一种基于尿液代谢组数据的尿结石风险预测方法及其系统
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及医疗数据处理技术领域,尤其涉及一种基于尿液代谢组数据的尿结石风险预测方法及其系统。
背景技术
尿结石是指在人体的泌尿系统内形成的固体结晶物质,其成分多种多样,包括草酸钙、草酸铵、磷酸钙、尿酸等。尿结石的形成过程是一个复杂的生化反应过程,主要包括以下几个步骤:饮食和代谢因素:饮食中的某些物质(如高蛋白质、高盐、高糖)以及代谢产物(如尿酸、草酸等)可以促进结石的形成。聚集:尿液中的溶解物质逐渐沉淀并聚集形成小结晶。生长:小结晶不断吸收尿液中的溶解物质并逐渐增大,最终形成可见的结石。粘附:结石表面具有一定的电荷特性,可以吸附细菌和其他微生物,形成感染源。移行:结石可以通过尿道、输尿管等部位移行,并引起疼痛和不适等症状。
采用尿液代谢组数据进行尿结石的分析,具体的分析过程为:样本采集:收集患者的尿液样本,并保存在低温条件下,避免代谢物质的降解和变化。数据获取:使用代谢组学技术(如质谱分析、核磁共振等)对尿液样本进行分析,获得代谢物质的定量和定性信息。数据预处理:对代谢物质的数据进行去噪、校正和归一化等预处理步骤,以保证数据的准确性和可比性。统计分析:使用统计学方法对代谢物质的数据进行分析,包括聚类分析、主成分分析、差异分析等,以确定不同样本之间的差异和相似性。生物信息学分析:将代谢物质的数据与生物信息学数据库进行比对和注释,以识别与尿结石相关的代谢通路和生物标志物。结果解释:根据分析结果,评估患者尿结石的风险和类型,并制定个性化的治疗方案。
但现有技术中的尿液代谢组数据进行尿结石的分析存在如下弊端:
(1)样本收集:尿液样本的质量和数量可能受到多种因素的影响,如采集时间、饮食、药物使用等。因此,样本收集过程需要严格控制,以确保数据的准确性和可靠性。
(2)数据处理:代谢组学技术的数据处理过程较为复杂,需要运用多种算法和软件进行预处理、统计分析和生物信息学分析。不同算法和软件之间的结果可能存在差异,需要经过反复验证和比对才能确定最终结果。
(3)数据解释:尿液代谢组数据分析的结果需要进一步与临床表现和其他检查结果相结合,才能作出准确的诊断和治疗决策。因此,需要具备专业的临床知识和经验,才能对数据进行科学的解释和应用。
(4)个体差异:尿液代谢组数据在不同个体之间存在显著差异,如年龄、性别、体重、饮食等因素都会对代谢物质的水平和类型产生影响。因此,需要考虑个体差异的影响,制定个性化的分析和治疗方案。
发明内容
为了解决上述问题,本发明提出一种基于尿液代谢组数据的尿结石风险预测方法及其系统,以通过机器学习方法,对大量的尿液代谢组数据进行训练,并构建出一个高效的分类模型或预测模型,以便在未来的样本中快速而准确地识别和预测尿结石的发生。同时,通过该技术还能够深入挖掘和解释代谢组数据中的关键特征和变化,从而更好地理解尿结石形成的机制和规律。此外,该技术还能够实现个体差异的自适应调整和优化,提高尿液代谢组数据分析的准确性和稳定性。
本发明通过以下技术方案实现的:
本发明提出一种基于尿液代谢组数据的尿结石风险预测方法,包括:
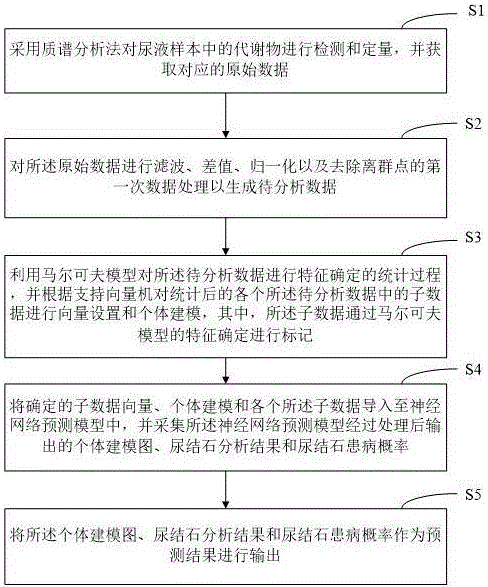
采用质谱分析法对尿液样本中的代谢物进行检测和定量,并获取对应的原始数据;
对所述原始数据进行滤波、差值、归一化以及去除离群点的第一次数据处理以生成待分析数据;
利用马尔可夫模型对所述待分析数据进行特征确定的统计过程,并根据支持向量机对统计后的各个所述待分析数据中的子数据进行向量设置和个体建模,其中,所述子数据通过马尔可夫模型的特征确定进行标记;
