CO中毒患者发生迟发性脑病预警方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及人工智能与临床医学相结合的技术领域,具体涉及一种基于机器学习的CO中毒患者发生迟发性脑病预警方法及系统。
背景技术
一氧化碳主要是含碳物质不完全燃烧产生,其进入人体后与血红蛋白结合形成碳氧血红蛋白,由于一氧化碳与血红蛋白的亲和力要明显高于氧气与血红蛋白的亲和力(约为氧气200~300倍),且结合后不易解离等特点,导致血红蛋白失去携氧能力,从而导致机体组织器官缺氧,产生一氧化碳中毒。迟发性脑病(delayed encephalopathy acutecarbon monoxidepoisoning,DEACMP)是急性一氧化碳中毒患者在最初临床症状缓解后,经过2~60天的“假愈期”后,出现以精神意识障碍、锥体系或锥体外系神经损害等为主要表现之一的一种疾病。据相关资料统计,DEACMP发病率高达10~30%,而重症CO中毒患者约有50%会出现DEACMP,而且这种趋势越来越高(“一氧化碳中毒迟发性脑病研究进展”,许新炜,中西医结合心血管病杂志,2018年3月)。
迟发性脑病的预后较差,严重影响患者的生活质量和社会功能。关于其发病机制归纳出以下几种学说:缺血缺氧学说、血管因素学说、血流变异常学说、细胞凋亡学说、细胞自噬学说、免疫反应学说、自由基学说、兴奋性氨基酸学说等。但尚不能完全解释迟发性脑病的某些发病特点和临床表现,许多机制仍停留在假说阶段,需进一步实验证实。需结合增加脑组织供氧、调整自身免疫功能、清除自由基等治疗方法,进一步阐明CO中毒迟发性脑病的机制(“一氧化碳中毒迟发性脑病发病机制的研究”,刘鹏等,内蒙古医学杂志,2019年第51卷第9期)。
目前,对于一氧化碳中毒患者是否会发生迟发性脑病,尚无有效的预测方法。王思琪等学者探讨
当前对DEACMP的研究多集中在对促发因素方面的分析,对预测因子的关注度不断升高。促发因素:1、CO中毒时的意识障碍。张晓莉在研究中指出急性CO中毒时意识障碍程度越严重,发生迟发性脑病的可能性就越大,尤其是昏迷持续时间超过12h,发生率明显升高,超过48h者迟发性脑病发生率接近60%。Steven R Goldsmith等在研究中指出意识障碍持续时间长的患者,脑白质区神经纤维的弥散受限更明显,迟发性脑病的发生率也越高;2、年龄。王文岚等在研究中指出CO中毒后导致脑代谢异常,年龄越大发生率越高,年龄>60岁发生的风险较45岁以下者高4倍以上,预后也更差;3、治疗不及时。急性CO中毒早期高压氧治疗可有效降低迟发性脑病的发病率,陈劲松等在研究中指出高压氧治疗时间是影响迟发性脑病发生的独立危险因素,其主要作用机制是加速碳氧血红蛋白解离和CO的排除,使大脑网状系统和脑干部位氧分压增加,改善脑组织缺血、缺氧状态,有利于休眠细胞复活和神经功能恢复;4、高血压和糖尿病。丁伟利等指出老年人,尤其是合并有高血压病、冠心病、脑血管病或糖尿病的老年患者更容易出现迟发性脑病,可能是因为合并有一定基础疾病的老年患者,脑动脉弥漫性硬化导致脑血管在中毒后受损更加严重,脑细胞长期暴露于严重缺血缺氧的环境中而发生脱髓鞘病变,进而发生迟发性脑病;5、头颅CR/MRI异常。Yueh-FengSung等在研究中指出CO可导致脑灰质易损区域坏死,Kaoru Kudo等也指出双侧对称性苍白球坏死被认为是急性CO中毒的特征性病变;6、吸烟、饮酒史。Hu等在研究中指出烟酒可引起机体各组织的氧化损伤,烟中的有害物质可直接损伤血管内皮细胞,破坏机体内环境稳态,导致大脑耐受缺氧能力下降。因此,有吸烟、饮酒史患者发生急性CO中机体对缺氧的耐受性减弱,更易损伤脑内神经元,发生迟发性脑病。
