基于深度确定性策略梯度算法的雨水管网优化方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及信息领域,尤其涉及一种基于深度确定性策略梯度算法(DeterministicPolicy Gradient,DDPG)的雨水管网优化方法。
背景技术
城市雨水管网系统是城市防洪排涝的关键设施,其设计优化涉及到多目标和多约束的问题,如防洪能力、造价、运行成本等。因此,有效的优化模型对于提升城市的防洪能力,降低投资成本和运行维护成本至关重要,同时也是保障城市居民的生活质量的重要手段。
传统的雨水管网设计优化方法主要依赖于经验和工程规范,如权重法和约束法。这些方法在处理单一目标优化问题上有一定的效果,但在处理多目标优化和多约束问题时,往往显得力不从心。同时,这些方法对于管网系统的约束条件处理也有限,往往需要手动调整,优化过程缺乏动态性和自适应性。
为了解决这些问题,有研究者引入了演化算法,如遗传算法、粒子群优化算法等,以求在处理多目标优化问题和约束条件上有所突破。然而,这些方法在处理连续状态和动作空间问题上存在困难,对于大规模问题优化效果有限,可能需要大量的计算时间和资源。
具体来说,雨水管网的优化设计问题是一个典型的多目标、多约束的连续状态和动作空间问题。状态空间主要由管网的各节点的水深、各管道的流速以及当前的降雨量等因素组成,而动作空间则主要涉及对某管道的直径、埋深进行调整,甚至包括增加新的排水节点等措施。传统的演化算法主要适用于离散的状态和动作空间,对于连续的状态和动作空间,这些算法往往需要进行复杂的编码和解码过程,同时在搜索过程中也可能出现效率低下的问题。
基于此,本发明提出了一种基于深度确定性策略梯度算法(DDPG)的雨水管网优化模型。DDPG是一种先进的深度强化学习算法,能够处理连续状态和动作空间,对于解决雨水管网优化问题具有很高的适用性。DDPG能够直接在连续的状态和动作空间中学习到最优的策略,无需进行复杂的编码和解码过程,大大提高了优化效率和精度。
这一新的模型为城市雨水管网的优化设计提供了有效的工具。它不仅可以有效处理多目标优化问题和多约束条件,而且能更好地适应和处理连续状态和动作空间的问题,从而在处理大规模的城市雨水管网优化问题上显示出优势。在城市化进程不断加速的今天,这一模型的提出具有重要的理论意义和实际价值。
发明内容
本发明提供了一种基于深度确定性策略梯度算法的雨水管网优化方法,结合了深度学习和强化学习的方法,能够有效处理多目标优化问题和多约束条件,同时在连续状态和动作空间上表现出良好的优化效果,为城市防洪排涝设施设计提供了一个高效、自适应的优化工具,对于提升城市防洪能力,降低投资成本和运行维护成本,保障城市居民生活质量具有重要价值。
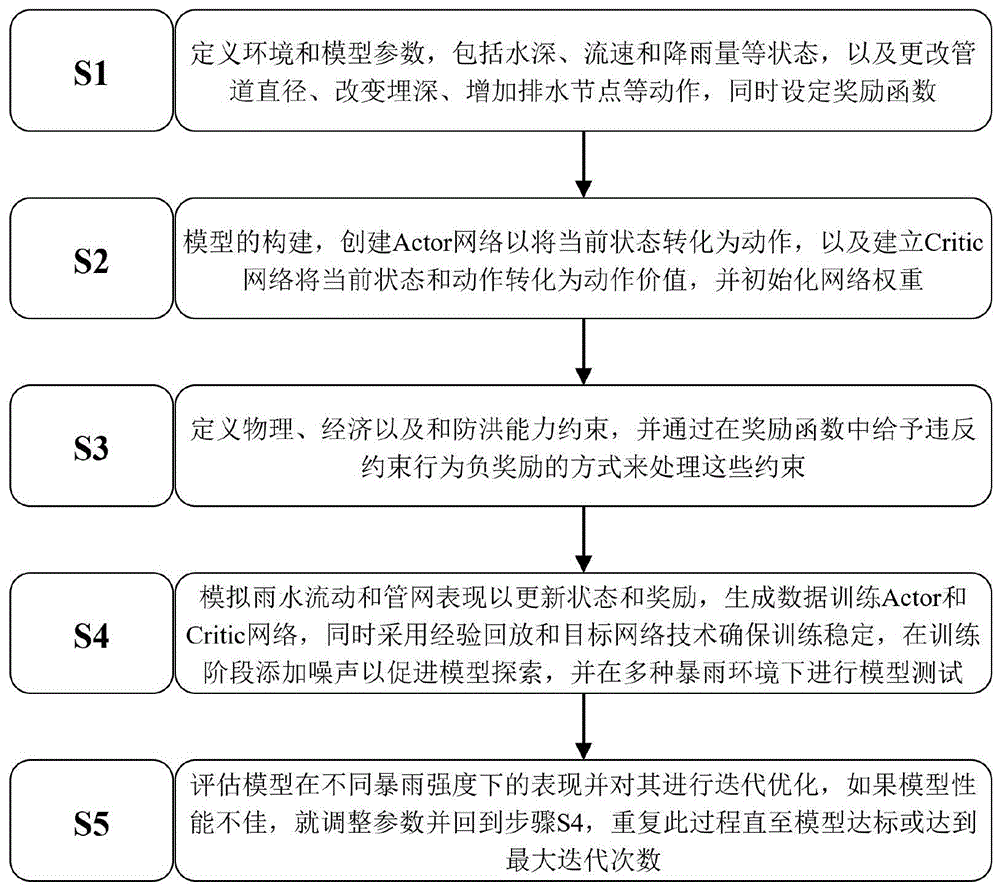
本发明提供了一种基于深度确定性策略梯度算法的雨水管网优化方法,具体包括以下步骤:该方法包括以下步骤:
步骤S1:定义模型的环境和参数,定义雨水管网各节点的水深、各管道的流速和当前的降雨量作为状态,改变管道直径、改变管道埋深或增加新的排水节点作为动作,最后通过考虑防洪能力、成本和设计约束设定奖励函数;
步骤S2:构建Actor网络和Critic网络,Actor网络接受当前状态作为输入并输出动作,Critic网络接受当前状态和动作作为输入并输出动作价值,同时进行网络权重的初始化;
步骤S3:定义物理和经济约束,包括管道直径和埋深的限制、造价限制、以及可应对一定强度暴雨的能力,并将这些约束纳入奖励函数中,如有违反则会给出负奖励;
步骤S4:利用城市水文模型SWMM模型,模拟雨水流动和管网表现,生成训练数据,通过训练更新Actor和Critic网络,利用经验回放和目标网络技术稳定训练;同时进行各种可能环境下的测试,以确保模型的泛化能力;
步骤S5:通过在不同的暴雨强度下测试模型,评估模型的性能和泛化能力,若模型表现不佳,调整模型参数并返回步骤S4进行迭代训练,直到模型达到预设的性能标准或达到最大迭代次数。