将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率;
将所述个体建模图、尿结石分析结果和尿结石患病概率作为预测结果进行输出。
进一步地,所述采用质谱分析法对尿液样本中的代谢物进行检测和定量,并获取对应的原始数据的步骤,包括:
采用液相色谱-质谱联用法对所述尿液样本进行高效液相色谱柱物质分离,生成第一样本数据;
采用气相色谱-质谱联用法对所述尿液样本进行气态化合物检测,生成第二样本数据;
并获取对尿液样本进行注射质谱法后的检测数据;
整合所述第一样本数据与所述第二样本数据生成所述原始数据,并将所述原始数据与检测数据进行比对判断原始数据误差阈值是否低于预设值;
若是,则获取所述原始数据。
进一步地,对所述原始数据进行滤波、差值、归一化以及去除离群点的第一次数据处理以生成待分析数据的步骤,包括:
滤波:采用Butterworth数字滤波器对所述原始数据进行处理,去除高频噪声和低频漂移并保留中频部分;
差值:采用二阶差分算法将原始数据转换成差分形式生成出代谢物浓度的变化趋势;
归一化:采用Z-score归一化消除原始数据中各个子数据之间的浓度差异;
去除离群点:依照滤波保留的中频部分对原始数据进行中位数绝对偏差以排除异常值。
进一步地,所述利用马尔可夫模型对所述待分析数据进行特征确定的统计过程,并根据支持向量机对统计后的各个所述待分析数据中的子数据进行向量设置和个体建模的步骤,包括:
通过所述马尔可夫模型对待分析数据中的各个子序列进行分类,并采用转移概率矩阵和稳态概率分布对各个所述子序列进行关键特征提取过程;
对各个所述子序列进行数学向量转化生成与各个子序列匹配的序列向量,并根据所述关键特征提取过程对各个序列向量进行维度和特征权重的设置;
创建三维坐标系XYZ,分别为液态浓度特征X、气态浓度特征Y、尿结石患病概率Z;
将各个进行维度和特征权重设置后的序列向量输入至所述三维坐标系中,通过各个序列向量中的液态浓度特征X和气态浓度特征Y输入在三维坐标系中构建出第一三维坐标系XY。
进一步地,所述将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率的步骤,包括:
将子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,通过所述神经网络预测模型评估出尿结石患病概率Z;
再将所述尿结石患病概率Z输入至第一三维坐标系XY生成第二三维坐标系XYZ,并将所述第二三维坐标系XYZ作为个体建模图输出。
进一步地,所述将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率的步骤,包括:
将将确定的子数据向量、个体建模和各个所述子数据导入至预先训练的神经网络预测模型中;
通过前向传播算法,将所述子数据向量从输入层经过多个隐含层传递到输出层并在每个神经元上应用ReLU激活函数,再由输出层输出尿结石患病概率;
匹配所述子数据向量与预设数据库中的若干相近向量,以生成若干相近向量中的验算概率值,并将尿结石患病概率与验算概率值进行评估获得误差;
采用反向传播算法对误差进行各层神经元的权重和偏置,从而生成尿结石分析结果和尿结石患病概率。
进一步地,所述采用反向传播算法对误差进行各层神经元的权重和偏置,从而生成尿结石分析结果和尿结石患病概率的步骤,包括:
根据反向传播算法计算出每个神经元对误差的贡献度值,进而得到误差梯度,其中,误差梯度为神经网络模型输出对于各个所述子数据向量的权重和偏置的变化量;