然而,即便知道迟发性脑病的一些发病机理,医务人员要在患者发生一氧化碳中毒后与发生迟发性脑病的2~60天的“假愈期”中提前作出诊断也是极其困难的,因为患者体征或常规检查难以作为诊断的直接依据,迟发性脑病的发生是多种因素导致的结果,现有技术中尚没有一种切实可行的诊断模型能够实现快速诊断。
在中国专利文献中,公开号为CN114795114A的发明专利提出了一种基于多模态学习的一氧化碳中毒迟发性脑病预测方法,通过结合贝叶斯网络结构学习算法和医生建议,构建特征依赖图;基于特征依赖图,构建图嵌入前馈神经网络,将特征间的依赖关系集成到神经网络结构中,以得到结构化特征的向量表示;并设计特征融合结构,获取融合多模态信息后的向量表示,并将该向量输入到非线性神经网络层,最终得到一氧化碳中毒患者是否会发生迟发性脑病的预测结果。该方案主要是解决了在数据缺失的情况下无法实现准确预测的问题。
随着信息技术尤其是新一代大数据、云计算、人工智能等前沿技术的发展,数据缺失,或者样本不足等问题已不是重点考虑的问题,而应当侧重于考虑如何在大量的已录入计算机或者网络中的样本诊断数据基础上,开发一种能够及时准确地预测一氧化碳中毒患者发生迟发性脑病风险的系统,以便医生能够根据预测结果采取相应的预防和治疗措施,降低迟发性脑病的发生率和严重程度。
发明内容
本发明的目的是提出一种基于机器学习的CO中毒患者发生迟发性脑病预警方法及系统,以解决上述技术问题。
本发明的一个方面,提出了一种基于机器学习的CO中毒患者发生迟发性脑病预警方法,该预警方法至少包括如下步骤:
构建基于云平台数据库的一氧化碳中毒迟发性脑病的机器学习模型;获取一氧化碳中毒患者的诊断信息并进行解析,得到一条或多条诊断明细;将前述的诊断明细输入预先构建的机器学习模型进行推理,得到针对前述的诊断明细的初始预测列表;根据前述的初始预测列表中包含的患者信息,从医院医疗系统中获取与患者相关联的临床数据,并构建临床数据集;根据前述的临床数据集筛选并排除不适合进行预警的患者后给出最终预警列表。
作为进一步的优选方案,还包括根据机器学习模型预测的结果与患者实际发生迟发性脑病的结果对照后的数据上传至云平台数据库中,对机器学习模型进行迭代升级,用迭代升级后的机器学习模型再进行预测;重复n次以上步骤,获得n次迭代升级后的推荐模型,n≥1。
其中,机器学习模型基于决策树、随机森林、XGboost三种方法分别构建,使用投票法作为推荐算法,来综合三种方法的预测结果,得出患者发生迟发性脑病的概率值。
在一些实施例中,获取一氧化碳中毒患者的诊断信息并进行解析,得到一条或多条诊断明细是通过从医院医疗系统中读取患者的电子病历,或者通过医生客户端输入患者的诊断信息,或者通过语音识别或自然语言处理技术将医生的语音或文字转换为结构化的诊断信息来实现。
在一些实施例中,针对诊断明细的初始预测列表是通过将诊断明细作为特征向量输入到机器学习模型中,根据模型的输出得到与诊断明细相关的迟发性脑病发生概率值,按照概率值从高到低排序后形成。
在一些实施例中,获取与患者相关联的临床数据是通过从医院医疗系统中查询与初始预测列表中的每一位患者相关联的临床数据,至少包括患者的基本信息、既往史、家族史、过敏史、用药史、检查结果在内,并构建一个包含了所有相关数据的临床数据集来实现。
