一种基于CV-XGBoost算法的油井含水率计算方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于采油过程中油井产液含水率的预测和控制技术领域,尤其是涉及一种基于CV-XGBoost算法的油井含水率计算方法。
背景技术
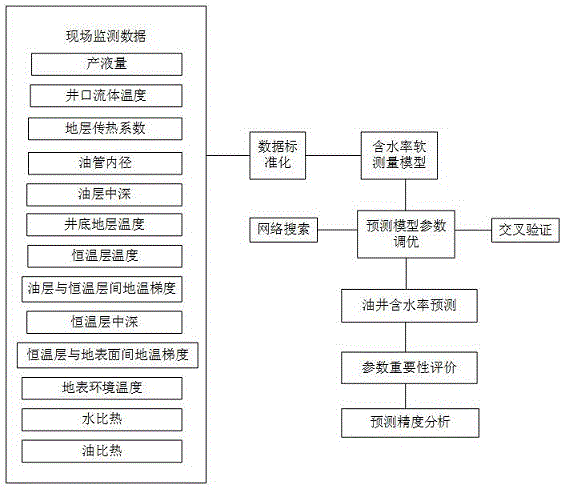
油井产液含水率是原油生产过程中的重要计量参数之一,也是评价油井以及油田开采能力与效益的重要指标。目前,中国已开发油田总体上进入高含水、高采出程度的“双高”开采阶段,高含水老油田剩余油分布呈现“总体高度分散、局部相对富集”的格局。为了能够及时了解和掌握采油过程的生产状况以便有针对性指导后续生产计划执行,确保油井始终处于最佳生产状态,最终达到提高油井开采效率和提高原油采收效率的目的,油井含水率的测量变得极为紧迫。而油田数字化建设以来,大部分油田通过功图量油,但这种测量方法只能得到产液量,而产气量、产油量、产水量、含水率、生产气油比或生产气液比等重要数据无法获得。为了解决这个难题,通过采集油田现场能够检测的数据,构造出一种以这些变量为输入,油井含水率为输出的数学模型,实现对油井含水率的在线预测,这便是油井含水率预测技术。
发明内容
本发明的目的是研究出一种基于CV-XGBoost算法的油井含水率计算方法,将交叉验证的思想与XGBoost算法结合,使学习出来的模型更加简单,并防止过拟合,实现采油过程中油井含水率的预测。
一种基于CV-XGBoost算法的油井含水率计算方法,包括如下步骤:
S1、收集油田现场采油过程的历史数据作为训练数据集
S2、将收集到的训练数据集归一化,形成数据取值范围限制在[0,1]之间的的数据集
训练数据集归一化具体做法为:找出每个参数的最小值和最大值,将原数据通过min-max归一化映射成在区间[0,1]中的值,公式如下:
;
式中,x为某参数的原值,x
S3、建立基于XGBoost算法、随机森林算法、LightGBM算法的油井含水率数据驱动预测模型;
XGBoost由多棵决策树组成,通过加法模型将一组弱学习器组合成强学习器,设有数据集(
;
式中,
;
式中,
考察第
;
式中,
由于目标函数很难在欧氏空间内优化,用泰勒公式展开,近似得到二阶导数:
;
将树模型细化到叶子节点,整理可得:
;
式中,
由式(8)可解得叶子节点的最优权重和最优目标函数值:
;
为了避免过拟合,模型训练迭代过程加一个缩减系数,实现小步迭代寻优:
;
式中,
随机森林利用bootstrap重抽样的方法,将具有
;
重复
;
式中,
使用随机森林预测出的结果,为所有决策树预测结果的均值;
;
LightGBM基于直方图算法对连续特征离散化处理,构造宽度为k的直方图,遍历找到最佳分裂点。回归树生长阶段,LightGBM采用基于叶子生长的Leaf-wise增长策略,相比于基于层生长的Level-wise增长策略,减少了计算量,有效控制模型复杂度,并通过限制最大深度,可以防止过拟合现象。LightGBM模型目标函数可通过下式表示:
;
式中,
S4、将归一化后的数据集
S5、对优选出的数据驱动模型使用基于交叉验证的极限梯度提升方法进行参数调优;
参数调优具体做法为:对于大小为
;
式中,
S6、辅助变量重要性评价;
S7、对归一化后的数据集进行降维,使用调优后的预测模型对降维后的数据进行学习,实现采油过程中对油井含水率的计算。
与现有技术相比,本发明的有益效果是:
本发明针对传统的XGBoost算法,提出了基于交叉验证的极限梯度提升的油井含水率预测方法,相较于其他传统的数据驱动模型,本发明的优势主要体现在引入了二阶导增加精度,且在目标函数中加入了正则项,降低了模型的方差,防止过拟合,降低了预测误差。
