一种压力驱动供水管网水力建模方法及应用
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及一种水力建模方法,具体涉及一种压力驱动供水管网水力建模方法。
背景技术
城市供水管网的管段摩阻系数以及节点高程参数是影响管网模型准确性的主要因素,其中,节点高程的准确性对于管网模型的精确度而言影响较大。传统的管网水力建模通过需水量驱动,较注重管网摩阻系数的率定。由于供水管网管段埋于地下,实测节点高程较为困难,导致管网水力建模先天不足。另外,传统管网水力建模及校验需要人工调整,复杂度高且工作量大,需要耗费大量的人力物力。
文献[1]和文献[2]中提出的供水管网建模方法均采用遗传算法对管网摩阻系数进行率定,文献[3]采用蚁群算法对管网摩阻系数进行率定,通过多工况数据校准,来提高最终模型的准确性。这些方法在供水管网水力建模方面有着一定的应用。然而,这些方法往往忽略了节点高程对于模型准确性的重要影响,且校核过程仅选取部分压力测点。在实际水力建模中,忽略高程因素可能导致模型的不准确性,进而影响模拟结果的可信度。
文献[4]提出了一种两步率定法,通过对节点高程和管网摩阻系数灵敏度高低的分析,采用首先对管网节点高程进行率定,然后再对管段摩阻进行率定的方法。然而,文献[4]方法仍采用需水量驱动,并未利用密集的压力测点数据,这在一定程度上降低水力模型的准确性。
相对于传统的需水量驱动方法,压力驱动方法在模型建立和优化过程中,能够更准确地考虑供水管网中水流的变化情况。随着水司SCADA系统的不断建设,首先通过远传大表采集了更多的单位/小区用水量数据。其次,通过密集的智能消防栓采集了管网众多节点的压力数据,这种实时数据为压力驱动水力系统建模的精确性和实用性提供了有力支持。故在物联网基础上开展充分利用压力测点数据的供水管网水力建模方法,对管网的节点高程与管段摩阻系数都进行率定,可以克服传统管网水力建模忽略高程导致模型不准确问题,实现供水管网快速水力建模及校验。
参考文献:
[1]信昆仑,程声通,刘遂庆.实数型编码遗传算法校核管道摩阻系数[J].中国给水排水,2004,20(9):3.DOI:10.3321/j.issn:1000-4602.2004.09.021.
[2]卓敏.给水管网管道摩阻的灵敏度分析及其校正研究[D].浙江大学,2005.
[3]张土乔,许刚,吕谋等.给水管网管道摩阻校正方法研究[J].浙江大学学报(工学版),2006(07):1201-1205.
[4]司伟超.JS输水管网水力建模及应用[D].杭州电子科技大学,2023.
发明内容
针对现有技术的不足,本发明提出了一种压力驱动供水管网水力建模方法,利用密布压力测点数据和海曾威廉公式,分步率定节点高程与管段摩阻系数,实现供水管网的快速水力建模及校验。
本发明提供了一种压力驱动供水管网水力建模方法,该方法包括以下步骤:
步骤1,获取管网静态结构和动态运行数据
步骤2,数据预处理,筛选符合常规流向的工况
根据管段管径确定两端节点埋深范围;
对压力数据进行去毛刺处理,并对少量缺项数据采用线性插值的方法进行预处理;
对压力数据采用卡尔曼滤波进行降噪;
对降噪后的压力数据,依据判定条件,确定管网水流的常规流向;
步骤3,管网节点高程率定
管网节点高程e作为优化变量,确定优化变量e的约束范围,给出优化目标为:
其中n为节点总数;m为工况总数;Q
采用遗传算法进行寻优;
步骤4,管段摩阻系数率定
管段摩阻系数C作为优化变量,确定优化变量C的约束范围,采用步骤3中相同的优化目标以及相同的遗传算法进行寻优;
