一种代码迁移过程中的跨库API推荐方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于软件智能化迁移领域,尤其是涉及一种代码迁移过程中的跨库API推荐方法。
背景技术
随着互联网技术的不断发展和信息化建设的进一步提升,各种软件的应用范围也日益扩大,在经济、教育、医疗、交通等领域都得到了广泛的应用和推广。这些软件不仅仅是简单的工具,更是催化剂,在改变人们工作和生活方式的同时,也深刻地影响着社会运行模式和产业格局。与此同时,软件需求量也大幅度增加,新的软件模式和开发模式不断涌现,其规模和数量正在以惊人的速度膨胀和扩增。不断涌现的软件已经成为推动数字经济发展的重要引擎。未来随着技术的不断进步和推广,软件将更加深入地融入到各个行业、领域中,为人们提供更加高效、智能、高品质的服务和体验,进一步促进社会的发展和进步。
代码迁移是将现有的软件系统或应用程序从一个平台或环境转移到另一个平台或环境的过程。在现代软件开发中,代码迁移是快速开发软件的重要途径之一。代码迁移可以实现软件组件的复用,降低软件开发和测试工作量,提高软件质量和可靠性。随着移动设备和云计算技术的普及,开发者需要将软件应用程序迁移到不同的平台上,以满足多样性的用户需求。代码迁移可以帮助开发者将现有代码库转移至目标平台上,从而加快应用程序的开发和部署速度。不仅如此,当企业收购或合并其他公司时,需要将新的代码库与现有代码库集成在一起,代码迁移可以帮助企业将新的代码库与现有代码库进行合并,并确保代码的功能完整性和稳定性。而且随着技术的进步和市场需求的变化,软件系统需要不断进行升级和更新,以满足日益增长的用户需求。代码迁移可以帮助开发者将现有代码库转移至新的开发环境中,实现软件系统的升级和扩展功能。总之,代码迁移是快速开发软件的重要途径,通过将现有代码库转移至目标平台上,可以提高软件开发效率、降低开发成本、提高软件质量和用户体验。
在代码迁移的过程中,跨库API推荐具有非常重要的意义。代码迁移的场景往往是熟悉某一开发编程语言的开发人员,需要往另一种他并不熟悉的编程语言或者编程框架上迁移。要顺利将代码迁移到新的编程语言或者编程框架中,实现原有的代码逻辑,重现原有代码功能,就需要开发人员对这两种软件库都非常熟悉。利用面向迁移的跨库API推荐方法,开发人员能够根据原有软件库的API,快速准确地找到目标软件库API,无需费时费力地学习新的API或者花费大量时间匹配功能相近的API,这可以大大提高迁移效率,使得迁移项目进度更快。而且面向迁移的跨库API推荐方法能够准确地匹配目标API,从而避免了手工匹配时可能出现的错误,降低迁移风险,确保系统在迁移后能够正常运行。
目前,多数的API推荐方法都是接受自然语言输入,推荐某一个软件库的API,并不适合代码迁移中涉及的两种或者两种以上软件库的场景,也不能推荐一种软件库到另一种软件库的映射。
发明内容
本发明提供了一种代码迁移过程中的跨库API推荐方法,能够结合多源信息,学习API深层的特征表示,从而为推荐任务提供更多有效信息,提高API推荐的效果。
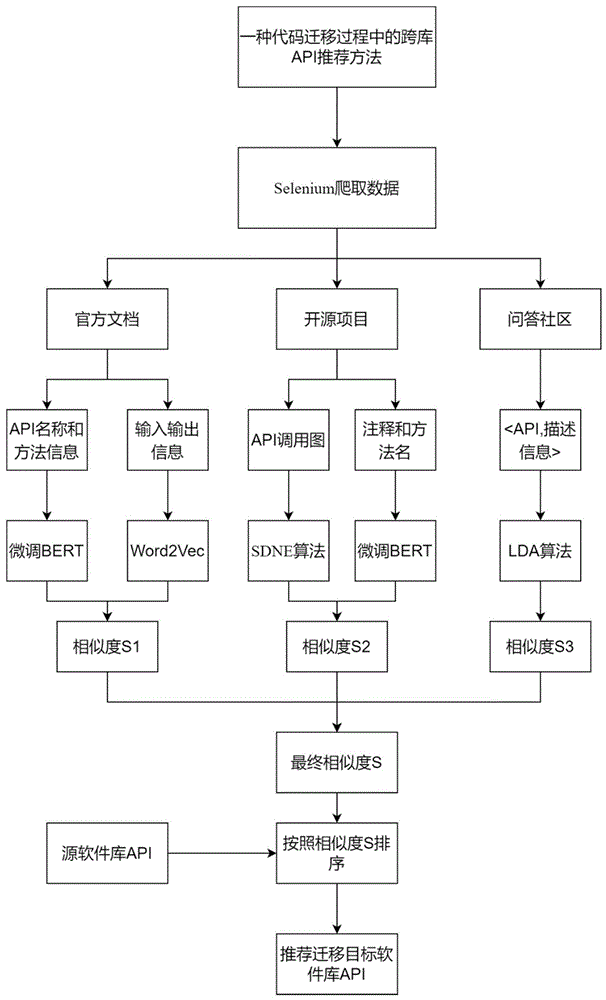
一种代码迁移过程中的跨库API推荐方法,包括以下步骤:
(1)利用爬虫框架爬取源软件库和迁移目标软件库的官方文档信息、开源项目以及问答社区数据,并对爬取到的信息进行加工处理,形成元数据;
(2)通过官方文档信息,将API的使用模式拆分成三个模块:API名称、方法信息、输入输出信息;通过三层微调的ALBERT模型对API名称和方法信息进行向量化,通过Word2Vec模型将输入输出信息进行向量化;
