一种基于强化学习的相机自动对焦方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及探测成像技术领域,具体涉及基于强化学习的相机自动对焦方法。
背景技术
自动对焦(Autofocus AF)技术是各类相机中的核心技术之一,如何快速准确地实现自动对焦对于各类相机具有重大意义。现有的基于数字图像处理的自动对焦方法可分为对焦深度法和离焦深度法,其中对焦深度法通过在对焦过程中获取一系列清晰度不同的图像,并用对焦评价函数计算其清晰度评价值,再以对焦搜索策略控制步进电机驱动镜头移动,直到镜头到达准焦位置。该方法的系统结构简单,成本较低,对焦结果准确,且对焦速度较快,成为了自动对焦领域的主流方法。但是,该方法往往需要人工设计对焦搜索策略,常用的策略包括爬山搜索策略,斐波那契搜索策略,黄金分割搜索策略等,这些现有搜索策略的对焦精度和速度受人工经验参数的影响较大,降低了算法的鲁棒性,因此需要探索新的自动对焦方法,其只需相机与环境的交互,即可自主学习到最优的自动对焦搜索策略。
强化学习是一种控制策略自学习算法,它既不属于有监督学习方法,也不属于无监督学习方法。强化学习是一种通过智能体(Agent)与环境(Environment)的交互进行学习的方法,在该过程中,执行动作(Action)改变智能体当前的状态(State),根据获得的奖励(Reward)调整网络参数,并最终学习到最优的策略。因此可使用强化学习网络学习到最优的自动对焦策略,并用于指导相机的自动对焦过程。然而,现有的基于强化学习的自动对焦方法的泛化性较差,例如,在2018International Conference on Control,Automation,Robotics and Vision会议上的“A robotic auto-focus system based on deepreinforcement learning”论文,提出了一种基于强化学习深度Q网络的自动对焦方法,用以指导显微镜系统的自动对焦过程,该方法首次将强化学习应用于自动对焦领域,并在相同视野的显微数据集上取得了较好的效果。但是,该方法在不同视野的显微数据集上的表现较差,并且需要花费大量时间训练深度Q网络。
发明内容
本发明的目的在于针对现有技术中存在的问题,提出一种基于强化学习的相机自动对焦方法。本发明方法克服了传统自动对焦方法需要人工设计对焦策略的缺点,仅通过智能体和相机视频流信息的交互,即可学习到最优的自动对焦策略,在不同场景下均能实现准确、高效的自动对焦。
一种基于强化学习的相机自动对焦方法,步骤如下:
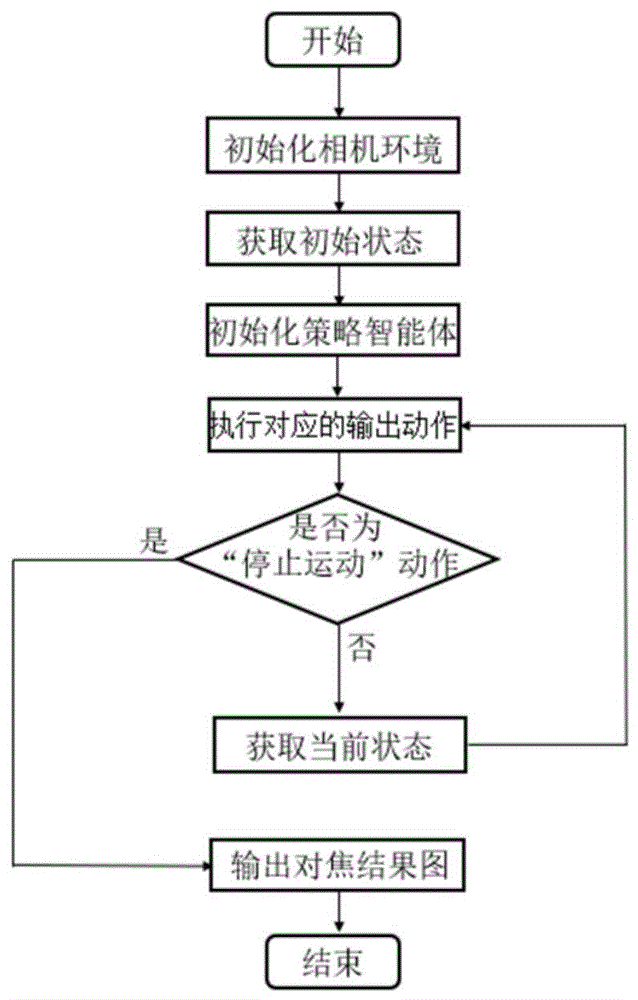
从相机视频流中获取当前的图像帧,首先使用图像清晰度评价函数获取图像的清晰度信息,然后将所述图像的清晰度信息转换为初始状态信息输入到强化学习网络中,强化学习网络输出下一阶段应执行的调焦动作,并获取执行所述调焦动作后相机当前的图像帧,循环往复,直至强化学习网络输出“停止运动”的动作,此时表示相机已完成自动对焦过程。
所述使用图像清晰度评价函数获取图像的清晰度信息的方法为,使用梯度算子分别提取图像水平方向和垂直方向的梯度值,求两个方向梯度值的绝对值之和,得到图像清晰度值。
所述图像清晰度值的计算方法具体为,水平方向的梯度算子定义为G
所述强化学习网络的训练过程如下:
以不同场景下的“失焦-准焦-失焦”图像数据集作为训练集,虚拟相机环境和策略智能体交互,以目标网络的目标价值与表现网络的估计值的差异为损失,迭代训练一定次数,得到最优的强化学习网络。
所述强化学习网络的构建:
1)构建虚拟相机环境:采用离线学习策略,设计相应的状态,动作和奖励。
2)构建策略智能体:采用表现网络和目标网络相解耦的双网络模式。
3)以不同场景下的“失焦-准焦-失焦”图像数据集作为训练集,以目标网络的目标价值与表现网络的估计值的差异为损失,通过虚拟相机环境和策略智能体交互学习得到最优的强化学习网络。