在一些实施例中,根据临床数据集中的不同属性,对初始预测列表中的每一位患者进行检查,如果患者存在以下情况之一,则将该患者从列表中删除,否则保留该患者,并根据预测概率值重新排序,形成最终预警列表;以下情况之一包括:患者已经确诊为迟发性脑病;患者已经死亡或转院;患者有严重的心肺功能障碍或其他危重症;患者有其他影响迟发性脑病发生和治疗的因素。
本发明的另一个方面,提出了一种基于机器学习的CO中毒患者发生迟发性脑病预警系统,至少包括以下模块:
诊断信息解析模块,用于获取诊断信息并进行解析,得到一条或多条诊断明细,包括患者信息、医生信息及疾病诊断;
预测模型构建模块,用于根据云平台数据库已有患者信息,使用决策树、随机森林、XGBoost三种机器学习方法,构建一氧化碳中毒患者发生迟发性脑病的预测模型;
临床数据获取模块,用于根据所述初始预测列表中包含的患者信息,从医院医疗系统中获取与所述患者相关联的临床数据;
预测结果生成模块,用于将所述诊断明细输入预先构建的预测模型进行推理,得到针对所述诊断明细的初始预测列表;
预警结果筛选模块,用于根据所述临床数据集筛选并排除不适合进行预警的患者后给出最终预警列表。
在一些实施例中,还包括将以上五个模块构成的系统嵌入现有的医院医疗系统后构成的新系统,实现与临床工作的无缝对接。
本发明的另一个方面,提出了一种用于CO中毒患者发生迟发性脑病预警的计算机可读载体,该计算机可读存储介质用于存储程序代码,该程序代码用于执行前述的基于机器学习的CO中毒患者发生迟发性脑病预警方法。
本发明的有益效果:
本发明提出一种基于机器学习的一氧化碳中毒患者发生迟发性脑病预警系统,实现迟发性脑病精准预警,提高临床预防能力。系统可以利用机器学习的方法,结合已有患者信息和临床数据,构建高效准确的预测模型,提高模型的泛化能力和鲁棒性;该方案可以嵌入院内医疗系统,实现与临床工作的无缝对接,自动抓取患者信息并进行分析,及时发出预警信号,提醒医生提前进行预防和治疗;可以为一氧化碳中毒患者的诊疗提供辅助决策支持,提高医生工作效率,减轻此类病人医疗负担。
附图说明
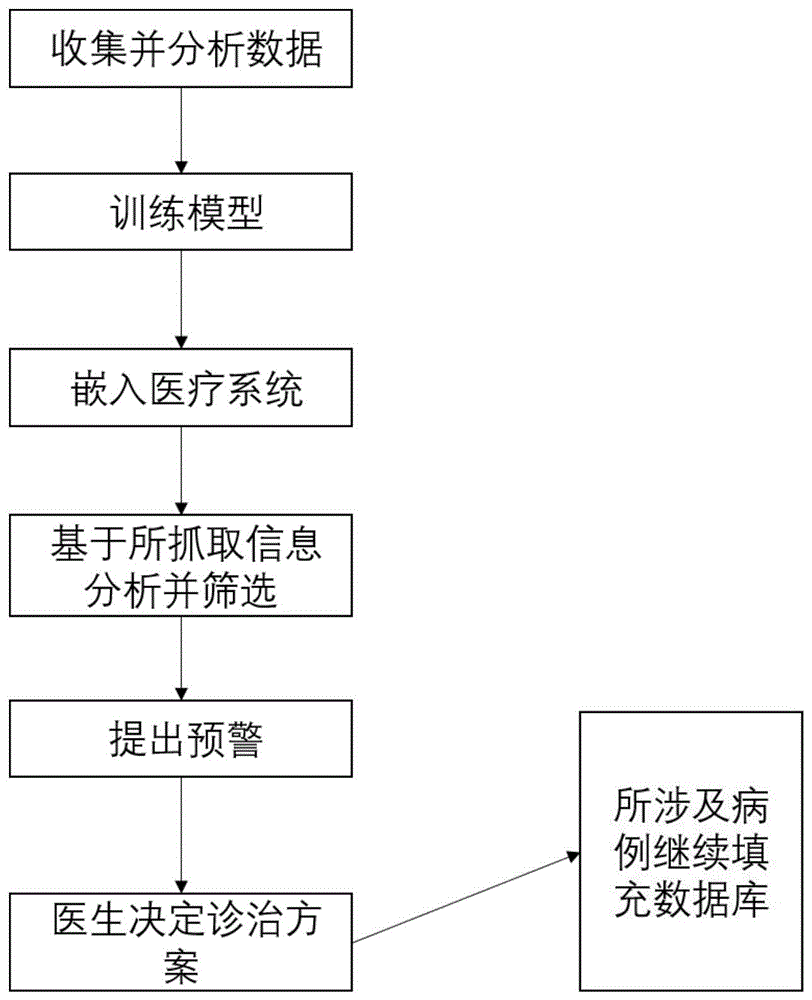
图1为本发明的一个实施例的计算流程图。
具体实施方式
以下将结合附图对本发明的较佳实施例进行详细说明,以便更清楚理解本发明的目的、特点和优点。应理解的是,附图所示的实施例并不是对本发明范围的限制,而只是为了说明本发明技术方案的实质精神。
在下文的描述中,出于说明各种公开的实施例的目的阐述了某些具体细节以提供对各种公开实施例的透彻理解。但是,相关领域技术人员将认识到可在无这些具体细节中的一个或多个细节的情况下来实践实施例。在其它情形下,与本申请相关联的熟知的装置、结构和技术可能并未详细地示出或描述从而避免不必要地混淆实施例的描述。
在整个说明书中对“一个实施例”或“一实施例”的提及表示结合实施例所描述的特定特点、结构或特征包括于至少一个实施例中。因此,在整个说明书的各个位置“在一个实施例中”或“在一实施例”中的出现无需全都指相同实施例。另外,特定特点、结构或特征可在一个或多个实施例中以任何方式组合。
实施例1:
如图1所示,在该实施例中,我们已有的历史诊断数据已上传至遵义市医疗系统这样一个平台中,因此在该实施例中,需要构建基于遵义市医疗系统内一氧化碳中毒迟发性脑病的预测模型,包括疾病特征信息库和迭代升级后的推荐模型。首先,必须对遵义市医疗系统内的历史诊断数据进行收集和预处理,并且分析数据。在这个过程需要收集大量的患者数据,这些数据包括患者的特征以及他们是否在一氧化碳中毒后发生迟发性脑病。这些数据需要经过预处理,例如清理、规范化和编码。
