一种基于群体学习的化工配方识别方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及文本分类技术领域,具体涉及一种基于群体学习的化工配方识别方法。
背景技术
配方研究在化学工业中,特别是对精细化工产品的开发极为重要。西方工业发达国家对此十分重视,在一家化学公司中,研究配方的工作人员有时会比研究合成工艺的工作人员还要多。这是一种重视应用开发的结果。其原因在于很少有一种单一的化学品能完全符合某一项特定的最终用途。例如,阿司匹林要复配制成复方阿司匹林的药片;洗涤剂是由若干种不同结构的表面活性剂及化工产品复配而成;染料的使用必须加入各种助剂。化工行业中的一个配方由基料(主料)和辅料(细料)两部分组成,基料部分主要指用量较多;细料部分主要指用量少,成份与配比直接影响产品品质与性能的那部分物料集合。而且配方作为化工类企业的技术核心,通常要求保密,特别是配方中细料部分保密级别更高。
随着数据隐私和安全性问题受到越来越多的关注,基于AI的化工配方识别方法本质上依赖于大型训练数据集。由于化工企业本身是分散的,本地的数据量往往不足以训练出可靠的分类系统。而且不同中心甚至国家之间的化工配方研究数据交换往往受到数据保护、隐私保护和数据主权法规的约束。技术问题同样也会影响数据使用,比如当需要以数字方式传输大量数据时,数据传输线路很快会达到其性能极限。鉴于这些情况,许多配方研究仅限于本地,很难利用其他地方可用的数据。
发明内容
发明目的:针对现有技术中存在的问题,本发明提供一种基于群体学习的化工配方识别方法,采用该方法能够准确的识别出化工配方,有效解决配方数据保存在数据所有者的本地,不需要交换原始数据,还可以提供高水平的数据安全,允许参数合并,所有成员的权利平等;可以保护机器学习模型免受攻击。
技术方案:本发明提供了一种基于群体学习的化工配方识别方法,包括如下步骤:
步骤1:采集并保存N个不同化工企业的化工配方数据,对化工配方数据制作成数据集;
步骤2:将N个不同化工企业的化工配方数据集进行预处理得到N个训练数据集,同时获取另一个化工企业的化工配方数据,预处理后得到一个全局测试数据集;
步骤3:将N个不同化工企业的训练数据集分布在N个不同群体学习框架的Swarm节点上,并在N个节点的化工配方数据集上分别构建改进后的文本分类模型;所述改进后的文本分类模型分为两个分支,第一个分支包含多层卷积神经网络,第二个分支包含双向长短期记忆网络以及自注意力机制;
步骤4:N个节点之间进行化工配方识别模型参数的更新,通过Swarm应用编程接口API进行交换,并在开始新一轮训练之前,合并创建一个参数更新的更新模型,直至满足定义的同步条件,停止训练得到更新后的模型;
步骤5:输入待识别的全局测试数据集,通过群体学习训练得到的更新模型对化工配方进行分类识别。
进一步地,所述步骤2中的数据预处理包括去重、去空处理。
进一步地,所述步骤3中改进后的文本分类模型将第一个分支取出的局部数据特征与第二个分支提取出的全局数据特征通过融合层Keras框架的ADD()函数对其进行融合;将得到的数据特征分别输送到最大池化层与平均池化层;
通过融合层Keras框架的ADD()函数对最大池化层与平均池化层进行融合,得到数据特征;
