基于类案融合和双层注意力的涉众型经济犯罪量刑方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于自然语言处理及司法办案信息技术领域,具体涉及一种基于类案融合和双层注意力的涉众型经济犯罪量刑方法。
背景技术
涉众型经济犯罪是当前经济犯罪领域中涉及群众最多、社会影响较大、涉案金额巨大、影响社会稳定的严重经济犯罪之一,也具有犯罪嫌疑人数量多、层级多的特点。对涉众型经济犯罪案件的犯罪嫌疑人进行量刑除了要考虑罪责行相适应还有相似案件的判决情况,所以对相似案件和嫌疑人层级的匹配是涉众型经济犯罪案件特有的量刑需求。需要根据同地区或经济水平相当地区的案件,找到犯罪事实比如非法集资的金额匹配案情为相同层级的案件,再根据嫌疑人的犯罪事实、情节、职位、就职期间匹配嫌疑人的层级,找到同一层级的嫌疑人判例进行参考,通过人工难以实现多重层级的相似案例查找和符合规定的量刑计算。为辅助检察办案,设计一种符合涉众型经济犯罪特征的量刑方法,实现对不同程度犯罪作用嫌疑人刑期的科学计算。
发明内容
(一)要解决的技术问题
本发明要解决的技术问题是如何提供一种基于类案融合和双层注意力的涉众型经济犯罪量刑方法,以解决针对经济犯罪领域中涉案人员多、涉案金额巨大、案情复杂等待决案件情况,现有量刑方法提取案件特征维度单一难以保证准确率的问题。
(二)技术方案
为了解决上述技术问题,本发明提出一种基于类案融合和双层注意力的涉众型经济犯罪量刑方法,该方法包括如下步骤:
S1、根据文书类型、案由、量刑情节、判决结果制定规则模版,规则模板包括依据文本类型、案由、常见量刑情节、判决结果制定的文本分类关键字、正则表达式的实体识别规则;
S2、根据文书类型、案由罪名选择S1对应规则模板,利用规则模版对已决案件判决书实现案件信息、被告人量刑情节、判决结果实体识别以构建类案数据库;
S3、根据待决案件文书类型、案由罪名选择S1对应规则模板,完成待决案件信息、被告人量刑情节的案件特征实体识别;
S4、以待决案件文书抽取的案件特征为准,在类案库中查询匹配相似案件特征的已决案件量刑判决结果,作为待决案件的类案特征;
S5、引入bert中文预训练模型,将S3提取的待决案件特征与S4提取的类案特征融合为待决案件文本特征并转化为词向量序列,作为模型编码层的输入;
S6、将S5输入的词向量序列送入编码层,选择Bi-GRU(bidirectional gatedrecurrentunit)神经网络模型作为编码层,结合词语级和句子级注意力上下文向量生成案件基本信息向量、量刑情节向量、类案判决结果向量;
S7、将S6生成的三个文本向量进行拼接并输入Softmax分类器中,分类器计算不同刑期区间的概率分布从而得到待决案件的量刑预测结果。
(三)有益效果
本发明提出一种基于类案融合和双层注意力的涉众型经济犯罪量刑方法,本发明提出一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,本发明是一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,旨在通过构建已决案件类案库,对待决案件采取类案融合技术,并利用双层注意力循环神经网络对融合后的文本特征编码,实现待决案件量刑预测,为涉案嫌疑人多、案情复杂的待决案件提供量刑参考,减少法官、检察官等办案人员大量的人工案件分析工作并辅助量刑决策,提高办案工作效率。
本发明提出一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,将已决案件判决书通过实体识别构建类案库,并抽取待决案件的司法文书文本特征即案件特征和类案特征,通过bert预训练模型强大的词向量表征能力学习文本特征的语义信息,将文本特征转为词向量序列作为模型输入,使用双层注意力机制给文本词语和句子分别赋予权重,引入两层结构的Bi-GRU神经网络作为编码器,对文本特征编码并送入Softmax分类器实现量刑预测,在满足待决案件量刑预测同时,保证结果的准确率。
