一种神经网络加速核调试系统的优化方法
文献发布时间:2024-04-18 20:00:25
技术领域
本发明涉及调试系统优化,具体涉及一种神经网络加速核调试系统的优化方法。
背景技术
AI(人工智能)作为一种新的通用技术,正推动着各行各业发生前所未有的改变,而作为实现人工智能的物理载体,人工智能芯片也在蓬勃发展。按照应用领域划分,用于人工智能的处理器主要分为训练、推理两类:训练芯片主要用于机器学习和深度学习的模型训练过程,需要通过大量数据进行学习,以便能够得到最优模型参数,因此训练芯片需要有强大的并行处理能力,并且还需要有高效的数据吞吐能力,以便能够快速访问和更新数据;推理芯片的目标是在已经训练好的模型上执行推理任务,推理芯片不需要进行复杂的学习过程,其设计重点是在保证高效计算的同时,尽可能减少功耗。
一般推理芯片的结构采用“主控CPU+神经网络加速核(NNA)”的模式。主控CPU将应用中神经网络模型的计算下载至神经网络加速核上执行,获取计算结果,并对计算结果进行进一步展示或处理。一般情况下,神经网络模型需要转换为一个个计算单元——算子(Operator,简称OP),算子是神经网络模型中各层所用的基本数学运算,对算子种类的支持能力是评价一个推理芯片应用的重要指标之一。推理芯片的性能评估通常会考虑对不同类型算子的支持能力,良好的算子支持能力能够为推理芯片提供更高的性能和灵活性,从而满足不同模型和应用的需求。因此,开发出高效准确的算子对于一款推理芯片而言至关重要,而有效的调试调优手段也成为提高算子开发效率的重要支撑。
现有推理芯片针对神经网络加速核的调试调优手段主要包括算子的计算结果导出、算子的执行周期统计、神经网络加速核运行状态等有限的几种类型,使得算子的开发效率较低,无法为开发人员提供更加丰富和便捷的调试调优手段。
发明内容
(一)解决的技术问题
针对现有技术所存在的上述缺点,本发明提供了一种神经网络加速核调试系统的优化方法,能够有效克服现有技术所存在的因对神经网络加速核的调试调优手段类型有限造成神经网络加速核算子开发效率较低的缺陷。
(二)技术方案
为实现以上目的,本发明通过以下技术方案予以实现:
一种神经网络加速核调试系统的优化方法,在神经网络加速核中加入调试系统模块,在指令集设计中增加停止事件指令,并配合神经网络加速核与主控CPU之间的中断控制,实现针对神经网络加速核的运行停止控制、指令级执行控制和数据导出控制的调试操作。
优选地,针对神经网络加速核的所有调试操作,均以神经网络加速核与主控CPU之间的调试中断信号为基础实现,由调试中断服务程序实现各类调试操作,并最终由调试中断服务程序控制神经网络加速核继续运行。
优选地,神经网络加速核内部执行过程中,遇到停止事件指令时,神经网络加速核将内部指令队列中所有指令执行完成后,即指令排空,再进入停止状态,并产生对应的调试中断信号,将调试中断信号发送至主控CPU。
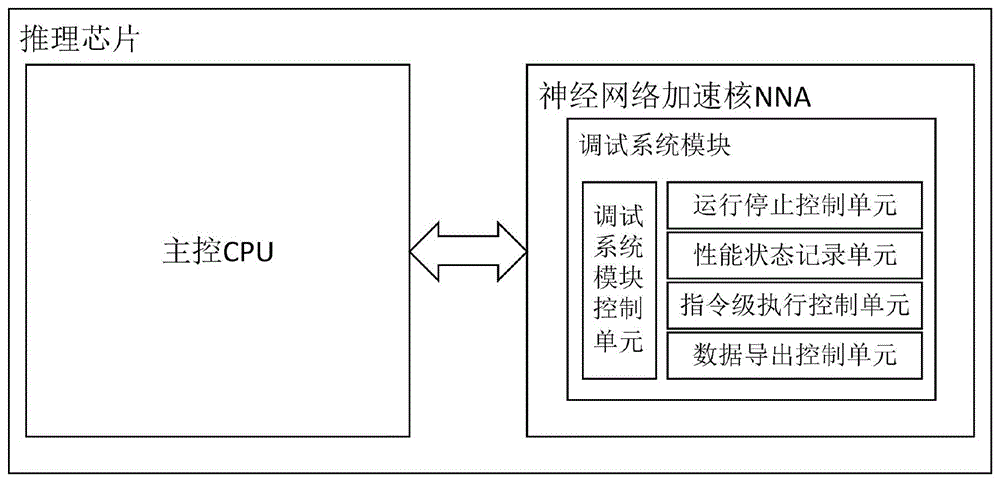
优选地,所述调试系统模块包括调试系统模块控制单元、性能状态记录单元、运行停止控制单元、指令级执行控制单元和数据导出控制单元;
调试系统模块控制单元,调试系统模块的主控单元,负责调试系统模块的相关配置,切换调试系统模块进入正常工作状态或低功耗状态;
性能状态记录单元,用于记录指令执行效率、指令执行数目和神经网络加速核状态信息;
运行停止控制单元,用于实现神经网络加速核的运行停止控制,通过配置内部寄存器将神经网络加速核在调试状态下由停止状态转换为继续运行状态;
指令级执行控制单元,用于实现神经网络加速核的指令级执行控制,通过配置内部寄存器实现指令单步执行、指令多步执行,配合性能状态记录单元提供指令级调试调优手段;
数据导出控制单元,用于实现神经网络加速核的数据导出控制,通过配置内部寄存器将神经网络加速核的核内缓存导出,以便于查看中间计算结果。