进一步地,所述步骤S1包括以下步骤:
步骤S11:收集并整理管网信息,所述管网信息包括管网布局、管道尺寸、排水节点位置,同时准备和处理降雨数据;
步骤S12:基于步骤S11收集的数据定义状态空间,所述状态空间包括节点水深、管道流速以及当前降雨强度;
步骤S13:定义模型的动作空间,包括改变管道直径、改变埋深或增加新的排水节点,且这些动作都在实际可操作范围内;
步骤S14:构建奖励函数,依据防洪能力、成本及基本设计约束因素;
步骤S15:使用城市水文模型SWMM建立模拟环境,该模拟环境可依据模型动作输出模拟新状态并返回相应奖励。
进一步地,所述步骤S2包括以下步骤:
步骤S21:构建输入为当前状态的Actor网络,用于决定针对当前状态应执行的最佳动作,具体地,状态空间s由管网各节点的水深h、各管道的流速v、当前的降雨量r组成,记为s={h,v,r},动作空间a由管道的直径d、管道的埋深l、新增的排水节点n,记为a={d,l,n},Actor网络看作是一个从状态空间到动作空间的映射函数,这个映射函数用深度神经网络来实现,Actor网络有N层,其中第i层的权重和偏置分别为W
a=f
其中,f
步骤S22:构建Critic网络,该网络接受当前状态及Actor网络输出的动作作为输入,输出相应动作的价值,即预期的系统性能评估,具体地,Critic网络的目标是评估在当前状态下采取某个动作的价值,即评估所选定的雨水管网配置的效能,Critic网络看作是一个从状态-动作空间到动作价值的映射函数,假设Actor网络有M层,其中第j层的权重和偏置分别为W′
Q=g
其中,g
步骤S23:在训练开始之前,采用正态分布来初始化Actor网络和Critic网络的权重,为后续的网络优化设定初始状态;
步骤S24:定义网络的优化器和损失函数,本模型使用Adam优化器,并设定损失函数为Critic网络的预测动作价值与实际奖励之间的均方误差,以便根据损失函数反馈优化网络。
进一步地,所述步骤S3包括以下步骤:
步骤S31:定义物理约束,包括管道直径和埋深的限制,以及管道流动的连通性;
步骤S32:根据实际应用中的经济考虑,定义经济约束;
步骤S33:定义防洪能力约束,确保模型优化的雨水管网能够应对预设强度的暴雨;
步骤S34:模型通过在奖励函数中包含约束,并对违反约束的动作给予负奖励的方式,实现对上述各种约束的处理,具体来说,奖励函数R定义为:
R=r1-λ1*C-λ2*V-λ3*D(3)
其中,r1是基础奖励,通常设为正值;C是实际造价超出预算的部分,如果没有超出预算,则C=0;V是洪水溢出量超过容忍值的部分,如果没有超出容忍值,则V=0;D是违反物理约束的程度;λ1,λ2,λ3是对应的惩罚系数;
步骤S35:在训练过程中,将这些约束融入到模型中,每一步都检查新的状态是否满足约束,以确保优化的雨水管网满足物理、经济和防洪能力约束。
进一步地,所述步骤S4包括以下步骤:
步骤S41:构建城市内涝模型,使用城市水文模型SWMM,该模型模拟雨水在管网中的流动情况,并依据所给定的动作生成相应的新状态和奖励;
步骤S42:模型训练,使用步骤S41生成的新状态和奖励对Actor网络和Critic网络进行训练,目标是在满足各项约束的前提下,最大化管网的防洪能力和最小化成本;
步骤S43:采用经验回放和目标网络技术,经验回放技术是通过保存并在训练中随机抽取过去的经验,包括状态,动作,奖励来打破数据间的相关性,增加训练的稳定性;目标网络技术通过创建一个参数更新较慢的网络提供稳定的目标Q值,解决Q-learning训练中的不稳定问题,具体地,在经验回放中,雨水管网优化模型保存了过去的一系列经验e=(s,a,r,s′),其中s是当前状态,a是执行的动作,r是得到的奖励,s′是执行动作a后的新状态,这些经验储存在雨水管网优化模型的经验回放缓冲区D中,每次训练时从中随机抽取一个小批量的经验来更新网络参数;在目标网络技术中,模型有两个相同结构的网络:Actor网络A和其对应的目标网络A′,以及Critic网络C和其对应的目标网络C′;网络A和C的参数是通过梯度下降法更新的,而网络A′和C′的参数则是通过软更新来进行的,表达为:
