基于视觉基础大模型微调的遥感图像交互式分割方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于遥感图像分割技术领域,具体涉及一种基于视觉基础大模型微调的遥感图像交互式分割方法。
背景技术
随着遥感技术不断发展,遥感卫星不断的发射,收集海量的遥感卫星图像数据成为可能,如高分卫星可以在全球范围内捕获大量高分辨率的遥感图像。在这个遥感大数据时代,大量的遥感图像数据带来了大量的应用机会,地球观测项目逐步增加,同时也提出了许多挑战;在这些挑战中,卫星图像的图像分割已经成为最引人关注的基础问题之一,因为它是一个广泛应用于城市监测、城市管理、交通管理、农业、自动制图和导航等领域的关键技术,具有非常重要的作用。
传统的图像分割算法性能具有上限,没有充分融入专家知识,结果难以直接应用,遥感图像数据集仍然依赖于人工标注。之前的交互式图像分割方法有两个主要的发展方向:提高推理预测速度,快速得到预测分割结果,比如从BRS的反向传导和在线优化[Jang WD,Kim C S.Interactive image segmentation via backpropagating refinementscheme[C]//Proceedings of the IEEE/CVF Conference on Computer Vision andPattern Recognition.2019:5297-5306],到f-BRS只在特定层反向传导[Sofiiuk K,Petrov I,Barinova O,et al.f-brs:Rethinking backpropagating refinement forinteractive segmentation[C]//Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition.2020:8623-8632],再到RITM的纯前馈网络[Sofiiuk K,Petrov I A,Konushin A.Reviving iterative training with maskguidance for interactive segmentation[C]//2022 IEEE International Conferenceon Image Processing(ICIP).IEEE,2022:3141-3145],推理速度得到极大提升;提高方法的分割性能和鲁棒性,得到高质量高准确率的预测分割结果,如Segment Anything Model[Kirillov A,Mintun E,Ravi N,et al.Segment anything[J].arXiv preprint arXiv:2304.02643,2023]使用超大数据集训练模型,得到了令人印象深刻的分割能力和零样本迁移能力,在实现过程中,研究人员发现如Segment Anything Model视觉基础大模型无法精准高效地实现遥感图像分割,在遥感领域的潜力仍然需要挖掘。
因此,如何充分利用视觉基础大模型的分割能力,让视觉基础大模型适应遥感领域,并通过人机交互结合专家知识来进一步提升分割效果和分割效率成为一个重要的问题。
发明内容
鉴于上述,本发明提供了一种基于视觉基础大模型微调的遥感图像交互式分割方法,能够通过联合微调策略充分利用视觉基础大模型性能,随着人机交互逐步修正,分割出用户期望的目标对象的掩膜,从而提高遥感图像分割的准确率和效率。
一种基于视觉基础大模型微调的遥感图像交互式分割方法,包括如下步骤:
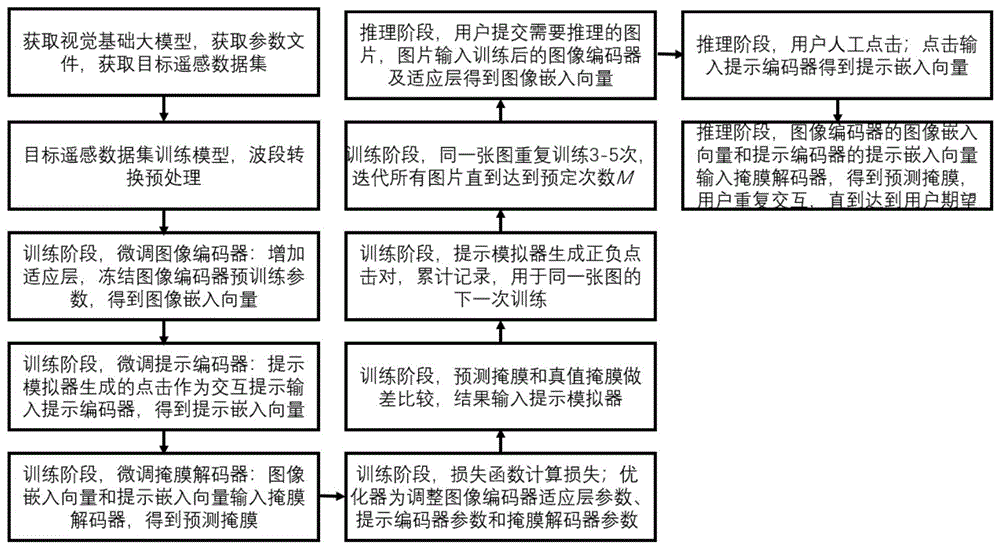
(1)获取视觉基础大模型及其预训练后的模型参数文件,同时获取目标遥感数据集并对其中的遥感图像进行预处理;所述视觉基础大模型包含图像编码器、提示编码器、掩膜解码器三部分;
