一种基于AC自动机算法的海量黑名单匹配方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及计算机网络安全领域,特别涉及一种基于AC自动机算法的海量黑名单匹配方法。
背景技术
在网络安全领域,基于黑名单的检测技术应用广泛,但随着黑名单和待检测数量的增多,如何保证检测的实时性和效率成为一个问题。现有的BF算法(Brute-Force算法,暴力算法)、KMP算法(bitmap算法,位图算法)、BM算法(Boyer-Moore字符串搜索算法)等虽然在一定程度上能够满足黑名单的检测需求,但依旧存在诸多不足。
Brute-Force算法在每个位置上逐个字符进行比较,需要遍历文本和黑名单中的所有字符。这种方式导致算法的时间复杂度较高,随着文本长度和黑名单数量的增加,算法的执行时间会呈线性增长。
KMP算法通过预处理构建最长公共前缀表,利用这些信息进行跳跃式的匹配。尽管KMP算法下匹配效率得以提高,但在某些情况下,仍然需要在文本中进行多次回溯和移动。特别当存在大量重复字符时,可能需要进行较多的回溯操作,导致匹配效率降低。
BM算法结合了好后缀规则和坏字符规则,通过预处理构建好后缀表和坏字符表,从而进行跳跃式的匹配。尽管BM算法在大多数情况下能够快速地找到匹配,但在某些特定情况下,可能需要进行多次的回溯和移动,特别是在存在大量重复字符且匹配失败的情况下,导致匹配效率降低。
发明内容
针对上述现有技术存在的问题,本申请的目的是提供一种基于AC自动机算法的海量黑名单匹配方法。该方法基于AC自动机算法构建AC自动机(Aho-Corasick自动机),旨在提升匹配黑名单的匹配速度和效率,具体包括:
提取黑名单中模式串的字符集合、分组和ID,并去重;
构建各模式串对应的状态转移表达式;该状态转移表达式为包含节点、边的图形结构;其中,节点表示状态,边表示从一个状态到另一个状态的转移;该状态至少包括状态名和时间戳;
使用AC自动机算法构建各状态转移表达式对应的AC自动机;
运用哈希计算,结合状态名和时间戳重命名各AC自动机的状态,并合并根节点;
将各AC自动机的状态连接到根节点,更新状态转移关系,得到状态转换表和匹配动作表;
根据状态转换表和匹配动作表,对待检测数据进行多核和/或多线程的匹配;
匹配成功后,进行匹配动作响应。
优选地,在提取黑名单中模式串的字符集合、分组和ID时,还包括:将模式串中的短模式串编码为位模式。短模式串为字符长度小于预设长度的模式串。
优选地,更新状态之间的转移关系包括:将各AC自动机中状态转移关系更新为连接到合并后的根节点或包括正常状态转移关系、Epsilon转移关系、失败状态、起始状态和接受状态、跳转和回退关系的其他已连接状态的关系;若AC自动机中状态转移关系为接受状态,则将状态的信息添加到合并后的AC自动机中;若状态之间出现转移冲突,则选择最具体的模式串进行匹配或进行合并。
进一步地,在更新状态转移关系,得到状态转换表和匹配动作表的同时使用无边界延伸算法动态添加节点和边界。
进一步地,在更新状态转移关系,得到状态转换表和匹配动作表的同时使用Sparse State机状态压缩技术进行状态创建。
优选地,在进行匹配时,采用SIMD指令集加速(Single Instruction MultipleData,单指令流多数据流指令加速)、最长匹配优化、优先级匹配和快速失败优化中的一种或多种进行优化匹配。
优选地,在进行匹配时,采用的数据结构包括有限状态自动机、字典树和位图。
如上所述,在该技术方案中,相较于现有技术中的BF算法、KMP算法、BM算法,因针对黑名单的模式串进行了解析、标准化和去重处理,将短模式串编码为位模式,且基于每一个模式串的状态转移表达式构建AC自动机,并利用优化、合并各AC自动机为一个单一的AC自动机的方法,减少了处理对象的数量和长度,并重新构建了数据间的逻辑关系,使得后续的匹配可以快速、高效地进行。此外,众所周知的,多核处理和多线程处理性能明显优于单核处理和单线程处理,能够大幅度提升数据处理的效率,在本发明中,即有效提升黑名单的匹配效率。