根据所述误差梯度和学习率,调整各个所述子数据向量的权重和偏置的值以输出尿结石分析结果和尿结石患病概率。
进一步地,所述匹配所述子数据向量与预设数据库中的若干相近向量,以生成若干相近向量中的验算概率值,并将尿结石患病概率与验算概率值进行评估获得误差的步骤,包括:
预设数据库中的若干相近向量为历史数据,所述历史数据包括若干相近向量所对应的以往患者实际患病情况,取所述若干相近向量的实际患病均值作为验算概率值。
本发明还提出一种基于尿液代谢组数据的尿结石风险预测系统,包括:
获取单元,用于采用质谱分析法对尿液样本中的代谢物进行检测和定量,并获取对应的原始数据;
预处理单元,用于对所述原始数据进行滤波、差值、归一化以及去除离群点的第一次数据处理以生成待分析数据;
统计单元,用于利用马尔可夫模型对所述待分析数据进行特征确定的统计过程,并根据支持向量机对统计后的各个所述待分析数据中的子数据进行向量设置和个体建模,其中,所述子数据通过马尔可夫模型的特征确定进行标记;
预测单元,用于将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率;
输出单元,用于将所述个体建模图、尿结石分析结果和尿结石患病概率作为预测结果进行输出
本发明的有益效果:
(1)预测精度高:该方法通过对大量尿液样本的分析和建模,可以高度准确地预测个体患尿结石的风险水平。相比传统的尿液检测和医学问卷调查等方式,该方法可以更加全面、客观地评估患者的风险情况。
(2)早期预警功能强:由于该方法可以在个体患病前预测其患病风险,因此可以帮助医生和患者及时发现可能存在的尿结石风险,从而采取有效措施进行干预和治疗,减少疾病的发生和发展。
(3)指导个性化治疗:该方法还可以根据个体的尿液代谢组特征,为医生提供指导性的治疗建议,包括饮食调整、药物治疗等方面,从而实现个性化治疗,提高治疗效果和患者的满意度。
(4)提高临床工作效率:该方法可以通过快速、自动化的数据分析和处理,大幅提高临床工作效率。相比传统的尿液检测和医学问卷调查等方式,该方法可以更加快捷地获取相关数据,并生成预测结果和治疗建议。
附图说明
图1为本发明的基于尿液代谢组数据的尿结石风险预测方法的流程示意图;
图2为本发明的基于尿液代谢组数据的尿结石风险预测系统的结构框图;
本申请为目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
实施方式
为了更加清楚完整的说明本发明的技术方案,下面结合附图对本发明作进一步说明。
请参考图1,为本发明提出的一种基于尿液代谢组数据的尿结石风险预测方法流程示意图,该方法包括:
S1,采用质谱分析法对尿液样本中的代谢物进行检测和定量,并获取对应的原始数据;
在具体实施的过程中,采用液相色谱-质谱联用法对所述尿液样本进行高效液相色谱柱物质分离,生成第一样本数据;采用气相色谱-质谱联用法对所述尿液样本进行气态化合物检测,生成第二样本数据;并获取对尿液样本进行注射质谱法后的检测数据;整合所述第一样本数据与所述第二样本数据生成所述原始数据,并将所述原始数据与检测数据进行比对判断原始数据误差阈值是否低于预设值;若是,则获取所述原始数据。