步骤5,水力模型校验,包括校验各压力监测点水压与实测记录的吻合程度和各流量监测点流量与实测记录的吻合程度。
本发明还提供了一种上述所建立模型在管网水力演算中的应用。
本发明充分利用密集智能消防栓大量压力测点数据,并考虑节点高程因素,采用卡尔曼滤波对压力数据降噪、常规流向筛选率定用工况等策略,消除测量噪声干扰,实现基于压力驱动方法的供水管网水力建模,提高了水力模型的准确性和可靠性。
本发明相较于传统方法,所建立的管网水力模型具有更高的精度和可靠性,能够更好地支撑安全生产和管理决策。同时,利用物联网采集的实时数据,快速建立和更新水力模型,更符合实际需要。
附图说明
图1为本发明方法流程图;
图2为实例管网结构图。
具体实施方式
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅仅用以解释本发明,而不是为了限制本发明的范围及其应用。
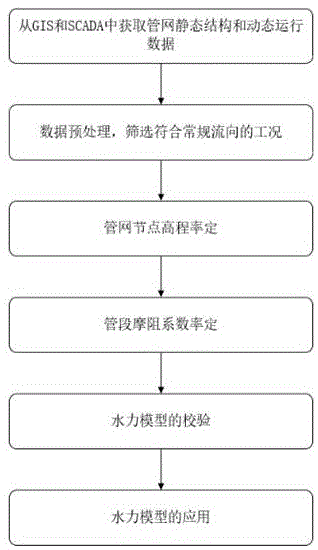
如图1所示,本申请实施例公开了一种压力驱动供水管网水力建模方法,包括以下步骤:
步骤1,从GIS和SCADA中获取管网静态结构和动态运行数据
通过GIS获得管网结构及节点位置及其地面高程h、管道连接信息。
通过智能消防栓获得密集压力测点数据P,通过远传大表获得需水节点用水量数据Q
例如:
通过GIS获得管网结构、节点位置及其地面高程h、管道连接信息,管网静态结构如图2所示,由20个节点、33个管段、1个水厂水池和1个水塔组成,管径从DN200-DN800,其中管网管长、管径数据如表1所示,管网节点的地面高程如表2所示。
表1管网管长管径数据,单位m
表2压力测点地面高程,单位m
从SCADA中获得管网动态运行数据,主要包括出厂流量/压力,通过智能消防栓获得密集压力测点数据P,以及通过远传大表获得需水节点用水量数据Q
表3出厂流量,单位LPS
表4出厂压力,单位m
表5密集压力测点数据,单位m
表6需水节点用水量数据,单位LPS
步骤2,数据预处理,筛选符合常规流向的工况
根据管段管径确定两端节点埋深范围,例如埋深范围[0,1m]。
对压力数据进行去毛刺处理,并对少量缺项数据采用线性插值的方法进行预处理。
表7预处理后的密集压力测点数据,单位m
在某一实施例中,需水节点的用水量缺项数据,采用线性插值或根据历史用水量数据进行估计。水量估计方法为根据前一周该时刻的均值作为未知需水量值。
式(1)中,Q为未知需水量,q
表8预处理后的需水节点用水量数据,单位LPS
原理上管段中水流方向由管段两端的节点水头H决定,节点水头H的计算公式如式(2)所示。
H
式(2)中,H
由于测量误差的存在,会逆转管网中个别管段的水流方向,造成与实际不符,从而影响参数率定。为减少这种不利影响,须对密集测点的压力数据进行降噪,并筛选出符合常规流向的工况用于参数率定。
由式(2)可知,智能消防栓采集的密集压力测点数据以及率定优化的节点高程都会对节点水头H产生影响。对于智能消防栓采集到的水压数据,首先需要降噪处理,从原始信号中分离提取出有用信号,减少噪声干扰。本实施例采用卡尔曼滤波方法对智能消防栓采集的压力数据进行降噪。具体地:
在卡尔曼滤波方法中,估计的状态x为压力测点数据,t时刻从t-1时刻的更新状态由以下步骤而来:
(1)根据系统模型和先前t-1时刻的状态估计,通过状态转移方程预测当前时刻t的状态。
式(3)中,
E
式(4)中,E