θ′
θ′
其中,θ
步骤S44:进行模型测试,以确保模型的泛化能力,具体做法是在不同暴雨条件下测试模型,同时,在测试阶段移除在步骤S42中添加的噪声,以便准确评估模型的性能和根据模型进行预测。
进一步地,步骤S42中,为了处理连续状态和动作空间,在训练过程中,添加噪声以鼓励模型进行探索;在预测阶段,去除噪声,使模型输出最优动作;具体包括以下步骤:
步骤S421:设置Ornstein-Uhlenbeck过程的参数,该过程用于在连续动作空间中生成随机噪声,Ornstein-Uhlenbeck过程是一个随机过程,其在离散时间下的更新公式为:
X
其中,X
步骤S422:在模型训练阶段,将步骤S421生成的随机噪声添加到Actor网络的输出动作上,以鼓励模型探索更多可能的解决方案,具体地,动作空间为a={d,l,n},根据Ornstein-Uhlenbeck过程,为每一个动作参数生成噪声,即为d、l和n分别生成噪声X
a′=a+X
这样,Ornstein-Uhlenbeck过程产生的噪声直接影响了雨水管网的每个决策变量,包括管道的直径d、埋深l和新增排水节点n,从而为模型提供了一种更好地探索解空间的方法;此外,添加到每个决策变量上的噪声需要根据这些决策变量的特性和量纲来调整σ,以使噪声在所有决策变量中的影响保持平衡;
步骤S423:根据模型训练的效果调整随机噪声,如果模型探索不足或预测过保守,增大噪声标准差;反之,如果模型行为过于随机或预测过于激进,减小噪声标准差,确保模型在各种降雨情况下都能表现良好。
进一步地,所述步骤S5包括以下步骤:
步骤S51:模型在模拟各种不同强度的暴雨情况下进行预测,以评估雨水管网的性能;
步骤S52:根据预测结果,对模型在防洪能力、经济成本以及满足基本设计约束等方面的性能进行评估;
步骤S53:如果模型性能未达到预设标准,或泛化能力不足,则需调整模型超参数或网络结构,然后重新开始训练;
步骤S54:如果模型性能达到预设标准或达到最大迭代次数,结束优化并记录当前模型参数,以便后续应用。
由上述技术方案可知,本发明提供的基于深度确定性策略梯度算法的雨水管网优化模型的技术效果在于:
1.模型实现了对雨水管网的自动优化设计,有效地提高了管网设计的效率与准确性。基于DDPG的算法可以从历史数据中学习并预测出最优的雨水管网设计方案,比传统的基于人工经验的设计方法更快、更精确。同时,通过不断的学习和迭代,模型的表现将随着时间的推移而不断改善。
2.模型考虑了实际工程中的多种约束条件,使得优化结果更具实用性。这包括物理约束(如管道直径和埋深的限制、水流的连通性)、经济约束(如造价预算)、以及防洪能力约束等,使得模型的优化结果能够在满足这些基本条件的前提下,达到最优。
3.模型采用了连续动作空间的策略优化方法,使得优化结果更加精细,可以应对更复杂的实际问题。通过引入Ornstein-Uhlenbeck噪声过程,模型能够在训练过程中更好地探索解空间,从而找到更优的解。通过对模型的性能进行不断评估与优化,该模型可以在各种不同的环境(如不同强度的暴雨条件)下都表现出良好的性能。通过反复迭代的训练,模型的泛化能力可以得到显著提高。
附图说明
图1示出了本发明实施例所提供的基于深度确定性策略梯度算法的雨水管网优化模型的流程图;
图2示出了本发明实施例所提供的基于深度确定性策略梯度算法的雨水管网优化模型的具体应用框图;
图3示出了本发明定义各类约束并处理约束的算法流程图;
图4示出了本发明实施例所提供的雨水管网优化模型训练过程示意图;
图5示出了本发明实施例所提供的不同暴雨重现周期下雨水管网优化结果。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述和说明:
