一种能源互联网中基于深度强化学习的数字孪生映射方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及能源互联网数据映射领域,特别涉及一种能源互联网中基于深度强化学习的数字孪生映射方法。
背景技术
能源互联网系统(IoE)是由光伏、风力涡轮机、发电机等与发电相关的设备相互连接形成的系统。为了保证IoE系统的稳定运行,需要对IoE系统的电网系统进行实时监控,主动诊断系统故障(K.Wang,J.Yu,Y.Yu,Y.Qian,D.Zeng,S.Guo,Y.Xiang,and J.Wu,“Asurveyon energy internet:Architecture,approach,and emergingtechnologies,”IEEESystems Journal,vol.12,no.3,pp.2403-2416,2018.)。IoE系统的电网系统监控需要实时数据处理。因此,这样的监测系统应该能够实时处理数据。数字孪生(DT)作为一种网络物理集成技术,越来越受到学术界和工业界的关注。数字孪生被广泛应用于不同行业(T.Fei,Z.Meng,C.JiangFeng,and Q.QingLin,“Digital twin workshop:a new paradigm forfuture workshop,”Computer Integrated Manufacturing Systems,vol.23,no.no.1,2017.),如产品设计(G.L.Knapp,T.Mukherjee,J.S.Zuback,H.L.Wei,T.A.Palmer,A.De,and T.Debroy,“Building blocks for a digital twin of additivemanufacturing,”Acta Materialia,vol.135,pp.390-399,2017.)、预测(G.Zhang,C.Huo,L.Zheng,andX.Li,“An architecture based on digitaltwins for smart power distributionsystem,”in 2020 3rd InternationalConference on Artificial Intelligence andBig Data(ICAIBD),2020.)、医疗(B.Koen,S.Filippo,and V.Jeroen,“Digital twins inhealth care:Ethical implications of an emerging engineering paradigm,”Frontiersin Genetics,vol.9,pp.31-,2018.)、(B.Zhang,K.Anastasia,B.Lai,andR.Milica,“Advances in organ-ona-chip engineering,”Nature Reviews Materials,2018.)、(J.Pang,J.Li,Z.Xie,Y.Huang,and Z.Cai,“Collaborative city digitaltwinfor covid-19pandemic:A federated learning solution,”2020.)。DT可以使用实时数据创建系统的虚拟数字描述,从而提供物理世界和虚拟空间之间的实时交互。由于DT可以有效地处理实时数据,DT已被用于实现IoE的实时监测系统(X.He,Q.Ai,J.Wang,F.Tao,B.Pan,R.Qiu,and B.Yang,“Situationawareness of energy internet of thing insmart city based on digital twin:From digitization to informatization,”IEEEInternet of Things Journal,pp.1-1,2022.)。