将强化学习网络应用于自动对焦方法,具体方法为:将采集得到的真实图像集输入到强化学习网络中,所述强化学习网络实时输出相机的动作流和对应的图像清晰度,指导相机完成自动对焦过程,输出视觉效果良好的图像。
所述不同场景下的“失焦-准焦-失焦”图像数据集,用于强化学习网络的训练和测试。所述不同场景下的“失焦-准焦-失焦”图像数据集的获取方法,具体步骤如下:
1)调节相机到最小对焦位置。
以最小对焦位置作为运动起点,不断步进并采集当前位置的图像,直至到达相机的最大对焦位置。
通过图像清晰度评价函数依次计算采集得到的每幅图像的清晰度值,得到图像清晰度曲线数据。
所述强化学习网络中,虚拟相机环境负责与策略智能体交互,通过输入策略智能体给定的动作,输出执行该动作后的状态量与执行该动作后可获得的奖励。通过设计合理的状态,动作和奖励,使策略智能体在与虚拟相机环境交互学习的过程中,逐渐学习到最优的自动对焦策略。
所述虚拟相机环境具体为:考虑到失焦模糊存在对称性,不能从单帧图像中获取当前的状态,因此定义t时刻的观测状态为S
所述策略智能体负责与虚拟相机环境交互,通过虚拟相机环境给定的状态,输出下一时刻应执行的动作;通过虚拟相机环境返回的奖励,更新上一时刻的状态动作价值。考虑到自动对焦任务中存在无限状态集,有限动作集的特点,策略智能体采用表现网络和目标网络相解耦的双网络模式,缓解单网络训练时“自导自演”带来的波动,具体如下:
所述策略智能体包含两个网络:其中一个是表现网络(Evaluation Network),负责与虚拟相机环境交互,选择下一时刻执行的动作,获取交互样本;另一个是目标网络(Target Network),负责计算目标价值。两个网络的结构相同,均由3个全连接层和2个RELU激活层组成,其中输入端的维度是5,隐藏层的维度是128,输出端的维度是5。
训练得到最优的强化学习网络。采用e-greedy探索策略,通过经验缓存池缓存交互样本,以目标网络的目标价值与表现网络的估计值的差异作为损失,迭代训练深度学校网络至一定的回合数,使策略智能体学习得到最优的强化学习网络,具体如下:
强化学习网络的训练过程采用e-greedy的探索策略,一开始以100%的概率随机选择下一时刻执行的动作,随着训练的进行缩减至一定的比例(如10%),从以探索为主的策略被逐渐转变成以利用为主的策略。采用经验缓存池缓存交互样本,其特征在于,将学习过程转变为离线模式,去除交互样本的相关性,提高交互样本的使用效率。强化学习网络的训练过程,具体如下:
1)初始化容量为N的经验缓存池D,表现网络Q及其参数θ,目标网络
2)设置迭代回合数为M,每次迭代前初始化虚拟相机环境,得到初始状态s
3)在当前回合内,每次以ε的概率随机选择一个动作a
4)执行动作a
5)若策略智能体在第j+1步执行“停止运动”的动作,则目标网络的目标价值y
6)设置损失函数LOSS=(y
7)迭代3)-6)至回合数为M,训练结束。
本发明的有益效果为:基于离线学习策略,设计了合理的状态,动作和奖励,得到虚拟相机环境,大幅减少了强化学习网络的训练时间。采用表现网络和目标网络相解耦的双网络模式训练得到最优的强化学习网络。在虚拟相机环境上完成了自动对焦方法的训练和测试,验证了基于强化学习的自动对焦方法具有良好的对焦精度和较高的对焦效率。本发明可应用于任意仅带有步进调焦功能的相机,而无需相机反馈精确的位置信息,具有较强的实用价值。
附图说明
图1是本发明方法“失焦-准焦-失焦”数据集构建过程的示意图。
图2是本发明方法的流程图。
图3是本发明方法强化学习网络中策略智能体的网络框架图。
图4是本发明方法强化学习网络的训练流程图。
图5是本发明实施例的强化学习网络的训练结果图。
图6是本发明实施例在虚拟相机环境上自动对焦的视觉结果图。
图7是本发明实施例在虚拟相机环境上自动对焦的动作流程图。
具体实施方式
以下结合具体实施例和附图进一步说明本发明。