根据图1所示,一种基于深度确定性策略梯度算法的雨水管网优化模型,具体包括以下步骤:
步骤S1:定义环境和模型参数。包括状态、动作和奖励。状态包括管网各节点的水深,各管道的流速,以及当前的降雨量等。动作包括更改某管道的直径、改变某管道的埋深、增加新的排水节点等。奖励函数需要综合考虑防洪能力、成本和满足基本设计约束等多重因素。
步骤S2:建立模型。构建Actor网络,输入为当前状态,输出为动作。构建Critic网络,输入为当前状态和动作,输出为动作价值。初始化网络权重。
步骤S3:定义并处理约束。对动作和状态定义物理和经济约束,包括管道直径和埋深的限制、造价限制、可应对一定强度暴雨的能力等。约束可以通过包含在奖励函数中进行处理,如违反约束则给予负奖励。
步骤S4:设计训练过程。利用SWMM模型(Storm Water Management Model)构建城市内涝模型,模拟雨水流动和管网表现,不断更新状态和奖励,得到多组数据,训练Actor和Critic网络,并采用经验回放(Experience Replay)和目标网络(Target Network)技术来稳定训练过程,同时,将模型在各种可能的环境(如不同暴雨条件下)下进行测试,以确保模型的泛化能力。
步骤S5:处理连续状态和动作空间。在训练过程中,添加噪声以鼓励模型进行探索。在预测阶段,去除噪声,输出最优动作。
步骤S6:评估和不断迭代优化模型。在各种不同的暴雨强度下测试模型,评估模型的性能和泛化能力。如果模型表现不佳,调整模型参数并回到步骤S4。持续进行步骤S4到步骤S6,直到模型达到预设的性能标准或达到最大迭代次数。
本实施例中,对南京市某小区常被淹没的区域进行雨水管网优化,该区域共包括39根雨水管线以及40个雨水管点,区域内的其他数据包括DEM以及建筑物、道路等基础地理数据。利用南京市的暴雨强度公式,实施例中设计了四场暴雨,降雨时长均为两小时,暴雨重现期分别为一年一遇、五年一遇、十年一遇以及二十年一遇。实施步骤如下如图2所示。
本实施例中雨水管网优化问题涉及到众多复杂因素,包括环境、气候、地理和经济等。因此,本发明设计的目标是通过智能方式优化管网设计,以提高防洪能力,降低成本,同时满足基本设计约束。为实现这个目标,需要构建一个精确模拟现实世界的环境,并定义一个涵盖这些目标的奖励函数。为此,本发明收集并整理了雨水管网优化所需的城市流域的雨水管网地理信息和降雨数据,定义了反映现实世界情况的状态空间和动作空间,构建了既能反映防洪能力、成本等多重目标,又能反映设计约束的奖励函数。最后,使用城市水文模型等工具搭建了模拟环境,该环境能根据模型的动作输出,模拟出相应的新状态,并返回相应的奖励。这样,通过对现实世界的精确模拟和合理的奖励设计,模型可以在学习过程中不断地对自身进行优化,从而达到优化雨水管网、提高防洪能力、降低成本的目标。因此,所述步骤S1包括以下步骤:
步骤S11:收集和整理数据。采集需进行雨水管网优化城市流域的雨水管网地理信息,包括管网的布局、管道的长度、直径、埋深、排水节点的位置等信息。同时,还需要获取历史和预测的降雨数据,包括各种不同强度和频率的暴雨数据。
步骤S12:定义状态空间。基于收集到的数据,定义状态空间,这可能包括管网各节点的水深、各管道的流速,以及当前的降雨强度(包括各种不同强度和频率的暴雨)等。
步骤S13:定义动作空间。确定模型能执行的动作,这可能包括更改某管道的直径、改变某管道的埋深、增加新的排水节点等。这些动作应在现实可操作的范围内。
步骤S14:构建奖励函数。奖励函数应综合考虑防洪能力、成本和满足基本设计约束等多重因素。例如,当洪水没有溢出时给予正奖励,当管网的总造价超过预算时给予负奖励,当不满足设计约束(如上游管道直径大于等于下游管道直径)时,也给予负奖励。另外,针对不同强度和频率的暴雨,应该设置相应的奖励函数,保证优化后的管网能够应对不同强度的降雨条件。