(2)对图像编码器结构进行微调,即通过增加适应层以提高其特征提取能力;训练时,冻结图像编码器的预训练参数,利用目标遥感数据集训练适应层参数,将预处理后的遥感图像输入图像编码器中,得到图像嵌入向量;
(3)利用提示模拟器生成正点击和负点击作为交互提示输入至提示编码器中,得到提示嵌入向量;
(4)对掩膜解码器结构进行微调,将图像嵌入向量和提示嵌入向量输入掩膜解码器中,得到预测掩膜;
(5)设计适当的损失函数对视觉基础大模型进行训练;
(6)将待分割的遥感图像以及用户点击交互信息输入至训练好的模型中,即可直接输出对应的预测掩膜作为图像分割结果。
进一步地,所述步骤(1)中获取的视觉基础大模型为Segment Anything Model且采用SA-1B数据集对其预训练,其中图像编码器用于对图像进行特征提取得到包含图像特征信息的嵌入向量,提示编码器用于对图像进行提示交互处理得到包含提示特征信息的嵌入向量,掩膜解码器用于对上述两组嵌入向量进行掩膜处理得到预测掩膜,最终实现对于图像的交互式分割。
进一步地,所述目标遥感数据集包含待标注图像、待修正掩膜图像、采集到的遥感图像以及交互点坐标(用户点击遥感图像产生的坐标)。
进一步地,所述步骤(1)中对遥感图像进行预处理的方式为:利用前置波段转换器将RGB-IR四波段的遥感图像通过波段选择以转换为RGB三通道的遥感图像,转换过程中先提取RGB波段得到一张三通道图像,再提取IR波段替换原图像中的R波段得到另一张三通道图像,训练时将两张三通道图像同时送入训练,确保所有输入图像数据在相同的格式下进行处理。
进一步地,所述图像编码器采用由MAE(Masked Auto Encoder)预训练的视觉Transformer,其由12个ViT单元级联构成,每个ViT单元并行增加适应层;每个ViT单元由LayerNorm、多头注意力机制层、LayerNorm、多层感知机依次连接组成;适应层的输出与多层感知机的输出合并,适应层包含两个低秩参数矩阵M
进一步地,所述步骤(3)中在首次训练时初始化提示模拟器,提示模拟器会模拟用户交互得到正点击或负点击,即模拟交互式采样的方式从真值掩膜中采样一个像素或合适半径的实心圆生成一个正点击,其为用于分割出目标对象掩膜的点击;从背景中模拟交互式采样一个像素或合适半径的实心圆生成一个负点击,其为用于去除不属于目标对象的掩膜的点击;在非首次训练时,提示模拟器会在真值掩膜覆盖而预测掩膜未覆盖的真阴区域模拟交互式采样一个像素或合适半径的实心圆作为正点击,在真值掩膜未覆盖而预测掩膜覆盖的假阳区域模拟交互式采样一个像素或合适半径的实心圆作为负点击;提示模拟器会将其生成的所有点击作为交互提示输入至提示编码器中通过位置编码生成提示嵌入向量。
进一步地,所述模拟交互式采样的方式即通过模拟人工点击的聚集性、显著性、边缘性、最大区分性等策略所设计相应的采样方式。
进一步地,所述掩膜解码器由提示自注意力机制层、提示-图像交叉注意力机制层、图像向量上采样层、多层感知机依次连接组成,得到各像素成为掩膜的概率,进而通过阈值控制得到预测掩膜;所述图像向量上采样层由转置卷积层、LayerNorm、GELU激活函数、转置卷积层、GELU激活函数依次连接组成。
进一步地,所述损失函数的表达式如下:
其中:L为总损失函数,L
本发明方法是一个完整的基于视觉基础大模型微调的遥感图像交互式分割流程,核心模型包括带适应层的图像编码器、提示编码器、掩膜解码器,实现了完整的人机交互循环,包括图像波段转换、图像编码器原参数冻结和适应层参数训练、提示编码器接收模拟点击输入和参数训练、掩膜解码器参数训练和反馈、提示模拟器模拟点击生成、提示编码器接收用户点击输入、掩膜解码器预测掩膜输出。