将源软件库和迁移目标软件库的API向量进行相似度计算,获得三个模块的相似度,最后对这三个相似度进行加权得到API文档相似度S1;
(3)通过开源项目,筛选出API的相关使用片段,构建API使用模式的图模型,再计算两个API图模型之间的图节点相似度;并根据代码片段的注释信息和方法名计算代码语义相似度,最后对图节点相似度和代码语义相似度进行加权得到API代码片段相似度S2;
(4)通过问答社区数据,得到API的相关问答描述,得到
(5)将相似度S1、S2、S3通过权重矩阵W,得到最终的API相似度S;
(6)输入源软件库的一个API,计算源软件库的API和迁移目标软件库中的每一个API的最终相似度S,并将所有API按S从大到小进行排序,进行推荐。
步骤(1)中,官方文档信息是指软件库的官方API使用文档,开源社区是指Github等包含源软件库和目标软件库的开源托管平台,问答社区是指StackOverflow等程序员专业领域社区;信息加工处理方式包括去除重复信息、清洗和过滤数据、提取关键词、格式化数据等。
步骤(1)具体包括:使用Selenium框架模拟浏览器行为,编写爬虫程序,自动打开官方文档网站,遍历两种软件库的文档页面,提取API接口、函数说明、示例代码等相关数据。采集半年内Github中所有的源软件库项目和目标软件库项目,并且根据星数对项目进行过滤,去除所有0星项目,然后从这些项目中筛选出其中的核心文件。爬取两种软件库在Stack Overflow上的相关问题和回答数据。通过搜索源软件库和迁移目标软件库中API的名称和相关标签,在问答社区进行检索并抓取相关问题和回答的内容。然后去除文本中的噪音和无关信息,例如HTML标签、特殊字符、标点符号、停用词等,并把所有单词转换为小写字母形式。
步骤(2)中,ALBERT模型BERT模型的微调过程如下:
首先利用步骤(1)中获得的问答社区数据对ALBERT进行预训练,采用动态MLM模型生成训练数据,并将所有数据复制十等份,每份数据采用不同的遮盖方法;
然后采用Softmax目标函数在SNLI数据集上对ALBERT模型进行微调,先将数据集问答对分别输入到模型中,采用平均池化操作得到两个句向量u和v;再将两个句向量拼接融合得到一个综合的向量表示,最后使用Softmax层对输入句子对的标注进行预测,目标函数如下
其中,|TD|表示样本的数量,y
最后采用余弦相似度损失作为训练损失函数在STS数据集进行微调;具体计算方法如下所示
其中,score
步骤(2)中,API文档相似度S1的计算公式如下:
其中,sim
步骤(3)中,构建API使用模式的图模型具体过程如下:
首先从步骤(1)中获得的开源项目中筛选出包含源软件库和目标软件库的项目,确定项目中包含的全部方法集合U、API节点集合I以及方法和API的关系边E,从方法起始编号开始,依次提取方法中涉及的API调用;然后判断该API是否存在,不存在则添加新的API节点编号到I中,否则从I中取出已存在的API节点编号;最后建立方法和API的关系边。例如方法u中提取了API i,那么u和i存在一条边,即e=(u,i),e∈E。
步骤(3)中,利用图模型得到API的调用图后,再利用SDNE算法进行图嵌入,用来计算两个API之间的图节点相似度;然后利用步骤(2)中微调后的ALBERT模型计算注释信息和方法名之间的代码语义相似度;
API代码片段相似度S2的计算公式如下:
S2=w
其中,sim
步骤(4)中,主题相似度S3的计算过程如下:
首先从问答社区数据中筛选出源软件库和目标软件库的问答对,首先对问答对进行文本处理,去除文本中的特殊字符、标点符号、HTML标签等噪音数据,将所有文本统一为小写或大写,去除停用词,如介词、冠词等在上下文中没有实际意义的词语,然后将其作为API的描述信息,构建
根据源软件库类数量t和迁移目标软件库中的类数量s,确定主题数量k=max{t,s};对于每一个数据对
步骤(5)中,权重矩阵为W=[w1,w2,w3]
步骤(6)中,将最终相似度S排名最高的前5个API推荐给开发人员,同时将API的官方文档信息和开源软件库中的代码片段作为附加信息提供给开发人员,以便开发人员能了解目标软件库API的使用方法,提高迁移效率。
与现有技术相比,本发明具有以下有益效果:
1、本发明能够根据两种软件库的API使用模式,在迁移过程中推荐相应的目标库API,提高代码迁移过程中的开发效率。
2、本发明能够结合多源信息,学习API深层的特征表示,从而为推荐任务提供更多有效信息,提高API推荐的效果。
3、本发明针对不同种类的API信息,采用不同的算法模型,再加以融合,能更加精确的捕捉到API的使用特点,提高目标软件库API的推荐准确度,从而提高代码迁移的效率。
附图说明
图1为本发明一种代码迁移过程中的跨库API推荐方法流程图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
本发明实施例的迁移场景为WPF迁移至Avalonia,WPF是微软公司推出的一种用于创建客户端应用程序的框架。它是在.NET Framework基础上开发的,提供了一套强大的工具和功能,用于构建现代化和高度可定制的用户界面。Avalonia是一个开源的跨平台UI框架,用于构建现代化的富客户端应用程序。它基于.NET平台,类似于WPF(WindowsPresentation Foundation),但与WPF不同的是,Avalonia不仅可以在Windows上运行,还可以在MacOS和Linux等其他操作系统上运行。
如图1所示,一种代码迁移过程中的跨库API推荐方法,包括以下步骤:
步骤1,使用Selenium框架模拟浏览器行为,通过自动化操作获取WPF和Avalonia软件库的官方文档信息。通过编写爬虫程序,自动打开官方文档网站,搜索或遍历目标软件库的文档页面,提取相关内容,如API接口、函数说明、示例代码等相关数据。采集2023年1月1日到2023年6月30日Github中所有的WPF项目和Avalonia项目,并且根据星数对项目进行过滤,去除了所有0星项目。从这些项目中筛选出其中的核心文件,这些文件都以“.cs”或者“.xaml”结尾。爬取目标软件库在Stack Overflow上的相关问题和回答数据。通过搜索目标软件库中API的名称和相关标签,在问答社区进行检索并抓取相关问题和回答的内容。去除文本中的噪音和无关信息,例如HTML标签、特殊字符、标点符号、停用词(常见但无实际意义的词语)等,并把所有单词转换为小写字母形式。
步骤2,使用问答社区数据对ALBERT进行预训练。本发明采用遮蔽语言模型进行预训练。训练时会将语料中每个句子的单词转化为对应的标记(token),按照一定的遮蔽率(mask rate)对句子的token进行随机遮盖,被选中的所有token以80%的几率被替换为[mask]标记,以10%的几率保持不变,以另外10%的几率替换为一个随机的token。本发明采用动态MLM模型生成训练数据,将所有数据复制十等份,每份数据采用不同的遮盖方法。在采用无标注的文本语料对模型进行预训练后,采用有标注的成对句子对模型进一步微调,可以获得深层次的句子级别的语义向量表示。
