一种基于图像识别技术的跌倒检测方法和系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及图像识别技术领域,特别是涉及一种基于图像识别技术的跌倒检测的方法和系统。
背景技术
随着人口老龄化的加剧,年轻人比例减少,老人跌倒无法及时被发现和采取必要措施,已成为一个日益严重的问题。老年人一旦跌倒,可能会导致骨折、外伤等严重后果,如果不能被及时发现和送医,那么甚至会危及生命。因此,对于老年人来说,及时检测出跌倒并采取相应的措施非常重要。传统的跌倒检测技术通常基于传感器的方法和可穿戴设备的方法。但是,这些方法都需要特殊的硬件设施,容易忘记充电或佩戴,并且难以普及应用。
目前,已存在一些使用图像识别进行跌倒检测的方法,但通常仅使用普通的摄像头进行图像获取,因此存在无法在夜晚进行跌倒识别、部分人体被遮挡时无法识别等问题。并且,现有技术中使用的预测关键点较少,因此存在检测精确度较差等问题。另一方面,现有的一些检测技术中,未对图像中出现的不同人物进行区分,当多人出现在图像中时,还存在无法对每个人进行区分等问题。
鉴于此,如何克服现有技术所存在的缺陷,解决现有技术中某些场景中无法获取图像的现象和检测精度低的现象,是本技术领域待解决的问题。
发明内容
针对现有技术的以上缺陷或改进需求,本发明解决了现有技术中某些场景中无法获取图像的问题和检测精度低的问题。
本发明实施例采用如下技术方案:
第一方面,本发明提供了一种基于图像识别技术的跌倒检测方法,具体为:定义人物上用于判断姿态的关键点,根据关键点的位置关系获取至少一种跌倒行为的特征,其中,所述关键点包括:头部关键点、躯干关键点和脚部关键点;使用雷达成像图像对红外视频流进行增强,获取增强后的视频流中每个人物上关键点的坐标,分别根据每个人物上关键点的坐标匹配相应的跌倒行为的特征,根据匹配结果判断相应人物是否跌倒。
优选的,所述头部关键点包括鼻子关键点和颈部关键点,所述躯干关键点包括中臀关键点,所述跌倒行为的特征具体包括:颈部关键点和中臀关键点之间向量的水平和垂直长度的比值大于第一参数,且身体宽高比大于第二参数,且至少一个脚部关键点和中臀关键点间向量的水平和垂直长度的比值大于第三参数;和/或,颈部关键点和中臀关键点间向量的水平和垂直长度的比值大于第一参数,且中臀关键点在至少一个脚部关键点的下方;和/或,鼻子关键点在至少一个脚部关键点的下方;和/或,颈部关键点在至少一个脚部关键点的下方。
优选的,所述关键点还包括:所述头部关键点还包括:右眼关键点、左眼关键点、右耳关键点和左耳关键点中的一种或多种;所述躯干关键点还包括:右肩关键点、右肘关键点、右手腕关键点、左肩关键点、左手肘关键点、左手腕关键点、右臀关键点、右膝盖关键点、左臀关键点和左膝盖关键点中的一种或多种;所述脚部关键点包括:右脚踝关键点、左脚踝关键点、左脚拇指关键点、左脚小指关键点、左脚跟关键点、右脚拇指关键点、右脚小指关键点和右脚跟关键点中的一种或多种。
优选的,所述身体宽高比具体包括:获取所有关键点的横坐标的最大值与横坐标的最小值的第一差值,获取所有关键点的纵坐标的最大值与纵坐标的最小值的第二差值,以第一差值和第二差值的比值作为身体宽高比。
优选的,所述使用雷达成像图像对红外视频流进行增强,具体包括:在红外视频流中抽取指定间隔帧数的图片,将抽取的图片与雷达成像图像进行叠加,基于叠加后的图片生成增强后的红外视频流。
优选的,所述获取增强后的视频流中每个人物上关键点的坐标,具体包括:对视频流中出现的每个运动物体进行目标跟踪,基于目标跟踪结果区分视频流中的每个人物,分别获取视频流中每个人物上关键点的坐标。