步骤S15:搭建模拟环境。使用城市水文模型SWMM模型,根据定义的状态和动作,以及相应的奖励函数,搭建雨水管网的模拟环境。该环境应能根据模型的动作输出,模拟出相应的新状态,并返回相应的奖励。
本实施例中基于深度确定性策略梯度算法的雨水管网优化模型的S2步骤设计主要是为了建立两个深度神经网络,即Actor网络和Critic网络,来形成策略和评估策略的价值。这两个网络相互协作,以实现雨水管网的有效优化。首先,Actor网络作为一个策略生成器,其基本原理是学习并确定在特定环境状态下应采取的最优动作。在雨水管网优化问题中,这些环境状态包括当前的降雨条件、管网状态、城市地形等信息,而动作则包括调整管道直径、改变管网连接方式等措施。Actor网络通过反复学习和试验,逐渐理解环境状态和动作之间的关系,从而学会在特定情况下制定最佳的管网调整策略。接着,Critic网络作为一个策略评估器,其基本原理是为每个状态-动作对赋予一个价值,以此评估Actor网络的策略优劣。在雨水管网优化问题中,Critic网络需要综合考虑各种影响因素,如防洪能力、建设和维护成本等,对策略进行全面评价。Critic网络的设计在多目标优化问题中显得尤为重要,因为它需要能够准确评估不同目标间的权衡。最后,Actor网络和Critic网络的权重初始化是为了在开始训练时给予网络一个初始的学习状态。这些权重在训练过程中将不断被更新,以逐步逼近最优解。因此,所述步骤S2包括以下步骤:
步骤S21:构建Actor网络。这是一个深度神经网络,输入为当前的状态,即包括管网各节点的水深、各管道的流速、当前的降雨量以及可能存在的多种暴雨等信息。这些信息组合起来,形成了雨水管网的状态描述。Actor网络需要从这些状态中学习并决定最合适的动作,包括更改某管道的直径、改变某管道的埋深、增加新的排水节点等。
具体地,状态空间由管网各节点的水深h、各管道的流速v、当前的降雨量r等因素组成,记为s={h,v,r},动作空间由管道的直径d、管道的埋深l、新增的排水节点n等决策组成,记为a={d,l,n}。Actor网络可以看作是一个从状态空间到动作空间的映射函数。这个映射函数可以用深度神经网络来实现,神经网络定义为N层,其中第i层的权重和偏置分别为W
a=f
其中,f
步骤S22:构建Critic网络。Critic网络也是一个深度神经网络,其输入为当前的状态和Actor网络输出的动作,输出为对应的动作价值。动作价值表示的是在给定状态下,采取某个动作后,雨水管网系统的预期性能。这个性能包括防洪能力、成本和满足基本设计约束等多重因素的综合评价。
具体地,Critic网络的目标是评估在当前状态下采取某个动作的价值,即评估所选定的雨水管网配置的效能。根据状态空间为s={h,v,r}(包括各节点的水深h、各管道的流速v、当前的降雨量r等因素)以及动作空间为a={d,l,n}(包括更改某管道的直径d、改变某管道的埋深l、增加新的排水节点n等决策)。那么,Critic网络可以看作是一个从状态-动作空间到动作价值的映射函数,假设神经网络有M层,其中第j层的权重和偏置分别为W′
Q=g
其中,g
步骤S23:初始化网络权重。在训练开始前,需要初始化Actor和Critic网络的权重。它决定了网络在训练开始时的状态。权重的初始值可以根据问题的特性来选择,本发明使用正态分布。
步骤S24:定义网络的优化器和损失函数。在这个模型中,使用Adam优化器,损失函数通常定义为Critic网络的预测动作价值与实际奖励的均方误差。这样,就可以根据损失函数的反馈来不断优化网络,使得它能够更好地适应和解决雨水管网优化问题。
