一种具有漂移修正和收敛加速的联邦学习方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于联邦学习技术应用领域,涉及一种具有漂移修正和收敛加速的联邦学习方法。
背景技术
随着人工智能的隐私安全问题日益严重,联邦学习(Federated Learning,FL)逐渐成为一种引人注目的机器学习方法。作为一种新兴的分布式机器学习框架,FL的各个子节点(叫做客户端)仅与中央节点(叫做服务器)进行通信,其目的是利用客户端节点的私有数据共同协作训练一个全局模型。FL最具吸引力的特性是客户端的本地数据不会被泄露,客户端与服务器之间仅仅传输必要的模型参数,从而在训练模式上实现了对客户端数据的隐私性保护。
然而,与传统的分布式学习不同,注重数据隐私安全的FL无法像分布式系统那样将所有数据进行主动划分和打乱以保证训练的高效稳定。因此,FL面临的分布式数据集是非独立同分布的(non-iid)。由于用户的偏好和使用习惯等,FL系统中的客户端的本地数据分布会完全不同。当采用与FedAvg类似的训练方式时,客户端的本地训练会使得模型向局部最优解的方向前进;当服务器对本地模型进行聚合时,全局模型会使模型趋于全局最优解。这种现象称为客户端漂移。由于客户端漂移的存在,FL的训练使得模型的梯度向本地目标函数和全局目标函数的折中的方向下降,造成全局模型的性能不佳,收敛速度缓慢。此外,由于客户端的网络连接、计算内存和设备电量等因素,每次参与训练的活动客户端子集仅占全体客户端的很小一部分,而这样的部分参与特性加剧了客户端漂移对FL模型的性能损失。
现有的解决客户端漂移的FL方法具有如下的问题:(1)对漂移变量的考虑不完备,从而无法获得更加精确的修正模型,造成模型性能不佳,收敛速度较慢;(2)中央服务器与客户端之间需要传输额外的变量来修正模型,导致整体通信量增加;(3)在面对大量客户端低参与度的困难数据异构场景时模型鲁棒性较低,造成严重的性能损失。
由于存在上述问题,针对数据异构FL带来的客户端漂移挑战,现有的联邦学习方法效果仍没有达到最佳,性能提升空间很大,如何缓解和改善客户端漂移对全局模型训练造成的不利影响依然有很大的研究价值。
发明内容
针对上述技术问题,本发明提出了一种漂移修正的联邦学习方法,以加快模型收敛和降低通信成本。首先,本发明将漂移变量分解为本地漂移变量和全局漂移变量,并分别对它们进行更新,然后利用它们来修正本地目标函数。此外,本发明在本地目标函数上增加了一个全局参数修正项来加速模型的收敛,降低通信开销。为实现上述目的,本发明采用的技术方案为:
步骤一、构建包括一个中央服务器和N个客户端的典型联邦学习系统:
步骤101、意图参与联邦训练客户端向中央服务器发起注册,中央服务器为该客户端分配存储空间用于存储模型参数;
步骤102、在第t个通信回合,中央服务器以概率ε选择部分活动客户端子集S
步骤二、被选中的客户端利用本地数据对模型进行训练,在训练后对本地漂移变量和全局漂移变量进行更新,并将训练后的模型参数上传至中央服务器:
步骤201、本地客户端i∈S
其中,
步骤202、客户端在训练后对本地漂移变量
其中,t′是该客户端上一次参与训练时的通信回合数,λ是全局漂移变量更新时的权重系数;
步骤203、客户端将更新后的本地模型