优选的,所述分别获取视频流中每个人物上关键点的坐标,还包括:判断指定帧数的连续帧图像是否都检测到同一人物,当连续帧图像都检测到同一人物后,获取所述人物在连续帧图像中每一帧中每个关键点的坐标。
优选的,所述分别根据每个人物上关键点的坐标匹配相应的跌倒行为的特征,根据匹配结果判断相应人物是否跌倒,具体包括:将每个人物上关键点的坐标分别与每种跌倒行为的特征相匹配,当一个或多个人物上关键点的坐标的位置关系与一种或多种跌倒行为的特征匹配时,判定所述一个或多个人物跌倒。
另一方面,本发明提供了一种基于图像识别技术的跌倒检测系统,具体为:包括图像采集设备和图像处理设备,具体的:所述图像采集设备用户获取待检测的增强后的视频流;所述图像处理设备用于根据第一方面中所述的基于图像识别技术的跌倒检测方法对增强后的视频流进行跌倒检测。
优选的,所述图像采集设备包括红外摄像头和成像雷达,具体的:所述红外摄像头用户获取红外视频流;所述成像雷达用户获取雷达成像图像。
与现有技术相比,本发明实施例的有益效果在于:使用雷达成像图像对红外视频流进行增强,避免了夜晚和遮挡情况下无法获取待检测图像的问题;使用25个关键点进行图像检测,根据不同的关键点特征区分不同的跌倒行为,并分别根据每个人物的关键点进行跌倒检测,提高了检测精度,避免了无法对多人进行跌倒检测的问题。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图作简单地介绍。显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为现有技术中姿态识别关键点示意图;
图2为本发明实施例提供的一种基于图像识别技术的跌倒检测方法流程图;
图3为本发明实施例使用的姿态识别关键点示意图;
图4为本发明实施例使用的一种跌倒行为的特征示意图;
图5为本发明实施例使用的另一种跌倒行为的特征示意图;
图6为本发明实施例使用的另一种跌倒行为的特征示意图;
图7为本发明实施例使用的另一种跌倒行为的特征示意图;
图8为本发明实施例提供的另一种基于图像识别技术的跌倒检测方法流程图;
图9为本发明实施例提供的另一种基于图像识别技术的跌倒检测方法流程图;
图10为本发明实施例提供的另一种基于图像识别技术的跌倒检测方法流程图;
图11为本发明实施例提供的另一种基于图像识别技术的跌倒检测方法流程图;
图12为本发明实施例提供的另一种基于图像识别技术的跌倒检测方法流程图;
图13为本发明实施例提供的一种基于图像识别技术的跌倒检测系统结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本发明是一种特定功能系统的体系结构,因此在具体实施例中主要说明各结构模组的功能逻辑关系,并不对具体软件和硬件实施方式做限定。
此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。下面就参考附图和实施例结合来详细说明本发明。
经过对现有技术的文献检索发现,在现有技术中,已存在一些使用图像识别进行跌倒检测的方法:
(1)基于关键点的跌倒检测方法,专利申请号202011026089.0。通过摄像头获取图像,然后使用目标检测的深度学习算法(Region Convolutional Neural Networks,简写为RCNN)框定图像中的人体,若人体宽高比大于设定的阈值,则判定摔倒,否则使用目标检测分隔算法(Mask RCNN)提取如图1所示的人体18个关键点,若关键点不全则用生成对抗网络补全,然后根据骨骼关键点的角度与距离判断是否跌倒。该方法在夜晚无光时无法检测到人体;并且,有多人在摄像头视野内时,无法区分每个人;并且,采用生成对抗网络补全的人体关键点可能与实际关键点位置相差很大,造成检测不准确。
(2)人体摔倒检测方法、装置、电子设备和存储介质,专利申请号202010660416.1。通过摄像头获取图像,然后获取人体髋部、颈部和膝盖部的关键点并将其间的相对位置关系作为人体关键点位置特征,获取人物形状特征,然后将特征分别输入分类器,得到跌倒检测结果,再综合分析得到的检测结果得到最终的跌倒检测结果。此方法未考虑夜晚无光时的情况,也未考虑部分人体被遮挡的情况,并且只考虑了三个关键点作为特征,将极限学习机作为分类器精度也比较低。
(3)基于时空信息的跌倒检测方法、系统、存储介质及设备,专利申请号202210536743.5。获取待检测目标在内的视频,使用yolo(全称为:you only look once)v3检测目标框,并使用多级姿态估计网络(multi-stage pose estimation network,简写为MSPN)得到每个人体检测框的如图1所示的18个关键点,使用滑动窗口将当前帧图像的人体骨骼关键点和前面连续的29帧图像的人体骨骼关键点划分为一组,将样本输入跌倒检测模型,得到待检测目标的跌倒检测结果。此方法未考虑夜晚无光时的情况,也未考虑部分人体被遮挡的情况,并且只考虑了18个关键点作为特征,而且如果先后有不同的人出现在视频中,或者视频中同时出现多人,也无法进行区分。
实施例1:
为了解决现有技术中的上述问题,本实施例提供了一种基于图像识别技术的跌倒检测方法,可以从已铺设的大量摄像设备或者安装家庭摄像头提取图像,结合后端算法分析来检测跌倒行为。
如图2所示,本发明实施例提供的基于图像识别技术的跌倒检测方法具体步骤如下。
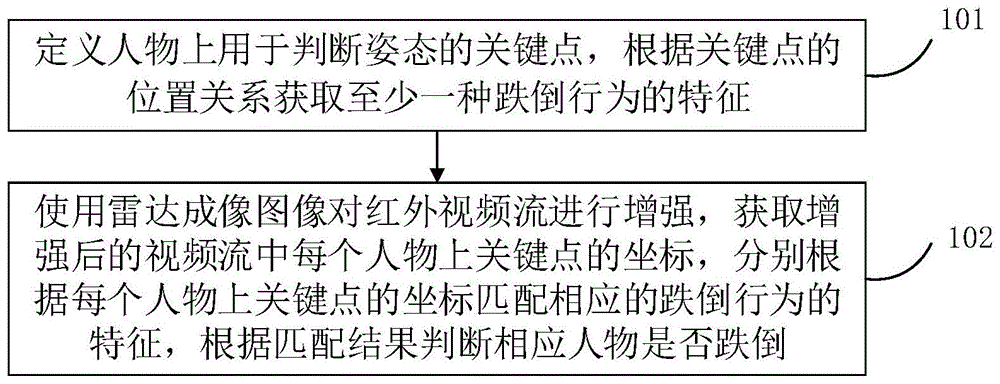
步骤101:定义人物上用于判断姿态的关键点,根据关键点的位置关系获取至少一种跌倒行为的特征。
为了提高跌倒检测的精度,与现有的技术中常见的18个关键点不同,本实施例提供的方法中,根据人物骨架的标准字体定义出25个关键点,并依次进行标记,以便后续作为跌倒判断的基准。如图3所示,标记出的关键点包括:头部关键点、躯干关键点和脚部关键点。其中,头部关键点包括以下关键点中的一种或多种:0鼻子关键点、1颈部关键点、15右眼关键点、16左眼关键点、17右耳关键点、18左耳关键点;躯干关键点包括以下关键点中的一种或多种:2右肩关键点、3右肘关键点、4右手腕关键点、5左肩关键点、6左手肘关键点、7左手腕关键点、8中臀关键点、9右臀关键点、10右膝盖关键点、12左臀关键点、13左膝盖关键点;脚部关键点包括以下关键点中的一种或多种:11右脚踝关键点、14左脚踝关键点、19左脚拇指关键点、20左脚小指关键点、21左脚跟关键点、22右脚拇指关键点、23右脚小指关键点、24右脚跟关键点。在实际实施中,为了提高检测的准确度,优选使用全部25个关键点进行计算,或使用包含所有脚部关键点的关键点集合进行计算。为了描述简便,下文中在无歧义的情况下,将上述关键点以部位名称进行简称,例如:将0鼻子关键点简称为0鼻子或鼻子。
