基于机器学习的生化免疫检验报告智能审核方法和系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于信息技术领域,具体涉及一种基于机器学习的生化免疫检验报告智能审核方法和系统。
背景技术
生化免疫检验报告(简称检验报告)是通过仪器检测后形成的数据,通过将相关信息进行整合形成的,检验报告需要进行人工或智能审核,符合规则为通过,不符合规则为不通过。相比人工审核,自动审核具有更好的准确度和效率,可以极大地减少实验室工作人员的人工审查时间和工作量,以及工作人员的视觉疲劳,从而使实验室工作人员将人工审核的重点放在小部分真正有问题的样本和检验结果上。然而,设计不当的自动审核规则容易造成假阴性结果,即自动发出了应该人工审核的样本。到目前为止自动审核的规则建立是基于逻辑和简单规则实现。实际工作中,这些规则的评价标准有限,简单的规则并不能包含所有的情况,不能处理复杂的临床数据,项目结果间的联系不能充分被利用,导致自动审核的准确率、通过率有限。
随着计算机科学进步,人类活动每天产生大量数据,机器学习(MachineLearning,ML)已渗透到几乎所有行业(例如,商业、研究和医疗保健),作为一种开放源码的计算工具,ML可以轻松实现(例如,商业的Python框架:Scikit-Learn、TensorFlow和Kera)。同时,实验室自动化正在将临床实验室转变为海量、复杂数据的来源。虽然ML技术正迅速发展(特别是深度学习),但目前临床实验室中只有少数基于ML的商业产品可用。在医学检验领域,ML已应用于微生物菌落研究,检测抗菌素耐药性,以及临床决策支持。
然而,到目前为止由于模型设计及模型参数选取不合理等问题,现有的机器学习模型对检验报告进行智能审核的准确率仍然不够理想,难以兼顾审核结果的灵敏度和特异性,这极大地限制了机器学习的技术在检验报告自动审核中的应用。
发明内容
针对现有技术的缺陷,本发明提供一种基于机器学习的生化免疫检验报告智能审核方法和系统,目的在于提供机器学习模型审核检验报告的准确率。
一种基于机器学习的生化免疫检验报告智能审核方法,包括如下步骤:
步骤1,输入待审核的检验报告,进行预处理和特征提取,得到特征;
步骤2,采用机器学习模型对步骤1得到的特征进行计算,得到是否通过的审核结果;
其中,所述机器学习模型是投票组合模型,所述投票组合模型的构建方法是:以DT、RF和SVM作为基分类器,采用投票法将所述基分类器的类别概率组合;
步骤3,输出所述审核结果。
优选的,步骤1中,所述预处理包括:
1)利用中位数或均数填补缺失值;
2)去除异常值。
优选的,步骤2中,所述DT、RF和SVM的训练方法如下:
步骤2.1,构建训练集和测试集;
步骤2.2,在训练集上利用十折交叉验证进行训练;
步骤2.3,在测试集上进行模型实际性能验证;
步骤2.4,利用学习曲线及网格搜索获得模型最佳超参数。
优选的,步骤2中,所述DT的参数为:Max depth为4;Criterion为gini;Minimpurity decrease为0;Min samples leaf为1;Splitter为best。
优选的,步骤2中,所述RF的参数为:N estimators为76;Max depth为22;criterion为entropy;Min impurity decrease为0;Min samples leaf为1。
优选的,步骤2中,所述SVM的参数为:kernel为rbf;gama为0.0294;C为1.1。
本发明还提供一种用于实现上述基于机器学习的生化免疫检验报告智能审核方法的系统,包括:
输入模块,用于输入待审核的检验报告;
预处理模块,用于进行预处理和特征提取,得到特征;
计算模块,用于采用机器学习模型对得到的特征进行计算,得到是否通过的审核结果;其中,所述机器学习模型是投票组合模型,所述投票组合模型的构建方法是:以DT、RF和SVM作为基分类器,采用投票法将所述基分类器的类别概率组合;
输出模块,输出所述审核结果。
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序用于实现上述基于机器学习的生化免疫检验报告智能审核方法。
本发明中,“审核结果”包括“合格样本”或“不合格样本”,所述“合格样本”是符合行业标准“WST 616-2018临床实验室定量检验结果的自动审核”,同时满足不是溶血样本、脂血样本和黄疸样本的样本;所述“不合格样本”包括不符合上述行业标准的样本、溶血样本、脂血样本和黄疸样本。
本发明利用多种机器学习算法对检验报告进行智能审核,解决了传统人工审核费时、费力,以及基于规则的自动审核系统的规则评价标准有限,不能处理复杂的临床数据,项目结果间的联系不能充分被利用的问题。通过优选设置模型的结构和参数,本发明集成学习模型在最佳阈值下,Sen为:0.93,Spe为:0.92,AUC为:0.96,样本审核通过率为91.80%(相比之下,现有技术中基于规则的自动审核系统在生化免疫检验报告分析中的通过率约为70%,本发明的方法通过率显著提升)。在保证正确率的前提下,显示出更高的通过率,这使得更少的样本需要人工审核,可更大程度上减少人工干预,缩短样本检测样本周转时间(TAT)。因此本发明在生化免疫检验报告的自动审核中具有很好的应用前景。
显然,根据本发明的上述内容,按照本领域的普通技术知识和惯用手段,在不脱离本发明上述基本技术思想前提下,还可以做出其它多种形式的修改、替换或变更。
以下通过实施例形式的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。凡基于本发明上述内容所实现的技术均属于本发明的范围。
附图说明
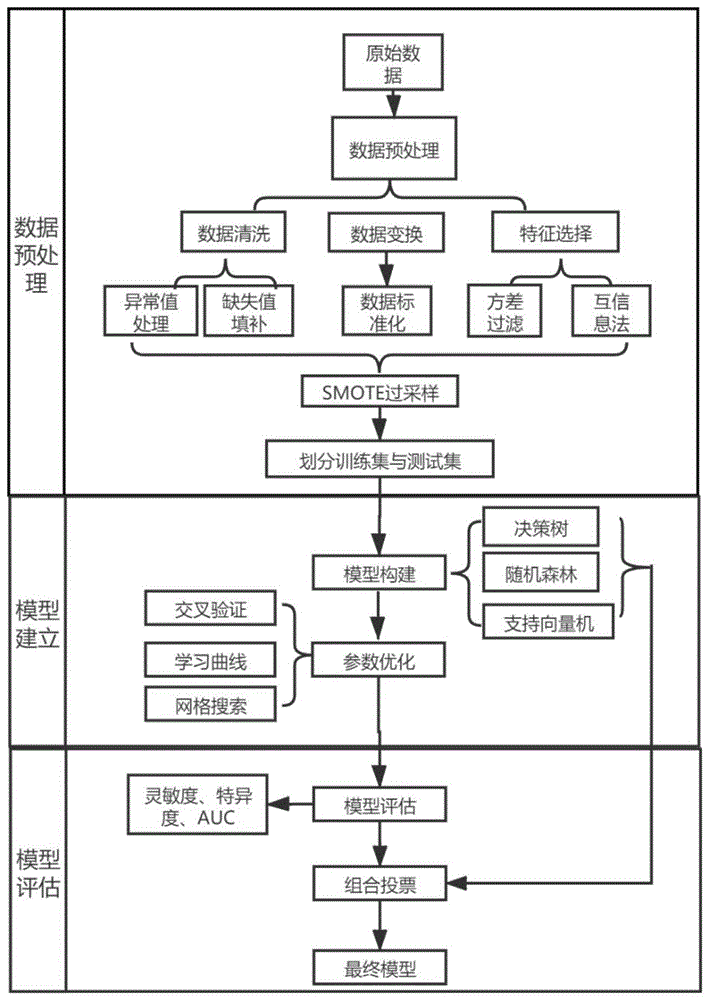
图1为基于机器学习的自动审核模型建立流程图;
图2为决策树模型Max depth、Criterion调参结果:(A)使用基尼系数时,树深度与模型AUC关系;(B)使用信息熵时,树深度与模型AUC关系;(C)分枝特征数与模型AUC关系;
图3为RF模型调参结果:(A)(B)使用基尼系数时,树模型数量与模型AUC关系;(C)树深度与模型AUC关系;(D)最小叶子样本量与模型AUC关系;
图4为不同机器学习模型ROC曲线:(A)决策树模型;(B)随机森林模型;(C)支持向量机模型;(D)集成模型。
具体实施方式
需要特别说明的是,实施例中未具体说明的数据采集、传输、储存和处理等步骤的算法,以及未具体说明的硬件结构、电路连接等均可通过现有技术已公开的内容实现。
实施例1
本实施例提供一种基于机器学习的生化免疫检验报告智能审核方法和系统,所述系统包括:
输入模块,用于输入待审核的检验报告;
预处理模块,用于进行预处理和特征提取,得到特征;
计算模块,用于采用机器学习模型对得到的特征进行计算,得到是否通过的审核结果;其中,所述机器学习模型是投票组合模型,所述投票组合模型的构建方法是:以DT、RF和SVM作为基分类器,采用投票法将所述基分类器的类别概率组合;
输出模块,输出所述审核结果。
采用上述系统进行生化免疫检验报告智能审核的方法为:
步骤1,输入待审核的检验报告,进行预处理和特征提取,得到特征;