液相色谱-质谱联用法分离物质:采用液相色谱-质谱联用法,对尿液样本进行高效液相色谱柱物质分离,以获得第一样本数据。在此过程中,样本中的化合物将被分离并进行检测,从而获得关于样本中不同化合物含量的信息。气相色谱-质谱联用法检测气态化合物:采用气相色谱-质谱联用法,对尿液样本进行气态化合物检测,以获得第二样本数据。在此过程中,样本中的气态化合物会通过气相色谱柱进行分离,并通过质谱仪进行检测和鉴定。获取注射质谱法检测数据:对尿液样本进行注射质谱法后的检测,以获取更为全面的检测数据。在此过程中,样本会经过质谱仪的分析和检测,获得更为详细和全面的代谢组信息。整合数据并比对误差阈值:将第一样本数据和第二样本数据整合在一起,生成原始数据。然后将原始数据与检测数据进行比对,并判断原始数据误差阈值是否低于预设值。如果误差阈值低于预设值,则说明所获得的数据准确度较高,可以作为后续分析和预测的依据。该步骤是通过不同的方法对尿液样本进行分析和检测,获得多种不同类型的代谢组数据,并通过整合和比对来保证数据的准确性和可靠性。
S2,对所述原始数据进行滤波、差值、归一化以及去除离群点的第一次数据处理以生成待分析数据;
滤波:采用Butterworth数字滤波器对所述原始数据进行处理,去除高频噪声和低频漂移并保留中频部分;Butterworth数字滤波器可以对原始数据进行处理,去除高频噪声和低频漂移,并保留中频部分。高频噪声通常来自仪器本身或者采集过程中的干扰,而低频漂移则可能由于环境变化等因素导致。滤波后的数据更加平滑和稳定,方便后续的数据处理和分析。
差值:采用二阶差分算法将原始数据转换成差分形式生成出代谢物浓度的变化趋势;二阶差分算法可以将原始数据转换成差分形式,从而生成出代谢物浓度的变化趋势。这个步骤可以帮助我们更好地理解数据的变化规律,从而为后续的数据分析和建模提供基础。
归一化:采用Z-score归一化消除原始数据中各个子数据之间的浓度差异;Z-score归一化是一种经典的归一化方法,可以消除原始数据中各个子数据之间的浓度差异。通过计算每个子数据的均值和标准差,可以将其转换为一个标准正态分布,方便后续的数据分析和建模。
去除离群点:依照滤波保留的中频部分对原始数据进行中位数绝对偏差以排除异常值;在进行数据分析和建模时,异常值可能会对结果产生较大的影响,因此需要对其进行排除。在本文中,我们采用中位数绝对偏差(MAD)来判断是否为离群点,并将其从原始数据中排除。MAD是一种比较鲁棒的统计方法,可以有效地识别异常值。
S3,利用马尔可夫模型对所述待分析数据进行特征确定的统计过程,并根据支持向量机对统计后的各个所述待分析数据中的子数据进行向量设置和个体建模,其中,所述子数据通过马尔可夫模型的特征确定进行标记;
S4,将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率;
S5,将所述个体建模图、尿结石分析结果和尿结石患病概率作为预测结果进行输出。
在一个实施例中,所述利用马尔可夫模型对所述待分析数据进行特征确定的统计过程,并根据支持向量机对统计后的各个所述待分析数据中的子数据进行向量设置和个体建模的步骤,包括:
通过所述马尔可夫模型对待分析数据中的各个子序列进行分类,并采用转移概率矩阵和稳态概率分布对各个所述子序列进行关键特征提取过程;在尿液代谢组数据分析中,可以将尿液样本的各个代谢物浓度作为状态,将时间点作为步数,构建一个时间序列,然后应用马尔可夫模型进行分析。对于待分析的数据中的各个子序列,可以将其视为一系列状态的集合。然后,我们可以利用转移概率矩阵来描述各个状态之间的转移概率。具体地说,对于每个状态j,转移概率矩阵中的元素pij表示从状态i到状态j的概率。这样,我们就可以利用转移概率矩阵来计算任意给定子序列的概率,并据此进行分类。一旦完成了子序列的分类,我们可以采用稳态概率分布来对各个子序列进行关键特征提取。稳态概率分布指的是当系统达到平稳状态时,各个状态的出现概率所构成的概率分布。在尿液代谢组数据分析中,可以将各个子序列视为系统的不同状态,并根据转移概率矩阵计算出稳态概率分布。然后,我们可以利用稳态概率分布来确定哪些代谢物对子序列的分类最具有贡献,从而进行关键特征提取。