由于人物在待检测图像中的拍摄角度不同,以及造成跌倒的原因不同,跌倒后在图像上呈现的姿态也不同;同时,当人物坐下、蹲下或躺下时,也会呈现与跌倒时相似的姿态特征。为了避免因角度和姿态不同导致的跌倒判定错误,本实施例中还需要对不同角度和姿态的跌倒图像特征进行分类,以通过相应特征定义不同角度和姿态下的跌倒行为,以便后续进行跌倒检测时进行相应关键点的检测计算。
步骤102:使用雷达成像图像对红外视频流进行增强,获取增强后的视频流中每个人物上关键点的坐标,分别根据每个人物上关键点的坐标匹配相应的跌倒行为的特征,根据匹配结果判断相应人物是否跌倒。
本实施例提供的方法中,为了避免光线不足或存在遮挡时造成的无法检测或检测不准确,本实施例提供的方法中,使用红外视频流作为图像识别的主要图像数据源,以便在光线不足的情况下获取需识别的人物图像。同时,使用雷达成像图像对红外视频流进行增强,以进一步增强弱光或无光环境中的图像识别能力,并通过雷达成像图片识别红外视频流图像中被遮挡的部分,以避免因遮挡造成的识别不准。
获取到待检测的视频流后,即可对视频流中每一帧图片上的人物姿态进行分析,获取步骤101中定义的25个关键点的实际坐标。再根据关键点的实际坐标计算不同关键点之间的位置关系特征,将位置关系特征与步骤101中获取到的跌倒行为的特征进行匹配,若能够匹配,则表明人物已跌倒。
经过本实施例中提供的步骤101-步骤102后,即可更准确的对各种环境、角度和姿态下的人物跌倒情况进行检测。
与现有技术中使用18个点的方案相比,本实施例提供的方法中,用于检测人体姿态的模型中使用了25个关键点。相对于现有技术,在躯干和腿部连接点增加了中臀关键点,通过颈部关键点和中臀关键点的连线对脊椎姿态进行抽象,通过左臀关键点、中臀关键点和右臀关键点的连线对盆骨姿态进行抽象,使得模型更符合人体的骨骼结构,腿部和躯干更易区分,且更易检测躯干的姿态;并在脚部增加了6个关键点,对左脚和右脚分别使用4个关键点进行建模,可以通过关键点的位置检测脚部姿态,避免了现有技术中左脚和右脚分别仅使用一个关键点导致的无法检测脚部姿态的问题。其优势在于:
(1)25个关键点识别能够更全面地捕捉到人体各个部位的细节,从而提高人体姿态估计的准确性。例如,对于一些特定的姿势,18个关键点的模型可能无法准确地捕捉到某些部位的姿态变化,而25个关键点的模型则能够更加准确地捕捉到这些部位的姿态变化;
(2)25个关键点识别能够更好地应对遮挡、噪声等复杂环境下的姿态估计问题。由于25个关键点模型对人体部位的划分更加细致,所以即使某些部位被遮挡或出现噪声干扰,该模型也能够通过其他部位的姿态信息来估算出这些部位的姿态;
(3)在跌倒场景中,25个关键点模型也能够更好地应对一些特殊的挑战,如人体的非刚体变形、不同视角下的姿态变化等,从而减少漏检的问题发生,提高了算法的检测精度。
进一步的,获取关键点和进行匹配时,为了便于与一般成像设备的坐标系相对应,实际实施中,如图3所示,各关键点的坐标系也使用图像的左上角作为坐标原点,X轴由原点起水平向右,Y轴由原点起竖直向下。进一步的,在实际实施中,由于遮挡等原因,可能出现关键点坐标的错误或不准确。因此,还可以计算每个关键点坐标的置信度,过滤掉置信度低于指定下限的关键点。另一方面,当神经网络识别异常时,或某一部位位于画面边缘时,相应关键点的横坐标或纵坐标可能为0,为了避免判断错误,横坐标或纵坐标为0的关键点也可以进行过滤。进行上述过滤后,或当遮挡较为严重时,可用于计算的关键点数量会减小,导致跌倒判断的准确性降低,因此,还需要判断剩余关键点数是否小于指定数量下限,若小于指定数量下限,则不进行跌倒判断。根据实际计算结果,能够确保准确度的指定数量下限可以设置为10。