特征选择和构建模型:这个过程需要选择与疾病相关的特征。然后,利用这些特征构建机器学习模型,该模型可以基于患者的特征预测他们是否可能患有这种疾病。训练模型:一旦有了机器学习模型,就可以用患者的特征和对应的结果(是否患病)来训练模型。可以使用一种现有的优化算法(如梯度下降)来最小化模型的错误率。
计算阈值:在模型训练完成后,可以用它来预测新患者的患病风险。这个预测通常是一个连续的数值,而不是一个二元的结果(例如,大于0.5为高风险,小于0.5为低风险)。这个过程可以选择一个阈值来确定何时认为一个患者是患病的。选择这个阈值可能涉及考虑误报率、漏报率和其他因素。最后,需要评估模型的性能,可以使用交叉验证、混淆矩阵和其他指标。根据模型的性能,需要调整模型或重新选择特征。
模型训练完成后,将模型嵌入到医院正在使用的医疗系统中,如任何一家医院的海泰医疗系统。在接诊某位一氧化碳中毒患者后,为了判定其发生迟发性脑病的可能性,首先需要抓取该患者与已经建立的机器学习模型中对应的特征信息,基于所抓取的信息分析并筛选,得到一条或多条诊断明细,包括患者信息、医生信息及疾病诊断。具体是通过从医院医疗系统中读取患者的电子病历,或者通过医生客户端输入患者的诊断信息,或者通过语音识别或自然语言处理技术将医生的语音或文字转换为结构化的诊断信息来实现。诊断明细可以包括患者的年龄、性别、中毒原因、中毒时间、中毒场所、救治措施、血液检测结果、影像学检查结果、第一次接受高压氧治疗的时间等。
将这些诊断明细输入预先构建的机器学习模型进行推理,得到针对所述诊断明细的初始预测列表。具体是通过将诊断明细作为特征向量输入到机器学习模型中,根据模型的输出得到与诊断明细相关的迟发性脑病发生概率值,按照概率值从高到低排序,形成初始预测列表来实现。
根据初始预测列表中包含的患者信息,从医院海泰医疗系统中获取与患者相关联的临床数据。具体通过从医院海泰医疗系统中查询与初始预测列表中的每一位患者相关联的临床数据,如患者的基本信息、既往史、家族史、过敏史、用药史、检查结果等,并构建一个包含了所有相关数据的临床数据集来实现。
根据临床数据集筛选并排除不适合进行预警的患者后给出最终预警列表。具体是通过根据临床数据集中的不同属性,对初始预测列表中的每一位患者进行检查,如果患者存在以下情况之一,则将该患者从列表中删除,否则保留该患者,并根据预测概率值重新排序,形成最终预警列表来实现。以下情况之一包括:
(1)患者已经确诊为迟发性脑病;
(2)患者已经死亡或转院;
(3)患者有严重的心肺功能障碍或其他危重症;
(4)患者有其他影响迟发性脑病发生和治疗的因素。
在完成上述步骤后,根据机器学习模块输出的概率值,判断是否需要向医生发出预警信号。本实施例中设定了一个阈值为0.5,即如果患者发生迟发性脑病的概率值大于等于0.5,则认为该患者有较高的风险,需要发出预警信号;如果患者发生迟发性脑病的概率值小于0.5,则认为该患者有较低的风险,不需要发出预警信号。
最后,需要显示该患者的特征信息和预测结果。在本实施例中,使用一个图形用户界面来显示该患者的特征信息和预测结果。特征信息包括年龄、性别、中毒原因、中毒时间、中毒场所、救治措施、血液检测结果、影像学检查结果等;预测结果包括三个机器学习模型输出的概率值和投票法输出的最终概率值。如果需要发出预警信号,则在界面上显示红色的“高风险”字样,并发出声音提示;如果不需要发出预警信号,则在界面上显示绿色的“低风险”字样,并无声音提示。
预警信息还可以提供一些预防和治疗迟发性脑病的建议,如高压氧治疗、药物治疗、心理干预等。
在本实施例中,机器学习模型由决策树、随机森林、XGBoost三种方法构建,并使用投票法进行集成。