数字孪生利用物联网(IoT)技术和机器学习(ML)知识来创建能源互联网的虚拟数字描述。虚拟数字描述可以真实地反映物理对象的特征、行为、形成过程和性能。IoE系统中传感器收集的实时数据可以映射到数字孪生中,以跟踪和监控物理对象。此外,DT还可以对物理对象进行预测、分析、故障诊断和预警。传感器采集的所有实时数据都可以映射到DT上,形成与物理对象具有相同状态、相同属性和相同变化过程的虚拟数字描述,而这个与物理世界相同的DT系统可能非常复杂或包含不必要的冗余信息。事实上,没有必要构建一个与真实世界相同的DT系统(L.Zhang,L.Zhou,and B.Horn,“Building a right digitaltwin withmodel engineering,”Journal of Manufacturing Systems,vol.59,no.2,pp.151-164,2021.),这意味着不是所有传感器采集的实时数据都要映射到数字空间。因此,需要一种数据映射机制来选择和传输物理世界中的数据到虚拟世界中。
目前的数字孪生映射机制包括完全映射机制和不完全映射机制。完全映射机制将物理世界中传感器收集的所有实时数据映射到数字孪生。L.Zhang,L.Zhou,and B.Horn,“Building a right digital twin withmodel engineering,”Journal ofManufacturing Systems,vol.59,no.2,pp.151-164,2021.认为DT数据应该包括传感器数据(如材料库存、人力工作量、设备容量)和企业信息系统数据(如产品生命周期数据、工艺文档、市场数据)。在DT模型迭代更新过程中,虚拟模型与物理实体之间的交互需要频繁交换大量数据。由于资源消耗和数据冗余等问题,大量物理世界实体的数据映射无法满足DT的实时性要求。为了保证DT系统的有效运行,必须保证映射数据的质量。不完全映射机制将部分实时数据映射到数字孪生。A.Al-Ali,R.Gupta,T.Batool,T.Landolsi,F.Aloul,andA.Al Nabulsi,“Digital twin conceptual model within the context of internet ofthings,”Future Internet,vol.12,p.163,092020.表示,当物理对象发生变化时,传感器会捕捉到变化并发送到DT系统。DT系统从数据存储库中读取更新后的数据,并创建反映当前物理对象或当前系统的模型。与完整映射机制相比,不完整映射机制减少了映射数据量。因此,不完全映射机制可以减少数据映射过程对资源的消耗。不完全映射机制可以通过降低传感器的数据采样率来减少数据量。然而,降低传感器的数据采样率可能会丢失重要的数据点。传感器自适应采样方法可以在一定程度上解决这一问题。然而,传感器自适应采样方法不能保证重要数据点的获取。因此,目前的不完全映射方法会导致数据映射精度低的问题。
发明内容
本发明目的是为了解决现有数字孪生映射方法还存在映射精度低的问题,而提出了一种能源互联网中基于深度强化学习的数字孪生映射方法。
一种能源互联网中基于深度强化学习的数字孪生映射方法具体过程为:
步骤一、获取实体数据;
所述实体数据为能源互联网系统中传感器获取的数据,包括:电压幅值、相角、发电机负荷、线路上的有功与无功功率;