本发明提出了一种基于视觉基础大模型的联合微调策略,在训练时同时微调图像编码器的适应层、提示编码器和掩膜解码器,使模型更加适应目标遥感数据集。本发明提出了交叉熵和聚焦损失的加权组合损失函数用于计算预测掩膜和真值掩膜的损失,根据损失对需要微调的参数进行调整。本发明为了支持RGB-IR四波段和RGB三波段的遥感图像,使用四波段转三波段的前置波段转换器,确保输入图像编码器的图像为三通道图像。为了使得提示编码器可训练,本发明提出了一种自动化迭代反馈的提示模拟策略,根据模拟交互式采样及预测掩膜和真值掩膜的差异生成下一次正负点击对用于模拟分割点击交互。
本发明组建了完整实用的交互式遥感图像分割训练和推理流程,通过用户点击交互,迭代输出或修正预测掩膜,提高了遥感图像分割的准确率和效率,为实用高效的遥感图像标注提供新方法。
附图说明
图1为本发明遥感图像交互式分割方法的步骤流程示意图。
图2为本发明视觉基础大模型的结构示意图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
如图1所示,本发明基于视觉基础大模型微调的遥感图像交互式分割方法,包括如下步骤:
(1)获取基于“图像编码器-提示编码器-掩膜解码器”结构的视觉基础大模型,得到通过SA-1B数据集对其预训练后的模型参数文件,以便进行微调。获取目标遥感数据集,其包含待标注图像、待修正掩膜图像、交互点坐标以及由遥感设备采集的遥感图像,确保数据质量和多样性。
本实施方式使用的预训练数据集为SA-1B数据集,视觉基础大模型采用SegmentAnything Model,使用带建筑物屋顶标签的AIRS遥感图像数据集作为3通道目标遥感数据集,并将其大小裁剪为512*512像素,保留RGB 3通道,图像和对应建筑物标签数量各为40000张;使用带建筑物标签的ISPRS Potsdam遥感图像数据集作为4通道目标遥感数据集,并将其大小裁剪为512*512像素,保留RGB-IR 4通道,图像和对应建筑物标签数量各为4000张。
(2)训练阶段,为基础大模型构建微调架构,如图2所示,确保其包括图像编码器适应层和波段转换器、提示编码器和模拟器以及掩膜解码器部分。
初始阶段,使用目标遥感数据集对整个模型进行训练,以便自适应特定遥感任务,利用前置波段转换器对遥感图像进行预处理,即对RGB-IR四波段图像执行波段选择以转换为RGB三通道图像,确保所有输入数据在相同的格式下进行处理。波段转换器支持RGB三波段和RGB-IR四波段的遥感图像,图像编码器由于冻结的预训练参数仅支持RGB三通道图像,且顺序必须为“RGB”或“BGR”,遥感图像在输入图像编码前通过一个波段转换器,统一将RGB-IR四波段的遥感图像转换为三通道的遥感图像;转换算法为提取RGB波段得到一张三通道图片,提取IR波段替换原图像的R波段,得到另一张三通道图片;训练时将两张图片同时送入训练,推理时由用户在四个波段中选择三个波段得到三通道图片进行推理,调整波段数后的图像会反馈给用户。
本实施方式中图像编码器网络结构可采用MAE预训练的ViT-B,ViT batch大小为16,需要输入三通道图片,学习率为1e-4,按0.01的权重衰减,优化算法为AdamW,训练100个epoch可以得到期望微调模型。训练时将RGB-IR图片转为RGB三通道图片和IR-GB三通道图片,两张图片同时送入训练;推理时默认选择RGB三通道进行推理,用户也可以自行选择三通道。
(3)训练阶段,对图像编码器进行微调,逐步增加适应层以提高其特征提取能力,这些适应层的参数根据低秩参数矩阵进行调整,实现维度变换。
本实施方式中图像编码器为由MAE预训练的视觉Transformer(ViT),由12个ViT单元构成,每个ViT单元并行增加适应层;每一个ViT单元的结构为LayerNorm、多头注意力、LayerNorm、多层感知机;适应层的输入为第一个LayerNorm的输入,适应层的输出与多层感知机的输出合并;适应层包含两个低秩参数矩阵M
(4)训练阶段,通过提示模拟器生成正点击和负点击,用于提示编码器的训练。