附图说明
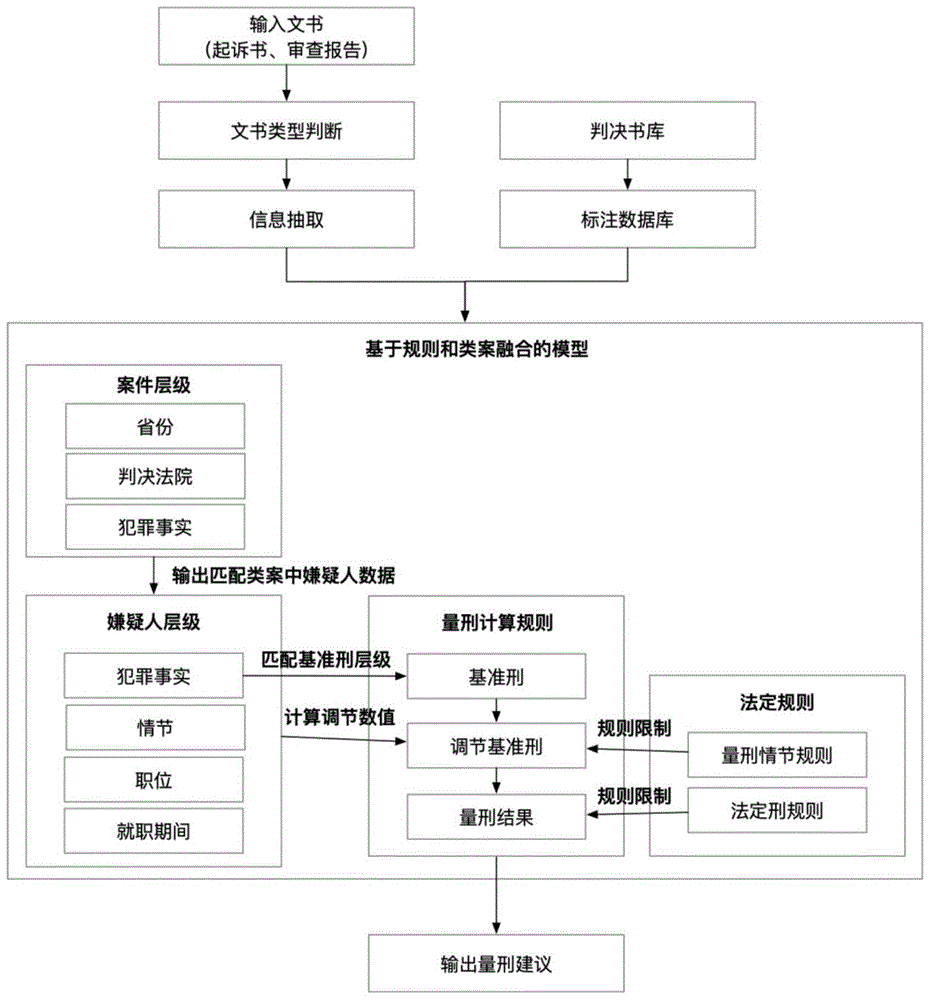
图1为本发明基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法业务逻辑图;
图2为基于类案融合和双层注意力循环神经网络模型结构图。
具体实施方式
为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本发明要解决的技术问题是:提供一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,以解决针对经济犯罪领域中涉案人员多、涉案金额巨大、案情复杂等待决案件情况,现有量刑方法提取案件特征维度单一难以保证准确率的问题。
本发明涉及一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,属于自然语言处理及司法办案信息技术领域。本发明将已决案件判决书通过实体识别构建类案库,并抽取待决案件的司法文书文本特征即案件特征和类案特征,通过bert预训练模型强大的词向量表征能力学习文本特征的语义信息,将文本特征转为词向量序列作为模型输入,使用双层注意力机制给文本词语和句子分别赋予权重,引入两层结构的Bi-GRU神经网络作为编码器,对文本特征编码并送入Softmax分类器实现量刑预测,在满足待决案件量刑预测同时,保证结果的准确率。
为了解决上述技术问题,本发明提出一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,所述方法包括如下步骤:
S1、根据文书类型、案由、量刑情节、判决结果制定规则模版,规则模板包括依据文本类型、案由、常见量刑情节、判决结果制定的文本分类关键字、正则表达式的实体识别规则;
S2、根据文书类型、案由罪名选择S1对应规则模板,利用规则模版对已决案件判决书实现案件信息、被告人量刑情节、判决结果实体识别以构建类案数据库;
S3、根据待决案件文书类型(起诉书、审查报告)、案由罪名选择S1对应规则模板,完成待决案件信息、被告人量刑情节的案件特征实体识别;
S4、以待决案件文书抽取的案件特征为准,在类案库中查询匹配相似案件特征(案件信息、被告人量刑情节)的已决案件量刑判决结果,作为待决案件的类案特征;
S5、引入bert中文预训练模型,将S3提取的待决案件特征与S4提取的类案特征融合为待决案件文本特征并转化为词向量序列,作为模型编码层的输入;
S6、将S5输入的词向量序列送入编码层,选择Bi-GRU(bidirectional gatedrecurrentunit)神经网络模型作为编码层,结合词语级和句子级注意力上下文向量生成案件基本信息向量、量刑情节向量、类案判决结果向量;
S7、将S6生成的三个文本向量进行拼接并输入Softmax分类器中,分类器计算不同刑期区间的概率分布从而得到待决案件的量刑预测结果。
实施例1:
本发明涉及一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,包括以下步骤:一、梳理出司法案件的常见量刑情节,结合文书类型和案由制定实体识别规则模板;二、选择规则模板对已决案件判决书完成实体识别从而构建类案库;三、使用规则模版对待决案件进行实体识别完成案件特征抽取;四、以待决案件特征为准在类案库中查询案情相似的类案判决结果作为本案的类案特征;五、将案件特征与类案特征融合并引入bert中文预训练模型将融合后的文本特征转化为词向量序列,作为编码层模型输入;六、编码层基于Bi-GRU神经网络分别构建词语级编码器和句子级编码器,同时引入双层注意力机制分别对词语级和句子级文本表示向量赋予注意力权重,输出编码后的文本表示向量;七、将文本表示向量送入分类器计算所属刑期概率值,以概率值最大的刑期值作为量刑预测结果,实现待决案件量刑建议,智能化辅助办案人员作出决策。
