一种基于时空Transformer的人体姿态估计方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及视频处理领域,特别是涉及一种基于时空Transformer的人体姿态估计方法。
背景技术
人体姿势估计任务是从图像或视频中检测所有的实例并估计出运动关键点的位置信息。它是计算机视觉领域的一项基本任务,具有广泛的应用,包括运动识别,人体重建,人体运动预测和人机交互等。
大多数早期的人体姿态估计方法主要从静态图像中估计人体姿态,采用概率图形模型或树状模型来模拟人体结构。然而这些方法需要对大量的特征进行人工标注,并且难以处理复杂背景所带来的挑战。随着深度学习技术的发展,研究人员利用深度卷积神经网络来解决姿势估计任务。Deep Pose通过迭代架构来估计关键点的坐标信息,直接获得最终结果。由于静态的人体图像可能存在模糊和遮挡,这会导致部分图像的信息损失。因此,将此类方法直接应用于视频任务,所表现出的泛化能力较差,估计出的关键点位置的准确率较低,并常表现出时间上的不连续性。
在监控跟踪和人类行为理解等实际场景中,需要模型具备从视频数据中精确估计人类的能力。因此,如何有效地利用视频中所包含的时间信息来提升人体估计精度是亟待解决的问题。最近,研究人员通过融合相邻帧所包含的相关时间上下文信息对目标图像的缺失部分进行补充,以提高基于视频的人体估计模型的性能。比如,基于长短期记忆网络(LPM)的链式网络结构模型。此外,基于卷积-循环神经网络的方法可以从视频中提取时间和空间特征,辅助模型输出更为准确的估计结果。尽管如此,此类模型过于关注人体的局部特征,难以从全局的角度充分理解人体姿态信息。目前,基于Transformer的图像识别模型具有构建全局关系的能力,并表现出良好的性能,研究人员提出将其用于处理姿态估计问题。
基于Transformer的模型在通过在每个Patch之间建立语义关系而表现出良好的长距离信息的关联建模能力,可以对人类姿态实现较好的全局信息理解。然而,现有的方法倾向于直接从短视频序列中聚合相邻帧的时间特征,导致模型过多关注于全局特征。使全局特征与目标帧特征的空间相似性未被合理的建模,并且每帧信息都被平等的处理,未对密切相关特征进行额外的关注,造成目标信息的削弱。此外,当前最先进的算法仅采用深度网络所捕捉的深度语义特征图进行学习,而忽略了对浅层特征图中所隐含的细节信息的提取,导致部分关键特征被丢失。
发明内容
本发明目的是在于提供一种基于时空Transformer的人体姿态估计方法,能够更加有效的利用视频中的局部和全局信息提高模型对人体关键点估计的精度,辅助研究人员更为准确的分析人体运动。
本发明的目的通过如下技术方案实现:
一种基于时空Transformer的人体姿态估计方法,包括以下步骤:
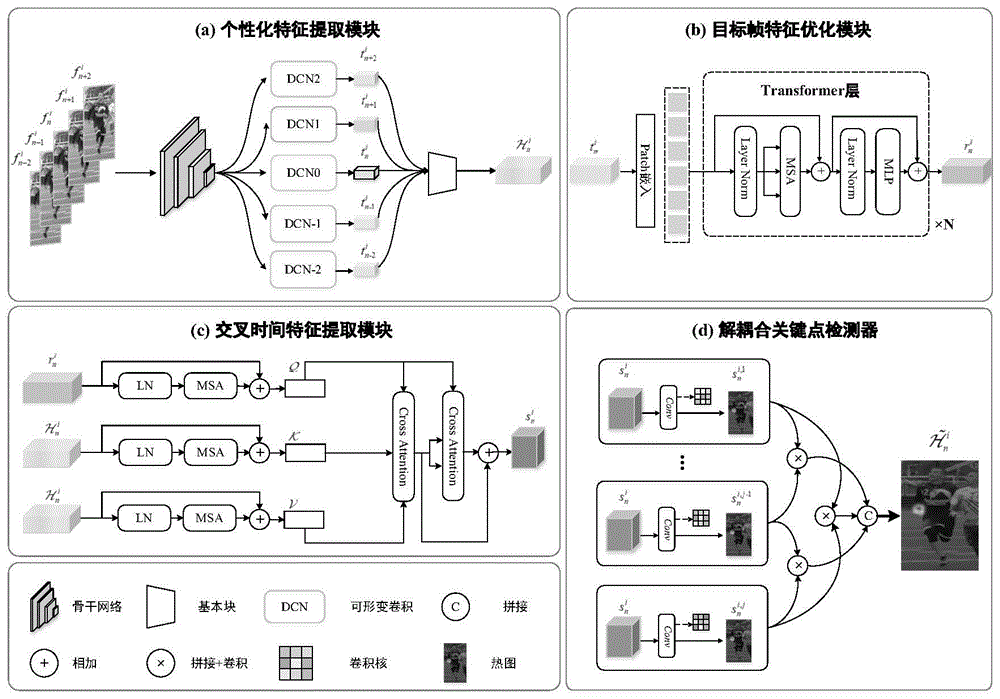
步骤一:将多帧连续的原始人体姿态视频帧输入改进的个性化特征捕捉模块获得相应的特征图;
步骤二:将获取的每帧个性化特征通过基本块聚合成浅层全局特征;
步骤三:采用基于Transformer的目标帧特征优化模块从目标帧捕捉局部优化特征;
步骤四:对步骤二和步骤三获取的浅层全局特征和局部优化特征输入交叉时间特征提取模块的多头自注意力机制分别进行多尺度特征提取与融合生成键矩阵、值矩阵和查询矩阵;
步骤五:将步骤四所编码的特征分别作为键矩阵、值矩阵和查询矩阵输入多层交叉注意力层生成深层全局特征;
步骤六:将步骤五所获取的深层全局特征输入解耦合关键点检测器,使用一系列并行的卷积网络分别提取每个关键点的信息;
步骤七:将步骤六中获取的每个关键点信息按照人体铰接关系进行拼接和建模以模拟人体结构信息,并经卷积操作后拼接成包含所有关键点信息的热图。
