一种基于视觉识别的茶果筛选方法
文献发布时间:2024-04-18 20:00:25
技术领域
本发明涉及食品加工领域,具体涉及一种基于视觉识别的茶果筛选方法。
背景技术
茶果是一种经济价值较高的木本油料作物,在进行下一道工序之前,需要对茶果进行分类,去除品质不达标的次品,在对茶果进行检验时,首先需要进行取样,然后对样本进行检验,进而估算全部茶果的质量。传统方式中,茶果的质量好坏通过外观便可以看出,目前主要是人工采用观察茶果外观的方式进行质量检测。传统的人工观察方式虽然简单,但存在如下问题:人的主观判断容易受到个体经验、感知误差和疲劳等因素的影响,难以保证判断的一致性和准确性。同时,人工观察需要大量的人力和时间投入,效率较低且劳动强度大。因此,需要一种基于视觉识别的茶果筛选方法。
发明内容
本发明针对现有技术的不足,提出一种基于视觉识别的茶果筛选方法,具体技术方案如下:
一种基于视觉识别的茶果筛选方法,其特征在于:
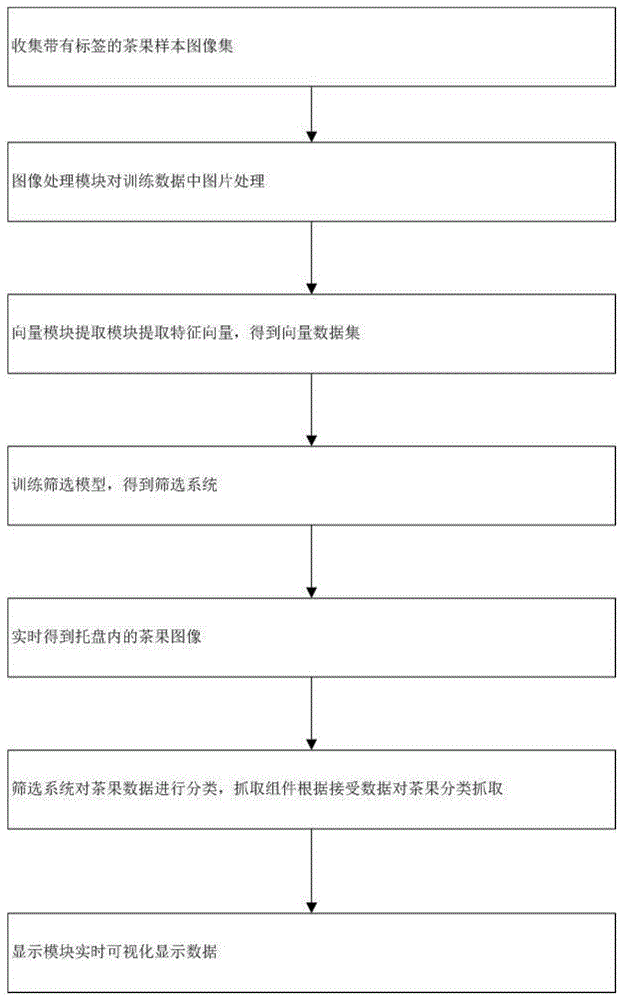
S1:收集带有标签的茶果样本图像集,该茶果样本图像集保存到训练数据库中作为训练数据集;
S2:图像处理模块对训练数据集中的图片进行去躁和平滑预处理,用于加强数据集中图像的特征;
S3:对于茶果样本图像集中的每张图片,向量提取模块依次对应的特征向量,得到向量数据集;
S4:数据处理模块以茶果的图像特征作为输入参数,以对应的标签数据作为输出参数训练筛选模型,得到筛选系统;
S5:采集模块实时采集托盘内的茶果图像;
S6:采集模块将茶果图像传入到图像处理系统中,所述图像处理模块对茶果图像处理后,输入到所述筛选系统中;
S7:所述筛选系统将托盘内所述茶果数据发送到抓取组件,所述抓取组件根据接受到的数据对托盘内的茶果进行分类抓取;
S8:所述图像识别模型向显示模块发送统计数据,所述显示模块实时对该批次茶果的数据进行可视化展示。
为更好地实现本发明,可进一步地:所述筛选系统为神经网络模型。
进一步地:所述S7包括如下步骤:
S7-1:所述图像识别模型将该预测数据保存到日志数据库中,所述图像识别模型根据所述输入特征识别是否存在坏果,如果是,则进入S7-2,否则,进入到S7-3;
S7-2:所述筛选系统通知抓取系统将所述坏果抓入到下料斗,所述下料斗将所述坏果送入到破碎机内,当所述破碎机内坏果数量达到设定标准,所述破碎机对所述破碎机内坏果破碎;
S7-3:所述筛选系统通知抓取系统将所述好果抓入到打包平台,打包平台对好果进行装箱。
进一步地:包括托盘、送料输送组件、包装输送组件、破碎组件、抓取组件、采集组件;
所述抓取组件位于所述包装输送组件、所述破碎组件和所述采集组件之间;
所述输送系统包括往复输送组件,所述托盘放置在所述往复输送带上;
所述采集系统包括支架和双目摄像头,所述双目摄像头连接在所述支架上,所述双目摄像头对准所述往复输送组件;
所述破碎组件包括下料斗和破碎机,所述下料斗位于所述破碎机上方,所述抓取组件抓取所述坏果经所述下料斗进入所述破碎机。
本发明的有益效果为:
通过带有标签的茶果样本图像集训练筛选系统,并对其进行图像处理和特征提取,利用神经网络模型进行图像识别,相对人工来说能够更加准确的识别茶果的品质和瑕疵。有效降低误判率,提高茶果的筛选准确性。
在图像处理模块中进行去噪和平滑预处理,能够增强数据集中图像的特征,进一步提高茶果图像的质量,有助于减少干扰因素对识别过程的影响,提高茶果图像的辨识度。