本实施例中精心定义和处理约束条件,来确保优化过程符合实际情况和需求。这些约束条件主要包括物理约束、经济约束和防洪能力约束。物理约束,包括管道直径和埋深的限制以及管网水流的连通性,是根据雨水管网的实际物理特性和工程要求设定的。在实际的雨水管网设计中,必须满足如上游管段埋深高程需要大于下游管段高程,上游管段直径需要大于等于下游管段直径等基本原则。这些约束条件在深度学习模型中的体现是通过设定一定的惩罚项来实现的,当产生的动作违反这些物理约束时,模型会得到负奖励,从而在学习过程中逐渐避开这类动作。经济约束主要是指雨水管网的建设和维护成本,因为在实际的工程应用中,经济因素往往是关键的制约因素。这个约束同样是通过设定惩罚项实现的,如果优化结果导致的建设和维护成本超出预定预算,那么模型将会得到负奖励。防洪能力约束则是根据雨水管网的主要功能,即排水防洪来设定的。雨水管网需要能够应对一定强度的暴雨,这是其基本的防洪能力要求。同样,当优化结果无法满足防洪能力要求时,模型也将会得到负奖励。
在定义了以上约束之后,本发明通过引入惩罚项的方式将这些约束融入到模型的奖励函数中,从而使得模型在学习过程中始终遵守这些约束。具体的实现方式是,在每一次训练步骤中,都检查新的状态是否满足约束,如果不满足,就给予负奖励,从而引导模型的学习方向。这样设计的目的是,通过将实际的工程约束条件与深度学习模型的训练过程紧密结合,以使得模型能够学习到符合实际应用需求的优化策略。在深度学习模型的学习过程中,这些约束条件起到了明确的指导作用,使得模型不仅能找到解决问题的策略,而且这些策略是符合实际工程约束的,从而提高了模型的实用性和应用价值。因此,所述步骤S3如图3所示,包括以下步骤:
步骤S31:定义物理约束。这包括包括管径约束(上游管段直径需要大于或等于下游管段直径)、埋深约束(上游管段、管点埋深高程需要大于下游管段、管点高程)和连通性约束。一般上游管段埋深高程需要大于下游管段高程,上游管段直径需要大于等于下游管段直径。
步骤S32:定义经济约束。考虑到实际应用中,雨水管网的建设和维护需要一定的经济成本,因此需要在模型中设置造价限制,管网造价需要尽可能地保持在预算内。
步骤S33:定义防洪能力约束。雨水管网需要能够应对一定强度的暴雨,这是其基本的防洪能力要求,因此在模型中也需要设置对应的约束。本实施例中雨水管网需要能够应对四种暴雨,包括一年一遇、五年一遇、十年一遇以及二十年一遇。在这些暴雨发生时,雨水管网,不出现溢流情况。
步骤S34:处理约束。在定义了上述的各种约束之后,模型设计了一种机制能够处理这些约束,使得优化的结果满足约束,即在奖励函数中包含约束。当某个动作违反约束时,可以通过给予负奖励的方式进行惩罚。如果新的状态不满足防洪能力约束,即模型预测的洪水溢出量超过了规定的容忍值,那么可以给予负奖励。
具体来说,奖励函数可以定义为:
R=r1-λ1*C-λ2*V-λ3*D (3)
其中,r1是基础奖励,通常设为正值;C是实际造价超出预算的部分,如果没有超出预算,则C=0;V是洪水溢出量超过容忍值的部分,如果没有超出容忍值,则V=0;D是违反物理约束的程度;λ1,λ2,λ3是对应的惩罚系数,可根据实际情况进行调整。
步骤S35:实现约束处理。将定义好的约束融入到雨水管网优化深度学习模型的训练中。具体的操作可能需要在模型训练的每一步都检查新的状态是否满足约束,或者在每次动作执行后都检查是否违反了约束。
本实施例中需要着重解决了模型的构建、训练、测试以及评估与优化等方面的问题。模型通过城市水文模型SWMM构建城市内涝模型,提供了一个逼真的模拟环境,使得模型可以在多样化的雨水情况下,通过训练学习到最优的管网设计方案。同时,模型引入经验回放和目标网络技术,打破数据间的关联性,提高训练稳定性,同时提供稳定的目标Q值,避免了训练过程中可能出现的不稳定现象。在模型训练完毕后,通过设置不同的降雨强度和频率对模型进行测试,确保模型具备良好的泛化能力和实用性。最后,通过对测试结果的评估,如果模型性能未达预期,可以进一步进行调优,包括调整网络结构、学习率等。本发明将优化过程分步处理,考虑全局和局部的平衡,实现了在满足防洪能力和经济成本优化目标的同时,保证了模型的稳定性和实用性。具体地,如图4所示,所述步骤S4包括以下步骤:
步骤S41:构建模型。使用城市水文模型SWMM来构建城市内涝模型。这个模型可以模拟雨水在管网中的流动情况,并根据给定的动作(即决策)来生成新的状态和奖励。