进一步的,步骤一中所述的个性化特征捕捉模块,公式如下:
其中,
进一步的,步骤二包括:通过基本块将个性化特征捕捉模块所提取的特征序列进行融合,形成包含局部序列信息的时空特征,具体操作如下:
其中,
进一步的,步骤三所述的基于Transformer的目标帧特征优化模块,首先将目标帧特征图分为N个Patch,然后再将其输入多头注意力机制层,最后将特征输入标准化层和多层感知器生成捕捉局部优化特征,具体操作如下:
目标帧特征图
其中,
进一步的,步骤四所述的捕捉浅层全局特征和局部优化特征来更好的适应时间相关特征的提取,来解决大多现有方法仅可关注浅层全局特征或局部优化特征的缺陷,公式化为:
其中,
进一步的,为了更为有效的从全局特征中查找与局部特征最为相关的信息,在步骤五中通过交叉注意力机制从局部特征中得到全局特征上的投影,增强了模型的表示能力,具体操作如下:
其中,softmax(·)表示激活函数,d是矩阵的维度。
进一步的,为了减少不同关键点运动特征为模型准确估计带来的干扰,采用一种解耦合的关键点检测器,通过并行的卷积网络针对每个关键点的特点分别提取信息,具体操作如下:
其中,
进一步的,为了模拟人体的实际结构辅助模型更为准确理解人体信息,首先根据人体关键点铰接关系进行特征建模,然后使用卷积神经网络完整信息提取并拼接成包含所有关键点信息的热图,具体操作如下:
其中,⊙表示拼接操作,
本发明的有益效果:
本发明提供了一种有效的用于解决人体姿态估计任务的时空特征学习Transformer框架。通过提出一个个性化的特征提取模块,利用视频序列中每帧中人体的个体特征来适应人体外形的复杂性和可变性。目标帧特征优化模块对目标帧中的人体空间信息进行编码,对局部相关语义信息进行细粒度提取。为解决现有方法在局部序列中捕获时空特征时,平等对待序列中每帧的信息,导致目标帧信息被弱化的问题,设计交叉时间特征提取模块,通过从局部序列的时空特征中挖掘与目标帧密切相关的线索来强化局部特征。此外,解耦合关键点检测器通过对铰接关节对进行建模,再提取每个关节的特征实现姿态估计。大量的实验证实,此发明可在两个大型的基准数据集中表现出较高的估计精度。
附图说明
图1为本发明所述的一种基于时空Transformer的人体姿态估计方法的整体框图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字后加以实施。
如图1所示,本发明通过将目标帧与相邻帧组成视频短片段,获取时空相关信息来训练深度学习模型,有效降低因目标帧部分信息缺少或丢失带来的负面影响。采用基于Transformer框架执行视频中的多人姿态估计任务,其中包括四个部分。1)首先通过目标检测器获取连续帧序列
实施例1
本发明的实施例1以PoseTrack2017数据集人体姿态估计为例,对视频中的人体关键点进行估计。首先,通过提取每帧的个性化特征,然后再聚合成全局特征的方式可以有效保留帧间特征的差异性。其次,通过对目标帧特征进行深层优化提取,获取细粒度的局部信息。再次,通过对局部信息和全局信息的交叉建模,有效捕捉与目标帧密切相关的综合特征。最后,针对不同关键点的特性进行解耦合估计,避免特征间的相互干扰。其步骤如下:
步骤101:逐帧获取个性化的人体姿态信息;
通过向个性化特征捕捉模块输入包含目标帧和邻近帧的视频短序列进行特征提取,其定义见下式所示:
其中,
为了使模型采集视频短序列中所包含的全局特征,使用基本块对获取的特征序列进行融合,操作公式如下:
其中,
步骤103:采用基于Transformer的目标帧特征优化模块优化局部特征;
将含有目标帧信息的局部信息作为自注意力机制的Q,K和V,分别是查询矩阵,键矩阵和值矩阵。以此对局部信息进行深层优化,具体操作如下:
MSA(Q,K,V)=Concat(head
其中,d
步骤104:对浅层全局特征和局部优化特征进行特征编码;
为了更好的捕捉与目标帧密切相关的全局特征,来更好的配合相关特征的准确提取,进而解决大多现有方法仅可关注浅层全局特征或局部优化特征的缺陷,分别将浅层全局特征和局部优化特征分别作为生成键矩阵、值矩阵或查询矩阵来提升模型对特征的捕捉能力,具体操作如下:
其中,
步骤105:采用交叉注意力模块编码深层全局特征;
为了更为有效的从全局特征中查找与局部特征最为相关的信息,在步骤五中通过交叉注意力机制从局部特征中得到全局特征上的投影,增强了模型的表示能力,具体操作如下:
其中,softmax(·)表示激活函数,d是矩阵的维度。
步骤106:解耦合关键点检测器获取关键点差异性特征;
为了减少不同关键点运动特征为模型准确估计带来干扰,采用解耦合的关键点检测器,通过并行的卷积网络针对每个关键点的特点分别提取信息,具体操作如下:
其中,
步骤107:模拟人体结构并估计出关键点;
为了强化模型对人体结构的理解能力,提升姿态估计的稳定性。将获取的每个关键点信息按照人体铰接关系进行拼接和建模以模拟人体结构信息,然后经卷积操作后拼接成包含所有关键点信息的热图。具体操作如下:
其中,⊙表示拼接操作,
本发明使用平均精度(AP)作为评价指标对不同算法的性能进行检验。另外,分别计算每个关键点的平均精度,并将所有关键点估计精度的平均值作为最终的平均AP(mAP)。
通过在PoseTrack2017验证集上测量模型得到的每个姿态的估计精度结果总结于表1。从结果分析中可以明显看出,本发明方法在Elbow,Wrist,Hip,Knee和Ankle等相对复杂关键点的姿态估计中取得了较好的检测精度。在与现有姿态估计算法PoseTracker、PoseFlow、JointFlow、FastPose、TML++、simple baseline(ResNet50)、simple baseline(ResNet152)、STEmbedding、HRNet、MDPN、Dynamic-GNN、PoseWarper、DCPose、IMAPose和GLPose的比较中发现,本发明的估计精度在7种重要关键点和平均精度方面显著高于上述算法。Wrist,Knee和Ankle等小尺度关键点的估计准确率分别比最先进的GLpose算法预高出1.8%、3.3%、2.2%。本发明提出的交叉特征提取模块极大提高了对遮挡部位和小尺度关键点具有重要辅助功能的特征信息提取,从而获得了较好的估计效果。
表1 PoseTrack2017数据集定量比较结构
实施例2
为了进一步评估算法的性能,使用PoseTrack2018验证集对模型性能进行检测。共采用10种方法进行了评价,包括STAF、AlphaPose、TML++、MDPN、PGPT、Dynamic-GNN、PoseWarper、DCPose、IMAPose、GLPose等。从表2的实验结果来看,人体姿态估计精度达到81.5mAP,超过了目前最先进的方法。值得一提的是,对于那些难以估计的具有挑战性的关节(例如,Wrist和Ankle),所提出的方法也获得了明显的提升,Wrist的估计精度为78.5AP比排名第二的方法高0.5AP,Ankle的估计精度74.4AP比之前最先进方法提升0.6AP。
表2PoseTrack2018数据集定量比较结构
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的实施例。
- 基于Transformer时空特征增强型的人体姿态估计方法
- 一种基于Transformer的人体姿态估计方法及系统