然后利用SNLI数据集进行微调。SNLI是由斯坦福大学提供的自然语言推理数据集,包含了570k条句子对以及它们之间的标签,可用于训练自然语言推理模型。本发明采用Softmax目标函数在SNLI数据集上对模型进行微调,首先将问答对分别输入到模型中,采用平均池化操作得到句向量u和v;然后将两个句向量拼接融合得到一个综合的向量表示,最后使用Softmax层对输入句子对的标注进行预测,目标函数如下:
最后采用STS数据集进行微调。STS是Cer等发布的用于评估模型在语义相似度计算任务上的性能的数据集。本发明采用余弦相似度损失作为训练损失函数,它是一种最小均方误差损失,具体计算方法如下所示,其中,score
将通过步骤1处理好之后的WPF和Avalonia官方文档信息进行进一步处理,对于每个API,将API的描述信息description和方法名称method单独提取出来,输入到步骤二中微调后的ALBERT中,得到描述信息的词嵌入向量u
其中,sim
步骤3,从WPF和Avalonia的开源项目中确定全部的方法集合U1和U2,以及WPF软件库和Avalonia软件库的API集合I1和I2。对U1和U2的每个方法进行编号,依次提取方法中设计的API调用,如果方法u中使用了API i,则添加一条边e=(u,i)。在得到API的调用图之后,利用SDNE算法进行图嵌入。SDEN算法是一种利用自编码器同时优化一阶和二阶相似度的图嵌入算法,学习得到的向量能够保留局部和全局的结构信息,得到API的图嵌入,用来计算两个API之间的相似度。
对于给定的图网络,定义向量
图网络的一些性质导致自动编码器不能够直接引用于图嵌入。因为网络的稀疏性,矩阵S中存在大量的0。如果使用传统的自动编码器,这些0元素更容易被重构,而非零元素则有很大可能被忽视。为此,需要修改损失函数中不同元素的权重:
其中,⊙表示点乘运算,图嵌入算法不仅要保持网络的全局结构,还需要捕获局部网络结构,即一阶相似性。对此可以使用监督学习的方法,其损失函数定义如下:
使用L2正则项
图嵌入可以将图中的节点映射到低维向量空间中,使得节点在向量空间中可以被表示为连续的数值向量。这样做的好处是可以捕捉API节点之间的相似性和关系。将WPF和Avalonia的API输入到模型中就可以得到API的图嵌入向量,然后计算其余弦相似度。然后利用步骤2中微调后的ALBERT算法计算注释信息和方法名之间的语义相似度,最后对这两个相似度进行加权得到S2
S2=w
其中,sim
步骤4,将文本预处理后的问答对构建成
步骤5,利用步骤2-4得到的三个相似度构建相似度特征向量v=[S1,S2,S3],权重矩阵为W=[w1,w2,w3]T,其中w1、w2、w3的值由训练集训练得到,本发明设置为0.4、0.3、0.3。将相似度矩阵[S1,S2,S3]与权重矩阵相乘得到最终API相似度S。计算公式如下:
S=V·W
步骤6,开发人员输入WPF中的API,模型计算该API和Avalonia中所有API的最终相似度S,然后将相似度从高到底排序,本专利将相似度排名前5的API作为候选API推荐给开发人员。同时将步骤1中采集的相关API描述信息和代码块作为附加信息返回,以便开发人员能够对Avalonia中的API使用更加了解,有助于迁移工作的进行。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 一种BI系统多源数据库跨源跨库融合系统和融合方法
- 一种基于迁移学习的API辅助代码概要生成方法
- 一种基于Tree-LSTM的API使用代码生成式推荐方法