将数据特征输入全连接层,训练Softmax分类器,将数据特征输入Softmax进行训练,完成改进后的文本分类模型的构造。
进一步地,所述步骤4中N个节点之间进行化工配方识别模型参数的更新,通过Swarm应用编程接口API进行交换,并在开始新一轮训练之前,合并创建一个参数更新的更新模型具体步骤如下:
N个节点共享其学习到的参数,并合并它们的参数;合并周期由同步间隔定义,指定了SL节点合并其学习参数之后的训练批的数量,在每个间隔的最后,将其中一个群学习SL节点选为领导者,领导者从其他群学习SL节点收集模型参数,并通过平均学习到的参数将它们合并到领导者模型中;之后,领导者SL节点接收到更新后的模型并启动下一个间隔;直至训练到epochs结束后,停止训练得到最终更新后的模型。
进一步地,所述化工企业数量为2,群体学习框架的Swarm节点设置有2个,使用两个群网络SN节点,代表这两个节点的docker容器的名称是SN1和 SN2;SN1是哨兵节点,SN1在主机 192.168.121.129 上运行,SN2 在主机 192.168.121.130 上运行;群学习SL节点和机器学习ML节点在训练期间由群操作员SWOP节点自动生成,并在训练后删除;使用两个SWOP节点连接到每个SN节点;代表这两个SWOP 节点的docker容器的名称是SWOP1和SWOP2;SWOP1在主机192.168.121.129上运行,SWOP2在主机192.168.121.130上运行;训练由在主机192.168.121.129上运行的SWCI节点启动,初始化后,SL1节点定期与SL2节点共享其学习到的参数,并合并它们的参数。
有益效果
1、本发明采用群体学习的平台,可以将化工配方数据保存在数据所有者的本地,而不需要交换原始数据,并且可以提供高水平的数据安全,允许参数合并,所有成员的权利平等,可以保护机器学习模型免受攻击。
2、本发明基于已有的TextCNN算法,组合BiLSTM算法、Self-Attention机制和TextCNN算法,提取化工配方文本特征。通过Keras框架的Add()函数对两种算法提取的特征进行融合,使融合后的特征既有局部特征又有全局特征。通过Keras框架的Add()函数对上一步输出的特征进行最大池化和平均池化,进一步提高训练速度。通过Softmax分类器进行分类输出,提高了化工配方的分类准确率,充分考虑了化工配方的特点,使特征处理更加优化,分类更加准确。
附图说明
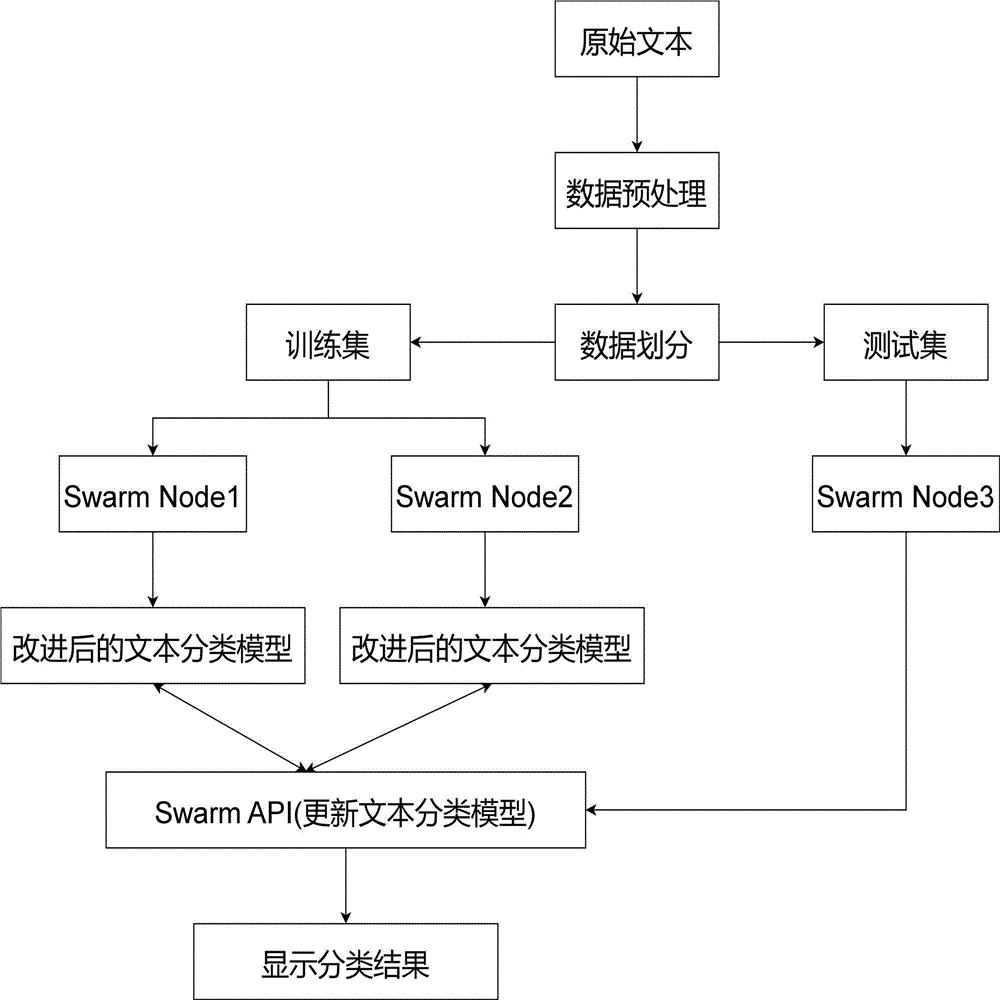
图1为基于群体学习的化工配方识别方法的流程图;
图2为群体学习的网络模型;
图3为改进的文本分类的模型;
图4为模型参数更新的模型。
实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
本发明提出了一种基于群体学习的化工配方识别方法,参见图1,本实施例以2个企业的化工数据为例进行说明,具体包括如下步骤:
步骤1:采集并保存2个不同化工企业的化工配方数据,对其化工配方数据制作成数据集,化工配方分为5类:胶粘剂、化妆品、药物、橡胶以及杀虫剂。
步骤2:将2组化工配方数据集分别划分为若干个不重复的训练数据,并获取另外一个化工企业的化工配方数据作为一个全局测试数据集,并对数据进行去重、去空处理,得到预处理后的数据集。