实施例
首先,使用相机系统采集并构建不同场景下的“失焦-准焦-失焦”图像数据集,具体步骤如下:
如图1所示,首先,调节相机到最小对焦位置。然后,以最小对焦位置作为运动起点,不断步进并采集当前位置的图像,直至到达相机的最大对焦位置。最后,对采集得到的图像数据集,通过图像清晰度评价函数依次计算每幅图像的清晰度值,得到当前数据集的图像清晰度曲线数据,用于后续强化学习网络的训练和测试。
使用图像清晰度评价函数获取图像的清晰度信息的方法为,使用梯度算子分别提取图像水平方向和垂直方向的梯度值,求两个方向梯度值的绝对值之和,得到图像清晰度值。
本发明方法的流程图如图2所示。
虚拟相机环境负责与策略智能体交互,通过输入策略智能体给定的动作,输出执行该动作后的状态量以及在执行该动作可获得的奖励。通过设计合理的状态,动作和奖励,使策略智能体在与虚拟相机环境交互学习的过程中,逐渐学习到最优的自动对焦策略。
其中,虚拟相机环境中状态,动作和奖励的设计具体描述如下:
考虑到失焦模糊存在对称性,不能从单帧图像中获取当前的状态,因此定义t时刻的观测状态为S
策略智能体负责与虚拟相机环境交互,通过虚拟相机环境给定的状态,输出下一时刻应执行的动作;通过虚拟相机环境返回的奖励,更新上一时刻的状态动作价值。考虑到自动对焦任务中存在无限状态集,有限动作集的特点,基于策略智能体采用表现网络和目标网络相解耦的双网络模式,缓解单网络训练时“自导自演”带来的波动。
其中,所述策略智能体具体如下:
策略智能体包含两个网络:其中一个是表现网络(Evaluation Network),负责与虚拟相机环境交互,选择下一时刻执行的动作,获取交互样本;另一个是目标网络(TargetNetwork),负责计算目标价值。两个网络的结构相同,如图3所示,均由3个全连接层和2个RELU激活层组成,其中输入端的维度是5,隐藏层的维度是128,输出端的维度是5。
随后,通过“策略智能体”和“虚拟相机环境模块”的交互学习,训练得到最优的自动对焦策略,具体过程如图4所示。采用e-greedy的探索策略,一开始以100%的概率随机选择下一时刻执行的动作,随着训练进行到2000回合时缩减至10%,从以探索为主的策略被逐渐转变成以利用为主的策略。采用经验缓存池缓存交互样本,将学习过程转变为离线模式,去除交互样本的相关性,提高交互样本的使用效率。强化学习网络的训练过程为:初始化容量为N=1024的经验缓存池D,表现网络Q及其参数θ,目标网络
使用本发明方法对某具体实施例的强化学习网络进行训练,训练结果如图5所示,图5(a)为每百回合的平均得分,图5(b)为每百回合的平均损失,图5(c)为每百回合的对焦成功率,图5(d)为每百回合的平均对焦步数,每一个值均由100回合的结果经平均计算得到。在训练的后期,强化学习网络的平均得分约为70,平均损失收敛到0.9左右,对焦成功率接近90%,平均对焦步数为4-5步左右,出现波动的原因是因为在训练过程中采用了概率为10%的随机探索。
自动对焦方法的应用具体描述如下:将采集得到的真实图像集输入到强化学习网络中,所述强化学习网络实时输出相机的动作流和对应的图像清晰度,指导相机完成自动对焦过程,输出视觉效果良好的图像。图6为某具体实施例基于本发明方法的运行结果,其中图6(a)是自动对焦前相机输出的图像,图6(b)是自动对焦后相机输出的图像,和图6(a)相比,对焦后的图6(b)场景信息更丰富,视觉效果更好。
图7为该具体实施例基于本发明方法的对焦动作流,其中,相机先以粗调动作运动,再以细调动作微调到达对焦清晰位置,通过5次运动完成自动对焦过程。
本发明提出了全新的基于强化学习的相机自动对焦方法,通过强化学习网络学习到最优的自动对焦策略,指导相机的自动对焦过程,得到视觉效果良好的对焦图像。
- 一种基于骨髓白细胞图片的自动对焦方法
- 基于强化学习的自动对焦方法、系统及其应用设备
- 基于焊接熔池的数字相机自动对焦系统及其自动聚焦方法