步骤二、将步骤一获取的实体数据输入到映射模型中,获得待映射的实体数据;
所述映射模型基于深度强化学习PPO算法学习映射数据的特征,从而获得待映射实体数据的时刻;
所述映射模型包括:单传感器映射模型、多传感器映射模型;
若步骤一获取的实体数据从一种类型的传感器中获取,则采用单传感器映射模型获取待映射的实体数据;
若步骤一获取的实体数据从多种类型的传感器中获取,则采用多传感器映射模型获取待映射的实体数据。
进一步地,所述实体数据从一种类型的传感器或多种类型的传感器中获取,具体为:
获取每个传感器获取的实体数据,并绘制曲线作为物理世界曲线;
获取所有物理世界曲线中极值点对应时刻之间的误差,将极值点对应的时刻误差与预设误差比较;
若所有物理世界曲线极值点对应的时刻误差都小于等于预设误差,则随机获取一个类型的传感器获取的实体数据;
若一部分物理世界曲线极值点对应的时刻误差小于预设误差,一部分物理世界曲线极值点对应的时刻误差大于预设误差,则在小于等于预设误差的时刻误差对应的传感器中,随机从一个类型的传感器获取实体数据;从所有大于预设误差的时刻误差对应的传感器中获取实体数据;
若所有物理世界曲线极值点对应的时刻误差都大于预设误差,则从所有大于预设误差的时刻误差对应的传感器中获取实体数据。
进一步地,所述映射模型基于深度强化学习PPO算法学习映射数据的特征,从而获得待映射实体数据的时刻,具体为:
S1、基于步骤一获取的实体数据获取t时刻的环境状态集S
S2、将t时刻的环境状态S
S3、基于动作集A
S4、对步骤一获得的所有实体数据进行三次样条插值,获得重构后的物理世界曲线;
S5、获取重构后的物理世界曲线和重构后的虚拟空间曲线误差E
其中,ε是误差阈值。
进一步地,所述S1中的t时刻的环境状态集S
S
其中,[t
所述重构后的虚拟空间曲线通过以下方式获得:在步骤一中获得的实体数据中选择部分数据,对部分实体数据进行三次样条插值,获得重构后的虚拟空间曲线。
进一步地,所述S2中的将t时刻的环境状态S
A
其中,0表示对当前实体数据进行映射,1表示对当前实体数据不进行映射。
进一步地,所述S5中的重构后的物理世界曲线和重构后的虚拟空间曲线误差E
T=t
其中,P′
进一步地,所述S5中的奖励值集,如下式:
ω
其中,N
进一步地,所述单传感器映射模型优化目标,如下式:
min E
s.t.t∈[t
N
其中,N
进一步地,所述多传感器映射模型优化目标,如下式:
s.t.t∈[t
N
C
ω
其中,ω
进一步地,所述映射模型基于深度强化学习PPO算法学习映射数据的特征,目标函数如下式:
其中,
本发明的有益效果为:
本发明基于能源互联网中的三层数字孪生架构,设计了一种基于深度强化学习(DRL)技术的IoE系统的自适应数据映射机制。本发明能够根据环境状态和用户需求动态调整映射数据选择,通过动态调整映射数据的选择,能够获取重要数据点,可以有效减少用于映射的数据量和资源消耗。本发明设计了基于单传感器场景和多传感器场景的映射策略,然后将数字孪生映射机制问题表述为优化问题并转化为马尔可夫决策过程,利用基于ppo的映射方法,通过与环境的交互,减少了映射数据数量和映射误差,提升了数据映射精度。同时本发明实施例的实验结果验证了本发明能够在减少映射数据和低资源消耗的情况下进行动态映射数据选择。
附图说明
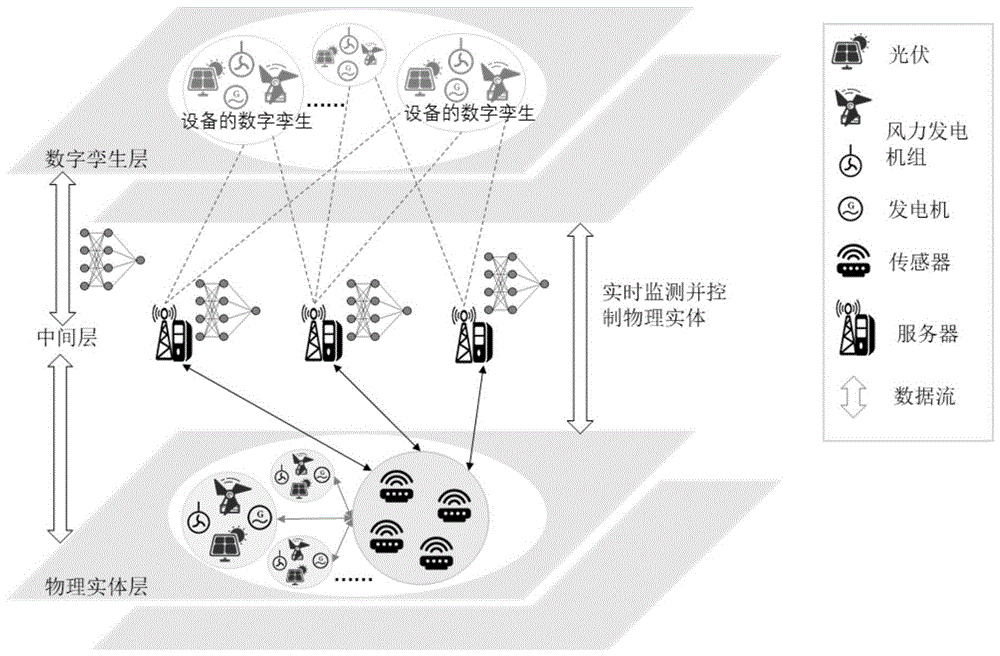
图1为IoE中的数字孪生架构;
图2为插值方法示例图;
图3为基于PPO的数字孪生映射机制;
图4为单传感器场景下不同学习率下PPO算法的收敛性能;
图5为多传感器场景下不同学习率下PPO算法的收敛性能;
图6(a)为成本为50%时DT模型对被观测物理世界的重构结果;
