度;该步骤采集的语音信息用于后续训练模型的建立。
S3、通过梅尔频率倒谱系数对预处理后的语音信号进行进一步处理;通过梅尔频率倒谱系数针对人耳对声音的感知产生的唯独特性,将语音信号从时域转化至梅尔频域,并提取出一组或多组相关的梅尔频率倒谱系数。这些特征可以大大降低语音信号的维度。
S3.1、通过预加重滤波器y[n]=x[n]-0.95·x[n-1]对语音信号进行预加重;由于高频语音信号的能量较大,低频语音信号的能量较小,因此预加重可以在语音信号的前端调整其相对增益,以便更好地回收高频能量,并减少音频信号的低频部分。
S3.2、通过多个Mel滤波器组将200-8000Hz的语音信号分为若干个大小相等的Mel带,每个Mel滤波器组将语音信号从时域转换为梅尔频率域;以人耳对声音分辨度的感知为基础,将人耳的较高分辨能力范围200-8000Hz分为若干个大小相等的段,通过使用多个Mel滤波器来模拟人耳对声音的分辨能力区间。在一实施例中,Mel滤波器组的数量为50组。
S3.3、通过将离散余弦变换应用于Mel频率滤波器组输出的对数能量,然后提取前K个系数所得到的一组特征参数,从而生成倒谱系数;从Mel频率滤波器的输出中生成倒谱系数。所述的倒谱系数是指通过将离散余弦变换应用于Mel频率滤波器组输出的对数能量即取对数后的幅度,然后提取前K个系数所得到的一组特征参数。在一实施例中K取值为12。
S4、通过ANN/HMM法对处理后的语音信号进行建模和训练从而取得基本模型;ANN为人工神经网络,其一般的步骤为:
a、数据准备:收集和整理用于训练和测试的数据集。
b、网络设计:选择网络结构,包括选择适当的神经元层数、节点数和连接方式等。
c、初始化权重:为神经网络的连接权重赋初值。
d、前向传播:将输入数据通过网络,计算每个神经元的输出。
e、计算损失:比较神经网络的输出结果与期望的标签或值,计算损失函数值。
f、反向传播:根据损失函数值,通过梯度下降算法调整网络中的权重,以最小化损失函数。
重复步骤d-f,直到达到停止条件,例如达到最大迭代次数或损失函数收敛。
g、模型评估:使用独立的测试数据集评估训练好的模型的性能。
HMM为隐马尔可夫模型,其一般的步骤为:
a、数据准备:准备用于训练和测试的序列数据集,包括观测序列和对应的隐藏状态序列。
b、参数初始化:初始化HMM模型的转移概率矩阵、观测概率矩阵和初始状态分布参数。
c、前向算法:使用前向算法计算观测序列出现的概率,以及给定观测序列和模型参数的情况下,每个时间步的前向概率。
d、后向算法:使用后向算法计算给定观测序列和模型参数的情况下,每个时间步的后向概率。
e、Baum-Welch算法:通过比较前向概率和后向概率,使用Baum-Welch算法估计HMM模型参数,包括转移概率矩阵、观测概率矩阵和初始状态分布参数。
f、解码和预测:使用维特比算法或其他解码方法,根据模型参数和观测序列,推断出最可能的隐藏状态序列。
g、模型评估:使用独立的测试数据集评估训练好的HMM模型的性能。
S5、下位设备采集用户新的语音信息并传输至语音处理模块生成待识别的特征序列,将待识别的特征序列与训练好的基本模型进行匹配和比较,找出待识别特征所表达的文本或指令;该步骤采集的语音信息为模型训练好后,新的命令信息。
S6、通过语言模型根据文本的语义关联算法来预测当前词出现的概率,从而衡量不同词序列的合理性并结合声学模型的结果,选择出最优的词序列作为识别结果;
S7、用户在下位设备选择所喜好的性格特征,控制系统控制选取调用模块调出语音包数据集合中对应性格的性格语音子集通过播音模块对识别结果进行回答或交流,从而丰富虚拟人物的性格属性表现能力,进而提高用户的满意度。
在一实施例中,所述步骤S2中用户语音信息采集的具体方法包括:
S2.1、所述下位设备上设有录音模块,用户将一段或多段语音通过录音模块录入下位设备并传输至语音处理模块;
S2.2、语音处理模块对输入的语音信号进行预处理,进行去除噪声和增强语音;将语音信号运用通过傅里叶变换转换为频域表示,得到音频信号的频谱;
S2.3、通过带通滤波器选择性地保留频段内的信号,抑制其他频率的成分从而达到除噪效果;
S2.4、通过语音增强算法改善语音信号的清晰度。从而提高语音识别的准确度。
数据库内还设有多个虚拟人物形象包集合,每种虚拟人物形象包集合对应一个性格语音子集,所述下位设备上设有显示面板,控制系统根据用户所选的虚拟人物性格,通过选取调用模块调取出对应的虚拟人物形象包集合在显示面板上进行展示。例如:对应温柔性格语音子集的虚拟人物形象包集合中虚拟人物形象的面部特征线条较为柔和、面带笑意、虚拟人物形象的动作较为轻柔、衣物和饰品等物品的颜色为暖色调颜色,所述的暖色调颜色包括红色、粉色、橙色、黄色等。从而提高虚拟人物的个性化展示能力。
上述的每个虚拟人物形象包集合中包含了男人物形象子集和女人物形象子集,上述的每种性格语音子集包含有男声子集和女声子集。可以通过初始时用户选择虚拟人物的性别来对应调取出相应性别的人物物形象子集和性格语音子集。
- 基于需求层次的河流综合治理规划方法
- 基于鱼类生境需求的多闸坝平原河流生态流量过程推求方法