步骤S42:模型训练。利用生成的数据对Actor网络(决策网络)和Critic网络(价值评估网络)进行训练。训练的目标是最大化累计奖励,即在保证满足约束的前提下,使得管网的防洪能力尽可能高,同时成本尽可能低。
步骤S43:采用经验回放和目标网络技术。为了使训练过程更稳定,本发明采用经验回放(Experience Replay)和目标网络(Target Network)技术。经验回放是通过保存过去的经验(状态,动作,奖励等)并在训练中随机抽取一部分来使用,这样可以打破数据之间的相关性,提高训练的稳定性。目标网络则是为了解决Q-learning中因为更新过程中目标Q值和实际Q值使用相同的参数导致的不稳定问题,它通过创建一个和原网络结构相同但参数更新较慢的网络来提供稳定的目标Q值。
具体地,在经验回放中,雨水管网优化模型保存了过去的一系列经验e=(s,a,r,s′),其中s是当前状态,a是执行的动作,r是得到的奖励,s′是执行动作a后的新状态。这些经验储存在雨水管网优化模型的经验回放缓冲区D中,每次训练时从中随机抽取一个小批量的经验来更新网络参数。在目标网络技术中,模型有两个相同结构的网络:Actor网络A和其对应的目标网络A′,以及Critic网络C和其对应的目标网络C′。网络A和C的参数是通过梯度下降法更新的,而网络A′和C′的参数则是通过软更新来进行的,可表达为:
θ′
θ′
其中,θ
步骤S44:模型测试。为了确保模型的泛化能力,需要将模型在各种可能的环境(如不同暴雨条件下)下进行测试。这一步通过设置不同的降雨强度和频率来进行。
本实施例中在雨水管网多目标优化问题中,涉及到Ornstein-Uhlenbeck噪声过程的应用。需要定义Ornstein-Uhlenbeck噪声过程参数,这是为了适应雨水管网优化中涉及到的连续动作空间,比如管道的直径、埋深和排水节点的位置。引入这种噪声过程可以增加模型在训练阶段的探索能力,因此,在训练阶段会在模型输出的动作上添加该噪声,以鼓励模型探索更多可能的解决方案。然而,当模型在实际应用中做出决策或预测时,需要移除这种噪声,使模型能够输出其认为的最优解,而不受随机噪声的干扰。另外,噪声过程的参数也需要动态调整。如果模型在训练过程中的探索不足,或者预测结果过于保守,可以适当提高噪声的标准差;反之,如果模型的行为过于随机,或者预测结果过于激进,噪声的标准差应适当降低。通过这样的调整,可以使模型在不同降雨条件下都能有较好的表现,进一步优化雨水管网,使其满足防洪和经济的需求。具体地,所述步骤S5包括以下步骤:
步骤S51:定义Ornstein-Uhlenbeck噪声过程参数。在雨水管网的优化问题中,由于动作空间是连续的,包括管道的直径、管道的埋深和排水节点的位置等,因此可以使用Ornstein-Uhlenbeck过程来产生连续的随机噪声。这个过程的参数(如噪声的标准差和theta值)会影响噪声的幅度和频率,需要根据实际的优化问题来设定。Ornstein-Uhlenbeck过程是一个随机过程,其在离散时间下的更新公式为:
X
其中,X
步骤S52:在训练阶段添加噪声。在模型训练阶段,对Actor网络输出的动作添加步骤S51产生的Ornstein-Uhlenbeck噪声。这意味着在决定管道的直径、埋深和排水节点的位置时,会在模型建议的基础上加入一些随机的变化,从而鼓励模型探索更多可能的解决方案,这可以帮助找到更优的雨水管网配置。
具体地,本发明的动作空间包括管道的直径d、管道的埋深l和新增的排水节点n,动作向量为a={d,l,n}。根据Ornstein-Uhlenbeck过程,我们可以为每一个动作参数生成噪声,即为d、l和n分别生成噪声X
a′=a+X
这样,Ornstein-Uhlenbeck过程产生的噪声直接影响了雨水管网的每个决策变量,包括管道的直径d、埋深l和新增排水节点n,从而为模型提供了一种更好地探索解空间的方法。此外,添加到每个决策变量上的噪声需要根据这些决策变量的特性和量纲来调整σ,以使噪声在所有决策变量中的影响保持平衡。
