基于多智能体近端策略优化算法的深空探测器任务规划方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及一种基于多智能体近端策略优化算法的深空探测器任务规划方法,属于航空航天技术领域。
背景技术
深空探测领域是现今世界重要技术发展领域之一,深空探测由于其探测对象的可知特征不完备性和环境的复杂性,使得附着任务难度很大,为了顺利地完成科学探索任务,深空探测器在附着过程中,需要具备对各种任务进行规划的能力,根据各种外界环境、自身系统的状态以及各种约束条件,规划出一组可执行的动作序列。
深空探测器多智能体自主协同任务规划问题是一个多约束、高冲突的复杂组合优化问题,即在满足任务约束、资源约束和时间约束的前提下,怎么安排一组动作序列及执行时间,使得任务收益最高,资源消耗最少,时间消耗最少等一个或多个目标函数达到最优。该问题一直备受各国学者的关注,并进行了多角度的探索和研究。
高艾等在中国授权发明专利CN114399225A中公开了“一种基于Q-Learning的深空探测器任务规划方法”,采用Q-Learning方法对任务规划进行训练,但该方法没有实现多智能体的协作规划,而采用MAPPO算法进行多智能体深空探测器任务规划的方法尚未见记载。
发明内容
本发明提供了一种基于多智能体近端策略优化算法的深空探测器任务规划方法,以用于实现深空探测器任务规划。
本发明的技术方案是:
根据本发明的一方面,提供了一种基于多智能体近端策略优化算法的深空探测器任务规划方法,包括:将多智能体规划问题建模为多智能体马尔科夫决策过程;依据多智能体马尔科夫决策过程,构建深空探测器多智能体任务规划环境;构建深空探测器多智能体近端策略优化模型;训练深空探测器多智能体近端策略优化模型,得到多智能体任务规划最优策略;利用训练好的多智能体任务规划最优策略进行深空探测器任务规划。
所述将多智能体规划问题建模为多智能体马尔科夫决策过程,具体为:
将深空探测器中的各个子系统视作一个单独的智能体,深空探测器视作由多个智能体组成的集合;将多智能体规划问题Pro描述为:
Pro=(I,G,K,A
其中,I表示深空探测器任务的初始状态,G表示深空探测器任务的目标状态,K为深空探测器任务规划的知识域,包括子系统名称、子系统状态、动作、动作的前提约束、状态转移关系;A
根据对多智能体规划问题的描述,将多智能体规划问题建模为多智能体马尔科夫决策过程M,包括:
M=
S=S
A=A
P=P(s
R=r(s
γ∈[0,1];
其中,N表示深空探测器子系统的总数量;S表示深空探测器所有子系统状态的集合,S
π={π
π
其中,π表示深空探测器的联合策略,π
所述奖励函数R设定为:
R=P+R
其中,P表示负向奖励值,R
所述负向奖励值P:
P=P
P
其中,P
所述正向奖励值R
所述构建深空探测器多智能体近端策略优化模型,包括:结合构建的深空探测器多智能体任务规划环境,定义两个网络,分别为对策略进行模拟的actor策略网络和对状态价值函数进行模拟的critic价值网络。
所述actor策略网络采用CNN网络或者RNN网络;所述critic价值网络采用CNN网络。
引入噪声正则化优势值:为每个智能体采样一个高斯噪声,使用有噪声的优势值来训练多智能体的策略;
或者,引入噪声正则化状态价值函数:随机采样N个高斯噪声构成高斯噪声向量,然后连接高斯噪声向量和深空探测器所有智能体状态集合输入到critic价值网络中,生成噪声值给每个智能体,并传播到优势值。
根据本发明的另一方面,提供了一种基于多智能体近端策略优化算法深空探测器任务规划系统,包括上述中任意一项所述方法的模块。
根据本发明的另一方面,提供了一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行上述中任意一项所述的基于多智能体近端策略优化算法的深空探测器任务规划方法。
本发明的有益效果是:
本发明考虑到了探测器的并行、分布特性,因此采用多智能体建模,充分利用各个子系统的知识和专门经验;同时本发明基于MAPPO算法,该算法是一种多智能体近端策略优化深度强化学习算法,深度强化学习是一种根据奖励信号决策动作的方法,无需具体指示每一步的执行细节,具有一定的自主性;该方法属于on-policy算法,是近端策略优化(PPO)算法用于多智能体任务的改进算法,采用的是actor-critic架构,通过其可以是寻找一种最优策略用于生成智能体的最优动作。
附图说明
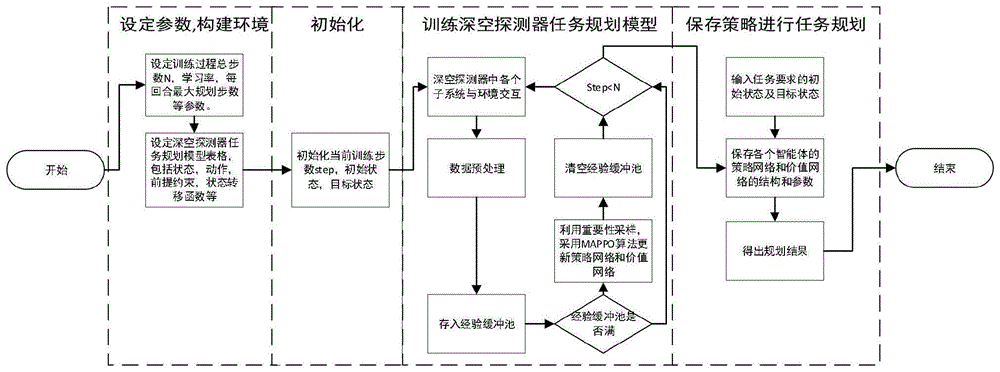
图1是本发明流程图;
图2是本发明的深空探测器任务规划结果甘特图;
图3是本发明的训练时的奖励回报曲线图。
具体实施方式
下面结合附图和实施例,对发明作进一步的说明,但本发明的内容并不限于所述范围。
实施例1:如图1-3所示,一种基于多智能体近端策略优化算法的深空探测器任务规划方法,包括:将多智能体规划问题建模为多智能体马尔科夫决策过程;依据多智能体马尔科夫决策过程,构建深空探测器多智能体任务规划环境;构建深空探测器多智能体近端策略优化模型;训练深空探测器多智能体近端策略优化模型,得到多智能体任务规划最优策略;利用训练好的多智能体任务规划最优策略进行深空探测器任务规划。
进一步地,所述将多智能体规划问题建模为多智能体马尔科夫决策过程,具体为:
将深空探测器中的各个子系统视作一个单独的智能体,深空探测器视作由多个智能体组成的集合;将多智能体规划问题Pro描述为:
Pro=(I,G,K,A
其中,I表示深空探测器任务的初始状态,G表示深空探测器任务的目标状态,K为深空探测器任务规划的知识域,包括子系统名称、子系统状态、动作、动作的前提约束、状态转移关系;A
根据上述对多智能体规划问题的描述,可以将多智能体规划问题建模为多智能体马尔科夫决策过程M,包括:
M=
S=S
A=A
P=P(s
R=r(s
γ∈[0,1];
其中,N表示深空探测器子系统的总数量;S表示深空探测器所有子系统状态的集合,S
π={π
π
其中,π表示深空探测器的联合策略,π
进一步地,所述奖励函数R的具体设置如下:
本文的奖励函数R设定为:
R=P+R
为了使深空探测器规划的任务序列为最优的动作序列,在深空探测器子系统的每步动作都给予了一个惩罚值P,即负向奖励值:
P=P
P
其中,P
进一步地,所述正向奖励值R
R
奖励函数作为决策目标的一种表征形式,在反应规划目标的同时,也为各个智能体学习如何决策提供引导。在奖励函数的设计上,该场景是合作型的多智能体强化学习任务,因此规划结束后各个智能体共享一个相同的奖励值。
进一步地,所述依据多智能体马尔科夫决策过程,构建深空探测器多智能体任务规划环境,具体为:依据状态空间、动作空间、奖励函数、状态转移函数,构建深空探测器多智能体任务规划环境。
进一步地,所述构建深空探测器多智能体近端策略优化模型,包括:结合构建的深空探测器多智能体任务规划环境,定义两个网络,分别为对策略π进行模拟的actor策略网络和对状态价值函数V进行模拟的critic价值网络。
进一步地,所述actor策略网络采用CNN网络或者RNN网络;所述critic价值网络采用CNN网络。
进一步地,引入噪声正则化优势值:为每个智能体采样一个高斯噪声,使用有噪声的优势值来训练多智能体的策略;或者,引入噪声正则化状态价值函数:随机采样N个高斯噪声构成高斯噪声向量,然后连接高斯噪声向量和深空探测器所有智能体状态集合输入到Critic价值网络中,生成噪声值给每个智能体,并传播到优势值。
所述状态价值函数V(S)=∑
第i个智能体的状态价值函数为:
为了衡量在s状态下采取a动作相对于平均水平的优势,引入优势函数,公式为:
A(s,a)=Q(s,a)-V(s);
Q(s,a)表示在状态s下采取动作a后预期的总回报,V(s)表示在状态s下预期的总回报。