本发明提供了一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,通过构建类案库引入类案特征,使用双层注意力机制Bi-GRU神经网络模型实现量刑预测,流程包括:
步骤S1:根据最高人民法院、最高人民检察院印发的《关于常见犯罪的量刑指导意见》梳理出司法案件的常见量刑情节(未成年人犯罪、老年人犯罪、未遂犯、从犯、自首情节、坦白情节、认罪认罚、退赃退赔、立功等),结合文书类型、案由制定规则模版,规则模板包括依据文本类型、案由、常见量刑情节制定的文本分类关键字、正则表达式的实体识别规则。其中文本分类的关键字以非法吸收公众存款罪的判决书为例:'(审理查明|检察院指控|公诉机关指控|本院认为)',结合之后的正则表达式,可实现案件信息和被告人信息实现实体识别;
步骤S2:根据已决案件判决书类型和案由,选择S1规则模版,完成已决案件判决书的审理法院、被告人基本信息、量刑情节实体识别,经过数据清洗将非结构化的文本数据转化为结构化文本数据,从而构建类案数据库;
步骤S3:根据S1梳理的常见量刑情节,结合待决案件文书类型(起诉意见书、审查报告)、案由选择S1规则模版,实现待决案件被告人基本信息、判决法院、常见量刑情节的案件特征x
步骤S4:考虑判决法院和常见量刑情节为类案要素,以S3抽取的待决案件特征为参考从类案库中查询与案件特征x
步骤S5:模型输入层。引入基于bert的中文预训练模型,该模型具有强大的词向量表征能力,其将融合后的文本特征x通过Transformer编码器学习语义信息并输出wordembedding词向量序列x',将x'作为模型编码层的输入,提高了法律文书上下文信息的语义理解;
步骤S6:模型编码层。
文本编码器:S5词向量序列x'是包含两层结构的序列集合,一个是组成案件文本的多个句子序列集合,一个是组成每个句子的多个词语序列集合。因此,构建一个具有两层编码器结构的Bi-GRU神经网络模型作为编码器来学习案件文本特征的向量表示,双层编码器结构分别包括词语级编码器、句子级编码器。假设词向量序列x'=[x
h
h
对向量进行拼接h
双层注意力机制:引入全局上下文词语级注意力向量w和句子级注意力向量s,对编码器输出向量h
h
d=[d
步骤S7:模型输出层。将S6案件表示向量d送入Softmax分类器中,Softmax分类器经过计算得到属于各个刑期标签的概率p
模型选择交叉熵作为损失函数,损失函数Loss F的公式如下:
其中r
本发明提出一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,本发明是一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,旨在通过构建已决案件类案库,对待决案件采取类案融合技术,并利用双层注意力循环神经网络对融合后的文本特征编码,实现待决案件量刑预测,为涉案嫌疑人多、案情复杂的待决案件提供量刑参考,减少法官、检察官等办案人员大量的人工案件分析工作并辅助量刑决策,提高办案工作效率。
本发明提出一种基于类案融合和双层注意力循环神经网络的涉众型经济犯罪量刑方法,将已决案件判决书通过实体识别构建类案库,并抽取待决案件的司法文书文本特征即案件特征和类案特征,通过bert预训练模型强大的词向量表征能力学习文本特征的语义信息,将文本特征转为词向量序列作为模型输入,使用双层注意力机制给文本词语和句子分别赋予权重,引入两层结构的Bi-GRU神经网络作为编码器,对文本特征编码并送入Softmax分类器实现量刑预测,在满足待决案件量刑预测同时,保证结果的准确率。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 一种基于多特征融合的司法类案搜索方法
- 基于双层注意力和时空特征并行融合的SDN网络异常流量分类装置及方法