(2)利用测量值与预测状态之间的误差,通过式(5)计算最优卡尔曼增益,然后通过式(6)将预测状态与测量值之间的差异乘以最优卡尔曼增益,得到修正后的状态估计并通过式(7)更新协方差矩阵,减小状态估计的不确定性。
K
P
式(6)及式(7)中,
本步骤采用卡尔曼滤波方法对智能消防栓采集的压力数据进行降噪结果如表9。
表9卡尔曼滤波后压力数据,单位m
进一步,对降噪后的压力数据,根据如下条件,确定管网水流的常规流向:
(1)在分支管段的末端管道需水流流向支管末端,即支管末端节点水头需小于与其连接的上游节点水头。
(2)供水管网中的水流须顺着大直径的主管段的流向小直径的分支管段,即主管段节点水头需大于与其连接的分支管道节点水头。如果出现反常,在连续1周以上的运行中,95%以上工况符合此流向,则可以确定此流向为常规流向。
筛选用于参数率定的工况时,当不符合常规流向(即逆向水流)的管段数量超过总管段数量的5%时,剔除该工况,以确保参数率定的准确性。
步骤3,管网节点高程率定
管网节点高程e作为优化变量。由于节点管段的埋深受到合理范围[l1,l2]的限制,因此优化变量e的约束范围为[e1,e2]。其中,e1=h-l1,e2=h-l2,h为节点地面高程。约束范围保证了在进行高程率定时,优化变量e的取值不会超出管段埋深的合理范围,从而确保优化结果的真实性和可靠性。
表10优化变量e约束区间,单位m
在“管网节点高程率定”优化命题中,优化目标为:
式(8)中,n为节点总数;m为工况总数;Q
在本申请中,节点有两类,一类是需水节点,另一类是非需水节点;根据质量守恒定律,在工况k下有:
式(9)中,Q
若节点为需水节点,可根据式(9)可以计算节点i在工况k下的净流量值Q
若节点为非需水节点,则没有用水量(即Q
显然,式(9)、(10)原本是约束函数,已被式(8)的目标函数所包含。
在一具体实施过程中,式(9)中工况k下的管段流量q
式(11)式(12)中,H为包含高程位能的节点水头,单位m;q
式(11)(12)中节点i在k工况下的水头H
由上所述,构成了搜寻节点高程e的优化命题。接下来,结合遗传算法,描述寻优过程。
结合遗传算法的寻优过程主要包括以下步骤:
S3.1初始化种群:设置单个染色体长度为待率定节点高程数量a,是优化变量e合理约束范围内的十进制数。设置初始种群数量为100,单个染色体长度为a。
S3.2交叉:种群交叉方式为模拟二进制交叉SBX,假设两个附带个体
其中β是按照下述公式动态随机决定:
式中,eta代表变异分布参数,该值越大则产生的后代个体逼近父代的概率越大。
S3.3变异:对种群中每条染色体,确定变异位置,根据变异概率确定是否变异,每条染色体变异运算后得到新种群对应的一条染色体。
S3.4适应度函数计算:单个染色体X(x
S3.5选择:根据S3.4计算得到的种群中每条染色体的适应度值计算种群中每条染色体的选择概率。
S3.6优化结果:对种群做S3.2到S3.5的运算,如此迭代G次。
结合遗传算法GA,得到优化结果,由表11所示。
表11高程率定值,单位m
步骤4,管段摩阻系数率定
管段摩阻系数C作为优化变量。其中,优化变量C的取值范围受到约束,限制在经验值区间[90,150]的范围内,以确保优化结果的真实合理性。
在“管段摩阻系数率定”优化命题中,优化目标及约束函数均结合步骤3相同公式,其中式(11)、(12)中的摩阻系数C即为本步骤的优化变量,式(2)中e
结合遗传算法的寻优过程与步骤3类似,主要步骤如下:
S4.1初始化种群:设置单个染色体长度为待率定管段摩阻系数数量为f个,是优化范围为[90,150]的十进制数。设置初始种群数量为100个,单个染色体长度为f。