本文采用GAE方法估计优势函数,具体如下:
定义:δ
然后对这n步的优势函数通过引入折扣因子λ(0≤λ≤1)加权平均,λ用来平衡估计的方差与偏差。如果λ=0,GAE的形式为TD误差的形式,有偏差但是方差小,而当λ趋近1时,则减少了估计值的方差,但是同时增加了偏差,就变成了蒙特卡洛目标值和价值估计之间的差。最终GAE计算的优势函数表示为:
所述actor策略网络为五层,第一层为输入层,输入量为归一化处理后的深空探测器各个子系统下的状态s
Actor网络优化目标为:
其中,L
所述Critic价值网络为六层,价值网络的输入量为归一化处理后的深空探测器所有智能体状态集合S(即全局状态量),第一层为输入层,第二层是64个节点的全连接层,第三层是64个节点的隐藏层,第四层是64个节点的全连接层,第五层是LayerNorm归一化层,第六层是输出层,输出量为深空探测器所有智能体状态集合S对应的状态价值函数V。
Critic网络优化目标为:
其中,L(φ)是Critic网络的价值梯度损失函数,φ是Critic网络的参数,我们的目标是最小化这个损失函数以更新价值函数的参数φ。B是批次大小,n是每个批次中的样本数量。
Critic价值网络的输入为深空探测器全局状态,这样可以更好地掌握全局状态,促进智能体的合作,但是也给中心化的价值网络带来了策略过拟合问题,这一问题主要是因为利用Critic网络的全局输出获得Actor网络的优势值为全局优势值
为了分解出正确的
第一种解决方式:
引入噪声正则化优势值:为每个智能体采样一个高斯噪声;
其中,N是智能体的数量,下一步在由GAE方法计算的优势值
第二种解决方式:
引入噪声正则化状态价值函数:随机采样N个高斯噪声
高斯噪声x
所述深空探测器多智能体近端策略优化模型的训练过程包括:设定参数、初始化、采样、更新参数。
步骤4.1:设定超参数,设定训练的总步数、学习率、batchsize、每回合最大步数参数等;
步骤4.2:在每个回合初始化深空探测器各个子系统的状态,之后每个智能体使用当前策略与环境交互,利用Actor网络生成一组动作序列,即样本,之后将样本进行数据预处理后,按照时间序列存入经验池中;
步骤4.3:更新参数,当经验池的数据存满时,将数据取出,利用重要性采样,利用MAPPO算法对策略网络和价值网络进行参数更新;不断循环以上几个步骤,直到达到设定的训练总步数,得到最终的深空探测器任务规划最优策略。
进一步地,利用训练好深空探测器多智能体近端策略优化模型进行深空探测器小行星着陆任务规划,具体为:依据需要执行的多智能体问题规划问题P输入初始状态、目标状态,利用训练完成的深空探测器多智能体近端策略优化模型进行规划,直到智能体到达终止状态结束规划,输出任务规划的动作序列A
根据本发明的另一方面,提供了一种基于多智能体近端策略优化算法深空探测器任务规划系统,包括上述中任意一项所述方法的模块。
根据本发明实施例的另一方面,提供了一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行上述中任意一项所述的基于多智能体近端策略优化算法的深空探测器任务规划方法。
再进一步地,以深空探测器小天体附着规划任务为例,下面结合附图,对本发明可选地具体实施方式进行如下说明:
第一步,设定超参数,如下表1所示;
表1超参数设置
第二步,依据状态空间、动作空间、奖励函数、状态转移函数,构建深空探测器多智能体任务规划环境,状态空间、动作空间数据如表2所示,状态转移函数及资源消耗数据如表3所示;本实验的规划目标为完成附着任务,比如当拍摄子系统动作为触发快门时第二正向奖励值为100,综电子系统动作为启动拍摄任务时第二正向奖励值为50,当附着任务完成时第一正向奖励值为100,当规划失败步数超过50时规划失败,第二负向奖励值为-100。每执行一个动作都会消耗一定的资源,给予一定的惩罚,第一负向奖励值为(-0.2×存储空间-0.2×电量-0.5×油量-0.1×动作执行时间)。