实际实施中,可以根据人体姿态的标准数据、获取图像的角度、大数据分析结果等方式获取本实施例中需要使用的跌倒行为的特征。以下提供一些常见的跌倒行为类型相应的特征,实际实施中,可以参考以下类型划分方式,也可以根据实际需要基于25个关键点获取其它跌倒行为类型的特征。
(1)对应图4所示,颈部关键点和中臀关键点之间向量的水平和垂直长度的比值大于第一参数,且身体宽高比大于第二参数,且至少一个脚部关键点和中臀关键点间向量的水平和垂直长度的比值大于第三参数。
实际计算中,可以获取1颈部和8中臀之间的向量,判断该向量的水平和垂直长度的比值是否大于第一参数α。第一参数α的优选值为1.6至1.8,表示人物上半身中轴线与水平面的夹角小于30度。
即:
进一步的,可以获取所有关键点的横坐标的最大值与横坐标的最小值的第一差值,获取所有关键点的纵坐标的最大值与纵坐标的最小值的第二差值,以第一差值和第二差值的比值作为身体宽高比,判断宽高比是否大于第二参数β。
第二参数β的优选值为1,表示人物整体的中轴线与水平面的夹角小于45度。计算身体宽高比时,必须使用全部关键点,以避免因遗漏关键点而造成的计算结果错误。
即:
实际计算中,计算每个脚部关键点和8中臀间向量的水平和垂直长度的比值,判断是否存在任一个脚部关键点的比值大于第三参数γ。第三参数γ的优选值为0.5,表示人物腿部与水平面的夹角小于30度。
即:
(2)对应图5所示,颈部关键点和中臀关键点间向量的水平和垂直长度的比值大于第一参数,且中臀关键点在至少一个脚部关键点的下方。
实际计算中,可以获取人物颈部和中臀间向量的水平和垂直长度的比值,判断比值是否大于第一参数α,第一参数α的优选值为1.6至1.8。
即:
实际计算中,计算每个脚部关键点和8中臀关键点间向量的纵坐标大小,判断8中臀向量的纵坐标是否大于任一个脚部关键点的纵坐标。
即:y
(3)对应图6所示,鼻子关键点在脚部关键点的下方;
实际计算中,计算每个脚部关键点和0鼻子关键点间向量的纵坐标大小,判断0鼻子关键点向量的纵坐标是否大于任一个脚部关键点的纵坐标。
即:y
(4)对应图7所示,颈部关键点在至少一个脚部关键点的下方。
实际计算中,计算8中臀关键点和脚部关键点间向量的纵坐标大小,判断是否存在任一个脚部关键点向量的纵坐标大于8中臀关键点的纵坐标。
即:y
参照相应附图中的姿态,以及各参数值的实际意义,可见,使用上述特征可以对不同类型的跌倒行为进行检测判定。
本实施例提供的方法中,为了在各种光线条件和遮挡情况下都能较为准确的获取到待检测的图像,可以使用红外摄像头采集视频流,并结合雷达成像图像对人物被遮挡部分进行增强,再将增强后的视频流中的每一帧图像作为待检测的图像。具体的:在红外视频流中抽取指定间隔帧数的图片,将抽取的图片与雷达成像图像进行叠加,基于叠加后的图片生成增强后的红外视频流。
为了对待检测图像中的多个人物分别进行跌倒检测,可以对视频流中出现的每个运动物体进行目标跟踪,基于目标跟踪结果区分视频流中的每个人物,分别获取视频流中每个人物上关键点的坐标。具体的,可以使用目标跟踪算法,框选出视频流中出现的人并进行标号区分。如图8所示,可以通过以下方式完成人物的区分和标定
步骤201:使用目标跟踪算法对视频进行处理,框选并跟踪视频流内出现的人物。
实际实施中,可以根据需要通过图像特征分析方法或目标追踪算法对人物进行区分。例如:DeepSort算法、ByteTrack算法等。优选使用简单高效的ByteTrack算法。
步骤202:判断指定帧数的连续帧图像是否都检测到同一人物,当连续帧图像都检测到同一人物后,获取所述人物在连续帧图像中每一帧中每个关键点的坐标。