S4.2交叉:种群交叉方式为模拟二进制交叉SBX,假设两个附带个体
其中β是按照下述公式动态随机决定:
式中,eta代表变异分布参数,该值越大则产生的后代个体逼近父代的概率越大。
S4.3变异:对种群中每条染色体,确定变异位置,根据变异概率确定是否变异,每条染色体变异运算后得到新种群对应的一条染色体。
S4.4适应度函数计算:单个染色体X(x
S4.5选择:根据S4.4计算得到的种群中每条染色体的适应度值计算种群中每条染色体的选择概率。
S4.6优化结果:对种群做S4.2到S4.5的运算,如此迭代G次。
结合遗传算法GA寻优,得到优化结果,由表12所示。
表12管段摩阻率定值
步骤5,水力模型的校验
供水管网水力模型在用于现状分析、改扩建规划及优化调度等之前,必须确保其在一定精度范围内与实际管网运行状态相吻合。
其中,供水管网水力模型的校验步骤如下:
S5.1由步骤3和步骤4所得到优化节点高程和管段摩阻系数,置入管网EPAnet中。
S5.2按照需水量驱动,将远程大表用水量数据作为模型需水量输入,模拟演算管网的水力状态,对照实际运行数据。
S5.3计算各压力监测点水压与实测记录的吻合程度,需满足如下水力模型校验要求:100%监测点的压力实测值与计算值之差≤±40kPa;80%监测点的压力实测值与计算值之差≤±20kPa;50%监测点的压力实测值与计算值之差≤±10kPa。
S5.4计算各流量监测点流量与实测记录的吻合程度,需满足如下水力模型校验要求:对于管段流量占管网总供水量的l%以上的管段,误差<±5%;对于管段流量占管网总供水量的0.5%以上的管段,误差<±10%。
若步骤S5.3或步骤S5.4未满足水力模型校验要求,则再次执行步骤1至步骤4。若满足,则通过水力模型校验,转入步骤6。
表13监测点的压力实测值与计算值之差占比
表14流量监测点流量与实测记录的吻合程度
本申请实施例还提供了一种水力模型的应用,在水力模型建立并校验后,投入使用(即在管网EPANet中,置入率定的节点高程、摩阻系数)。使用时,仍按照需水量驱动,将远程大表用水量数据作为模型需水量输入,模拟演算管网的水力状态,对照实际运行数据,以辅助生产调度、爆管侦测等。
当模拟结果与实际数据发生长时间偏差时,须考虑更新水力模型。即再次执行步骤1至步骤5。
本申请通过试算需水量驱动和压力驱动两种方法所建水力模型在监测点压力的模拟值与实测值之间的MAE、MAPE、MSE指标,来比较两种方法的精度,对比结果如表15所示。
表15两种建模方法建模精度指标
值得说明的是,传统的需水量驱动方法中,通过求解质量平衡方程式和海曾-威廉水头损失方程式来计算节点压力。该方法以满足节点需水量为主要目标,通过预设的需水量模式和时间步长来确定节点的用水量,并进一步分配管段水量和计算节点压力。然而,需水量驱动方法不保证管网中压力分布合理性,即使低压甚至负压也照样满足节点需水量,难以准确反映管网实际水力状态。相比之下,压力驱动方法基于管网中各个节点的实际压力进行流向、流量演算,能更准确地反映管网中节点压力、管段流量和用水量。物联网技术支撑的智能消防栓,密集分布在供水管网上,可以实时获取管网各个节点的压力数据,为压力驱动方法在供水管网高精度水力建模及应用提供了有力的支持。
- 一种基于大数据以最不利点压力优化供水管网压力的方法
- 一种基于供水管网GIS数据库的水力模型生成方法及系统
- 一种面向供水管网水力模型水量校核的压力监测点移动布置方法
- 一种高铁站供水管网在线水力模型的建立与应用方法