附图说明
为了更清楚地说明本说明书一个或多个实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书一个或多个实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明基于CV-XGBoost算法的油井含水率计算方法步骤图;
图2是基于XGBoost算法的油井含水率预测输出结果图;
图3是基于随机森林算法的油井含水率预测输出结果图;
图4是基于LightGBM算法的油井含水率预测输出结果图;
图5是本发明基于CV-XGBoost算法的油井含水率计算方法的预测输出结果图;
图6是辅助变量对含水率的敏感性分析结果图;
图7是降维后基于CV-XGBoost算法的油井含水率预测平均绝对误差分析结果图;
图8是降维后基于CV-XGBoost算法的油井含水率预测平均相对误差分析结果图。
具体实施方式
为使本公开的目的、技术方案和优点更加清楚明白,以下结合具体实施例,对本公开进一步详细说明。
需要说明的是,除非另外定义,本说明书一个或多个实施例使用的技术术语或者科学术语应当为本公开所属领域内具有一般技能的人士所理解的通常意义。本说明书一个或多个实施例中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
本申请以油田现场给出计算实例,提出一种基于CV-XGBoost算法的油井含水率计算方法,包括以下步骤:
S1、收集油田现场采油过程的历史数据作为训练数据集
以井口流体温度、产液量、油管直径、油层至恒温层间地温梯度、恒温层至地表面间地温梯度、地层传热系数、油层中深、地表环境温度、恒温层温度、井底地层温度、恒温层中深、油比热、水比热作为辅助变量,含水率作为预测变量,共13个自变量,1个因变量,1000个历史样本数,部分训练数据集见表1和表2:
S2、将收集到的训练数据集归一化,形成数据取值范围限制在 [0,1]之间的的数据集
训练数据集归一化具体做法为:找出每个参数的最小值和最大值,将原数据通过min-max归一化映射成在区间[0,1]中的值,公式如下:
;
式中,x为某参数的原值,x
Min-max归一化后的数据集如表3和表4所示:
S3、建立基于XGBoost算法、随机森林算法、LightGBM算法的油井含水率数据驱动预测模型;
XGBoost由多棵决策树组成,通过加法模型将一组弱学习器组合成强学习器,设有数据集(
;
式中,
;
式中,
考察第
;
式中,
由于目标函数很难在欧氏空间内优化,用泰勒公式展开,近似得到二阶导数:
;
将树模型细化到叶子节点,整理可得:
;
式中,
由式(8)可解得叶子节点的最优权重和最优目标函数值:
;
为了避免过拟合,模型训练迭代过程加一个缩减系数,实现小步迭代寻优:
;
式中,
随机森林利用bootstrap重抽样的方法,将具有
;
重复
;
式中,
使用随机森林预测出的结果,为所有决策树预测结果的均值;
;
LightGBM基于直方图算法对连续特征离散化处理,构造宽度为k的直方图,遍历找到最佳分裂点。回归树生长阶段,LightGBM采用基于叶子生长的Leaf-wise增长策略,相比于基于层生长的Level-wise增长策略,减少了计算量,有效控制模型复杂度,并通过限制最大深度,可以防止过拟合现象。LightGBM模型目标函数可通过下式表示:
;
式中,
S4、将归一化后的数据集
平均相对误差MAPE越小,预测精度越好,平均相对误差MAPE公式如下:
;
将步骤S2中min-max归一化后的数据集划分为训练集和测试集,依次使用XGBoost、随机森林、LightGBM三种训练模型进行含水率预测,预测结果见表5-表7:
S5、对优选出的数据驱动模型使用基于交叉验证的极限梯度提升方法进行参数调优;
参数调优具体做法为:对于大小为
;/>
式中,
使用基于CV-XGBoost算法的数据驱动模型对含水率进行预测,预测结果如表8所示:
S6、辅助变量重要性评价;
由于影响含水率的因素众多,各影响因素对含水率的影响程度不同,且影响因素间存在多重共线性,考虑到现场无法完整获取全部参数,需要对原自变量进行敏感性分析,使用XGBClassifier()函数和feature_importances_()函数可以得到各自变量对含水率的影响程度,如表9所示:
S7、对归一化后的数据集进行降维,使用调优后的预测模型对降维后的数据进行学习,实现采油过程中对油井含水率的计算。计算的
含水率误差如表10所示:
具体实施例构建了1000个单因素敏感性分析的数据作为初始训练样本进行建模,为了验证本发明的基于CV-XGBoost算法的含水率软测量模型的可行性,对比了基于随机森林算法、LightGBM算法、XGBoost算法的数据驱动模型。将归一化后的数据集分别输入数据驱动模型中,上述四种预测模型分别在最佳效果下的预测精度如表11所示,四种方法的运行结果如图2-图5所示:·
表11给出了四种数据驱动模型预测效果对比。从预测精度方面来分析,本发明的方法在预测精度上有相对更好的表现,基于CV-XGBoost算法的数据驱动模型预测含水率精度最高,相对于随机森林算法预测模型MAPE降低了16.43%,相比于LightGBM算法预测模型MAPE降低了18.06%,相对于XGBoost算法预测模型MAPE降低了10.95%。
对比图2和图3、图4、图5,可以看出,基于CV-XGBoost算法的数据驱动模型预测含水率变化趋势与实际值一致,明显优于其他3种预测模型,曲线拟合最好,预测精度最高。原因是CV-XGBoost引入了二阶导能够自定义损失函数,且加入了正则项防止了模型过拟合。
从图6中我们可以看出,各自变量对含水率的影响程度都不一样,从大到小依次是:产液量、恒温层至地表面间地温梯度、井口流体温度、恒温层温度、井底地层温度、油层与恒温层间地温梯度、地层传热系数、油管直径、地表环境温度、恒温层中深、油比热、油层中深、水比热。
将自变量按影响程度从小到大依次剔除,得到降维后的数据,使用基于CV-XGBoost算法的油井含水率预测模型对降维后数据进行预测。结果如图7和图8所示:我们可以看出,剔除6种敏感性较弱的自变量后,模型预测含水率精度依旧很高,平均相对误差在15%左右,能够满足现场因参数获取不足也可以精确预测含水率的需求。
因次,本发明采用上述基于CV-XGBoost算法的油井含水率计算方法,将交叉验证的思想与XGBoost算法结合,帮助模型防止过拟合,实现了采油过程中对油井含水率的预测。
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子;在本公开的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本说明书一个或多个实施例的不同方面的许多其它变化,为了简明它们没有在细节中提供。
本说明书一个或多个实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本说明书一个或多个实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本公开的保护范围之内。
- 车辆用电子钥匙系统以及控制电子钥匙的方法
- 钥匙安全管理系统及方法
- 一种具有通用钥匙和专用钥匙的门禁管理系统
- 钥匙管理柜、管理系统及钥匙管理方法
- 钥匙管理单元、方法及系统