判断连续N帧图像内是否都检测到同一人物,是则对该人物进行姿态估计,N大于等于1。实际实施中,可以根据需要通过图像特征分析方法或人物姿态估计算法获取人物的关键点坐标。例如:使用openpose算法、DeepCut算法、AlphaPose算法、Mask RCNN等方法,估计出计算时需要使用的关键点。优选使用准确度和便捷性较高的openpose算法。
经过本实施例中提供的步骤201-步骤202后,即可获取到视频流中每个人物的关键点,进而完成跌倒检测。
获取到人物姿态的的关键点后,即可基于步骤101中跌倒行为的特征进行判定和检测。将每个人物上关键点的坐标分别与每种跌倒行为的特征相匹配,当一个或多个人物上关键点的坐标的位置关系与一种或多种跌倒行为的特征匹配时,判定所述一个或多个人物跌倒。
为了提升判定的准确度,减少正常躺下或者坐下的动作被误判为跌倒的情况发生,可以对跌倒的速度特征和时间特征进行辅助判断来规避此类误报问题。具体的:阶段一,由于跌倒是即时状态变化,其速度将远大于正常下蹲或躺下的速度,可以根据待测视频连续K帧图像的25个关键点的坐标信息,计算人体重心点P的运动速度V
在实际实施中,上述计算中的帧数和其它参数可以根据统计经验获取,也可以根据需检测的精度进行调整。在通常的检测场景中,可以参考以下具体数值进行设置:
(1)待测视频的图像帧数K应该大于等于1;
(2)通常跌倒行为发生时间一般在300至500ms之间,跌倒发生的重心位移在0.5到1m左右,因此本示例中运动速度阈值V可以被设置为2m/s,该值仅做参考,可根据实际项目进行调整;
(3)跌倒后正常人体反应时间为1s以上,一般监控视频流的1s有30帧图像,因此本示例中图像帧数W可以被设置为30,该值仅做参考,可根据实际项目进行调整。
进一步的,由于步骤101中获得的特征中包含了完全跌倒时的姿态(3)和(4),以及即将跌倒时的姿态(1)和(2)。因此,上述特征还可以用于进行跌倒状态的预测。连续多帧图像中,若人物姿态快速由正常站立姿态转换为即将跌倒时的姿态,即可在人物即将跌倒时对跌倒状态进行预测。
进一步的,也可以通过深度学习的方式完成上述关键点的获取和跌倒检测。在某个实际场景中,如图9所示,可以使用以下方式完成跌倒行为特征的提取。
步骤301:导入模型库,指定要预测的图像路径和使用的模型路径。
步骤302:通过训练模型解析出样本数据集中的人体骨架坐标,并定义跌倒行为的关键点。其中,关键点包括脚部关键点、躯干关键点和头部关键点。
步骤303:基于样本数据集分别获取每个行为关键点的关键点坐标列表。
步骤304:基于关键点坐标列表计算获取跌倒行为的关键点基准坐标。
步骤305:获取待测视频图像,基于关键点基准坐标和训练模型,预测待测视频图像中的跌倒行为。
经过本实施例中提供的步骤301-步骤305后,即可通过深度学习的方法获取待检测视频中的关键点,并对跌倒状态进行检测和预测。
本实施例提供的基于图像识别技术的跌倒检测方法具有以下有益效果:
1.本实施例提供的方法采用雷达成像和红外视频流结合的方式,实现了在夜间无光以及人物有被遮挡的情况下对人物视频的采集,解决了黑暗和有遮挡环境下无法对人物整体进行视频采集的问题;
2.本实施例提供的方法采用目标跟踪算法将视频内的人物进行区分,解决了当视频内有多人出现时判断人物是否跌倒时容易造成混淆的问题;
3.本实施例提供的方法采用了姿态估计算法识别25个人体关键点,比传统的18个关键点估计的结果更加准确。
