一种异常设备识别模型训练方法、电子设备及存储介质
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及机器学习领域,特别是涉及一种异常设备识别模型训练方法、电子设备及存储介质。
背景技术
自人类社会进入信息时代以来,数字技术的快速发展和广泛应用衍生出了数字经济。数字经济是继农业经济、工业经济之后的主要经济形态,是以数据资源为关键要素,以现代信息网络为主要载体,以信息通信技术融合应用、全要素数字化转型为重要推动力,促进公平与效率更加统一的新经济形态。随着数字经济的发展,大数据、云计算、物联网、区块链、人工智能等新兴技术实现了井喷式的发展。与此同时,随着数据在网络上的流通,利用电子诈骗进行获利的不法分子也日益猖獗。
目前的技术中,对设备的异常与否进行识别时经常采用反欺诈指纹的方法,将设备的硬件信息、系统信息等数据进行特征化之后,分为正样本和负样本,进行反欺诈逻辑回归模型的训练,并通过逻辑回归模型对待检测设备进行预测。
上述现有技术中,目前能够获取到的负样本大多数靠公司自身的模拟器进行数据模拟,样本数量不足,导致预测结果不够精确。
发明内容
针对上述技术问题,本发明采用的技术方案为:
一种异常设备识别模型训练方法,方法包括:
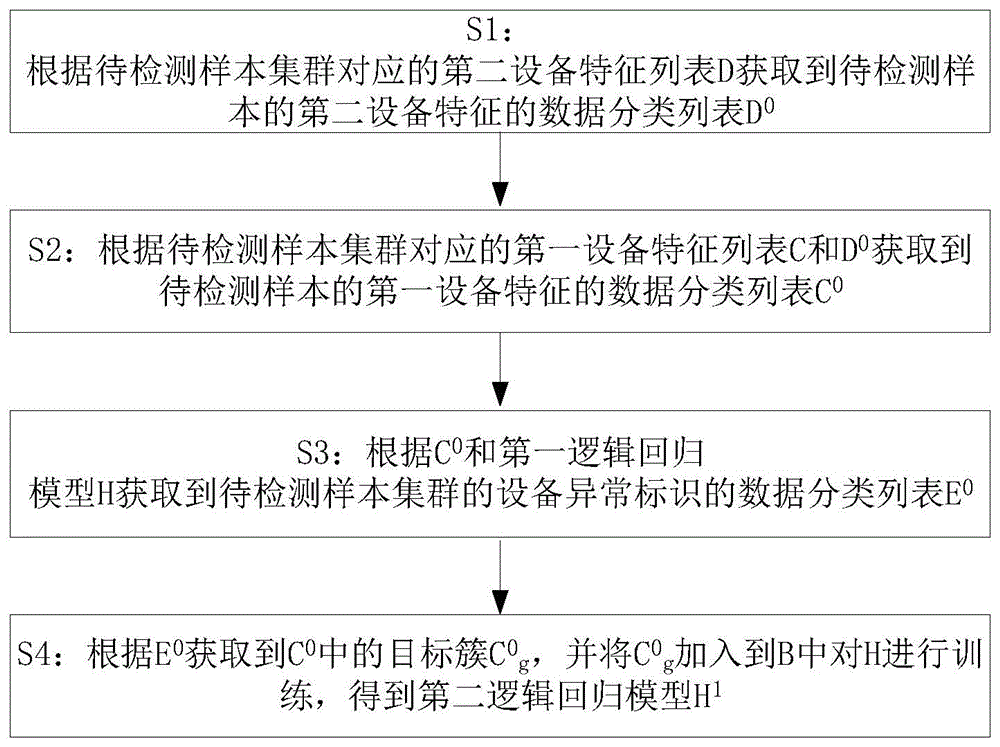
S1:根据待检测样本集群对应的第二设备特征列表D获取到待检测样本的第二设备特征的数据分类列表D
S2:根据待检测样本集群对应的第一设备特征列表C和D
S3:根据C
在步骤S3中还包括如下步骤获取H:
S31:获取到正样本集群和负样本集群,负样本集群中包括若干个异常设备标识,正样本集群中包括若干个非异常设备标识;
S32:根据正样本集群对应的第一正样本特征列表A和负样本集群对应的第一负样本特征列表B,对预设逻辑回归模型进行训练,得到第一逻辑回归模型H,其中A中包含有正样本集群中全部非异常设备标识对应的第一正样本特征向量,B中包含有负样本集群中全部异常设备标识对应的第一负样本特征向量,第一正样本特征向量与第一负样本特征向量以及第一设备特征向量包含的维度相同,H的输出结果为设备异常标识,设备异常标识为用于确定设备异常与否的标识;
S4:根据E
获取C
S41:根据E
S42:将F按照异常置信度的大小进行降序排列形成F
本发明至少具有以下有益效果:
在对待检测样本集群进行预测之前,首先需要获取预测模型。本发明通过预先选择完毕的第一正样本特征列表和第一负样本特征列表训练生成第一逻辑回归模型H,H的输出结果用于标识设备的异常与否。当需要对待检测样本集群进行预测时,在预测前首先对待检测样本集群的第二设备特征向量进行聚类分类形成D
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种异常设备识别模型训练方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种异常设备识别模型训练方法,方法包括如下步骤:
S1:根据待检测样本集群对应的第二设备特征列表D获取到待检测样本的第二设备特征的数据分类列表D
具体的,本实施例采用K-means算法对D进行聚类。
具体的,设备标识为唯一的设备ID。
具体的,第二设备特征向量包括设备开机时间戳、陀螺仪传感器最大变动角度、屏幕亮度变化幅度比例、设备存储使用量比例以及设备内存使用量比例。
上述,异常设备的频繁开机(指1小时内开机2次或以上)的比例高于正常设备的2倍。异常设备在使用过程中设备发生移动的情况很少,因此可将其作为识别异常设备与否的特征。异常设备的陀螺仪的数据中,X、Y、Z三轴的坐标值的数据在10小时内的变动小于0.01,即可认为变动微小,有成为异常设备的可能。