步骤3:构建群体学习网络模型,如图2所示,将步骤2中的训练数据集分布在两个不同Swarm节点上,并在两个节点(Node)的私人数据上分别构建模型,群体学习提供安全措施以支持数据主权、安全和保密性(这由私人许可的区块链技术实现)。每个参与者都有明确的定义,只有预先授权的参与者可以执行交易。
改进的文本分类模型,如图3所示,分为两个分支,第一个分支包含多层卷积神经网络,第二个分支包含双向长短期记忆网络以及自注意力机制,将第一个分支取出的局部数据特征与第二个分支提取出的全局数据特征通过融合层Keras框架的ADD()函数对其进行融合;将得到的数据特征分别输送到最大池化层与平均池化层,提高训练速度。
通过融合层Keras框架的ADD()函数对最大池化层与平均池化层进行融合,得到数据特征。
将数据特征输入全连接层,训练Softmax分类器,将数据特征输入Softmax进行训练,完成改进后的文本分类模型的构造。
在步骤3中,采用的是Adam优化器,损失函数是交叉熵损失函数,训练批次30次,初始学习率设置0.00001,批次大小设置为32。
交叉熵损失函数的公式:
其中,x的预测结果p(x)越大,则交叉熵f(x)越小。
步骤4:模型参数更新,如图4所示,两个节点之间进行化工配方识别模型参数的更新,通过Swarm应用编程接口(API)进行交换。使用两个群网络(SN)节点,代表这两个节点的docker容器的名称是SN1和SN2。SN1是哨兵节点。SN1 在主机 192.168.121.129 上运行。SN2 在主机 192.168.121.130 上运行。群学习(SL)和机器学习(ML)节点在训练期间由群操作员(SWOP)节点自动生成,并在训练后删除。使用两个SWOP节点连接到每个SN节点。代表这两个SWOP 节点的docker容器的名称是SWOP1和SWOP2。SWOP1在主机192.168.121.129上运行。SWOP2在主机192.168.121.130上运行。训练由在主机192.168.121.129上运行的SWCI节点(swci1)启动。初始化后,SL1节点定期与SL2节点共享其学习到的参数,并合并它们的参数。这种合并周期由同步间隔(SI)定义,它指定了SL节点合并其学习参数之后的训练批的数量。在每个间隔的最后,将其中一个SL节点选为领导者。领导者从另一个SL节点收集模型参数,并通过平均它们学习到的参数将它们合并到领导者模型中。之后,领导者SL节点接收到更新后的模型并启动下一个间隔。直至训练到epochs结束后,停止训练得到最终更新后的模型。
步骤5:对待识别的全局测试数据集,通过群体学习训练得到的更新模型对化工配方进行分类识别。
本发明的性能指标评价采用准确率(Accuracy)评价指标公式如下:
这个指标主要是用来指示预测正确的样本数占总样本数的个数。
上述实施方式只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所做的等效变换或修饰,都应涵盖在本发明的保护范围之内。
- 一种基于学习等级的测试题分配方法及学习客户端
- 一种基于多标签学习的群体软件开发中服务匹配方法
- 一种基于粗粒度-细粒度嵌套学习的群体活动识别方法