图6(b)为成本为70%时DT模型对被观测物理世界的重构结果;
图6(c)为成本为90%时DT模型对被观测物理世界的重构结果;
图7(a)为不同物理世界重建的方法的最大误差性能;
图7(b)为不同物理世界重建的方法的误差方差性能。
具体实施方式
IoE中的数字孪生架构,如图1所示,该架构有三层:物理实体层、中间层和虚拟空间中的数字孪生层。物理实体层由IoE中的客户端设备组成,如光伏、发电机、风力发电机组等。客户端设备用U={u
DT
其中,D
物理实体层中设备的变化导致数字孪生层的相应变化,数字孪生层可以反映物理实体的实时性能,并实时监视与控制物理实体。数字孪生初始模型的建立基于历史实体的数据离线执行,在线执行数字孪生的迭代更新。根据J.Pang,J.Li,Z.Xie,Y.Huang,andZ.Cai,“Collaborative city digitaltwin for covid-19pandemic:A federatedlearning solution,”2020.,本发明使用DT进化过程中的自-自进化类型,它不会产生新的模型,但会更新当前的模型。根据历史数据在真实系统和DT中建立动态联系,通过增量学习和机器学习算法训练这些联系,使模型属性逐渐接近仿真需求。此数字孪生架构构造了一个映射机制,将物理实体层中的客户端设备与数字孪生层的数字系统连接起来。在此映射机制中,不需要全部物理世界实体的数据就能够形成比较准确的数字孪生映射模型,这在很大程度上降低了资源的消耗。本发明提出的映射方法在中间层完成,接下来结合具体实施方式说明本发明。
具体实施方式一:本实施方式一种能源互联网中基于深度强化学习的数字孪生映射方法具体过程为:
步骤一、根据环境状态确定从一种类型还是多种类型的传感器中获得实体数据,并获取实体数据:
实体数据包括:电压幅值、相角、发电机负荷、线路上的有功与无功功率;
获取每个传感器获取的实体数据,并绘制曲线作为物理世界曲线图;获取所有物理世界曲线图中极值点对应时刻之间的误差,将极值点对应的时刻误差与预设误差比较;
若所有物理世界曲线极值点对应的时刻误差都小于等于预设误差,则随机获取一个类型的传感器获取的实体数据;
若一部分物理世界曲线极值点对应的时刻误差小于预设误差,一部分物理世界曲线极值点对应的时刻误差大于预设误差,则在小于等于预设误差的时刻误差对应的传感器中,随机从一个类型的传感器获取实体数据;从所有大于预设误差的时刻误差对应的传感器中获取实体数据;
若所有物理世界曲线极值点对应的时刻误差都大于预设误差,则从所有大于预设误差的时刻误差对应的传感器中获取实体数据。
若所有物理世界曲线极值点对应时刻之间的误差都在预设误差内,则从一种类型的传感器中获取实体数据;若存在大于预设误差的时刻误差,则从多种类型传感器中获取实体数据。
只需要一个传感器就可以进行描述的环境状态,如母线电压、电流等;
需要多个传感器共同进行描述的环境状态,如发电环节的风机出力、变电站周围环境需要图像传感器、温湿度传感器、气体传感器等共同反映;
步骤二、将步骤一获得的实体数据输入到映射模型中,获得待映射实体数据:
所述映射模型基于深度强化学习PPO算法学习映射数据的特征,从而获得待映射数据的时刻;
所述映射模型包括:单传感器映射模型、多传感器映射模型;
通过以下方式获得待映射数据:
将在步骤一中获得的实体数据输入到PPO网络中进行深度强化学习选择重要时刻的实体数据,具体为:
本发明采用基于马尔可夫决策过程(MDP)进行建模,MDP是一种对代理与动态环境交互过程进行数学建模的方法。自适应数据映射策略的形成可建模成一个马尔可夫决策过程,并采用深度强化学习的方法进行策略优化。典型的MDP由一个四元组M=(S,A,P,R)定义,其中S是状态的有限集,A是动作的有限集,P表示在执行动作a后从状态s到状态s′状态转移概率,R是执行动作a后的实时奖励函数。学习环境系统的三个关键要素,即状态S、动作A和奖励函数R;