步骤2,采用机器学习模型对步骤1得到的特征进行计算,得到是否通过的审核结果;
步骤3,输出所述审核结果。
其中,本实施例的机器学习模型的训练方法如图1所示,具体步骤如下:
1、训练模型用数据
原始数据获取:从LIS及中间件中回顾性收集西南医科大学附属医院医学检验部2020年1月至2020年11月生化报告包括门诊、住院患者和体检患者,中间件提取的数据附带有自动审核系统的验证结果。数据集具有34个特征属性,其中常规生化检测项目32项(GGT、Alb、ALT、TG、Crea、ALP、Cl、Urea、UA、Glu、LDH、AST、DBil、TC、TBil、TP、LDLC、CO2、HDLC、GSP、IBil、PA、GFR、RBP、Apo A、Apo B、TBA、K、Na、Ca、CO2和AG),临床因素2项(性别、年龄);
标签属性的获得:由两名中、高级职称的临床实验室单独手工标记,由于自动审核系统具有高特异性,故自动审核结果为阴性的报告手工标记结果也为阴性;另外,从LIS中回顾性获取不合格标本、复查样本及原因、溶血、脂血、黄疸样本的报告评价,以上标本为人工审核不合格样本,以减少手工标记的工作量。手工标记在不知道自动审核结果情况下进行,无时间限制。当两位专家的审核意见存在分歧时,由第三位专家进行复审。手工标注后的数据如表1所示。
表1手工标注后的原数据集
2、训练模型的方法
训练模型的过程包括:利用中位数、均数填补缺失值;互信息法剔除无效特征;SMOTE过采样法平衡正负样本;经过训练集(70%)与测试集(30%)划分后,使用决策树DT、RF、SVM 3种不同机器学习算法作为基学习器,在训练集上进行十折交叉验证训练模型,并利用学习曲线及网格搜索获得模型最佳超参数;在测试集上进行模型性能验证;最后将上述三种模型采用投票法构建集成学习模型。模型评估采用Sen和Spe、样本通过率、ROC、AUC。
具体如下:
2.1数据预处理
2.1.1缺失值异常值处理
缺失值处理:删除项目缺失值大于20%的项目;对于服从正态分布的特征用均值进行填补;不符合正太分布的特征采用中位数填补。异常值处理:删除无效ID的样本、非血清样本、重复数据。
2.1.2数据标准化及特征提取
由于数据集中各指标间量纲不同,数值差异较大,如果直接使用原始数据进行模型构建,数值较高的指标在模型中的作用会被放大,数值水平较低指标作用会被低估,因此需要对数据进行标准化处理。本实施例采用正态规化法对数据进行标准化,标准化后的数据符合标准正态分布,即均值为0,标准差为1。
为了避免特征冗余,使用互信息法选择最优特征。
2.1.3SMOTE过采样
由于本实施例中阴性样本与阳性样本的数量之比约为99:1,存在正负样本不平衡的问题。经过数据清洗和特征选择后,采用合SMOTE法来平衡正负类别。SMOTE通过自举采样在可用的少数数据内进行内插并通过k近邻算法生成数据来创建新的少数数据。将采样过后的数据按7:3的比例随机分配将为两个数据集(训练数据集和测试数据集),训练数据用于模型学习,测试数据进行模型验证。
2.2模型建立及参数优化
模型建立:本实施例使用了3种机器学习算法:随机森林(RF)、决策树(DT)、支持向量机(SVM)。训练过程中,采用10折交叉验证进行模型评估,通过重复10次迭代来确定模型的参数,得到平均结果,交叉验证可以更有效地利用数据,便于进一步统计分析。
参数优化:使用学习曲线和网格搜索算法获取模型最佳参数。为了兼顾模型的通过率和灵敏度,采用AUC作为调参过程中的评价指标。
2.3集成学习