4.本实施例提供的方法采用跌倒特征检测辅助进行判断,能有效避免正常躺下或坐下的行为被误判为跌倒的情况发生。
实施例2:
基于实施例1提供的基于图像识别技术的跌倒检测方法,本实施例中提供了一些步骤102中根据每个人物的关键点坐标匹配相应的跌倒行为的特征的具体方法。可以理解的是,本实施例提供的判断过程仅为实际实施场景中可参考的具体实施方法,并不作为本发明保护范围的限制。实际实施中,可以参考以下方式进行跌倒行为判断,也可以根据需要对以下方式进行调整。
本实施例提供的判断方式中,可以根据以下方式依次判断每个人物的每个关键点是否与跌倒行为的特征相匹配。当完成一个人的所有关键点的遍历判定后,即可根据匹配结果进行跌倒判定。
为了便于计算,本实施例中的计算方式都使用图像中获取到的关键点与相应基准关键点之间的向量作为计算数据,跌倒类型依照实施例1中的类型(1)-(4)进行匹配,且各参数都使用优选参数。
进一步的,为了便于进行依次匹配,可以将脚部关键点:11右脚踝、21左脚跟、19左脚拇指、29左脚小指、21左脚跟、22右脚拇指、23右脚小指、24右脚,按照序号顺序进行排列,并过滤掉置信度较低、横坐标为0或纵坐标为0的脚部关键点,将剩余脚部关键点中序号最小的脚部关键点作为比较对象。为了便于描述,以下将进行排序和过滤后序号最小的脚部关键点称为第一个脚部关键点。
进一步的,为了便于对不同类型的跌倒行为特征进行判断,本实施例中定义了判断标志量condition_A、condition_B、condition_C、condition_D、condition_E和condition_F。上述判断标志量的初始值都为False。
如图10-图12,为进行跌倒判断的具体方式。
步骤401:判断颈部和中臀的横坐标和纵坐标是否都不为0。若是,转步骤402;若否,转步骤406。
步骤402:判断颈部和中臀间向量的水平和垂直长度的比值是否大于1.6。若是,condition_A=True,转步骤403;若否,转步骤403。
步骤403:判断脚部关键点的个数是否为0。若是,转步骤404;若否,转步骤406。
步骤404:判断第一个脚部关键点和中臀间向量的水平和垂直长度的比值是否大于0.5。若是,condition_E=True,转步骤405;若否,转步骤405。
步骤405:判断是否中臀在脚部下方且condition_A=True,或者是否颈部在脚部下方。若是,condition_B=True,转步骤406;若否,转步骤406。
步骤406:判断鼻子和中臀的横坐标和纵坐标是否都不为0。若是,转步骤407;若否,转步骤411。
步骤407:判断鼻子和中臀向量的水平和垂直长度的比值是否大于1.6。若是,condition_A=True,转步骤408;若否,转步骤408。
步骤408:判断脚部的关键点个数是否不为0。若否,转步骤409;若是,转步骤411。
步骤409:判断不为0的第一个脚部关键点和中臀间向量的水平和垂直长度的比值大于第二参数。若是,condition_E=True,转步骤410;若否,转步骤410。
步骤410:判断是否中臀在脚部下方且condition_A=True,或者鼻子在脚部的下方。若是,condition_B=True,转步骤411;若否,转步骤411。
步骤411:将25个关键点中横纵坐标都不为0的关键点定义为全部非零节点。
步骤412:获取全部非零节点中横纵坐标的最大值和最小值。
步骤413:判断横纵坐标最大的点和横纵坐标最小的点间向量的水平和垂直长度的比值是否大于1。若是,condition_C=True,转步骤414。若否,转步骤414。