在取得以上有益效果的基础上,本申请进一步的方案或优选方案还取得了以下有益效果:边界延伸算法中状态可以跨越字符边界延伸到匹配多个字符,使得一个状态可以同时响应多个模式串,提升匹配效率;Sparse State(稀疏状态)机状态压缩技术能够减少状态的数量,提高匹配性能,减少内存占用;而SIMD指令集加速、最长匹配优化、优先级匹配和快速失败优化都是提升匹配效率的有效优化策略;而有限状态自动机、字典树和位图可支持快速匹配,提升匹配效率。
附图说明
图1是本发明一种实施例的流程示意图。
图2是本发明一种实施例构建AC自动机的流程示意图。
图3是本发明一种实施例运行期匹配过程的流程示意图。
具体实施方式
针对现有技术中存在的技术问题,本申请提供了一种基于AC自动机算法的海量黑名单匹配方法。具体而言,随着黑名单和待检测数量的增多,如何保证检测的实时性和效率成为一个问题,现有的BF算法、KMP算法、BM算法等虽然在一定程度上能够满足黑名单的检测需求。其中,BF算法是最简单直接的方法,但在处理大量文本和复杂黑名单时性能较低,而KMP算法和BM算法利用了一些预处理的技巧,可以在一定程度上提高匹配效率,但随着黑名单和待检测数量的大幅增加,这些算法的性能问题逐渐凸显出来。
一般而言,黑名单匹配会用于下述情景。
入侵检测系统(intrusion detection system,IDS)/入侵防御系统(IntrusionPrevention System,IPS):黑名单可用于识别和阻止已知的恶意IP地址,这些地址可能与恶意活动(如攻击、恶意软件传播等)相关联,IDS/IPS可以根据黑名单进行实时检测和阻断,提高网络的安全性。
防火墙规则:网络防火墙可以使用黑名单地址列表来配置防火墙规则,阻止从这些IP地址发起的入站或出站流量,这可以帮助防止来自已知恶意来源的攻击或不信任的流量。
邮件过滤:黑名单可以用于电子邮件过滤系统,识别和拦截来自这些地址的垃圾邮件、恶意链接或恶意附件,这有助于减少垃圾邮件和恶意软件的传播;
访问控制列表(Access Control Lists,ACL):网络设备(如路由器、交换机)可以使用黑名单地址列表来配置ACL,限制从这些IP地址访问网络资源或服务。
网站访问控制:网站管理员可以使用黑名单来限制来自这些IP地址的访问,以保护网站免受来自恶意用户或恶意行为的威胁。
随着计算机技术的高速发展,信息传递速率也在节节攀升。一方面,这使得信息交流变得更为便捷快速,另一方面,也使得网络攻击的手段更为丰富,攻击速率更为迅猛。因此,建立反应迅速的网络安全防护系统,开发网络安全防范产品和方法成为迫在眉睫的现实需求和本领域技术人员的责任。
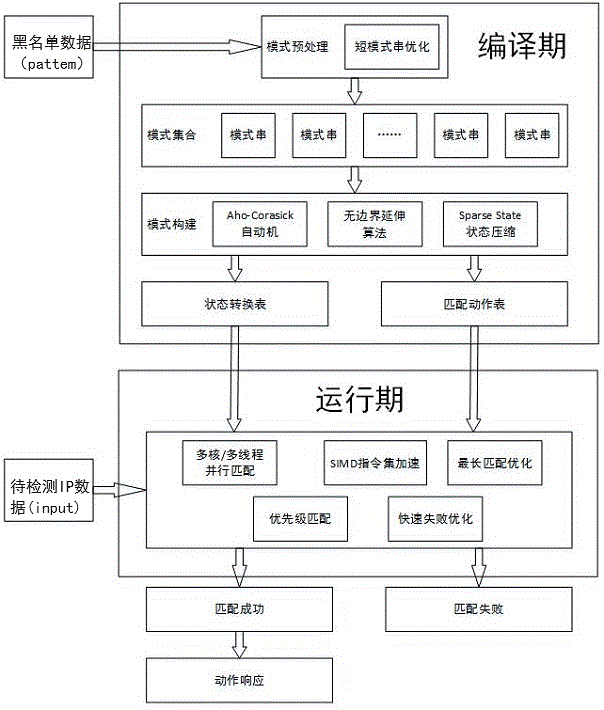
基于上述时代背景和现实需求,本发明提供了一种基于AC自动机算法的海量黑名单匹配方法,该方法基于AC自动机,如图1所示,具体包括编译期和运行期两部分;编译期包括:
准备大量IP黑名单数据(Pattern)和待检测的IP数据(Input);
将Pattern作为输入,Pattern中每一个IP黑名单数据是一个模式串,所有的IP黑名单数据作为一组模式串。首先,对提供的一组模式串进行解析和标准化,提取其字符集合、分组和唯一ID。对于模式集合中长度较短的短模式串,将其预先编码成为一种特殊的模式串—位模式。具体而言,将长度较短的模式串视为短模式串,通常为预设长度阈值在4到8个字符之间的固定字符串,其中,不包含通配符或正则表达式。然后,对模式串进行去重处理,防止相同的模式串被多次包含在后续构建的模式集合中,以减少不必要的匹配尝试;在对模式串进行解析和去重处理后,基于黑名单中以分组和ID区分出的不同的字符集合,对每个模式串、位模式构建状态转移表达式,状态转移表达式是一个包含节点、边的图形结构,其中节点表示状态,边表示从一个状态到另一个状态的转移。这个过程称为模式的预处理和转换操作,多个模式串在经过预处理和转换操作后的状态转移表达式构成模式集合。
如图2所示,基于模式集合,进行多模式串合并,将多个状态转移表达式合并成一个单一的AC自动机。AC自动机是一种有向带标签的多叉树结构,它能够在输入数据中同时匹配多个模式,并以线性时间复杂度完成匹配。