步骤S53:在预测阶段去除噪声。当模型训练完成后,在使用模型进行预测或者决策时,应去除步骤S52中添加的噪声。这样,在实际应用中,可以得到模型认为最优的雨水管网配置,而不会被噪声干扰。
步骤S54:根据训练效果调整噪声参数。如果发现模型在训练过程中的探索不够充分,或者预测的结果过于保守,可以适当增大噪声的标准差;相反,如果模型的行为过于随机,或者预测的结果过于激进,可以适当减小噪声的标准差。这样可以确保模型能够在各种降雨情况下都有良好的表现。
本实施例中需要对模型进行评估与优化。可以通过模拟不同强度的暴雨,比如十年一遇、二十年一遇等,使用当前的模型对雨水管网在各种暴雨强度下的表现进行预测,对模型的效果进行评估。根据预测结果,对模型的防洪能力、经济性以及是否满足基本设计约束等多方面性能进行评估。这种评估可以通过比较预测结果和实际情况,或者根据预设的评估指标来进行。此外,模型要进行迭代优化的判断。如果模型的性能未能达到预设的标准,或者模型对于不同强度的暴雨的处理能力不均衡,就需要对模型进行进一步的优化。优化方式可以包括调整深度确定性策略梯度算法的超参数,比如学习率、折扣因子等,也可以调整网络的结构,比如层数、节点数等。具体地,所述步骤S6包括以下步骤:
步骤S61:模型评估。通过SWMM模拟不同暴雨强度(如十年一遇暴雨、二十年一遇暴雨等)的情况,使用当前的模型进行预测,获取模型对各种暴雨强度下的雨水管网表现的预测结果。
步骤S62:性能评估。根据预测结果,评估模型的性能,包括防洪能力、经济成本和满足基本设计约束等方面。这可以通过与实际情况对比,或者根据预设的评估指标来进行。
步骤S63:迭代优化判断。如果模型的性能未达到预设的标准,或者模型的泛化能力不足,例如对不同强度暴雨的处理能力不均衡,那么需要进一步优化模型。可以调整DDPG的超参数,包括学习率、折扣因子等,也可以调整网络结构,包括层数、节点数等,然后回到步骤S4,进行新一轮的训练。
步骤S64:更新模型。如果模型的性能达到预设的标准,或者达到最大迭代次数,那么此次优化结束。记录下此时的模型参数,用于之后的应用。
本实施例雨水管网优化结果能够应对暴雨重现期分别为一年一遇、五年一遇、十年一遇以及二十年一遇的四种降雨,优化后改动的管段和管点空间分布图如图5所示,其中,虚线部分为优化变动的管网,实线部分为原始无需优化的管网。
总之,基于深度确定性策略梯度算法(DDPG)的雨水管网优化模型是一个结合了深度学习和强化学习方法的先进模型。这个模型通过定义清晰的环境和模型参数,包括状态、动作和奖励,可以有效地处理多目标优化问题和多约束条件。在此模型中,利用深度神经网络构建了Actor和Critic网络,其中,Actor网络用于确定最优的动作,而Critic网络则用于评估Actor网络的动作。同时,模型对状态和动作设定了物理和经济约束,能够实现对连续状态和动作空间的处理。模型的训练过程采用了SWMM模型,通过模拟雨水流动和管网表现,更新状态和奖励,以训练Actor和Critic网络。训练过程还采用了经验回放和目标网络技术来保证训练的稳定性。为增加模型的探索性,训练过程中会向Actor网络的输出动作中添加一些噪声。通过不断的迭代优化,模型可以在各种不同的暴雨强度下进行测试,从而评估模型的性能和泛化能力。模型在处理多目标优化问题和多约束条件,以及在连续状态和动作空间上表现出优良的性能,从而为城市防洪排涝设施设计提供了一个高效、自适应的优化工具。
以上所述仅为本发明的一般步骤,并不能以此限制本发明的保护范围,凡是在本发明的精神和原则之内所作的任何修改和等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于深度确定性策略梯度的虚拟网络功能迁移优化算法
- 一种基于深度确定性策略梯度的虚拟网络功能迁移优化算法