步骤三、中央服务器利用服务器端的漂移变量对更新后的本地模型参数进行联邦聚合,并将聚合更新后的本地模型下发至活动客户端进行下一轮本地训练;
步骤301、中央服务器对接收到的本地模型进行平均,即:
步骤302、中央服务器利用平均模型参数
其中,h
步骤303、中央服务器利用服务器端的漂移变量更新全局模型,并将更新后的全局模型下发给活动客户端子集S
步骤四、在中央服务器与客户端通信T个回合后,输出最终模型:
步骤401、中央服务器与客户端通信T个回合后,利用存储在中央服务器上的所有客户端的本地模型参数,计算得到此次训练的最终模型w
本发明提供的一种具有漂移修正和收敛加速的联邦学习方法,与现有技术相比,具有以下特点:
(1)由于本发明通过定义本地漂移变量和全局漂移变量来获得更加准确的修正模型参数,从而减轻了客户端漂移对全局模型的影响,极大提升了模型的性能;
(2)本发明在本地目标函数上增加了一个全局参数修正项来加速模型的收敛,并且仅仅传输模型参数而不需要传输额外的变量来修正模型,从而大大降低了本方法的通信开销;
(3)本发明所提出的联邦学习方法在面对大量客户端低参与度的困难数据异构场景时具有较强的鲁棒性,仍然可以保持良好的模型性能和收敛速度。
附图说明
图1为本发明的流程框图;
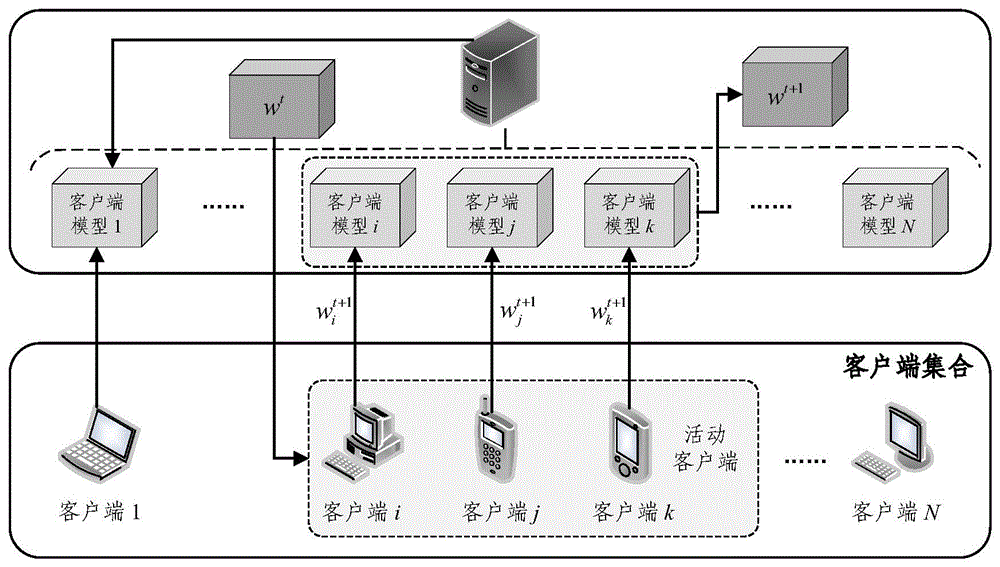
图2为本发明的系统架构图;
具体实施方式
下面结合附图及本发明的实施对本发明的方法作进一步的详细的说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1表示的是一种具有漂移修正和收敛加速的联邦学习方法的流程图。
图2表示的是一种具有漂移修正和收敛加速的联邦学习方法的系统架构图。
为便于对本发明实施例的理解,下面结合附图说明本发明的合理性与有效性,包含具体步骤如下:
步骤一、构建包括一个中央服务器和N=500个客户端的典型联邦学习系统:
步骤101、意图参与联邦训练客户端向中央服务器发起注册,中央服务器为该客户端分配存储空间用于存储模型参数;
步骤102、在第t个通信回合,中央服务器以概率ε=5%选择部分活动客户端子集S
步骤二、被选中的客户端利用本地数据对模型进行训练,在训练后对本地漂移变量和全局漂移变量进行更新,并将训练后的模型参数上传至中央服务器:
步骤201、本地客户端i∈S
其中,
步骤202、客户端在训练后对本地漂移变量
其中,t′是该客户端上一次参与训练时的通信回合数,λ=0.97是全局漂移变量更新时的权重系数;
步骤203、客户端将更新后的本地模型
步骤三、中央服务器利用服务器端的漂移变量对更新后的本地模型参数进行联邦聚合,并将聚合更新后的本地模型下发至活动客户端进行下一轮本地训练;
步骤301、中央服务器对接收到的本地模型进行平均,即:
步骤302、中央服务器利用平均模型参数
其中,h
步骤303、中央服务器利用服务器端的漂移变量更新全局模型,并将更新后的全局模型下发给活动客户端子集S
步骤四、在中央服务器与客户端通信T=1000个回合后,输出最终模型:
步骤401、中央服务器与客户端通信T=1000个回合后,利用存储在中央服务器上的所有客户端的本地模型参数,计算得到此次训练的最终模型w
。
- 一种具有焊片自动装配带纠正和喷涂助焊剂作用的设备
- 一种具有轻量级验证机制的隐私保护联邦学习方法
- 一种具有奖惩机制的联邦学习方法及相关装置