首先,使用AC自动机算法构建各状态转移表达式对应的AC自动机,再对AC自动机的状态进行重命名。为防止状态之间的冲突,即状态名的重复,每个AC自动机的状态都会被重命名,以确保它们在合并后仍然唯一,通过结合原本的状态名和时间戳的HASH(哈希)运算来获得新的状态名。
然后,合并根节点,将所有AC自动机的根节点(即起始状态)合并成一个新的根节点,将新的根节点将作为合并后的AC自动机的根。最后连接状态,将各个AC自动机的状态连接到新的根节点,更新状态之间的转移关系。
其中,更新状态之间的转移关系是一个关键步骤,它确保合并后的AC自动机能够正确地匹配多个模式串,主要包括以下步骤:将原始AC自动机中的状态转移关系更新为连接到新的根节点或其他已连接状态的关系,即状态将以新的方式响应输入字符。如果原始AC自动机中的状态转移关系是表示一个模式串结束的接受状态,则需将接受状态的信息添加到合并后的AC自动机中,以便在匹配时正确地跟踪模式串的结束;在多个AC自动机合并时,可能会出现状态之间的转移冲突,即多个状态都试图响应相同的输入,此时需选择最具体的模式串进行匹配或合并多个转移。
其中,其他已连接状态的关系为:当多个AC自动机被合并时,这些初始状态被连接到合并后的根节点,以形成一个大的联合状态机。在联合状态机中,其他已连接状态是指那些与根节点直接或间接相连的状态,这些状态在合并后的状态机中具有相同的行为,可看作是已连接状态的一部分。
更新状态转移关系以连接到合并后的根节点或其他已连接状态的目的是优化状态机的性能和内存使用。可以减少状态机的复杂性,并且在查找和匹配过程中提供更高的效率。
具体而言,其他已连接状态的关系包括:
正常状态转移关系:表示从一个状态到另一个状态的正常状态转移,通常由特定输入字符触发。在AC自动机中,这些状态转移关系用于构建匹配模式的有向图,以确定字符串是否匹配任何模式。
Epsilon(空)转移关系:Epsilon转移是一种特殊的状态转移,不需要输入字符来触发,用于将状态连接到其他状态,可用于实现状态的跳转和优化匹配性能。
失败状态:在AC自动机中,通常有一个失败状态,当没有匹配的模式时,会转移到这个状态。失败状态有助于快速退出匹配操作,不必检查所有可能的状态。
起始状态和接受状态:起始状态表示AC自动机的初始状态,它是匹配操作的起点。接受状态表示匹配操作已成功,已找到匹配模式。
跳转和回退关系:有些AC自动机实现可能会使用额外的跳转关系,以加速匹配操作,可用于快速跳过输入字符或回退到之前的状态。
上述状态之间的连接关系构成了整个合并后的状态机的结构。
在构建AC自动机的过程中,可引入无边界延伸算法和Sparse State机状态压缩技术来优化AC自动机的构建。
在传统的AC自动机中,每个状态只负责匹配一个字符,但在无边界延伸算法中,状态可以跨越字符边界,延伸到匹配多个字符,这使得一个状态可以同时响应多个模式串。无边界延伸算法可以通过利用正则表达式中的无边界回溯和匹配延伸特性,以线性时间复杂度处理具有回溯性质的正则表达式,引入额外的状态信息和剪枝策略,从而避免不必要的回溯操作。
在传统的AC自动机中,会为每个字符创建状态,而采用Sparse State机状态压缩技术后,并不会立即为每个输入字符创建一个新状态,相反,状态的创建是根据模式串的实际字符需求进行的,如果多个模式串共享相同的前缀,那么只有在这个前缀的最后一个字符需要匹配时才会创建一个新的状态,这样,状态的创建会被延迟,直到确实需要匹配某个字符时才会进行状态创建。换言之,SparseState机状态压缩技术只对构建节点中具有状态转换的节点进行存储,省略没有状态转换的节点,可减少AC自动机的内存占用。此外,该技术可按照模式集合中的节点出现的频率对节点进行排序,将出现次数较少的节点删除,并调整指向这些节点的转移边,最后重新构建状态图,输出状态转移表。
合并后的优化AC自动机包含两个部分,状态转移表和匹配动作表,其中状态转移表用于描述AC自动机中状态之间的字符转移关系,用于确定AC自动机如何在Input中移动以寻找匹配;匹配动作表用于存储与状态相关联的匹配动作。
运行期包括:
利用生成的状态转换表和匹配动作表,根据具体的Input进行实际的匹配操作,以最小开销进行模式匹配。当待检测数据,例如输入文本字符到达时,根据当前状态以及输入字符查找状态表,以确定下一个状态,根据状态转移表逐字符地移动,直到达到一个接受状态,即找到一个匹配的模式串,或匹配失败。当达到接受状态,会查找匹配动作表,以执行与该状态相关联的匹配动作。具体的匹配过程如图3所示。