步骤414:判断鼻子、颈部、右肩、左肩、中臀的横坐标和纵坐标都不为0。若是,转步骤415;若否,转步骤419。
步骤415:定义脖子和中臀之间的向量长度为upper_body。
步骤416:定义脚部的点和中臀之间的向量最大长度为lower_body。
步骤417:定义upper_body和lower_body直接的比值为up_low_ratio。
步骤418:判断是否up_low_ratio小于等于0.45,且脖子在中臀上方,且脖子和中臀间的向量的水平和垂直长度的比值小于1。若是,condition_D=True,转步骤419;若否,转步骤419。
步骤419:判断是否颈部和中臀的横坐标和纵坐标都不为0,且脖子在中臀下方。若是,condition_F=True,转步骤420;若否,转步骤420。
步骤420:判断是否condition_A、condition_C和condition_E都为True,或者是否condition_B为True,或者是否condition_F为True。若是,判定跌倒;若否,判断未跌倒。
经过本实施例中提供的步骤401-步骤420后,即可完成实施例1中提供的各跌倒行为特征的匹配,实现不同类型姿态的跌倒检测。
实施例3:
在上述实施例1至实施例2提供的基于图像识别技术的跌倒检测方法的基础上,本发明还提供了一种可用于实现上述方法的基于图像识别技术的跌倒检测系统,
如图13所示,是本发明实施例的系统架构示意图。系统中包括图像采集设备和图像处理设备。图像采集设备用户获取待检测的增强后的视频流。图像处理设备用于根据实施例1或2中提供的基于图像识别技术的跌倒检测方法对增强后的视频流进行跌倒检测,例如,执行以上描述的图2、图8和图9所示的各个步骤。
为了获取到步骤102中所需使用的红外视频流和雷达成像图像,本实施例提供的系统中,图像采集设备包括红外摄像头和成像雷达,具体的:红外摄像头用户获取红外视频流;成像雷达用户获取雷达成像图像。在具体实施中,可以使用红外摄像头采集视频流,并结合UWB MIMO雷达成像,对人体被遮挡部分进行增强,再将增强后的视频流传入图像处理设备中进行检测。
另一方面,为了便于部署且减小能耗,图像处理设备可以使用各种边缘处理设备,以标定图像中的每个人物、获取每个人物的姿态关键点、并根据姿态关键点进行跌倒检测。进一步的,当判断有人跌倒时,还可以直接通过边缘处理设备发出告警,或向指定设备推送告警信号。
在某个实际实施场景中,使用Atlas500智能小站作为图像处理设备。使用Atlas500智能小站自带的解码模块对视频流进行解码;通过Atlas500智能小站的显示接口框选出跌倒的人物;通过Atlas500智能小站的报警接口,使用蜂鸣器发出告警;通过Atlas500智能小站的有线和无线网络接口,向监控app发送告警。使用Atlas500智能小站能够一站式处理视频输入、预测和告警,降低了部署难度。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于图像识别技术的疲劳驾驶行为检测方法
- 一种基于图像识别技术的菜品识别系统和方法
- 一种基于AEP内存技术的SWRaid检测方法及检测系统
- 一种基于图像处理技术的无人机在覆冰检测系统及其工作方法
- 一种基于主机监控技术的挖矿恶意软件检测系统及方法
- 一种基于图像识别技术修饰金属的检测方法及检测系统
- 一种基于图像识别技术修饰金属的检测方法及检测系统