在本实施例中,已知患者发生一氧化碳中毒,并且得到如下信息:年龄、性别、一氧化碳中毒原因、一氧化碳中毒时间、一氧化碳中毒场所、救治措施、血液检测结果、影像学检查结果。将如下信息分别编号并录入数据库后,利用这些信息,分别由决策树、随机森林、XGBoost三种方法构建机器学习模型,以判定患者是否发生迟发性脑病,实例步骤如下:
1.决策树模型的构建步骤:
(1)准备数据:将患者的年龄、性别、一氧化碳中毒原因、一氧化碳中毒时间、一氧化碳中毒场所、救治措施、血液检测结果、影像学检查结果等数据整理成表格或数据库形式,作为训练集和测试集。
(2)划分数据集:将数据集分为训练集和测试集,其中训练集用于训练模型,测试集用于评估模型的准确性和泛化能力。
(3)选择特征:根据所提供的信息,选择与迟发性脑病相关的特征。例如,年龄、性别、一氧化碳中毒原因、一氧化碳中毒时间、一氧化碳中毒场所、救治措施、血液检测结果、影像学检查结果等。
(4)构建决策树模型:使用决策树算法,根据选择的特征构建决策树模型。具体步骤如下:
a.选择一个特征作为根节点,将数据集按照该特征的不同取值进行划分。
b.对于每个划分的子数据集,选择一个新的特征作为子节点,并将子数据集按照该特征的不同取值继续划分。
c.重复上述步骤,直到满足停止条件,例如子节点中的样本数小于预定阈值,或者所有样本都属于同一类别。
d.将每个叶节点标记为相应的类别,即“是迟发性脑病”或“不是迟发性脑病”。
(5)评估模型:使用测试集评估模型的准确性和泛化能力。具体方法包括计算模型的精度、召回率、F1分数等指标。
(6)优化模型:根据评估结果,对模型进行优化,例如剪枝、调整停止条件等。
(7)应用模型:将优化后的模型应用于实际场景中,使用该模型对新的患者进行预测和判定是否发生迟发性脑病。
2.随机森林算法模型的构建步骤:
(1)数据清洗和准备:首先,我们需要确保所有的数据都被正确地记录和清理。这可能包括处理缺失值、异常值和重复值。另外,需要将分类变量(例如,性别、一氧化碳中毒原因、一氧化碳中毒场所等)进行编码,以便机器学习算法能够理解。
(2)特征选择:选择哪些特征对于判断迟发性脑病最有影响。这可能包括年龄、性别、一氧化碳中毒原因、一氧化碳中毒时间、一氧化碳中毒场所、救治措施、血液检测结果、影像学检查结果等。
(3)建立随机森林模型:使用scikit-learn库中的RandomForestClassifier或RandomForestRegressor类来建立模型。这个过程设置一些参数,例如树的数量(n_estimators)、树的最大深度(max_depth)等。
(3)训练模型:使用患者的历史数据来训练模型。这将教会模型如何根据给定的特征预测患者是否患有迟发性脑病。
(4)验证和评估模型:使用一部分未用于训练的数据来验证模型的准确性。这可以通过计算模型的精度、召回率、F1分数等来完成。
(5)调整模型:如果模型的性能不佳,可能需要调整模型的参数,或者尝试不同的机器学习算法。此外,如果存在新的数据,也可以用来进一步训练模型,以改进其预测性能。
(6)应用模型:一旦模型经过验证并满足要求,就可以在实际场景中应用。当有新的患者数据时,将数据输入模型,以预测他们是否可能患有迟发性脑病。
3.XGBoost(Extreme Gradient Boosting)模型的构建步骤:
(1)数据准备和预处理:首先,将收集到的患者信息(年龄、性别、一氧化碳中毒原因、一氧化碳中毒时间、一氧化碳中毒场所、救治措施、血液检测结果、影像学检查结果)进行清洗和预处理。将某些分类变量进行编码(例如,将“一氧化碳中毒原因”这一类别变量转化为数值),或者对某些连续变量进行归一化(例如,“年龄”)。