此外,一般用户的设备在一天的使用环境中会经历不同光照的变化,因此屏幕亮度会产生变化,异常设备的使用环境较为固定,屏幕亮度不会产生变化。
其次,由于异常设备需要在长时间且变动较小的情况下使用,因此内存使用比例也可作为特征进行使用,异常设备的内存使用率在连续的6小时内会大于80%或小于30%。
以及,异常设备进行异常活动时通常不会选择安装其他的软件,因此异常设备的存储使用比例普遍较低,异常设备普遍来说具有以下特征:当设备存储为64GB时,使用量小于30%,设备存储128GB机型,使用量小于25%,设备存储256GB机型,使用量小于15%。
具体的,在S1中还包括如下步骤对D进行聚类:
S11:根据分类系数列表K={K
S12:将L降序排序生成L
上述,分类系数K的选择对最终的结果影响较大,为了能够选取到更为合理的分类系数,本申请采用轮廓系数对不同分类系数的结果进行评估。轮廓系数衡量了聚类结果的紧密度和分离度,取值范围在-1到1之间,根据预设的不同的分类系数,选取轮廓系数取值最高的分类系数作为对D进行聚类的分类系数。
具体的,本实施例采用的分类系数为5,即p=5。
S2:根据待检测样本集群对应的第一设备特征列表C和D
S3:根据C
具体的,在步骤S3中还包括如下步骤获取H:
S31:获取到正样本集群和负样本集群,负样本集群中包括若干个异常设备标识,正样本集群中包括若干个非异常设备标识。
具体的,负样本通过模拟器设备数据进行采集。
具体的,正样本通过对异常设备风险率较低的行业内的设备进行采集。
具体的,非异常设备标识指正常设备标识。
S32:根据正样本集群对应的第一正样本特征列表A和负样本集群对应的第一负样本特征列表B,对预设逻辑回归模型进行训练,得到第一逻辑回归模型H,其中A中包含有正样本集群中全部非异常设备标识对应的第一正样本特征向量,B中包含有负样本集群中全部异常设备标识对应的第一负样本特征向量,第一正样本特征向量与第一负样本特征向量以及第一设备特征向量包含的维度相同,H的输出结果为设备异常标识,设备异常标识为用于确定设备异常与否的标识。
具体的,第一正样本特征向量至少包括机型、手机内存、手机存储、匿名设备标识符、系统版本、ip、传感器采集数据以及其他本领域技术人员可以知晓的用于对异常设备进行识别的特征,均属于本发明的保护范围,此处不再赘述。
S4:根据E
其中,获取C
S41:根据E
S42:将F按照异常置信度的大小进行降序排列形成F
上述,将第二设备特征向量进行聚类之后,将相似的第二设备特征向量所对应的第一设备特征向量作为同一类特征,通过H进行异常设备标识的判断,并计算每一类特征对应的异常置信度。当其中一类第二设备特征向量的集群特征的异常置信度较高时,说明该特征中的大部分设备均为异常设备,此时将该簇所对应的第一设备特征向量添加至B中,增加训练逻辑回归模型时的负样本数量,从而增加预测的精确度。
在对待检测样本集群进行预测之前,首先需要获取第一逻辑回归模型。本发明通过预先选择完毕的第一正样本特征列表和第一负样本特征列表训练生成第一逻辑回归模型H,H的输出结果用于标识设备的异常与否。当需要对待检测样本集群进行预测时,在预测前首先对待检测样本集群的第二设备特征向量进行聚类分类形成D
本发明的实施例还提供了一种非瞬时性计算机可读存储介质,该存储介质可设置于电子设备之中以保存用于实现方法实施例中一种方法相关的至少一条指令或至少一段程序,该至少一条指令或该至少一段程序由该处理器加载并执行以实现上述实施例提供的方法。
本发明的实施例还提供了一种电子设备,包括处理器和前述的非瞬时性计算机可读存储介质。
虽然已经通过示例对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员还应理解,可以对实施例进行多种修改而不脱离本发明的范围和精神。本发明开的范围由所附权利要求来限定。