优选地,所述运行停止控制单元内部设有继续运行寄存器,当神经网络加速核由于停止事件指令或指令级执行控制进入停止状态后,运行停止控制单元通过配置内部继续运行寄存器驱动神经网络加速核进入继续运行状态;
其中,将继续运行寄存器置为1的操作只有两种,一种是神经网络加速核由主控CPU配置启动运行,另一种是由软件置为1,且只能置为1;当神经网络加速核进入停止状态时,由硬件将运行寄存器置为0。
优选地,所述指令级执行控制单元内部设有32bit的指令控制寄存器,指令级执行控制单元通过配置指令控制寄存器实现指令单步执行、指令多步执行;
其中,指令控制寄存器的最高位比特为0时,表示神经网络加速核处于正常运行控制模式;指令控制寄存器的最高位比特为1时,表示神经网络加速核处于正常指令级执行控制模式。
优选地,所述神经网络加速核处于正常指令级执行控制模式时,指令控制寄存器的低31位比特表示需要执行的指令条数,并且神经网络加速核每执行完成一条指令,指令控制寄存器减1,当指令控制寄存器的值为0x80000000时,神经网络加速核进入停止状态。
优选地,所述数据导出控制单元内部设有目标地址寄存器、导出缓存类型寄存器和导出缓存长度寄存器,当神经网络加速核由运行状态转换为停止状态时,数据导出控制单元根据目标地址寄存器、导出缓存类型寄存器和导出缓存长度寄存器中的信息,将神经网络加速核的指定核内缓存buffer中的数据导出至目标存储器。
优选地,所述神经网络加速核和主控CPU均设置于推理芯片上,所述神经网络加速核用于神经网络模型计算。
(三)有益效果
与现有技术相比,本发明所提供的一种神经网络加速核调试系统的优化方法,通过在神经网络加速核中新增调试系统模块和停止事件指令,并配合神经网络加速核与主控CPU之间的中断控制,实现对各种执行性能的统计功能,以及神经网络加速核的运行停止控制功能、指令级执行控制功能和神经网络加速核核内数据导出功能,可以在兼顾神经网络加速核高效计算的同时,为开发人员提供更加丰富和便捷的调试调优手段,提高针对神经网络加速核算子(程序)的开发效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中推理芯片调试系统模块示意图;
图2为本发明在用户层面的调试流程示意图;
图3为本发明中神经网络加速核运行停止控制的流程示意图;
图4为本发明中神经网络加速核指令级执行控制的流程示意图;
图5为本发明中神经网络加速核核内数据导出控制的流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种神经网络加速核调试系统的优化方法,在神经网络加速核中加入调试系统模块,在指令集设计中增加停止事件指令(event),并配合神经网络加速核与主控CPU之间的中断控制,实现针对神经网络加速核的运行停止控制、指令级执行控制和数据导出控制的调试操作。
神经网络加速核和主控CPU均设置于推理芯片上,神经网络加速核用于神经网络模型计算。
本申请技术方案中,针对神经网络加速核的所有调试操作,均以神经网络加速核与主控CPU之间的调试中断信号为基础实现,由调试中断服务程序实现各类调试操作,并最终由调试中断服务程序控制神经网络加速核继续运行。
神经网络加速核内部执行过程中,遇到停止事件指令时,神经网络加速核将内部指令队列中所有指令执行完成后,即指令排空,再进入停止状态,并产生对应的调试中断信号,将调试中断信号发送至主控CPU。
如图1所示,调试系统模块包括调试系统模块控制单元、性能状态记录单元、运行停止控制单元、指令级执行控制单元和数据导出控制单元;
调试系统模块控制单元,调试系统模块的主控单元,负责调试系统模块的相关配置,切换调试系统模块进入正常工作状态或低功耗状态;