智能体根据当前观测到的环境状态s
式中,
深度强化学习的具体过程如下:
S1、基于步骤一获得的实体数据,获取t时刻的环境的状态集S
S
其中,[t
所述重构后的虚拟空间虚线,通过以下方式获得:在步骤一中获得的实体数据中选择部分数据,对部分实体数据进行三次样条插值,获得重构后的虚拟空间曲线。
S2、PPO网络将t时刻的状态S
A
式中,0表示对当前实体数据进行映射,1表示对当前数据观测值不进行映射。
S3、基于动作集A
在本发明提出的架构中,能源互联网数字孪生的映射机制包括两个阶段:选择重要物理世界实体的数据时刻点进行映射和利用所选时刻点进行整个监测映射时间段内的环境状态曲线重构。它们都在边缘服务器上执行。边缘服务器分析其接收到的全部历史实体的数据,发现这些数据在时间序列上呈现一定的规律性。针对某段时间内边缘服务器收集到的这些变化有规律的实体的数据,提出了一种数据映射策略,自适应地选择重要的实体的数据时刻点进行映射。当两个映射点之间的间隔不够短时,可能会忽略被监视的物理世界产生的突发事件,或当两个映射点之间的间隔太短时,可能会观测到连续而不重要的数据值。这两种情况下数字孪生模型的还原度都会降低。所以控制映射频率,即映射时刻点的选择尤为重要。在中间层中,利用接收到的实体的数据和物理世界重构方法,重构出整个映射时间段内的环境状态曲线,并计算与真实物理世界曲线的误差,若误差在用户可接受范围内,则所选实体的数据形成的映射机制成功实现数字孪生模型的映射。
在本发明中,物理世界曲线的重构方法采用了三次样条插值。当然,也可以选择最近邻插值、线性插值和分段三阶Hermit插值等插值方法。图2给出了通过n=18个数据点的上述四种插值方法的例子。样条插值使用多个低阶多项式来通过所有数据点。样条最简单的例子是线性样条,“把点连接起来”生成直线段,也就是线性插值法。线性样条函数缺乏平滑,三次样条则可以解决线性样条的这个缺点。三次样条在两个数据点之间使用三阶多项式替换线性样条两点之间的线性函数。三次样条插值被广泛用于通过离散数据拟合光滑连续函数。
本发明称P′
S4、对步骤一从传感器中获得的所有实体数据进行三次样条插值,获得重构后的物理世界曲线;
在任意时间t∈[t
S5、获取重构后的物理世界曲线与重构后的虚拟空间曲线的误差E
奖赏是对环境做出特定动作后所获得的收益的数学表示。奖励函数能够反映什么动作决策有利于模型构建。自适应数据映射策略的目标是在保证映射数据量尽可能少的情况下,数字孪生模型映射后物理世界重构的误差E
ω
其中,N
E
采用交叉验证作为能源互联网数字孪生模型映射精度的检验方法。交叉验证作为目前最常用的精度检验方法,通过比较重构后的虚拟空间曲线上的预测值P
式中,P
其中,预测值指的是重构后的虚拟空间曲线上的值,实际观测值指的是重构后的物理世界曲线上的值。
E
具体实施方式二:所述单传感器映射模型目标,通过以下方式获得:
min E
s.t.t∈[t
N
其中,E
图3反映了物理实体层的客户端设备、传感器、中间层的边缘服务器、数字孪生层的环境和神经网络之间的交互框架。从图3可以看出,边缘服务器将选择的实时数据传输到数字孪生环境中,反映物理实体层中环境状态的变化。在接收到[t
在训练步骤中,PPO网络直接与基站交互,学习环境知识。PPO网络将重构的曲线看作环境的状态作为输入。基于PPO的数据映射策略训练过程见表1。
表1
具体实施方式三:所述多传感器映射模型的目标函数,通过以下方式获得:
能源互联网的结构非常复杂,在很多情况下一个传感器并不能近似地描绘出其周围的环境,而是需要几个传感器来共同反映。可能是几个相同类型的传感器,也可能是几个不同类型的传感器。当基站将其资源分配给其覆盖范围内的传感器时,由于每个传感器所处的地理位置不同,因此不同传感器所拥有的资源也会产生差异,将其自身采集到的数据进行传输所需要的代价也是不同的。
在其他条件都满足单传感器条件情况下,进行多传感器场景下的数字孪生映射机制研究。现有W个传感器,用S={s
将数字孪生模型映射的准确性与映射点数作为优化目标,力求在满足代价上限时,依然保持数字孪生映射机制的可信度。也就是说,在映射点数尽可能少的情况下,使插值重构出的虚拟空间曲线与物理世界曲线的误差尽可能小。多传感器映射模型目标优化问题,如下:
s.t.t∈[t
N
C
ω
其中,C
本发明采用PPO算法,
传统的强化学习方法,如Q-Learning,使用Q表来存储每个状态和动作对应的奖励值。在能源互联网中的数字孪生框架中,环境状态不断变化,如果采用传统的强化学习方法,Q表中存储的奖励值会非常多,所需的存储空间会迅速增加。DRL算法将深度学习和强化学习方法结合起来,利用深度学习网络代替Q表。这样可以节省Q表的存储空间。DRL代理与环境交互,学习环境的规则。由于所提问题的动作空间涉及离散变量,本发明使用PPO算法作为DRL算法的框架。PPO算法结合了Q-Learning和深度神经网络的优势,是一种免模型的基于Actor-Critic架构的策略梯度算法,在TRPO算法的基础上进行了优化。
PPO是一种model-free,on-policy,actor-critic,policy-gradient方法。它旨在保持TRPO算法的可靠性能,通过考虑策略更新的Kullback-Leibler(KL)散度,保证单调改进,同时只使用一阶优化。策略梯度方法通过带有参数θ的随机策略网络来对策略进行参数化,在训练过程中通过优化梯度来更新策略,最终使目标函数达到最优。通过在环境中运行策略,以Monte Carlo(MC)方式估计梯度,以获得策略损失J(θ)及其梯度的样本:
其中,τ表示形式为(s
实际上,这些梯度是使用自动微分软件在替代损失目标上获得的,其梯度与公式(2)相同,然后通过神经网络反向传播以更新θ:
策略梯度方法的核心挑战在于减少梯度估计值的方差,以便在制定更好的策略方面取得一致的进展。演员-评论家体系结构在这方面产生了重大影响,它根据优势重新制定了奖励信号;所述强化学习网络的奖励信号A
/>
A
其中,V
优势函数(5)衡量一个动作与该状态其他可用动作相比的好坏,例如,好的动作有积极的回报,坏的动作有消极的回报。因此,必须能够估计状态的评价回报,即价值函数V
PPO最大化替代目标函数:
其中,
clip(r
实施例:为了验证本发明有益效果,进行了以下试验:
实验所需的电网运行数据是利用PowerFactory 15.1中的IEEE39母线系统生成。实体数据包括各条母线的电压幅值、相角,发电机、负荷、线路上的有功与无功功率。利用电网运行数据,本实施例分别对单传感器场景下的不同误差评定方法与学习率和多传感器场景下不同学习率、不同误差、不同重建方法和不同代价进行了实验。
所有的仿真实验使用Python 3.7和Pytorch 1.8完成。训练智能体所使用的PPO算法以及神经网络参数如表2所示。
表2 PPO算法及神经网络参数
A单传感器场景下的性能
在单传感器场景下,本实施例使用基于PPO的DRL算法进行数字孪生映射机制的性能评估实验。PPO算法使用Actor-Critic网络。Actor网络和Critic网络的训练需要采用适当的学习率。为了获得适宜的学习率,本实施例进行了评估学习率对映射机制影响的实验。学习率评估实验对{3x10-4,3x10-5,3x10-6}设置中的学习率进行比较。图4描绘了在不同学习率下映射机制结果的平均累积奖励。从图4可以看出,当学习率为3e-4,即3x10-4时,算法的平均累计奖励最大,且收敛速度快于其他两种学习率。