集成学习是构建集成分类模型的方法之一,本实施例将上述构建的三个基分类器组合在一起,构造一个集成模型。组合模型有两种方法:第一种为“软投票”,将预测结果或基本分类器的概率分数作为输入;另一种集成技术是“硬投票”也叫多数投票,即将不同基分类器的预测结果中最频繁的分类结果作为最终分类。本本实施例采用硬投票的方式进行集成模型的构建。
3、模型训练结果
3.1预处理结果
由于电解质项目K、Na、Cl、Ca、CO2、AG项目数量过少,不能用填补法进行处理,将其删除;对于服从正态分布的特征用均值进行填补;不符合正太分布的特征采用中位数填补;对性别和标签两个二分类变量进行了二值化。删除了无效ID的样本、非血清样本、重复数据。保留了34项特征,共计39998条数据。
进行数据标准化后,采用互信息法进行特征选取,34个特征的互信息值均大于0,表明这些特征均和因变量相关,予以保留。数据预处理后最终数据集如表2所示。
使用SMOTE方法进行数据平衡后,通过与不通过的样本量相同,样本不平衡问题得到解决,纳入模型进行训练。
表2预处理后数据集
3.2模型建立及参数优化结果
3.2.1决策树模型
为获得模型的最优结果,首先使用学习曲线,以AUC为评价指标,确定了决策树的树深度(Max depth)、分枝标准(Criterion)的最佳参树;随后利用网格搜索确定了最小不纯度下降(Min impurity decrease)、最小叶子样本量(Min samples leaf)、分枝策略(Splitter)的最佳参数。图2为DT模型的调参过程,表3列出了决策树模型的最佳参数组合。
决策树模型的评估:决策树模型的最佳阈值为0.8989,灵敏度为:0.88,特异度为:0.84,AUC为:0.89,样本审核通过率为82.91%。如图2,表3所示:
表3决策树最佳参数
3.2.2随机森林
首先使用学习曲线,以AUC为评价指标,确定了随即森林的树模型数量(nestimators)、树深度、最小叶子样本量的最佳参树;随后利用网格搜索确定了分枝标准、最小不纯度下降的最佳参数。图3显示了RF调参过程,表4列出了RF模型的所有最佳参数组合。
随机森林模型的评估:最佳阈值为0.1430,灵敏度为:0.86,特异度为:0.92,AUC为:0.93,最终的审核通过率为91.80%。如图4,表4所示。
表4随机森林最佳参数
3.2.3支持向量机
对于支持向量机,利用网格搜索确定了kernel、gama、c的最佳参数。表5列出了SVM模型的最佳参数组合。如图4,表5所示:SVM的最佳阈值为0.3690,灵敏度为:0.93,特异度为:0.79,AUC为:0.91,最终的审核通过率为89.82%。SVM模型灵敏度高但特异度较低,表明SVM能较好的区分少量的不通过样本,但易拦截原本能通过的样本。
表5支持向量机最佳参数
3.2.4集成学习模型
如图4,表6所示:在3种基学习器中,各模型表现有差异,SVM模型的灵敏度最高;RF的特异性最好,AUC、通过率最高。集成学习模型的最佳阈值为0.3402,灵敏度为:0.93,特异度为:0.92,AUC为:0.96,最终的样本审核通过率为91.80%。集成学习模型的灵敏度高与特异度都较上述的基学习模型有了提升,表明集成学习模型能在较正确区分少量的不通过样本条件下,保持较高的灵敏度与通过率,具有最佳的综合性能。
表6不同机器学习模型性能比较
通过上述实施例可以看到,本发明提供的生化免疫检验报告智能审核方法和系统能够兼顾报告审核结果的灵敏度和特异性,在保证正确率的前提下,显示出更高的通过率,这使得更少的样本需要人工审核,可更大程度上减少人工干预,缩短样本TAT时间。这使得本发明在临床上具有很好的应用前景。
- 基于大数据的检验报告自动审核方法、系统和存储介质
- 基于条码扫描的临床检验报告审核系统及方法