对各个所述子序列进行数学向量转化生成与各个子序列匹配的序列向量,并根据所述关键特征提取过程对各个序列向量进行维度和特征权重的设置;对各个所述子序列进行数学向量转化生成的过程是将每个子序列中的代谢物浓度数据转化为一个数学向量,以便于计算和比较。具体地说,可以将每个子序列中的代谢物浓度按时间顺序排列,并将其作为该子序列对应的数学向量。这样,我们就可以利用数学工具来比较不同子序列之间的相似性或差异性。接下来,根据关键特征提取过程,可以对各个序列向量进行维度和特征权重的设置。维度指的是数学向量的长度,即其中包含的元素数量。在尿液代谢组数据分析中,每个数学向量都代表一个子序列,因此其维度应该与代谢物数量相同。特征权重则指的是数学向量中每个元素的重要性,它们可以用来区分不同的子序列并确定哪些代谢物对分类最具有贡献。根据稳态概率分布,我们可以计算出每个代谢物对子序列分类的贡献值,并据此设置特征权重。
创建三维坐标系XYZ,分别为液态浓度特征X、气态浓度特征Y、尿结石患病概率Z;
将各个进行维度和特征权重设置后的序列向量输入至所述三维坐标系中,通过各个序列向量中的液态浓度特征X和气态浓度特征Y输入在三维坐标系中构建出第一三维坐标系XY。
而所述将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率的步骤,包括:
将子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,通过所述神经网络预测模型评估出尿结石患病概率Z;
再将所述尿结石患病概率Z输入至第一三维坐标系XY生成第二三维坐标系XYZ,并将所述第二三维坐标系XYZ作为个体建模图输出。
在一个实施例中,所述将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率的步骤,包括:
将将确定的子数据向量、个体建模和各个所述子数据导入至预先训练的神经网络预测模型中;
通过前向传播算法,将所述子数据向量从输入层经过多个隐含层传递到输出层并在每个神经元上应用ReLU激活函数,再由输出层输出尿结石患病概率;前向传播算法是神经网络中的一种计算方法,它可以将输入数据从输入层经过多个隐含层传递到输出层,并计算出每个输出节点对应的输出值。在这个过程中,每个神经元都会应用一个激活函数,如ReLU激活函数。具体地说,对于每个输入向量,它会被送入输入层中的神经元,然后经过一系列的权重计算和激活函数的作用,最终得到输出层的结果。在每个隐含层中,通过矩阵乘法和偏置项加和来计算下一层的输入。同时,在每个神经元上,使用ReLU激活函数来产生非线性的响应。最终,输出层的神经元将根据其对应的患病概率输出一个值,表示该输入向量的尿结石患病概率。
匹配所述子数据向量与预设数据库中的若干相近向量,以生成若干相近向量中的验算概率值,并将尿结石患病概率与验算概率值进行评估获得误差;
采用反向传播算法对误差进行各层神经元的权重和偏置,从而生成尿结石分析结果和尿结石患病概率。
具体的,所述采用反向传播算法对误差进行各层神经元的权重和偏置,从而生成尿结石分析结果和尿结石患病概率的步骤,包括:
根据反向传播算法计算出每个神经元对误差的贡献度值,进而得到误差梯度,其中,误差梯度为神经网络模型输出对于各个所述子数据向量的权重和偏置的变化量;
根据所述误差梯度和学习率,调整各个所述子数据向量的权重和偏置的值以输出尿结石分析结果和尿结石患病概率。
具体的,所述匹配所述子数据向量与预设数据库中的若干相近向量,以生成若干相近向量中的验算概率值,并将尿结石患病概率与验算概率值进行评估获得误差的步骤,包括:
预设数据库中的若干相近向量为历史数据,所述历史数据包括若干相近向量所对应的以往患者实际患病情况,取所述若干相近向量的实际患病均值作为验算概率值。
在一个实施例中,所述采用液相色谱-质谱联用法对所述尿液样本进行高效液相色谱柱物质分离,生成第一样本数据的步骤,包括:
对尿液样本中的代谢物进行提取和纯化,将纯化后的代谢物用液相色谱-质谱联用法进行检测和定量,获取代谢物的种类和含量。
进一步地所述利用马尔可夫模型对所述待分析数据进行特征确定的统计过程的步骤,包括:
根据尿液样本中的各种代谢物的含量和种类,用马尔可夫模型构建代谢网络,对代谢网络进行统计分析,对每种代谢物的含量进行归一化,确定尿结石风险的影响特征。
进一步地所述将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率的步骤,包括:
在神经网络预测模型中,输入尿液样本的代谢组数据,并结合代表尿结石风险的影响特征,对尿结石风险进行预测,并输出预测结果。
通过这种方式,"基于尿液代谢组数据的尿结石风险预测方法"更明确地包含了"代谢"组分的相关信息。
参考附图2为本发明提出的一种基于尿液代谢组数据的尿结石风险预测系统结构框图,包括:
获取单元1,用于采用质谱分析法对尿液样本中的代谢物进行检测和定量,并获取对应的原始数据;
预处理单元2,用于对所述原始数据进行滤波、差值、归一化以及去除离群点的第一次数据处理以生成待分析数据;
统计单元3,用于利用马尔可夫模型对所述待分析数据进行特征确定的统计过程,并根据支持向量机对统计后的各个所述待分析数据中的子数据进行向量设置和个体建模,其中,所述子数据通过马尔可夫模型的特征确定进行标记;
预测单元4,用于将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率;
输出单元5,用于将所述个体建模图、尿结石分析结果和尿结石患病概率作为预测结果进行输出。
综上所述,本发明提出一种基于尿液代谢组数据的尿结石风险预测方法,包括:采用质谱分析法对尿液样本中的代谢物进行检测和定量,并获取对应的原始数据;对所述原始数据进行滤波、差值、归一化以及去除离群点的第一次数据处理以生成待分析数据;利用马尔可夫模型对所述待分析数据进行特征确定的统计过程,并根据支持向量机对统计后的各个所述待分析数据中的子数据进行向量设置和个体建模,其中,所述子数据通过马尔可夫模型的特征确定进行标记;将确定的子数据向量、个体建模和各个所述子数据导入至神经网络预测模型中,并采集所述神经网络预测模型经过处理后输出的个体建模图、尿结石分析结果和尿结石患病概率;将所述个体建模图、尿结石分析结果和尿结石患病概率作为预测结果进行输出。以通过机器学习方法,对大量的尿液代谢组数据进行训练,并构建出一个高效的分类模型或预测模型,以便在未来的样本中快速而准确地识别和预测尿结石的发生。同时,通过该技术还能够深入挖掘和解释代谢组数据中的关键特征和变化,从而更好地理解尿结石形成的机制和规律。此外,该技术还能够实现个体差异的自适应调整和优化,提高尿液代谢组数据分析的准确性和稳定性。
当然,本发明还可有其它多种实施方式,基于本实施方式,本领域的普通技术人员在没有做出任何创造性劳动的前提下所获得其他实施方式,都属于本发明所保护的范围。
- 一种基于神经网络的经营数据预测方法、可读存储介质和预测系统
- 一种基于排气扇操作数据的行为预测及控制方法、系统
- 一种基于机器学习和代谢组学预测泌尿结石的系统
- 基于代谢组学数据的自杀倾向与自杀行为预测方法及系统