为了明确学习率产生的累计奖励与映射机制准确性的关系。本实施例分别进行了在映射点数上限为100,200,和400时,不同学习率交叉验证误差分析的实验。实验结果如表3,表4和表5所示。从这三张表中可以看出,采用RMSE,MAE,MRE三种误差评定方法的计算结果都表明当学习率为3x10
表3映射点数不超过100时的不同学习率交叉验证误差分析结果
/>
表4映射点数不超过200时的不同学习率交叉验证误差分析结果
表5映射点数不超过400时的不同学习率交叉验证误差分析结果
B、多传感器场景下的性能
为了获得适宜的学习率,本实施例进行了评估学习率对映射机制影响的实验。学习率评估实验对{3x10-3,3x10-4,3x10-5,3x10-6}设置中的学习率进行比较。
图5描绘了在不同学习率下所提出的基于PPO的算法的平均累积奖励。考虑到误差和映射点数,设置奖励。当奖励较大时,少量的映射数据点就足以获得较为准确的数字孪生模型。因此,在较大奖励的场景中,DT映射模型可以有效的减少能耗。因为只有当学习率等于3x10-4、3x10-5或3x10-6时,提出的基于PPO的算法实现了收敛,仅在图5中显示了这些情况的结果。当学习率为3e-5时,算法的平均累积奖励比3e-4大,且收敛速度比3e-6快。因此最终选取的学习率为3x10-5。从图5可以看出,在训练初期阶段,由于动作网络均处于动作探索阶段,因此算法的奖励值较低,且存在较大波动。随着智能体从经验池中提取历史数据进行学习,奖励值逐渐呈上升趋势。在10000轮训练后,奖励函数趋于收敛。这表明训练后的模型适用于数字孪生的映射,并具有良好的收敛性能。
在多传感器场景中,四种代价下的交叉验证结果如表6所示。代价比例由用户规定。理论上,代价与误差成反比关系,代价越大,映射的数据就越多,误差越小。映射的数据量和模型的精度与用户指定的代价比例成正比。从表6可以看出,实验结果与理论一致。在相同的实验环境下,RMSE、MAE和MRE都随着代价的减小逐渐增加。这说明映射策略能够根据用户给出的代价,自适应地选择物理世界实体的数据点进行映射,以最优的决策实现数字孪生模型的映射。
表6不同代价交叉验证误差分析结果
利用IEEE39母线中的母线电压数据,进行了不同代价对重构物理世界曲线治理影响的实验研究,结果如图6(a)-图6(c)所示。图6(a)-图6(c)分别为成本为50%、70%、90%时DT模型的重构结果。这些图表明,当cost减小时,自适应映射策略选出的映射点个数越少。它们还表明,在物理世界环境状态变化剧烈时,自适应映射策略会增加其映射点数量。如图中所示,物理世界中环境状态变化剧烈的点被自映射机制密集地映射出来,环境状态较为稳定的点通过自适应映射机制进行稀疏映射。
图7为相关实验得到的不同物理世界重建方法的性能。图7(a)和图7(b)给出了基于最近邻插值、三次样条插值、线性插值和分段三阶Hermit插值的最大误差和误差的方差。如图7(a)所示,三次样条插值方法在大多数情况下在最大误差方面都优于其他三种方法。图7(b)表明,四种方法的误差的方差随着代价比例的增加而减小。三次样条插值方法在代价比例较大的情况下达到了最佳的性能。因此三次样条插值方法最适合用于物理世界的重构。其他三种方法也能够较为精确地实现模型的映射机制。两个图都表明,映射数据量与预设百分比η成正比,因此,本发明在较大η值下可获得较高的映射精度。
- 基于深度强化学习的能源互联网中虚拟电厂经济调度方法
- 基于深度强化学习的矿井数字孪生系统传感器配置方法