此外,你需要将标签(是否发生迟发性脑病)进行编码,例如,可以将“是”编码为1,“否”编码为0。
(2)划分数据集:将数据集分为训练集和测试集。使用交叉验证的方法进行训练和测试数据集的划分。
(3)使用XGBoost构建模型:
在Python环境下,可以使用xgboost库来使用XGBoost算法。以下是一个示例代码片段:
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
#假设X是特征数据,y是标签
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,
random_state=42)
#将标签编码为数值
le=LabelEncoder()
y_train=le.fit_transform(y_train)
y_test=le.transform(y_test)
#定义XGBoost模型
param={
'max_depth':6,#the maximum depth ofeach tree
'eta':0.3,#the training step for each iteration
'silent':1,#logging mode-quiet
'objective':'binary:logistic',#error evaluation for multiclasstraining
'eval_metric':'auc'#evaluation metric
}
num_round=20#the number oftraining iterations
bst=xgb.train(param,X_train,y_train,num_round)
#使用模型进行预测
y_pred=bst.predict(X_test)
y_pred=le.inverse_transform(y_pred)#将预测结果转换为原始标签
(4)模型评估:可以使用一些指标来评估模型的性能,如准确率、召回率、F1分数等。例如,可以使用以下代码计算准确率:
from sklearn.metrics import accuracy_score
accuracy=accuracy_score(y_test,y_pred)
print("Accuracy:%.2f%%"%(accuracy*100.0))
(5)模型优化:如果模型的性能不理想,需要对模型进行优化。例如,可以尝试调整XGBoost的参数(例如max_depth、eta等),或者尝试使用不同的特征。
(6)应用模型:当模型经过训练和优化后,将其应用于实际场景中,使用它来预测新的患者是否会发生迟发性脑病。
4.使用投票法来集成三个预测模型。可以使用sklearn库中的VotingClassifier类来实现,根据不同模型的预测结果或预测概率来决定最终的预测结果。
from sklearn.ensemble import VotingClassifier
vc=VotingClassifier(estimators=[("dt",dt),("rf",rf),
("xgb",xgb)],voting="soft")
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
- 一种基于多模态学习的一氧化碳中毒迟发性脑病预测方法
- 一种一氧化碳中毒迟发性脑病预测模型的构建方法