本实施方式中提示模拟器会模拟用户交互得到正点击或负点击,正点击用于分割出目标对象掩膜的点击,负点击用于去除不属于目标对象的掩膜的点击;提示模拟器首次训练时提示模拟器初始化,从真值掩膜中随机采样一个像素或一个合适半径的实心圆生成一个正点击,从背景中随机采样一个像素或一个合适半径的实心圆生成一个负点击,将所有提示模拟器生成的点击作为交互提示输入提示编码器生成提示嵌入向量;提示模拟器非首次训练时,在真值掩膜覆盖而预测掩膜未覆盖的真阴区域随机采样一个像素或一个合适半径的实心圆作为正点击,在真值掩膜未覆盖而预测掩膜覆盖的假阳区域随机采样一个像素或一个合适半径实心圆作为负点击;提示编码器通过位置编码,得到提示嵌入向量,提示向量维度是256。
(5)训练阶段,微调掩膜解码器,图像嵌入向量和提示嵌入向量输入掩膜解码器,得到预测掩膜。
本实施方式中的掩膜解码器包括提示自注意力、提示-图像交叉注意力、图像向量上采样、多层感知机,得到各像素成为掩膜的概率,通过阈值控制得到预测掩膜;图像向量上采样方法的结构为卷积转置、LayerNorm、GELU激活函数、卷积转置、GELU激活函数;多层感知机的结构为线性层、ReLU激活函数、线性层;掩膜解码器的向量维度等于提示嵌入向量的维度,为256;双路Transformer的深度为3,多层感知机的维度是1024,注意力头数量为8。
(6)训练阶段,采用适当的损失函数(如交叉熵损失和聚焦损失)计算预测掩膜与真值掩膜之间的损失,用以优化模型,调整需要微调的参数;进而使用优化器(如AdamW)对图像编码器的适应层参数、提示编码器参数和掩膜解码器参数进行微调,以最小化损失函数,调整图像编码器适应层参数、提示编码器参数和掩膜解码器参数。
本实施方式通过以下损失函数公式计算损失L:
其中:S代表预测掩膜,G代表真值掩膜,s
(7)训练过程中,步骤(5)生成的预测掩膜和图像对应的真值掩膜进行做差比较,得到比较结果,输入提示模拟器。
(8)训练阶段,提示模拟器得到反馈,在真阴区域生成一个正点击,在假阳区域生成一个负点击,累计记录图像所有点击得到模拟点击图,用于同一张图的下一次训练。
本实施方式在非首次训练时,提示模拟器在真值掩膜覆盖而预测掩膜未覆盖的真阴区域随机采样一个像素作为正点击,在真值掩膜未覆盖而预测掩膜覆盖的假阳区域随机采样一个像素作为负点击;提示编码器通过对所有点击进行位置编码,得到提示嵌入向量。
(9)训练阶段,同一张图重复步骤(3)到步骤(8)训练3~5次,训练数据集中所有图像训练均完成训练视为迭代一次,重复训练直到达到预定次数M。
本实施方式同一张图重复训练3次,预定次数M=100,即训练100个epoch可以获得期望微调模型。
(10)推理阶段,用户提交需要推理的图片,图片输入训练后的图像编码器及适应层得到图像嵌入向量。
本实施方式中用于推理的图像和对应建筑物标签数量各为200张,如果用户提交的图片超过了Transformer要求的尺寸,将会优先调整最长边长度。
(11)推理阶段,用户人工左键点击图像上需要分割的目标对象,作为正点击,或右键点击图像上不属于这个目标对象的一个像素作为负点击;点击输入提示编码器得到提示嵌入向量。
(12)推理阶段,图像编码器的图像嵌入向量和提示编码器的提示嵌入向量输入掩膜解码器,得到预测掩膜,反馈至用户,用户根据结果进行下一轮交互,即重复步骤(10)到步骤(12),直到达到用户期望。
本实施方式如果用户的输入图片经过调整以满足模型需求,在预测分割结果输出后将会通过双线性插值法进行还原。初步实验表明,对于1张512*512分辨率的遥感图像,平均6次点击以上,可以达到85%mIoU的参考性能,平均10次点击以上,可以达到90%mIoU的参考性能。
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明,熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
- 基于视觉注意与残差网络的SAR遥感图像水域分割方法
- 基于形状先验信息和视觉对比度的遥感图像目标分割方法