表2深空探测器子系统状态动作表
表3深空探测器状态转移表
/>
/>
第三步,训练深空探测器任务规划模型,首先深空探测器中各个子系统与环境交互,交互得到的数据经过数据预处理存入经验缓冲池,之后判断经验池是否充满,如果没有充满且当前训练步数小于总步数N,则继续采集数据直到经验池充满。如果充满则利用重要性采样,利用MAPPO算法更新策略网络和价值网络。之后清空经验缓冲池,判断当前训练步数是否小于总步数N,如果小于则继续执行第三步。不断循环该过程直到当前训练步数等于总步数N,则输出训练好的各个智能体的策略网络和价值网络的结构和参数;
第四步,利用训练好的网络进行任务规划。首先输入实际任务要求的初始状态和目标状态,利用训练好的网络进行任务规划,得到规划结果,如图2所示。
第五步,对比实验及结果分析:
1、多智能体强化学习任务规划奖励值对比实验:对模型进行训练评估,当最大规划步数为50时的奖励值的折线图如图3所示。引入噪声噪声正则化状态价值函数的NV-RMAPPO相较于MAPPO的奖励值有较大的提高。不使用RNN的NV-MAPPO,NA-MAPPO,MAPPO的都表现欠佳,使用了RNN的NV-RMAPPO和NA-RMAPPO相较于RMAPPO收敛速度更快,在70000步左右时就已经收敛,而RMAPPO在400000步时左右才开始收敛,并且收敛的奖励值更高,同时引入噪声正则化优势值对算法的收敛结果的提升较为明显。其中,NV-RMAPPO表示的是本发明采用引入噪声正则化状态价值函数+策略网络与价值网络分别设为RNN的方法;NA-RMAPPO表示的是本发明采用引入噪声正则化优势值+策略网络与价值网络分别设为RNN的方法;RMAPPO、NV-MAPPO、NA-MAPPO、MAPPO表示本发明的对照方法(MAPPO表示策略网络与价值网络分别设为CNN的方法,RMAPPO表示策略网络与价值网络分别设为RNN的方法,NV-MAPPO表示的是本发明采用引入噪声正则化状态价值函数+策略网络与价值网络分别设为CNN的方法;NA-MAPPO表示的是本发明采用引入噪声正则化优势值+策略网络与价值网络分别设为CNN的方法)。基于上述可知,采用NV-RMAPPO的性能最优。
2、多智能体强化学习任务规划的规划成功率对比实验:本发明将MAPPO中的策略网络与价值网络中的网络模型分别设为CNN和RNN,与不添加噪声,添加噪声给优势值和添加噪声给价值函数的方法进行组合,一共设置六种算法进行实验,取最大规划步数分别为50,100,150,200,最大规划步数越短,规划难度越高,每次实验用该算法进行500000步规划。不同算法在不同最大规划步数下的规划成功率如表4所示。
表4不同算法在不同最大规划步数下的平均规划成功率
根据实验结果可以得出,NV-RMAPPO在不同的最大规划步数下成功率均在85%以上,就算在高规划难度即最大规划步数为50的情况下,基于本发明方法建立的NV-RMAPPO的成功率相较于MAPPO仍然提高了31%,且相较于其他算法均有较高提升,因此表明NV-RMAPPO具有显著优势。
3、多智能体强化学习任务规划的规划时间对比实验:当最大规划步数为50时,取每次实验的平均规划耗时的均值为该次实验的最终结果,如表5所示。
表5不同算法在最大规划步数为50时的平均规划时长(单位:秒)
通过表5的结果可以看出,NV-MAPPO和NA-MAPPO的规划时长在0.3秒左右,比MAPPO算法规划速度快了3.2秒,相较于其他算法规划效率较高。
由仿真结果可以看出,采用本发明算法能够实现深空探测器小天体附着自主规划任务,规划结果较为合理,证明了本发明方法的有效性和适用性。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 一种基于Q-Learning的深空探测器任务规划方法
- 基于动态奖励的强化学习深空探测器自主任务规划方法及系统