性能状态记录单元,用于记录指令执行效率、指令执行数目和神经网络加速核状态信息;
运行停止控制单元,用于实现神经网络加速核的运行停止控制,通过配置内部寄存器将神经网络加速核在调试状态下由停止状态转换为继续运行状态;
指令级执行控制单元,用于实现神经网络加速核的指令级执行控制,通过配置内部寄存器实现指令单步执行、指令多步执行,配合性能状态记录单元提供指令级调试调优手段;
数据导出控制单元,用于实现神经网络加速核的数据导出控制,通过配置内部寄存器将神经网络加速核的核内缓存导出,以便于查看中间计算结果。
①运行停止控制单元内部设有继续运行寄存器(ContinueRun),当神经网络加速核由于停止事件指令或指令级执行控制进入停止状态后,运行停止控制单元通过配置内部继续运行寄存器驱动神经网络加速核进入继续运行状态;
其中,将继续运行寄存器置为1的操作只有两种,一种是神经网络加速核由主控CPU配置启动运行,另一种是由软件置为1,且只能置为1;当神经网络加速核进入停止状态时,由硬件将运行寄存器置为0。
②指令级执行控制单元内部设有32bit的指令控制寄存器(StallInstrs),指令级执行控制单元通过配置指令控制寄存器实现指令单步执行、指令多步执行;
其中,指令控制寄存器的最高位比特为0时,表示神经网络加速核处于正常运行控制模式;指令控制寄存器的最高位比特为1时,表示神经网络加速核处于指令级执行控制模式。
神经网络加速核处于正常指令级执行控制模式时,指令控制寄存器的低31位比特表示需要执行的指令条数,并且神经网络加速核每执行完成一条指令,指令控制寄存器减1,当指令控制寄存器的值为0x80000000时,神经网络加速核进入停止状态。
③数据导出控制单元内部设有目标地址寄存器(DestAddrChip)、导出缓存类型寄存器(BufferSort)和导出缓存长度寄存器(BufferLength),当神经网络加速核由运行状态转换为停止状态时,数据导出控制单元根据目标地址寄存器、导出缓存类型寄存器和导出缓存长度寄存器中的信息,将神经网络加速核的指定核内缓存buffer中的数据导出至目标存储器。
如图2所示,在用户层面的调试流程主要依赖于神经网络加速核与主控CPU之间的中断控制实现,各种调试操作也是基于主控CPU对神经网络加速核的访问实现的。一般推理芯片的应用流程是,用户基于推理芯片的应用由CPU执行,CPU将应用中神经网络模型的计算下载至神经网络加速核上执行,神经网络加速核执行完成后通过中断告知CPU,CPU获取计算结果,并对计算结果进行进一步展示或处理。
而本发明的调试流程也是建立在神经网络加速核与主控CPU之间的中断控制之上的。CPU在执行推理应用时,首先完成神经网络加速核的指令和数据的准备工作,随后启动神经网络加速核运行,神经网络加速核停止运行并触发产生中断,CPU根据中断类型判断是神经网络加速核计算执行完成还是调试操作触发中断:若是计算执行完成触发中断,则CPU处理计算结果并继续执行下一步应用操作;若是调试操作触发中断,则开发人员执行调试操作后,继续启动神经网络加速核运行,直至计算执行完成。
如图3所示,主要描述利用停止事件指令(event)和运行停止控制单元内部的继续运行寄存器(ContinueRun)实现针对神经网络加速核的运行停止控制,并实现调试操作流程。继续运行寄存器为1bit寄存器,当值为0时表示内核处于停止状态,值为1时表示内核处于运行状态。开发人员根据需要,在适当位置处增加停止事件指令。
推理应用加载完成后,CPU在调试中断服务程序入口设置断点,在执行至神经网络模型计算时,CPU完成神经网络加速核的指令和数据的准备工作,并将指令和数据的地址写入神经网络加速核的指定寄存器中,随后启动神经网络加速核运行。神经网络加速核运行至停止事件指令时进入停止状态,并产生调试中断上报至CPU,CPU识别调试中断并进入调试中断服务程序,由于在调试中断服务程序的入口处设置有断点,因此CPU停止在调试中断服务程序入口处。此时,神经网络加速核和CPU均处于停止状态,执行各种需要的调试操作,满足开发人员调试需求。