通过实时采集托盘内的茶果图像,并利用图像处理模块进行处理和识别,筛选系统能够根据定位数据对托盘内的茶果进行分类抓取。实时监测茶果的品质,并对茶果进行实时分类处理,实现了集中化管理。
筛选系统中的图像识别模型将识别预测数据保存到日志数据库中,并向显示模块发送统计数据。显示模块能够实时对该批次茶果的数据进行可视化展示,提供茶果筛选的统计信息和分析结果,帮助了解茶果的品质及筛选结果。
筛选系统根据识别结果通知抓取系统执行相应的动作,将坏果抓入下料斗进行破碎处理,将好果抓入打包平台进行装箱,实现茶果的自动化筛选和加工。
附图说明
图1为本发明的工作流程图;
图2为本发明的整体结构图;
图中附图说明为,托盘1、双目摄像头2、包装输送组件3、下料斗4、破碎机5、破碎组件6、抓取组件7、送料输送组件8。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1和图2所示:
一种基于视觉识别的茶果筛选方法,包括托盘1、送料输送组件8、包装输送组件3、破碎组件6、抓取组件7、采集组件;
所述抓取组件7位于所述包装输送组件3、所述破碎组件6和所述采集组件之间;
所述输送系统包括往复输送组件,所述托盘1放置在所述往复输送带上;
所述采集系统包括支架和双目摄像头2,所述双目摄像头2连接在所述支架上,所述双目摄像头2对准所述往复输送组件;
所述破碎组件6包括下料斗4和破碎机5,所述下料斗4位于所述破碎机5上方,所述抓取组件7抓取所述坏果经所述下料斗4进入所述破碎机5。
S1:收集带有标签的茶果样本图像集,该茶果样本图像集保存到训练数据库中作为训练数据集;
S2:图像处理模块对训练数据集中的图片进行去躁和平滑预处理,用于加强数据集中图像的特征;
S3:对于茶果样本图像集中的每张图片,向量提取模块依次对应的特征向量,得到向量数据集;
S4:数据处理模块以茶果的图像特征作为输入参数,以对应的标签数据作为输出参数训练筛选模型,得到筛选系统,所述筛选系统为神经网络模型。
S5:采集模块实时采集托盘1内的茶果图像;
S6:采集模块将茶果图像传入到图像处理系统中,所述图像处理模块对茶果图像处理后,输入到所述筛选系统中;
S7:所述筛选系统将托盘1内所述茶果数据发送到抓取组件7,所述抓取组件7根据接受到的数据对托盘1内的茶果进行分类抓取;
S8:所述图像识别模型向显示模块发送统计数据,所述显示模块实时对该批次茶果的数据进行可视化展示。
其中,所述S7包括如下步骤:
S7-1:所述图像识别模型将该预测数据保存到日志数据库中,所述图像识别模型根据所述输入特征识别是否存在坏果,如果是,则进入S7-2,否则,进入到S7-3;
S7-2:所述筛选系统通知抓取系统将所述坏果抓入到下料斗4,所述下料斗4将所述坏果送入到破碎机5内,当所述破碎机5内坏果数量达到设定标准,所述破碎机5对所述破碎机5内坏果破碎;
S7-3:所述筛选系统通知抓取系统将所述好果抓入到打包平台,打包平台对好果进行装箱。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 一种利用生产薄木片的设备进行薄木片生产的方法
- 一种利用苹果渣生产食用苹果果胶的方法
- 一种利用脱硫扒渣铁生产含硫易切削钢的方法
- 一种利用电解锌酸法浸出渣生产锌酸钙的方法
- 一种利用有机硅硅渣生产氯硅烷的方法及装置
- 一种利用木瓜渣生产粗纤维食品的设备及其生产方法
- 粗纤维营养食品及生产方法