优选地,在运行期的匹配阶段,通过利用服务器的多核多线程和SIMD,从硬件的角度提升匹配的性能;通过利用最长匹配优化、优先级匹配和快速失败优化等匹配策略,从软件的角度提升匹配的效率。
其中,SIMD即单指令多数据流(Single Instruction Multiple Data)指令集,是通过一条指令同时对多个数据进行运算的硬件加速技术。在传统计算中,使用标量运算一次只能对一对数据执行乘法操作,使用SIMD加速,则可同时对多对数据进行处理。常见的SIMD有基于x86体系的sse和avx。显而易见,相较于传统的单线程处理方式,同时对多对数据进行处理效率更高。
最长匹配优化是基于最长匹配原则的一种匹配方法,在匹配时自动匹配到最长的模式串来减少匹配结果的数量,减少不必要的回调触发。该方法假定文中单词从左到右排列,从头开始,把最长的字词作为基本处理单元,尽可能地匹配最长的词,而非简单地切割词语或字母,由此减少匹配过程中处理对象的数量。因此,如果多个模式串都匹配到输入文本的一部分,只会报告最长匹配,而不会报告所有可能的匹配,从而达到提升匹配速度和匹配效率的技术效果。
优先级匹配允许为不同的模式串分配优先级,当多个模式串匹配相同位置时,优先级最高的模式串将会被选中作为匹配结果。
快速失败优化用于加速匹配失败的情况,如果在某个状态无法匹配任何模式串,会在这个状态快速失败而不继续深入匹配。可见,无论是多核处理还是多线程匹配,其处理数据的速度和效率都优于单核或单线程。
优选地,在进行逐行匹配时,采用的数字结构包括有限状态自动机、字典树和位图。对比而言,传统算法中多采用数组、指针和字符串来实现字符比较和位置移动。
有限状态自动机(FSM finite state machine或FSA finite state automaton )是自动机理论的研究对象,是为研究有限内存的计算过程和某些语言类而抽象出的一种计算模型。有限状态自动机拥有有限数量的状态,每个状态可以迁移到零个或多个状态,输入字串决定执行哪个状态的迁移。
字典树(Trie树)是一种树形结构,是一种哈希树的变种。在数据匹配的实际应用中,可利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,从而提升匹配效率。
位图(Bitmap)是一种广泛应用于索引、数据压缩等方面的数据结构。具体而言,用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况,通常用于判断某一个数据是否存在。在本发明中,位图的应用可快速判断黑名单数据在某个待检测IP数据中是否存在,从而提升匹配效率。
可见,在该技术方案中,相较于现有技术中的BF算法、KMP算法、BM算法,因针对黑名单的模式串进行了解析、标准化和去重处理,将短模式串编码为位模式,且基于每一个模式串的状态转移表达式构建AC自动机,并利用优化、合并各AC自动机为一个单一的AC自动机的方法,减少了处理对象的数量和长度,并重新构建了数据间的逻辑关系,使得后续的匹配可以快速、高效地进行。此外,众所周知的,多核处理和多线程处理性能明显优于单核处理和单线程处理,能够大幅度提升数据处理的效率,在本发明中,即有效提升黑名单的匹配效率。
在取得以上有益效果的基础上,本发明进一步的方案或优选方案还取得了以下有益效果:边界延伸算法中状态可以跨越字符边界延伸到匹配多个字符,使得一个状态可以同时响应多个模式串,提升匹配效率;Sparse State机状态压缩技术能够减少状态的数量,提高匹配性能,减少内存占用;而SIMD指令集加速、最长匹配优化、优先级匹配和快速失败优化都是提升匹配效率的有效优化策略;而有限状态自动机、字典树和位图可支持快速匹配,提升匹配效率。
以上仅为本发明的优选实施例而已,并不用于限制本发明新型,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于布隆算法实现海量黑名单处理的方法
- 一种对海量含通配符黑名单高速匹配的方法