完成调试操作后,继续运行调试中断服务程序,并由调试中断服务程序配置运行停止控制单元内部的继续运行寄存器,启动神经网络加速核继续运行。若有多条停止事件指令,神经网络加速核会产生多次调试中断,供开发人员执行各种需要的调试操作,直至神经网络模型计算完成,产生最终的计算执行完成中断。
如图4所示,主要描述利用指令级执行控制单元内部的指令控制寄存器(StallInstrs)实现针对神经网络加速核的指令级执行控制。指令控制寄存器为32bit寄存器,最高位比特为0时,表示神经网络加速核处于正常运行控制模式;最高位比特为1时,表示神经网络加速核处于指令级执行控制模式。当处于正常指令级执行控制模式时,指令控制寄存器的低31位比特表示需要执行的指令条数,并且神经网络加速核每执行完成一条指令,指令控制寄存器减1,当指令控制寄存器的值为0x80000000时,神经网络加速核进入停止状态。
在开发人员进行指令级执行控制调试时,推理应用加载完成后,CPU在调试中断服务程序入口设置断点,并将需要执行的指令条数配置到指令控制寄存器,随后CPU开始执行。在执行至神经网络模型计算时,CPU完成神经网络加速核的指令和数据的准备工作,并将指令和数据的地址写入神经网络加速核的指定寄存器中,随后启动神经网络加速核运行。
神经网络加速核每执行完成一条指令,指令控制寄存器减1,当指令控制寄存器的值为0x80000000时,神经网络加速核进入停止状态,并产生调试中断上报至CPU,CPU识别调试中断并进入调试中断服务程序,由于在调试中断服务程序的入口处设置有断点,因此CPU停止在调试中断服务程序入口处。此时,神经网络加速核和CPU均处于停止状态,执行各种需要的调试操作,满足开发人员调试需求。
完成调试操作后,开发人员可配置下一次需要执行的指令条数至指令控制寄存器。随后,继续运行调试中断服务程序,并由调试中断服务程序配置运行停止控制单元内部的继续运行寄存器,启动神经网络加速核继续运行,直至神经网络模型计算完成,产生最终的计算执行完成中断。
如图5所示,主要描述利用数据导出控制单元内部的目标地址寄存器(DestAddrChip)、导出缓存类型寄存器(BufferSort)和导出缓存长度寄存器(BufferLength)实现针对神经网络加速核的数据导出控制,将神经网络加速核的核内缓存中间结果导出至片内存储或片外存储(如片内共享存储器、片外DDR等)。
数据导出控制是以神经网络加速核的运行停止控制和指令级执行控制为基础的,当内核由运行状态转换为停止状态时,数据导出控制单元根据内部配置寄存器中的信息,将神经网络加速核的指定核内缓存buffer中的数据导出至目标存储器。
开发人员进行调试,并需要导出神经网络加速核的核内缓存buffer中的数据时,首先根据需要完成运行停止控制或指令级执行控制的相关配置;其次,完成数据导出控制单元内部相关寄存器的配置工作,并启动神经网络加速核运行。当神经网络加速核停止运行时,数据导出控制单元将神经网络加速核的指定核内缓存buffer中的数据导出至目标存储器。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不会使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 一种有机固废垃圾的无害化处理装置
- 一种有机固废热解处理的组分复配预处理方法
- 一种农村有机固废液废循环处理系统和方法
- 一种基于催化分解远离的有机废气净化装置
- 一种基于蚯蚓的有机固废分解装置及方法
- 一种基于化学链制氢的有机固废处理装置及其使用方法